






GAN
GAN的提出,从生成模型(机器学习的一大分支)来说,为非显式地拟合生成模型开辟了一条新路;从监督/半监督学习的角度来说,深度学习解放了人工设计特征,而对抗学习解放了人工设计优化目标(损失函数)。Yann LeCun对于GAN的评价非常之高,不是没有道理的。
作为开山之作,关注
1. 解决的问题(重要,学习作者提问题的能力);
2. 形式化的表达(重要,学习作者提炼表达的能力);
3. 具体的操作(不是很重要,开山之作一般不会有完美的工程实现);
4. 评价流程(重要,为后来工作定标尺)。
1. focus
深度生成模型面临的两个问题:
1. MLE(Maximum Likelihood Estimation,极大似然估计)过程中大量的不可解问题;
2. 分段线性函数(比如ReLU)等不适用于生成模型。
2. formulation
面对这两个问题,Goodfellow等人提出对抗生成网络(Generative Adversarial Nets,简称GAN)[文献1]。
记分类器为
D
,生成器为
对应于生成器,其优化目标为:
在刚刚开始训练的时候,生成器很弱,上述目标容易饱和,因此优化目标是:
3. solution
完整的训练过程如下:

注意到,训练分类器
D
和生成器
4. evaluation
采用概率密度估计的方法,即对数似然。这里涉及用pazen窗对概率密度进行估计。
值得注意的是,由于pazen窗方法本身在高维空间表现不佳,这种指标并非完全公允。CGAN[文献2]的这个指标较差,然而其作者仍然认为他们的performance是“comparable”的,从这个角度看不算是强辩。
论文的最后指出了改进的5个方向,不愧为开山之作:
第一,将条件变量加入
G,D
,建立条件生成模型
p(x|c)
——>这条建议直接催生了CGAN[文献2]论文
第二,
第三,
第四,半监督学习:当标签数据有限时,分类或者推理网络学习到的特征可以帮助提高分类性能;
——>这条建议在DCGAN[文献3]的实验有所体现
第五,效率提升:使用更好的方法协调
G,D
的训练,或者使用更好的分布采样
z
;
——>这条建议催生了
注:原始GAN论文的相关证明较为简单,而且流于理论,对于实际训练没有什么帮助,但却是后面工作改进的突破口。
注1:固定
Proof.
对于 D(x) 的求导容易得到第一部分结论;此时,
注意到最后两项其实是实际数据分布和生成模型分布之间的JS散度(确切来说是JS散度的两倍)。因为JS散度的非负性,并且在两个分布相等的情况下达到最小值为0,故后两部分得证。
注2:在 G,D 有足够的模型复杂度,并且更新量足够小的情况下,模型收敛。
原始GAN提出之后,很多工作对其进行了改进,其中有的是从单一改进方向进行,有的则跨了几个改进方向。改进方向就可以大致分为:提供局部的指导信息;
Partial Guidance
1. CGAN
条件GAN论文给出的方式简单粗暴,虽然效果不是很好,但是紧跟在原始GAN之后,实现了在类别信息(label)或者标签信息(tag)的指导下的GAN。另外,论文将CGAN延伸到多模态应用下。而且论文的Acknowledge特别提及了Goodfellow在蒙特利尔大学访学时候参与讨论了本文的工作。以上是其能够中的一些原因。
