







numpy简介
numpy是python最为常用的库,没有之一,它表示Numeric Python,从名字也可以看出来,它被用来做数值计算,常与scipy配合使用。现在几乎各种应用场合都会用到numpy,主要有以下几个原因:
- numpy提供了很多数值计算和常用算法的函数
- numpy归功了很多线性代数的相关操作
- numpy的执行效率高
首先导入numpy库
import numpy as np
常规列表应用
用numpy建的列表类型都是ndarray,因此我们首先来看np.array的用法
np.array的参数列表如下:
numpy.array(object, dtype = None, copy = True, order = None, subok = False, ndmin = 0)
| parameter | description |
|---|---|
| object | 要新建的数组对象 |
| dtype | 数组的所需数据类型 |
| copy | 对象是否被复制。 |
| order | C(按行)、F(按列)或A(任意,默认)。 |
| subok | 默认情况下,返回的数组被强制为基类数组。 如果为true,则返回子类。 |
| ndmin | 指定返回数组的最小维数。 |
首先来看一维列表的应用
# 构建一维列表
>>> a = np.array([1.0, 2.0, 3.0])
>>> type(a)
<class 'numpy.ndarray'>
>>> a.shape #a是一个一维的array
(3,)
# 列表索引
>>> a[0]
1.0
>>> a[1:3]
array([2., 3.])
>>> a[:2] #默认是0:2
array([1., 2.])
>>> a[0:5:2]
array([1., 3., 5.])
>>> a = np.array([1.0, 2.0, 3.0, 4.0, 5.0])
>>> idx = range(0,5,2)
>>> a[idx]
array([1., 3., 5.])
# 列表的常规运算
# 广播操作
>>> 3 * a
array([ 3., 6., 9., 12., 15.])
>>> a.sum()
15.0
>>> a.std()
1.4142135623730951
>>> a.cumsum()
array([ 1., 3., 6., 10., 15.])
>>> a**2
array([ 1., 4., 9., 16., 25.])
>>> np.sqrt(a)
array([1. , 1.41421356, 1.73205081, 2. , 2.23606798])
>>> b = np.array([1,2,3,4,5])
>>> a + b
array([ 2., 4., 6., 8., 10.])
>>> a * b
array([ 1., 4., 9., 16., 25.])
>>> 3 * a
>>> a / b
array([1., 1., 1., 1., 1.])
下面再来看二维列表
>>> a = np.array([[1,2,3],[4,5,6]])
>>> print(a)
[[1 2 3]
[4 5 6]]
>>> a.shape
(2, 3)
>>> a = np.random.standard_normal((3,4))
>>> a
array([[-1.75678372, -0.62623838, 0.9360396 , 2.006273 ],
[ 1.1764022 , -0.02253561, 0.28304646, -0.5089298 ],
[-0.60796283, 0.21279179, 0.76809883, 2.03964675]])
# 索引
>>> a[2,3]
2.0396467524421187
>>> a[0:2,1:3]
array([[-0.62623838, 0.9360396 ],
[-0.02253561, 0.28304646]])
>>> a[:2,1:]
array([[-0.62623838, 0.9360396 , 2.006273 ],
[-0.02253561, 0.28304646, -0.5089298 ]])
>>> a[:2,1:-1]
array([[-0.62623838, 0.9360396 ],
[-0.02253561, 0.28304646]])
# 基本运算
>>> a.sum()
3.8998483020681207
>>> a.std()
1.0801601854740654
>>> a.cumsum()
array([-1.75678372, -2.3830221 , -1.4469825 , 0.55929051, 1.73569271,
1.7131571 , 1.99620356, 1.48727376, 0.87931093, 1.09210272,
1.86020155, 3.8998483 ])
在新建ndarray时指定维数
>>> a = np.array([1,2,3,4], ndmin=2)
>>> a
array([[1, 2, 3, 4]])
>>> a.shape # a是一个二维array
(1, 4)
numpy中常用的函数
创建数组
numpy.array()
首先就是np.array了,可以直接把list转成ndarray
>>> lst = [1,2,3,4]
>>> nd1 = np.array(lst)
>>> nd1
array([1, 2, 3, 4])
numpy.arange(n)
生成range数据,注意要区别于python中的range()函数,numpy中的arange()
>>> nr = np.arange(1,10,2)
>>> nr
array([1, 3, 5, 7, 9])
numpy.ones(shape)
生成全1的array
>>> n1 = np.ones((2,3))
>>> n1
array([[1., 1., 1.],
[1., 1., 1.]])
