







ICLR2014
OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks
ILSVRC2013 winner
本文提出了一个框架,将 图像识别、定位、检测 问题集成到一个 CNN网络中,训练该网络可以提高分类精度和 检测定位的精度。大体思路就是对第5层卷积特征池化后的特征 maps,进行滑动窗口式分类器卷积,得到每个位置的类别概率,再通过回归得到最好的矩形框大小、位置、类别概率。
1 Introduction
CNN网络提出的时间比较早了,一开始用于手写字符识别,但是在小的数据库上,CNN网络的优势并不明显。直到大型数据库 ImageNet 的建立,CNN网络的优势在这个数据库上显现出来了。
CNN网络最大的优势就是整个系统是端对端的,原始图像作为输入,最终需要的结果作为输出,不需要手工设计合适的特征提取器。但是存在的问题就是需要大量的标定数据作为训练样本。
ImageNet 分类数据库上的图像大多数含有一个位于图像中心的物体, 该物体在图像中的位置和尺寸变化比较大。解决这个问题的第一个思路就是在图像多个位置多个尺度应用CNN网络,类似滑动窗口的方法。很明显,这种方法下很多位置对应的窗口包含一小部分物体,而且不在中心位置,这导致定位和检测精度的下降。于是第二个思路就是训练一个系统,不仅对每个窗口给出一个类别概率,还给出一个位置预测及一个关于包含物体的矩形框坐标。第三个思路就是计算在每个位置和尺寸对应的每个类别的概率累积。
AlexNet 在 ImageNet2012 年的 分类和检测竞赛中都是第一名,但是在文章中作者没有说明他们在检测上是怎么做的,我们这篇文献是第一篇针对 ImageNet 数据上 检测和定位问题 CNN网络是如何工作的文献。
2 Vision Tasks
这里介绍了 三个问题: 分类、定位、检测在2013ImageNetLargeScale VisualRecognitionChallenge (ILSVRC2013) 各自的精度判断准则。


