







 本文详细介绍了AdaBoost算法的原理,包括其起源、目标和优化方法。 AdaBoost通过多次迭代,结合弱分类器形成强分类器。在OpenCV2.4.9中, AdaBoost实现包括Discrete、Real、Logit和Gentle四种类型,弱分类器通常采用决策树。文章还探讨了不同类型的AdaBoost算法的迭代过程和参数设置,并指出OpenCV推荐使用GentleAdaBoost或Real AdaBoost。
本文详细介绍了AdaBoost算法的原理,包括其起源、目标和优化方法。 AdaBoost通过多次迭代,结合弱分类器形成强分类器。在OpenCV2.4.9中, AdaBoost实现包括Discrete、Real、Logit和Gentle四种类型,弱分类器通常采用决策树。文章还探讨了不同类型的AdaBoost算法的迭代过程和参数设置,并指出OpenCV推荐使用GentleAdaBoost或Real AdaBoost。
一、原理
AdaBoost(Adaptive Boosting,自适应提升)算法是由来自AT&T实验室的Freund和Schapire于1995年首次提出,该算法解决了早期Boosting算法的一些实际执行难题,而且该算法可以作为一种从一系列弱分类器中产生一个强分类器的通用方法。正由于AdaBoost算法的优异性能,Freund和Schapire因此获得了2003年度的哥德尔奖(Gödel Prize,该奖是在理论计算机科学领域中最负盛名的奖项之一)。
假设我们有一个集合{(x1, y1),(x2, y2), …, (xN,yN)},每一个数据项xi是一个表示事物特征的矢量,yi是一个与其相对应的分类yi∈{-1, 1},即xi要么属于-1,要么属于1。AdaBoost算法通过M次迭代得到了一个弱分类器集合{ k1, k2,…, kM},对于每一个数据项xi来说,每个弱分类器都会给出一个分类结果来,即km(xi)∈{-1, 1}。这M个弱分类器通过某种线性组合(式1所示)就得到了一个强分类器Cm,这样我们就可以通过Cm来判断一个新的数据项xk是属于-1,还是1。这就是一个训练的过程。
在进行了第m-1次迭代后,我们可以把这m-1个弱分类器进行线性组合,所得到的强分类器为:
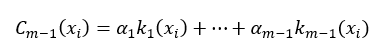
式中,α为k的权值,并且m > 1。当进行第m次迭代时,AdaBoost就通过增加一个弱分类器的方式扩展成另一个的强分类器:
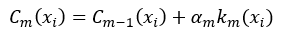
只有使Cm的分类结果强于Cm-1,算法迭代才有意义。那么如何能够使Cm的性能优于Cm-1呢?这就由增加的那个第m个弱分类器km及其它的权值αm来决定。我们用所有数据项xi的指数损失的总和来定义Cm的误差E,从而判断km和αm是否为最优,即:
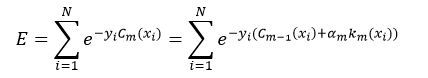
令 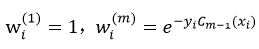
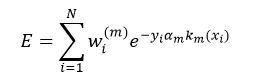
我们可以把上式拆分成两项:
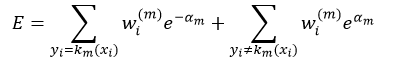
式中,yi=km(xi)的意思是对xi来说,第m次迭代得到的弱分类器km的分类结果与其实际的分类y相同,要么都等于-1,要么都等于1,即分类正确,所以它们的乘积一定等于1,即yi km(xi)= 1;而yi≠km(xi)的意思是对xi来说,第m次迭代得到的弱分类器km的分类结果与其实际的分类y不相同,其中一个如果等于-1,那么另一个一定等于1,即分类错误,所以它们的乘积一定等于-1,即yi km(xi)= -1。所以式5中的前一项表示的是对所有y等于km的那些数据项xi的误差求和;而第二项表示的是对所有y不等于km的那些数据项xi的误差求和。我们又可以把式5写出如下形式:
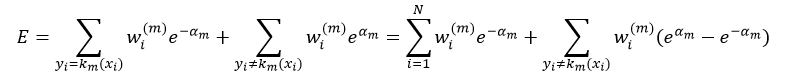
从上式我们可以看出,如果αm一定的话,强分类器Cm的误差大小完全取决于第二项中的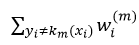
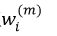
为了使误差E最小,我们需要对式5进行求导:
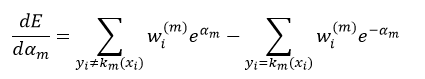