numpy.zeros(shape)
生成全0的array
>>> n0 = np.zeros((2,3))
>>> n0
array([[0., 0., 0.],
[0., 0., 0.]])
numpy.full(shape, val)
生成数值都是val的array
>>> nv = np.full((2,3), 5)
>>> nv
array([[5, 5, 5],
[5, 5, 5]])
numpy.eye(n)
生成单位矩阵
>>> ne = np.eye(3)
>>> ne
array([[1., 0., 0.],
[0., 1., 0.],
[0., 0., 1.]])
numpy.ones_like(a)
按数组a的形状和类型生成全1的数组
>>> a = [[1.0,2,3],[4,5,6]]
>>> nol = np.ones_like(a)
>>> nol
array([[1., 1., 1.],
[1., 1., 1.]])
numpy.zeros_like(a)
按数组a的形状和类型生成全0的数组
numpy.full_like (a, val)
按数组a的形状和类型生成数值全是val的数组
numpy.linspace(m,n,d)
>>> n1 = np.linspace(0,6,3)
>>> n1
array([0., 3., 6.])
>>> n2 = np.linspace(0,6,3, endpoint=False)
>>> n2
array([0., 2., 4.])
numpy.concatenate()
拼接两个ndarray
>>> np.concatenate((n1, n2))
array([0., 3., 6., 0., 2., 4.])
也可以指定拼接的方向,按行拼接或者按列拼接,需要注意的是,一维array的拼接不能指定axis=0,axis=0表示按列拼接,axis=1表示按行拼接
>>> n11 = np.array(n1, ndmin=2)
>>> n22 = np.array(n2, ndmin=2)
>>> np.concatenate((n11,n22), axis=1)
array([[0., 3., 6., 0., 2., 4.]])
>>> np.concatenate((n11,n22), axis=0)
array([[0., 3., 6.],
[0., 2., 4.]])
数组维度变换
obj.reshape(shape)
>>> a = np.arange(0,6,1).reshape(2,3)
>>> a
array([[0, 1, 2],
[3, 4, 5]])
obj.resize(shape)
跟numpy.reshape()的区别在于resize()没有返回值,直接对原始数组进行修改
>>> a = np.arange(0,6,1)
>>> a.resize(2,3)
>>> a
array([[0, 1, 2],
[3, 4, 5]])
obj.swapaxes(ax1, ax2)
将两个维度调换,numpy中的维数从0开始索引,即如果是个二维的array,则维度的索引值为0 1
>>> a.swapaxes(0,1)
array([[0, 3],
[1, 4],
[2, 5]])
obj.flatten()
对数组进行降维,从名字也可以看出,就是把数组打平
>>> a = np.random.standard_normal((2,3))
>>> a
array([[ 0.27694629, 2.13266506, 1.51229221],
[ 0.83796963, -0.61849818, -0.99148708]])
>>> a.flatten()
array([ 0.27694629, 2.13266506, 1.51229221, 0.83796963, -0.61849818,
-0.99148708])
数组类型转换
obj.astype(new_type)
>>> a.astype(np.int)
array([[0, 2, 1],
[0, 0, 0]])
obj.tolist()
把ndarray转换成list
>>> a.tolist()
[[0.27694628837953544, 2.1326650560980402, 1.5122922063725635], [0.8379696303853928, -0.6184981767787137, -0.9914870782615903]]
数学运算
np.sqrt() #开平方根
np.abs() #求模值
np.square() #取平方
np.log() #自然对数
np.log2() #以2为底的对数
np.log10() #以10为底的对数
np.exp() #指数
np.sign() #取符号
np.maximum(a,b) #最大值
np.minimum(a,b) #最小值
np.fmax() #取最大值,返回ndarray
np.fmin() #取最小值,返回ndarray
np.copysign(a,b) #将b中各元素的符号赋值给数组a的对应元素
随机函数
np.random.rand(m,n)
生成m行v列[0,1)之间均匀分布的随机数
>>> np.random.rand(2,3)
array([[0.30555863, 0.41887171, 0.12944243],
[0.047311 , 0.5610462 , 0.05545177]])
np.ramdom.randn(m,n)
生成m行v列服从标准正态分布的随机数
标准正态分布
>>> np.random.randn(3,4)
array([[ 0.23319176, 0.25340606, 0.68854916, -1.05048334],
[-1.50006282, 0.57744967, -0.32361244, -2.24994722],
[-2.17479774, -0.06314763, -0.41480656, -1.75927588]])
np.random.standard_normal((m,n))
