






线性回归:
定义:线性回归通过一个或者多个自变量与因变量之间进行建模的回归分析。其中特点为一个或多个称为回归系数的模型参数的线性组合,称为迭代的算法
一元线性回归:涉及到的变量只有一个
多远线性回归:涉及到的变量两个或两个以上
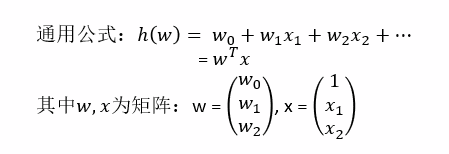
回归:可以无限去划分,目标值属于连续的问题 函数
分类:离散型类似于散点图,序列
回归解决的问题:房价预测、销售额预测、贷款额度预测
线性关系:
二维图像中呈现一条直线
三维中:数据基本在一个图面上
线性关系模型:通过一个属性组合来预测的函数
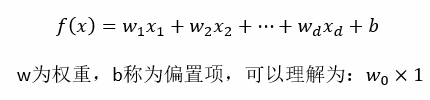
对于多个特征:采用加权的方式表示
损失函数:(误差)
yi为第i个训练样本的真实值
hw(xi)为第i个训练样本特征值组合预测函数
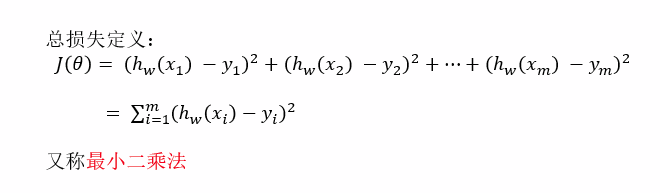
如何求解模型当中的w,使得损失最小
优化迭代,求出最优的w值
方法:
1、最小二乘法之正规方程:
API:sklearn.linear_model.LinearRegression

2、最小二乘法之梯度下降(常用):
API:•sklearn.linear_model.SGDRegressor

scikit-learn:
优点:封装比较好,建立模型比较简单,预测简单
缺点:算法的过程,有些参数都在算法API内部优化中
tensortflow:封装低,可以修改学习率
案例分析(线性回归):
1、获取数据
2、数据分割
3、训练数据与测试数据标准化
4、使用最简单的线性回归模型LinearRegression和梯度下降估计SGDRegressor进行预测
from sklearn.datasets import load_boston
from sklearn.linear_model import LinearRegression, SGDRegressor
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
import numpy as np
def mylinear():
#获取数据
lb = load_boston()
#分割数据集
x_train, x_test, y_train, y_test = train_test_split(lb.data, lb.target, test_size=0.25)
#进行标准化处理 目标值也需要标准化
std_x = StandardScaler()
x_train = std_x.fit_transform(x_train)
x_test = std_x.transform(x_test)
#目标值
std_y = StandardScaler()
y_train = std_y.fit_transform(y_train.reshape(-1,1))
y_test = std_y.transform(y_test.reshape(-1,1))
#estimator预测
#正规方程求解方式预测结果
lr = LinearRegression()
lr.fit(x_train,y_train)
print(lr.coef_)
#预测测试集房子价格
y_predict = lr.predict(x_test)
print("测试集每个房子的预测价格:", y_predict)
#梯度下降来预测房子价格
sgd = SGDRegressor()
sgd.fit(x_train, y_train)
print(sgd.coef_)
# 预测测试集房子价格
y_sgd_predict = std_y.inverse_transform(sgd.predict(x_test))
print("测试集每个房子的预测价格:", y_sgd_predict)
return None
if __name__ == "__main__":
mylinear()回归性能评估:
均方误差(Mean Squared Error)评价机制:
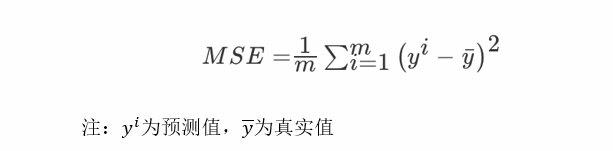
梯度下降与正规方程对比:

LinearRegression与SGDRegressor评估:
特点:线性回归是最为简单、易用的回归模型,从某种程度上限制了使用,在不知道特征关系的前提下,使用线性回归器是首要选择
小规模数据:LinearRegression(不能解决过拟合问题)
大规模数据:SGDRegressor
欠拟合与过拟合:
欠拟合:一个假设在训练数据上不能获得更好的拟合, 但是在训练数据外的数据集上也不能很好地拟合数据,此时认为这个假设出现了欠拟合的现象。(模型过于简单)
原因:学习到的数据特征较少
解决方法:增加数据的特征数量
过拟合:一个假设在训练数据上不能获得更好的拟合, 但是在训练数据外的数据集上也不能很好地拟合数据,此时认为这个假设出现了欠拟合的现象。(模型过于简单)
原因:原始特征较多,存在嘈杂特征,模型过于复杂是由于模型尝试兼顾各个测试数据点
解决方法:
1、进行特征选择,消除关联性大的特征(较为困难)
2、交叉验证(让所有数据都有过训练)
3、正则化(了解)
正则化:
减少高次项特征值权重,减少特征影响,接近于0
越小的参数越简单,越简单的模型越不容易过拟合
L2正则化:
Ridge:岭回归
自带正则化的线性回归 解决过拟合
API:sklearn.linear_model.Ridge


线性回归 LinearRegression与Ridge对比:
岭回归:回归得到的回归系数更符合实际,更加可靠,另外,能让估计参数的波动范围变小,变得更加稳定。在存在病态数据偏多的研究中有较大的实用价值
特征选择:
1、过滤式:低方差特征
2、嵌入式:正则化、神经网络、决策树
欠拟合与过拟合通过交叉验证训练集的结果来观察:两者表现不好,误差较大
线性关系:简单模型(系数)
非线性关系:复杂模型(系数)(数据的特征和目标值之间的关系不仅仅是线性关系)
模型的保存和加载:
API:from sklearn.externals import joblib
保存:joblib.dump(rf,'test.pkl')
加载:estimator = joblib('test.pkl')
文件保存的固有文件格式为pkl















 801
801











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









