









Recurrent Scale Approximation for Object Detection in CNN
ICCV2017
https://github.com/sciencefans/RSA-for-object-detection
本文还是针对人脸检测 中的 尺度问题 进展展开的。主要内容有以下三点:
1)首先使用一个 scale-forecast 网络来进行图像中人脸尺度的预测,
2)设计一个 recurrent scale approximation (RSA),使用 RSA 模块来 生产预测到尺度所对应的特征图,
3)提出一个 landmark retracing network (LRN),使用人脸局部特征信息来去除虚警。
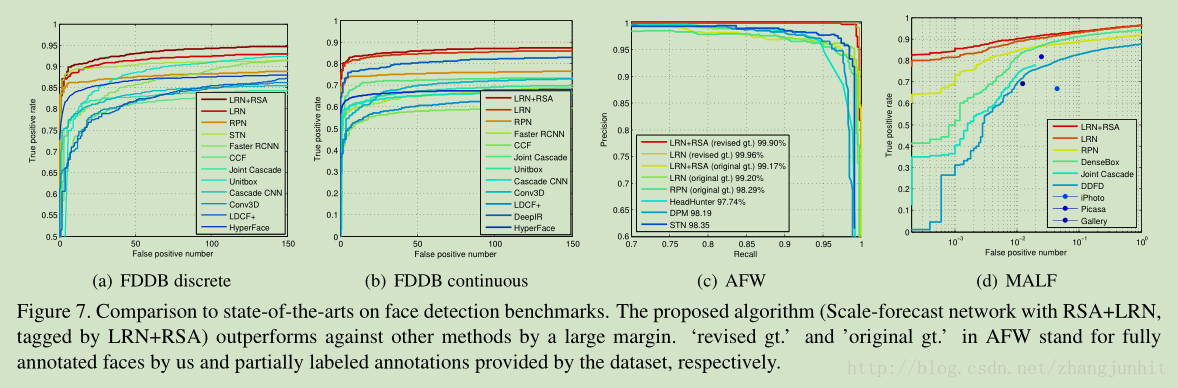
对于多尺度问题 的三个解决方案如下图所示
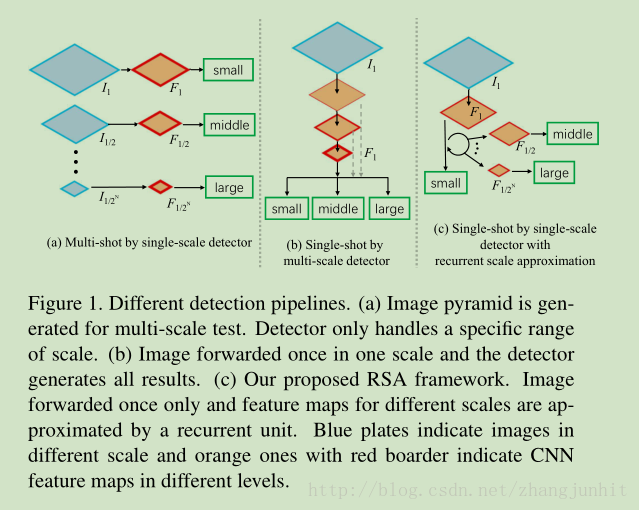
Multi-shot by single-scale detector 单尺度检测器对应 多尺度输入图像 得到不同尺度目标
Single-shot by multi-scale detector 多尺度检测器 对应 单尺度输入图像 得到不同尺度目标
本文的策略是直接将图像中目标的尺度检测出来,在知道尺度的情况下进行目标检测
3.1. Scale-forecast Network
The network is a half-channel version of ResNet-18 with a global pooling at the end
Scale-forecast Network 采用 ResNet-18 的一半通道,最后使用 global pooling,
输出是一维向量, B 个 dimensions ,B = 60 is the predefined number of scales
通过公式将人脸框的长度映射到 一个直方图的 bin 中,直方图 bin 的数目是 B=60,
接着我们使用 Gaussian mixture model 来拟合该 直方图向量 来得到 我们想要的人脸尺度, 6个高斯对应 six main scales
determine the local maximum and hence the potential occurring scales
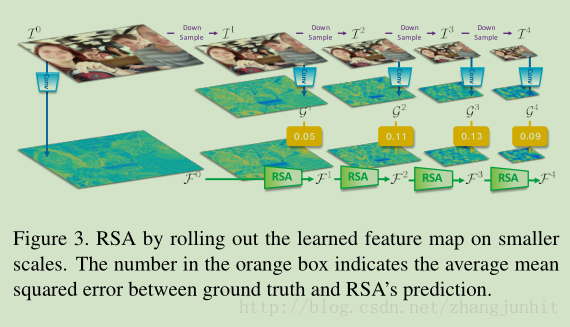
3.2. Recurrent Scale Approximation (RSA) Unit
使用 RSA 由最大尺寸的特征图得到我们期望的 尺寸的特征图
3.3. Landmark Retracing Network
这里主要使用人脸中的局部特征信息 Landmark 来去除检测中的 虚警
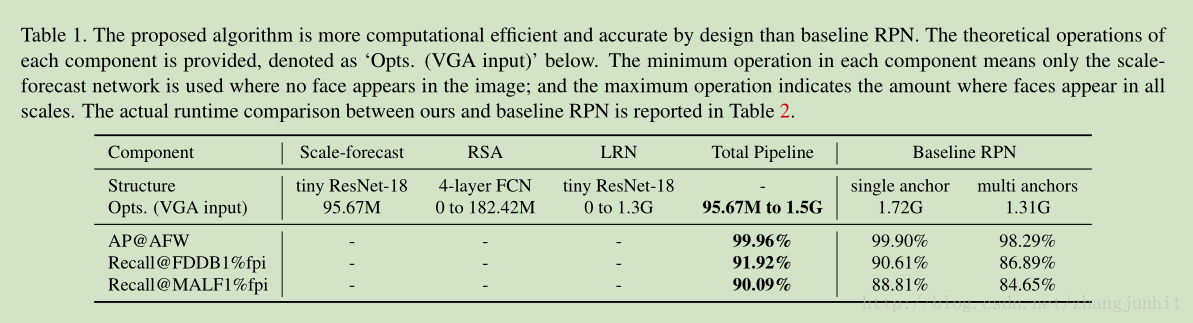
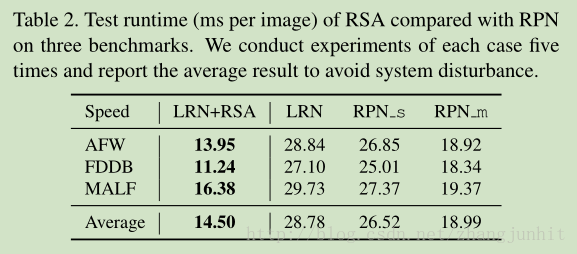



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