跟np.random.randn(m,n)功能相同,只是参数为tuple
np.random.normal(mean, var, shape)
产生均值为mean,标准差为var,shape形状的正态分布
>>> np.random.normal(0,1,(3,4))
array([[ 1.33985417, -0.73385786, 1.24840547, 0.383745 ],
[-0.88195275, -1.96785155, -0.22755158, -0.02383854],
[-0.82976081, -0.33360492, -0.85581441, 1.28111454]])
np.ramdom.randint(low,high,(shape))
生成在low和high之间的随机整数
>>> np.random.randint(1,10,(2,3))
array([[8, 9, 9],
[2, 3, 1]])
np.random.uniform(low, high, shape)
生成在low和high之间的随机浮点数数
>>> np.random.uniform(1,20,(4,5))
array([[10.30839345, 9.15929767, 2.09133005, 10.90228798, 2.92443925],
[ 3.1389329 , 19.84637209, 2.87868248, 14.43621747, 10.66421098],
[14.21018776, 7.68568737, 12.42300546, 12.73930224, 18.99678353],
[ 1.34370231, 12.82687093, 3.53277008, 14.82696923, 5.52948898]])
np.ramdom.seed(n)
随机数种子,如果想每次产生的随机数多是一样的,只要设置相同的随机数种子就可以
np.random.shuffle(a)
根据数组a的第一轴进行随机排列,改变数组a
>>> a = np.random.standard_normal((4,5))
>>> a
array([[ 0.94883904, 0.06622621, -0.55604216, 0.4201526 , 0.93582474],
[-0.19459866, 0.61766597, -0.0381477 , -0.76228097, -0.39149656],
[-0.15616535, 1.69581075, -1.36644287, -1.48007808, -0.45827237],
[-2.10678691, 1.09201772, -1.27128825, 0.47358959, 0.37246547]])
>>> np.random.shuffle(a)
>>> a
array([[-2.10678691, 1.09201772, -1.27128825, 0.47358959, 0.37246547],
[-0.15616535, 1.69581075, -1.36644287, -1.48007808, -0.45827237],
[-0.19459866, 0.61766597, -0.0381477 , -0.76228097, -0.39149656],
[ 0.94883904, 0.06622621, -0.55604216, 0.4201526 , 0.93582474]])
permutation(a)
根据数组a的第一轴进行随机排列, 但是不改变原数组,将生成新数组
>>> np.random.permutation(a)
array([[ 0.94883904, 0.06622621, -0.55604216, 0.4201526 , 0.93582474],
[-0.15616535, 1.69581075, -1.36644287, -1.48007808, -0.45827237],
[-2.10678691, 1.09201772, -1.27128825, 0.47358959, 0.37246547],
[-0.19459866, 0.61766597, -0.0381477 , -0.76228097, -0.39149656]])
choice(a[, shape, replace, p])
从一维数组a中以概率p抽取元素, 形成shape形状新数组,replace表示是否可以重用元素,默认为False
>>> a = range(1,10)
>>> np.random.choice(a,(3,2))
array([[5, 2],
[6, 9],
[6, 8]])
np.random.poisson(lambda,shape)
泊松分布
>>> np.random.poisson(10,(2,3))
array([[11, 7, 8],
[ 6, 8, 13]])
统计函数
np.sum(a, axis = None) #求和
np.mean(a, axis = None) #求均值
np.std(a, axis = None) #求标准差
np.average(a, axis = None, weights) #按权重求均值
np.min(a) #最小值
np.max() #最大值
np.argmin() #最小值下标
np.argmax() #最大值下标
np.unravel_index(index, shape) #根据shape将一维下标index转成多维下标
np.median(a) #中值
np.ptp(a) #最大值和最小值的差
梯度计算
np.gradient(a)
计算数组a中元素的梯度,f为多维时,返回每个维度的梯度
>>> a = np.random.randn(2,3)
>>> np.gradient(a)
[array([[-0.40790034, -0.85434474, 0.78626434],
[-0.40790034, -0.85434474, 0.78626434]]), array([[ 1.72286723, 0.14257516, -1.43771691],