3 Classification
我们的分类网络架构类似于 AlexNet , 我们在网络的设计和推理步骤进行了改进。但是对于一些AlexNet网络的训练技巧没有深入探索。 我们的网络性能还可以被进一步提升。
3.1 Model Design and Training
我们在 ImageNet 2012 训练数据上训练我们的网络(1.2百万张图像,1000类),多尺度输入图像,采用 DropOut,具体一些参数设置看文献。
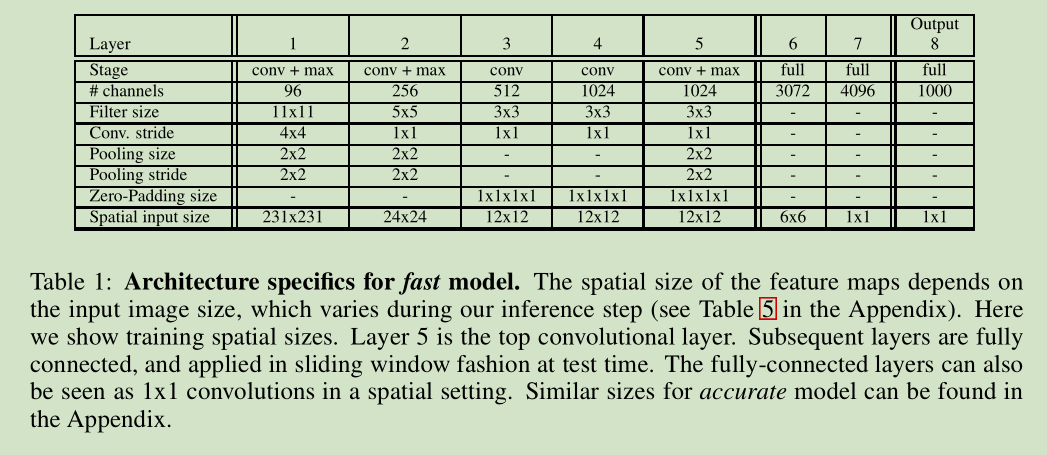
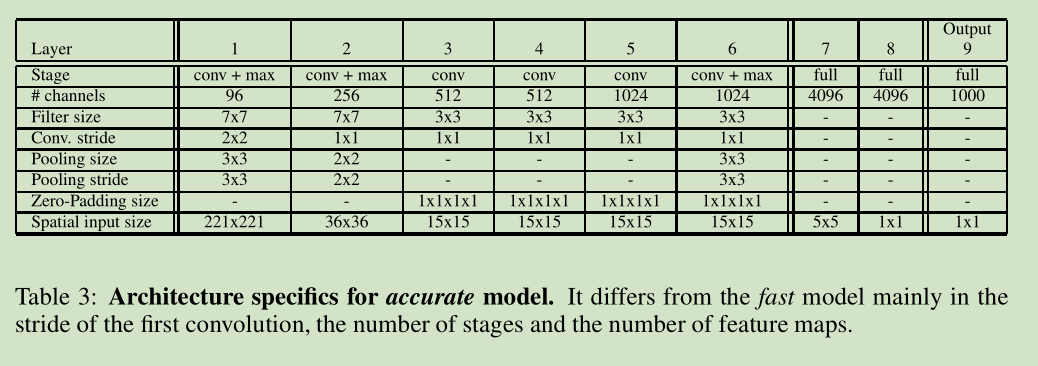
和 AlexNet 区别: 1) contrast normalization 没用,2)池化区域不重叠,3)我们模型的第一层和第二层的 feature maps 要大,因为 用了一个小的步长, stride=2。 打的步长速度快,但是精度会低。
3.2 Feature Extractor
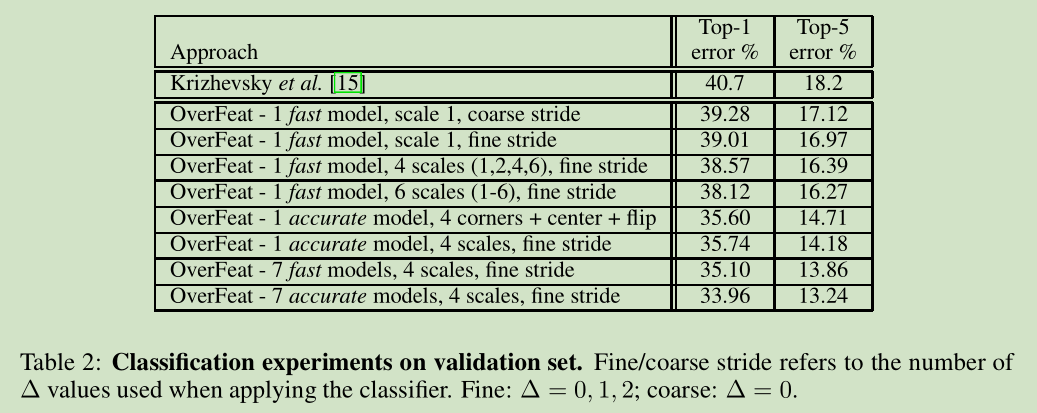
伴随这篇文献,我们在网上发布了一个 特征提取器叫 “OverFeat”以便大家后续研究。有两个模型提供,一个更快些,一个精度更高些。两者之间有一些对比参考图表。
3.3 Multi-Scale Classification
文献【15】 AlexNet 中通过 data agumentation 获得不同视角来投票提升性能。(10个固定角度,一个中心,4个角,一共5组数据,再水平镜像,10组数据)。但是这么做会导致忽略图像大部分区域,当视角重叠计算就变得冗余。此外只计算一个尺度,那么这个尺度对应的概率可能不是最优的。
和 AlexNet 采取的上面策略不一样,我们在整个图像密集运行CNN网络,每个位置对应不同尺度。对于某些模型,滑动窗口式方法因为计算量太大导致不可行,但是对于CNN网络却具有内在的高效(3.5节将会说明)。这种方式可以用更多的视角来投票,从而在保持速度的前提下提高鲁棒性。对一幅任意尺寸图像卷积 ConvNet 的结果就是对应一个尺度生成一个 spatial map, 每个点是一个 C 维向量, 对应C类的概率。
但是,网络整体的下采样率是 2*3*2*3=36。 所以输入图像36个像素对应输出中的一个点,该点含有 C维向量。这种粗糙的输出分布降低了系统性能,相对于 AlexNet 的10个视角,因为网络滑动窗口和图像中的物体没有很好对应上。当网络滑动窗口和物体很好的对应上,给出的网络响应就很强。为了解决这个问题,我们采用了类似文献【9】中的方法, apply the last subsampling operation at every offset,这样总的降采样就是12倍而不是36倍。