令上式等于0,则权值αm为:
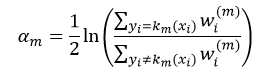
令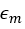
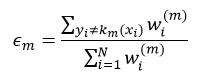
则式8为:
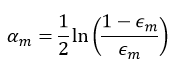
经过以上分析,我们导出了AdaBoost算法:在每次迭代中,我们选择使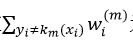
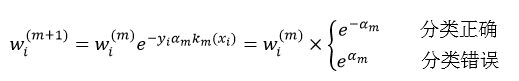
需要说明的是,权值仍然可以按照前面介绍的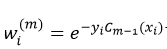
基于以上的分析,我们给出AdaBoost的计算步骤:
1、设有n个样本x1, …, xn,它们所希望得到的输出(即分类)为y1, …, yn,y∈{-1, 1};
2、初始化每个样本的权值 
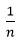
3、进行迭代:m = 1, …, M
①找到使误差率
②计算km(x)的权值αm(式10);
③得到新的强分类器Cm(x)(式2);
④更新每个样本的权值wi(m+1)(式11);
⑤对权值wi(m+1)进行归一化处理,使∑iwi(m+1)= 1;
4、得到最终的强分类器

从式12可以看出,强分类器是由权值αm和弱分类器km(x)决定的。权值αm由式10计算得到,而弱分类器可以用上一篇文章介绍的决策树的方法得到,那种最简单的、每个中间节点只能被分叉为左、右两个分支(stumps)的决策树就足以完成对弱分类器的设计。也就是说,每一个弱分类器就是一个决策树,而该决策树是由加权后的样本构建而成,由于每次迭代的权值wi(m)不同,所以每次迭代所构建的决策树也是不同的。当要应用AdaBoost预测样本x时,只要把该样本带入不同的决策树(即弱分类器)进行预测即可,预测的结果就是km(x),然后应用式12把不同的决策树的预测结果进行加权和,最后判断其符号。OpenCV就是采用的这种方法。当用决策树的形式的时候,权值αm的计算公式为:
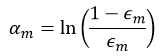
而每个训练样本数据的权值wi(m+1)则为:
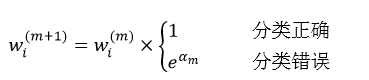
AdaBoost算法可分为DiscreteAdaboost,Real AdaBoost,LogitBoost和Gentle AdaBoost。前面我们给出的是Discrete Adaboost算法的原理和计算步骤。虽然这四种算法的基本结构相似的,但彼此之间还是有一些差异。Discrete AdaBoost的每个弱分类的输出结果是1或-1,在组成强分类器的过程中,这种离散形式的弱分类器就略显粗糙。而Real Adaboost的每个弱分类器输出是该样本属于某一类的概率,即弱分类器km是通过一个对数函数将0-1的概率值映射到实数域,sign(km)给出的是一个分类,而|km|给出的就是一个置信度的度量。Real Adaboost的迭代过程为:
①基于每个样本的权值wi(m),拟合一个分类概率估计pm(x)=P(y=1|x)∈[0,1],它表示样本属于分类结果为1的概率;
②得到该次迭代的弱分类器km(x):
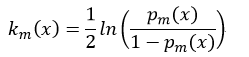
③更新权值wi(m+1):
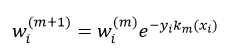
④归一化权值使∑iwi(m+1)= 1。
则最终的强分类器C为:
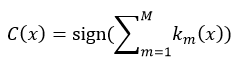
LogitBoost算法是逻辑回归技术在AdaBoost的应用,弱分类器的选取并不是基于分类结果yi,而是基于加权最小二乘法。设迭代之前强分类器C0(x) = 0,每个训练样本数据的概率估计p0(xi) = 0.5,则LogitBoost算法的迭代过程为:
①计算工作响应zi(m):
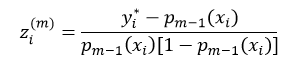
式中
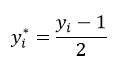
②计算权值wi(m):