[ 1.27642283, 0.7396575 , 0.20289217]])]
结构数据
pandas的用法我们之前整理过,它对DataFrame的处理非常方便,但pandas运行的确实太慢了,如果是一些简单的DataFrame,我们可以使用numpy的结构数组来替代,同样简单方便,运行还快
>>> dt = np.dtype([('name', 'S10'), ('age', '<i4'), ('height', 'f'), ('child/adult', 'i4', 2)])
>>> data = np.array([('Jim', 20, 178, (0, 1)),('John', '5', 90, (1, 0))],dtype = dt)
>>> data
array([(b'Jim', 20, 178., [0, 1]), (b'John', 5, 90., [1, 0])],
dtype=[('name', 'S10'), ('age', '<i4'), ('height', '<f4'), ('child/adult', '<i4', (2,))])
>>> data['name']
array([b'Jim', b'John'], dtype='|S10')
>>> data['age'].mean()
12.5
数据类型的表示:
- i: 32bit的整数类型, 相当于np.int32
- f: 32bit的单精度浮点数, 相当于np.float32
- |: 忽视字节顺序
- <: 低位字节在前, 即大端序
>:高位字节在前, 即小端序- b1, i1, i2, i4, i8, u1, u2, u4, u8, f2, f4, f8, c8, c16, a
(分别对应 bytes, ints, unsigned ints, floats, complex and
fixed length strings of specified byte lengths-固定字节长度的字符串) - int8,…,uint8,…,float16, float32, float64, complex64, complex128 (这里是按位长计算bit sizes)
代码向量化
用过向量的朋友应该都知道,向量化运算,别提有多爽,不用一层一层的for循环了,python本身是不能够向量化运算的,但numpy却可以。
>>> r=np.random.standard_normal((4, 3))
>>> s=np.random.standard_normal((4, 3))
>>> s + r
array([[-1.511067 , 0.19941485, -3.34742021],
[ 1.11920413, 0.10829615, -1.79163394],
[ 0.0605728 , -0.50659722, 1.08233105],
[ 1.10578534, -1.22821669, -0.65957104]])
>>> 2*r + 3
array([[ 0.25647939, 1.50448199, 0.27938363],
[ 4.77064689, 1.03096248, -0.9815989 ],
[ 1.24174253, 3.8165197 , 3.22864982],
[ 2.63337107, 1.08923183, 0.0950697 ]])
>>> r.transpose()
array([[-1.37176031, 0.88532344, -0.87912874, -0.18331447],
[-0.74775901, -0.98451876, 0.40825985, -0.95538409],
[-1.36030818, -1.99079945, 0.11432491, -1.45246515]])
>>> np.shape(r)
(4, 3)
对于数学函数,math库是不支持向量化运算的,此时可以用numpy中的数学函数
>>> import math
>>> math.sin(r)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: only size-1 arrays can be converted to Python scalars
>>> np.sin(r)
array([[-0.98025764, -0.67999734, -0.97792904],
[ 0.77411978, -0.83300593, -0.91308767],
[-0.77018346, 0.3970128 , 0.11407603],
[-0.1822895 , -0.81653553, -0.99300703]])
>>> np.sin(np.pi)
1.2246467991473532e-16
效率提高入门
我们都知道numpy的运行速度要快很多,下面我们来直观的感受一下
import time
from functools import reduce
import random
I=5000
time_st1 = time.time()
mat=[[random.gauss(0, 1) for j in range(I)] for i in range(I)]
reduce(lambda x, y: x + y, [reduce(lambda x, y:x + y, row) for row in mat
time_end1 = time.time()
time_st2 = time.time()
mat=np.random.standard_normal([I, I])
mat.sum()
time_end2 = time.time()
print(time_end1 - time_st1)
print(time_end2 - time_st2)
> 28.042604207992554
> 1.446082592010498
可以看出,使用numpy要节省很多的时间,下面我们看为什么numpy的速度快?
