






逻辑回归:
线性回归的式子作为输入 解决二分类问题 能够得出概率值
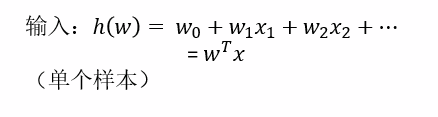
sigmoid函数:


损失函数:
均方误差:(不存在多个局部的特点)只有一个最小值
对数似然损失:(有多个局部最小值)目前解决不了的问题
其他代替解决方法:1、随机初始化,多次比较最小值结果;2、求解的过程中,调整学习率 这两种方法只能改善,但是不能彻底解决,尽管没有全局的最低点,但是局部最低点还是可以的
采用梯度下降优化求解

API:sklearn.linear_model.LogisticRegression

案例分析:
1、网上获取数据
2、数据缺失值处理、标准化
3、LogisticRegression估计器流程
LogisticRegression总结:
应用:广告点击率预测、电商购物搭配推荐
优点:合适需要得到一个分类概率场景
缺点:当特征空间很大是,逻辑回归的性能不是很好
逻辑回归(判别模型):
解决问题:二分类
应用场景:适合所有的二分类问题
参数:正则化力度
朴素贝叶斯(生成模型):
解决问题:多分类问题
应用场景:一般用于文本分类
参数:没有
相同点:得出的结果都有概率的解释
生成模型和判别模型:是否具有先验模型
非监督学习算法:
物以聚类,人以群分
把相近特征的数据归为一类
分为多少类用k进行表示,不知道类别数则为超参数
k-means 步骤:
1、随机在数据当中抽取三个样本,当做三个类别的中心点(k1,k2,k3)
2、计算出其余的点到这这三个中心点的距离,从中选出距离最近的一个点作为自己的标记形成三个族群
3、分别计算这三个族群的平均值,把三个平均值与之前的三分旧中心点进行比较,如果相同:聚类结束,如果不相同:把这三个平均值当做新的中心点,重复第二步骤
API:sklearn.cluster.KMeans

聚类评估标准:
轮廓系数:
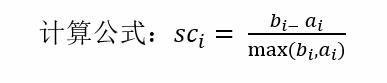

外部距离最大化、内部距离最小化

API:sklearn.metrics.silhouette_score

k-means总结:
特点分析:采用迭代算法,直观易懂非常实用
缺点:容易收敛到局部最优解(多次聚类),需要预先设定簇的数量(k-means++解决)















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