下面我们来详细说说怎么将降采样从36变为12。我们使用6个尺度对应不同尺寸 第5层卷积特征,没有池化,经过下面的步骤处理,最后输入分类器。
(a)对于一幅图像,给定尺度,我们开始于没有池化的第5层卷积特征 maps
(b)对于每个为池化 maps,我们使用 3*3 最大池化操作,不重叠区域,重复 3*3次,x,y方向分别平移像素位置{0,1,2}
(c)这样我们就得到一组池化 feature maps, 每个位置对应3*3个,即一个为池化 feature map 对应3*3个池化后的 feature maps。
(d)网络分类器(第6,7,8层)的输入尺寸是固定的 5*5,在池化后的 featue maps 每个位置上产生一个 C 维向量输出。分类器在 池化后的 maps 上按滑动窗口式进行应用,产生 C维向量输出 maps
(e)针对前面池化时的平移,我们得到对应的输出 maps,将其组合成一个 3D 输出 maps。
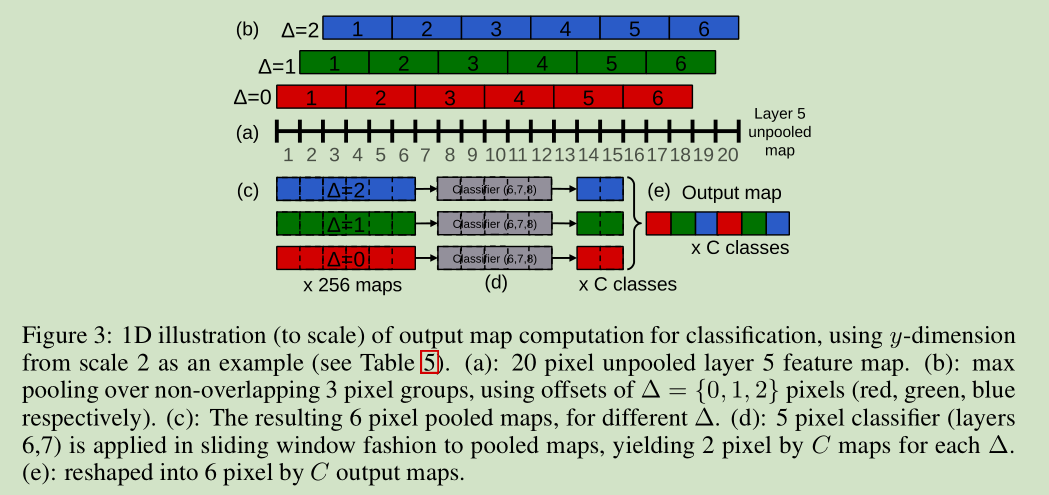
其实就是对第5卷积层输出的 特征进行 滑动窗口式的分类器(6-8层)运算,得到较多分类结果,再通过投票决定最后的结果。
降采样从36变为12关键就是 x,y方向分别平移像素位置{0,1,2}
3.5 ConvNets and Sliding Window Efficiency
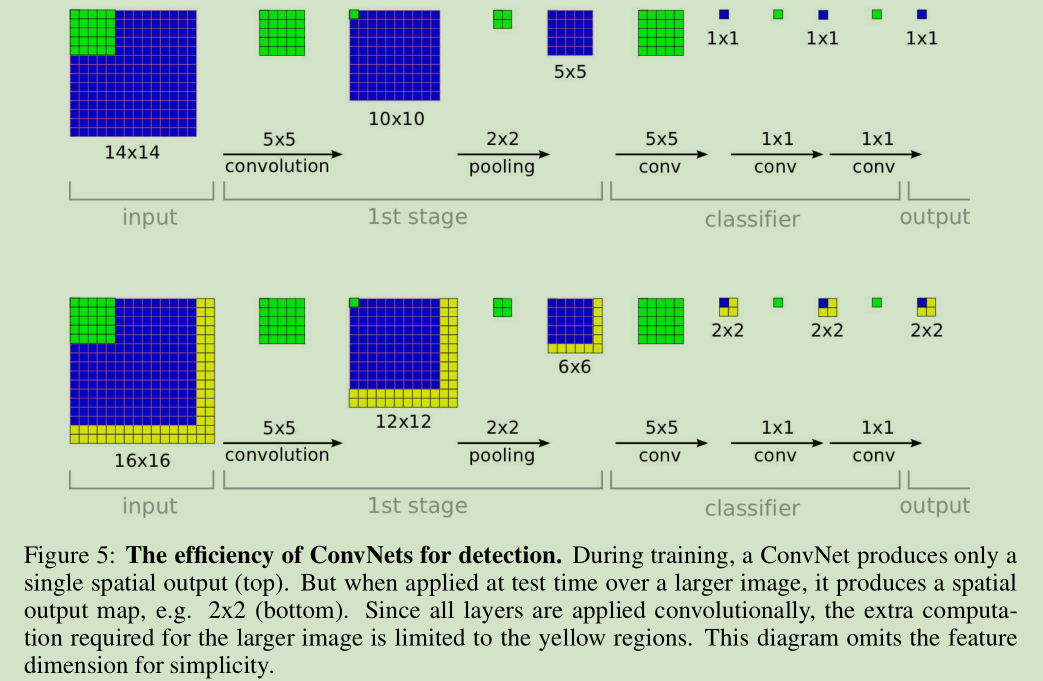
图5 上面是训练对应的计算, 下面是对应检测的计算。图像黄色区域是滑动窗口对应多计算的部分
4 Localization
针对定位问题,我们从训练好的分类网络开始,将分类器层替换为一个回归网络,训练它输出每个位置和尺度对应物体矩形框坐标。我们将这个回归位置预测和每个位置分类结果结合起来。
将第5层卷积特征池化后输入回归网络,按滑动窗口式计算每个位置,输出每个位置的类别概率,然后通过回归得到一个最好的矩形框。




回归网络矩形框示例:

















 211
211











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