效率提高进阶
python是动态类型,而非静态类型
像C这种静态类型的语言,在一开始编译器就知道所有的数据类型,按照下面的流程进行处理。
int a = 1;
int b = 2;
int c = a + b;

Python的解释器只有在运行的时候才会确定变量的类型,解释器会对每个变量进行检查,然后才进行赋值操作。

可以看出,一个简单的加法python就比C要多了好多步,这是python慢的第一个原因。
编译器(compiler)比解释器(interpreter)更快的地方在于编译器往往会把很多重复的或者没有用到的操作进行优化,在运行的时候就会更快一些。
python运行慢还有一个重要原因就是python存放数据时往往不是在连续区域,这样就导致数据的索引效率不高。而numpy则采用了C的逻辑,将np.array数据放在连续区域,提高批量数据的读写速度。
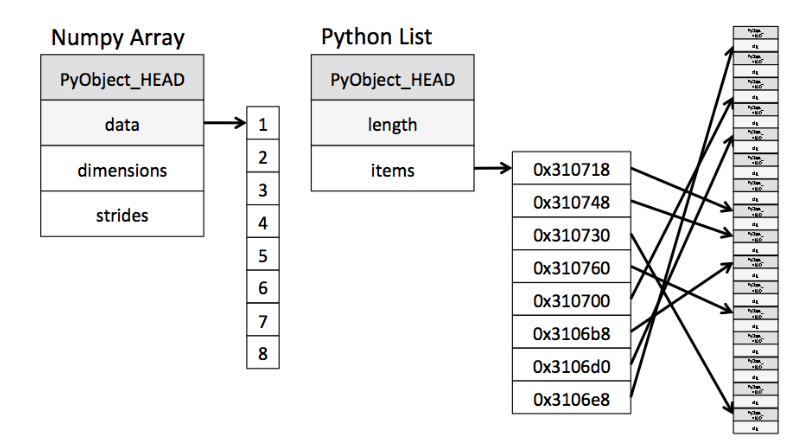
如何正确的使用numpy
知道了numpy运行快的原因了,那我们怎么使用numpy才能达到加速的效果呢?