其目标函数较为简单:
对 G ,
y 和 z 共同映射到隐藏层的表示。具体做法就是直接拼接,比较粗暴,这是因为对抗网络对如何形成隐藏层的表示是较为宽松的。
值得注意的是,作者在脚注中也提到了:这里简单地用MLP将条件输入和先验噪声囊括,如果建模更高阶的交互将会得到更为复杂的生成机理,从而吊打传统的生成模型。原文为:For now we simply have the conditioning input and prior noise as inputs to a single hidden layer of a MLP, but one could imagine using higher order interactions allowing for complex generation mechanisms that would be extremely difficult to work with in a traditional generative framework.
对
D , y 和x 共同输入。
一些想法:
1. 判别器只以
x
为输入(因为类别信息不影响图像的真伪);
2. 再加上辅助的分类器
3. 分类器固定,不然容易拒绝识别真样本。
如何验证:pazen窗对数似然估计的统计结果;训练过程中假样本正确识别率随着
G
<script type="math/tex" id="MathJax-Element-445">G</script>更新的变化曲线;MLP或者DCGAN的架构下,上述二者均超越原目标函数。
2. DCGAN与LAPGAN
LAPGAN[文献4]采用逐层加入新生成的高频信息的架构,因为Laplacian金字塔(通俗简练的说法是,Laplacian金字塔的每一层是Gaussian金字塔相邻两层之差。严格来说,Gaussian金字塔上层尺寸为下层的1/4,因此要先进行近邻插值的上采样才能计算二者之差)也采取相同结构,因此得名。
训练过程和生成过程对称。训练过程从尺寸最大的原图出发,训练生成的图片频率越来越低,生成过程从尺寸最小的生成样本出发,用于合成的图片频率越来越高。
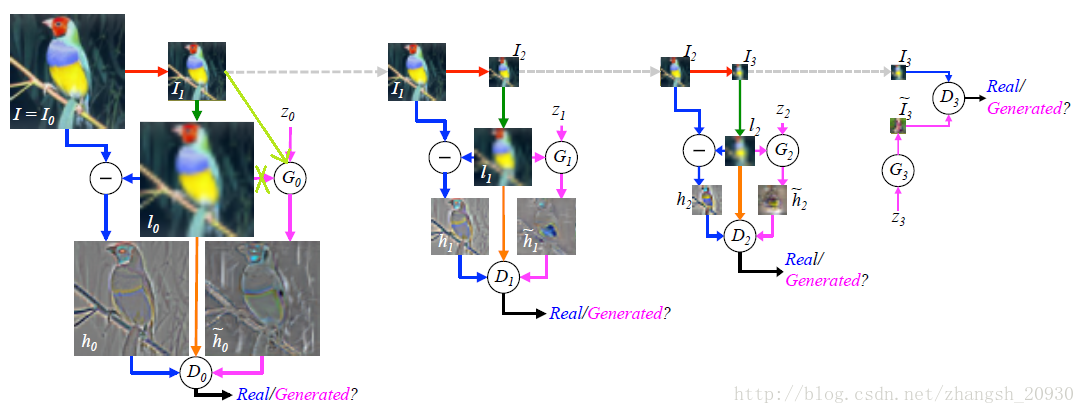
注意到,这里采用了CGAN的模型做训练。其中条件信息就是低频图像进行近邻插值的上采样得到的图像(就是模糊的那个),其作为条件信息在生成器和判别器中都得到了应用。
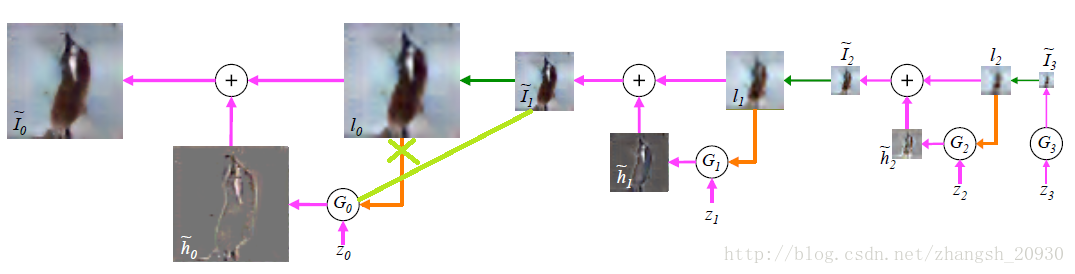
一些想法:(见上面两张图中浅绿色的线,各层同理省略)
在计算真实数据高频信息的时候,图像上采样是必要的,但是在生成高频信息的时候,上采样非必要。第一,直接以下采样图片和噪声输入可以减少参数数量;第二,上采样是“硬操作”,不可训练。
顺便地,因为生成器的条件信息改变了,判别器的条件信息相应改变,同样可以减少参数数量。如若不然,生成器和判别器的条件将有差别,而调研中没有发现相关工作。
另外,看不出加入高频信息的必要性,后面有些工作是从低维图片生成高维。















 11万+
11万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











