







在第23-24节我们已经找到了上限函数
mH(N)
m
H
(
N
)
,那么是否把它代入到霍夫丁不等式就OK了呢?答案是否定的,我们最终会经过一系列证明把霍夫丁不等式变成如下的样子:

上面的式子最后会变成如下:
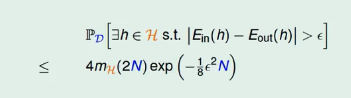
以下是证明步骤:
第一步,把无限的 Eout(N) E o u t ( N ) 变成有限个
在霍夫丁不等式中,我们知道 Ein(N) E i n ( N ) 是有限的,但是 Eout(N) E o u t ( N ) 是无限的,这对我们的计算是极为不利的,所以我们要想办法把 Eout(N) E o u t ( N ) 也变为有限多个,这样计算起来就简单很多了。
那么要怎么样才能使
Eout(N)
E
o
u
t
(
N
)
变成有限个呢?办法是有的,假设我们有一个测试集
D′
D
′
,该测试集的数据量为有限的N个,那么原来的
Eout(N)
E
o
u
t
(
N
)
其实就相当于测试机的
Ein
E
i
n
,此处我们为了方便区别,我们令为
E′in
E
i
n
′
.那么这三者的关系可以用下图来表示:
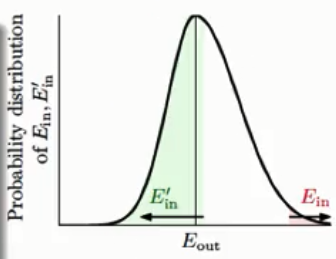
从上图可以看出,如果
Ein
E
i
n
离
Eoout
E
o
o
u
t
很远,则
Ein
E
i
n
也离
E′in
E
i
n
′
很远。
现在我们就可以用
E′in
E
i
n
′
来代替
Eout
E
o
u
t
了,但是要加入一些常数(如下图圈起部分),我们可以不管这些常数是怎么来的,因为展开讲会十分麻烦,所以先记住吧。

接下来的第二三步证明我这边也听不懂,这里就不进一步展开了,我们只要记住结论就好了,先跳过吧,知道的同学可以加群讨论。
===========================懵逼分割线===========================
欢迎大家加入Q群讨论:463255841
===========================懵逼分割线===========================














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