内存数据存储形式
在np.array中我们经常会用到2D或者多维的数据,但内存中没有维度这个概念,就是存储在连续空间中。我们创建 ndArray 的方式不同, 在这个连续空间上的排列顺序也有不同,我们采用不同方式进行读写的速度也会不同,使用了numpy后发现速度没有提升,多半的原因都是因为对数据的读写方式的问题。
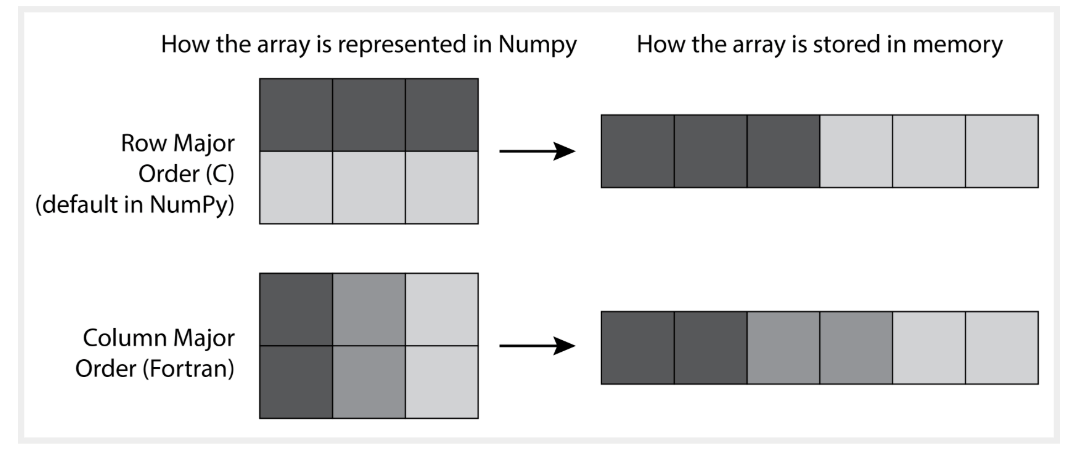
Numpy默认与C的存储方式相同,即按行排列,当然我们也可以指定numpy的内存存储方式,当存储方式确定后,再用对应的方法去读写数据,速度就会明显提升。(在.py文件中用time.time()查看运行时间时,运行一次往往不太准确,需要运行多次,看平均时间或者最小最大时间;也可以在ipython(注意是ipython,不是python console)中使用%timeit命令,可以自动给出运行多次后的最小运行时间)。下表是用%timeit统计出来的计算时间。
x1 = np.ones((5,10000000))
C1 = np.array(x,order = 'C')
F2 = np.array(x,order = 'F')
x2 = np.ones((10000000,5))
C2 = np.array(x,order = 'C')
F2 = np.array(x,order = 'F')
x3 = np.ones((1000,1000))
C3 = np.array(x,order = 'C')
F3 = np.array(x,order = 'F')
| 运行函数 | 运行时间 | 运行函数 | 运行时间 |
|---|---|---|---|
| C1.sum() | 64.2ms | F2.sum(axis=1) | 98.9ms |
| F1.sum() | 64.2ms | C2.cumsum(axis=0) | 457ms |
| C1.sum(axis=0) | 99ms | C2.cumsum(axis=1) | 290ms |
| C1.sum(axis=1) | 64.6ms | F2.cumsum(axis=0) | 257ms |
| F1.sum(axis=0) | 239ms | F2.cumsum(axis=1) | 289ms |
| F1.sum(axis=1) | 237ms | C3.sum(axis=0) | 73.3ms |
| C1.cumsum(axis=0) | 294ms | C3.sum(axis=1) | 128ms |
| C1.cumsum(axis=1) | 265ms | F3.sum(axis=0) | 128ms |
| F1.cumsum(axis=0) | 300ms | F3.sum(axis=1) | 73.6ms |
| F1.cumsum(axis=1) | 462ms | C3.cumsum(axis=0) | 5.14s |
| C2.sum(axis=0) | 239ms | C3.cumsum(axis=1) | 542ms |
| C2.sum(axis=1) | 241ms | F3.cumsum(axis=0) | 552ms |
| F2.sum(axis=0) | 64.1ms | F3.cumsum(axis=1) | 4.92s |
从运行结果可以看出,对行做运行的速度以C形式排列要快于以F形式排列,而对列做运算时,以F形式排列比C形式排列速度要快。原理也很容易理解,哪一种方式可以对内存的连续地址的数据做处理,哪一种的速度就快。当一个数据中行数明显多与列数时,对该数据的处理时C要快于F;当一个数据中列数明显多与行数时,对该数据的处理时F要快于C。
view跟copy
copy就是从内存中将数据拷贝到另一个地方,view就是直接对原始数据做处理。类似于我们前面讲的数字跟列表的区别。
>>> a = np.array([1,2,3,4])
>>> a_view = a
>>> a_copy = a.copy()
>>> a[0] = 5
>>> a_view
array([5, 2, 3, 4])
>>> a_copy
array([1, 2, 3, 4])
在numpy中,有几种结果相同但处理过程不同的操作,而这些操作的运行速度也不尽相同。
View不会复制东西,速度快,而copy则速度慢。在numpy中,a*=2是用view方式,而a=a*2则是用copy的方式。
N = 100
a = np.random.standard_normal((1000000,1))
def func1(a,N):
for i in range(N):
a = a*2
def func2(a,N):
for i in range(N):
a *= 2
t0 = time.time()
func1(a,N)
t1= time.time()
func2(a,N)
t2= time.time()