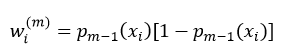
③应用权值wi(m),基于从zi(m)到xi的加权最小二乘法回归方法,拟合弱分类器km(x);
④更新pm(xi):
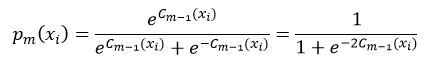
⑤更新强分类器
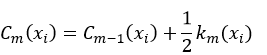
最终的强分类器为式17。
Gentle AdaBoost算法与LogitBoost算法相似,但参数的选择上更简单。弱分类器km(x)是由基于权值wi(m)的从yi到xi的加权最小二乘法的回归拟合得到。每次迭代得到强分类器Cm(x)和权值分别wi(m+1)为:
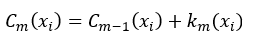
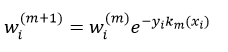
这里的权值仍然需要进行归一化处理。强分类器仍然为式17。
OpenCV实现了上述四种类型的AdaBoost,并且弱分类器都是采用CART决策树的方法,其中DiscreteAdaboost和Real AdaBoost应用的是分类树,因为它们的分类结果是类的形式,而LogitBoost和Gentle AdaBoost应用的是回归树,因为它们的分类结果是数值的形式。
二、源码分析
下面我们就给出OpenCV的源码分析。
我们先看构建Boosting的参数:
CvBoostParams::CvBoostParams()
{
boost_type = CvBoost::REAL;
weak_count = 100;
weight_trim_rate = 0.95;
cv_folds = 0;
max_depth = 1;
}
CvBoostParams::CvBoostParams( int _boost_type, int _weak_count,
double _weight_trim_rate, int _max_depth,
bool _use_surrogates, const float* _priors )
{
boost_type = _boost_type;
weak_count = _weak_count;
weight_trim_rate = _weight_trim_rate;
split_criteria = CvBoost::DEFAULT; //分叉准则,即用什么方法计算决策树节点的纯度
/*****************************
CvBoost::DEFAULT为特定的Boosting算法选择默认系数
CvBoost::GINI使用基尼指数,这是Real AdaBoost的默认方法,也可以被用于Discrete Adaboost
CvBoost::MISCLASS使用错误分类率,这是Discrete Adaboost的默认方法,也可以被用于Real AdaBoost
CvBoost::SQERR使用最小二乘准则,这是LogitBoost和Gentle AdaBoost的默认及唯一方法
******************************/
cv_folds = 0; //表示构建决策树时,不执行剪枝操作
max_depth = _max_depth;
use_surrogates = _use_surrogates;
priors = _priors;
}
其中参数的含义为:
boost_type表示Boosting算法的类型,可以是CvBoost::DISCRETE、CvBoost::REAL、CvBoost::LOGIT或CvBoost::GENTLE这4类中的任意一个,OpenCV推荐使用GentleAdaBoost或Real AdaBoost算法
_weak_count表示弱分类器的数量,即迭代的次数
_weight_trim_rate表示裁剪率,在0~1之间,默认值为0.95,在迭代过程中,那些归一化后的样本权值wi(m)小于该裁剪率的样本将不进入下次迭代
_max_depth表示构建决策树的最大深度
_use_surrogates表示在构建决策树时,是否使用替代分叉属性
_priors
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 883
883

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