print(t1-t0)
> 0.5090291500091553
print(t2-t1)
> 0.0820047855377197
讲NpArray矩阵中的数据打平时,用ravel()要比flatten()要快,也是因为ravel()仅在需要copy的时候才会进行copy,不进行copy时会使用view的方式。
a = np.random.standard_normal((1000,1000))
%timeit a.flatten()
> 3.31 ms ± 155 µs per loop
%timeit a.ravel()
> 282 ns ± 5.02 ns per loop
选择数据
总的来说,用slice方式选择数据比用index方式更快一些。
a_view1 = a[1:2, 3:6] #
a_view2 = a[:100] #
a_view3 = a[::2] #
a_view4 = a.ravel() #
a_copy1 = a[[1,4,6], [2,4,6]] # 用 index 选
a_copy2 = a[[True, True], [False, True]] # 用 mask
a_copy3 = a[[1,2], :] # 虽然 1,2 的确连在一起了, 但是他们确实是 copy
Slice用的是view的方式,而index用的是copy方式。
Out参数
使用Out参数也可以加快程序的速度
np.add(a,1)
np.add(a,1,out = a)
np.mul(a,2,out = a)
下面的链接是所有可以使用Out参数的函数
用numpy代替pandas
链接 | 文章中提出,在数据量比较小时,pandas的效率不如numpy(在实际的使用中,会发现pandas明显比numpy要慢很多),对于一些简单的数据结构,可以使用numpy来代替pandas使用。
numpy的结构数组的用法我们上面也提到过,这里做个运算时间的对比。
aa = pd.DataFrame({'ints':[1,2,3,4], 'floats':[1.1,2.1,3.1,4.1]}, index = ['a','b','c','d'])
dt = np.dtype([('floats','f'),('ints','i4')])
bb = np.array([(1.1,1),(2.1,2),(3.1,3),(4.1,4)],dtype = dt)
%timeit aa['ints']+1
> 112 µs ± 2.03 µs per loop
%timeit bb['ints']+1
> 1.2 µs ± 68.9 ns per loop
可以看出,numpy比pandas的速度要快很多。
既然讲到了加速运算,我们就再讲一个Python中更简单的加速方式–numba
numpy是效率虽高,但使用时需要注意数据的排列方式,如果使用不当,是不会起到加速作用的。而numba的用法则更加简单直接。
numba库使用jit(just-in-time)加速python低效的for语句,前面我们提到过C比python快的一个原因是C会先编译好再运行,而jit的原理就是先编译python,让代码变得静态,从而使运行速度更快。
import numba as nb
@nb.jit
def add_nb(lst):
res = [0] * len(lst)
for i, ele in enumerate(lst):
res[i] = ele + 1
return res
lst = list(range(100000))
>>> %timeit add_nb.__wrapped__(lst) #11.9ms
>>> %timeit add_nb(lst) #5.08ms
__wrapped__是接触装饰器作用,这里的装饰器就是@nb.jit,当指定__wrapped__后,按没有jit的函数运行。
可以看出,使用了jit后速度变快。
需要注意的是:
- numba不支持list comprehension,即对于下面的函数是不能用numba加速度的。
def f():
return [x for x in range(1000)]
- jit会预编译代码,因此变量类型在某种程度上上固定的,如果上述函数想对浮点的lst进行处理,则最好写成
res=[0.]*len(lst).
如果用numpy进行操作,发现运行时间只有57us。
def add_np(np_array):
return np_array + 3
np_array = np.arange(100000)
nb中还有parallel的加速方式,但很多时候都达不到理想的效果,这里不做讲解。
Numba的jit中还有种多线程加速方式,后续我们会一一讲到。















 4167
4167

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









