







前言
在上一篇文章之中,我们提到了最原始的NLP结构:RNN,以及为了解决其现阶段存在的一些问题所推出的改进版本:GRU和LSTM两个结构。到了GRU这一部分,看上去似乎在表面上,这个模型已经没有什么可以改进的了,直到Transformer的提出和注意力机制的应用。我们发现,从另一个角度突破,达成的效果相比之前产生了质的飞跃。
引子:注意力(attention)机制
1.从Seq2Seq应用场景指出注意力机制的诞生意义:
注意力机制诞生于实际的运用中遇到的一个问题,下面的例子是一个实际运用:
Seq2Seq,也就是输入的是一段文本,输出的也是一段文本的形式生成文本内容。
场景:给出一句有t-1个词语的未完成的句子,预测第t个词语(Seq2Seq)
没有注意力机制的情况:
参数解析:
h:Encoder中的输入的语句的句子内容
x:在Encoder阶段即将输入的词语
c:包含了句子全部内容的要传给Decoder模型的信息
s:输出阶段,综合考虑了Encoder部分输入的句子内容c,和Decoder部分输入的语句信息得到的,综合考虑了全部Encoder信息和Decoder部分部分输入信息产生的矩阵信息

对于产生每一个词语的时候,输入的原来语句的信息都是不变的,这就没有了针对性,相当于做阅读理解时回答每一个问题都把整个文章重新读一遍,其准确性肯定不如先定位问题所在位置再阅读精确。我们现在就要通过模型本身的调整,使得其每一次获取文章内容的时候,都是有针对性的。
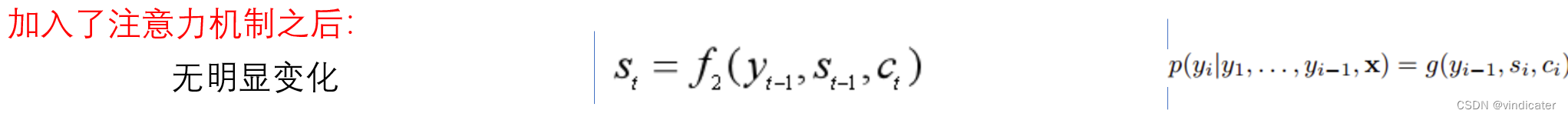
与上面的对比发现,主要的差别是每一次得到包含着句子前T个词语的信息的句子S_t的意义的时候, 采用的关于Encoder部分的内容c不再是一个恒定不变的C,而是一个针对于每一个在decoder部分中输入的词语得到一个对应的Encoder的输入语句意思C_t。
增加了不同的解读方式下的含义矩阵,有助于对于每一个词语得到更好的预测结果。
2.Attention机制的具体操作:
(1)模型图示:
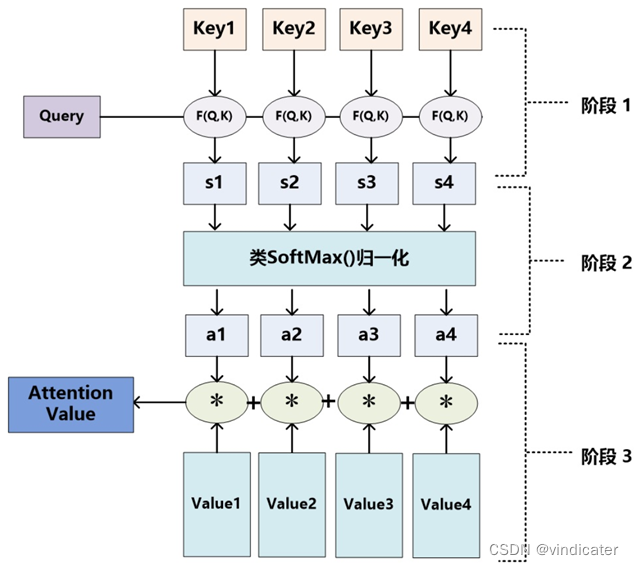
(2)参数解析:
在注意力机制中,对于一个词语,其被赋予了两个向量用来表示:分别是Key向量和Value向量。
其中Key向量最根本的目的是储存词语的表层信息,其是用来和要判断的向量做内积得到相关性的。
而Value向量更多是用来储存词语的语义信息,其是语句含义矩阵C的直接组成部分。
(3)计算公式&公式解析:
阶段1:

1.通过函数F对查询向量Q和第i个词语key向做运算得出相关度s。先前案例把前t-1个向量处理结果s作为Q输入通过注意力机制得到和s有关的原文内容c。
阶段2:
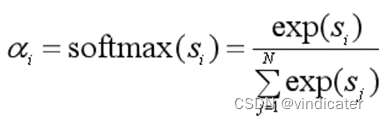
2.通过softmax函数对于𝑠𝑖s_i进行归一化处理将其变成概率
阶段3:
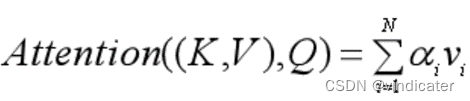
3.将相关概率和第i个词语的Value向量做乘积之后求和得到针对于词语向量Q的句子信息c
由此,通过改变输入词语Query可以让这个模型给我们提供不同的信息矩阵,这是很有针对性的一种行为。
3.注意力在句中的应用:自注意力机制
(1)和软注意模型的区别分析(目的):
对于软注意模型来说,其计算的注意机制是使用了生成句子得到的前i-1个词语对应的词语向量和原句子做相似性研究从而对于源句子的意思做有目的性的理解。而对于自注意模型,其关注的是自己句子或者文章内部的很深层的关联,也就是句法结构这些细节。所以从某种角度上其是一种将自己内部所有元素之间关系学习的操作。
当提到了对于内部元素之间的关系,那很自然地跳出来的是CV之中的全连接层:目的是完全一致的。那为什么不直接套用?
(2)为何使用自注意模型而不使用全连接层?:
对于全连接层来说,其输入的channel数和输出的channel数必须是固定的,而这对于Seq2Seq这种不定长的模型很致命,所以这里采用了自注意模型来学习词语之间的长距离联系。
(3)自注意机制的具体特性:
问题:对于这个模型应该如何确定key值,Value值,Query值比较合适呢?
答:从道理上来说,机器也不知道应该和哪一个词语相似才能提取出句子的主干,因此实际上采用的是随机的方式生成,后续通过学习的方式逐渐调整。因此,不仅是Key向量,Value向量是随机生成的,自注意模型的Query矩阵也是随机生成的。
如图:
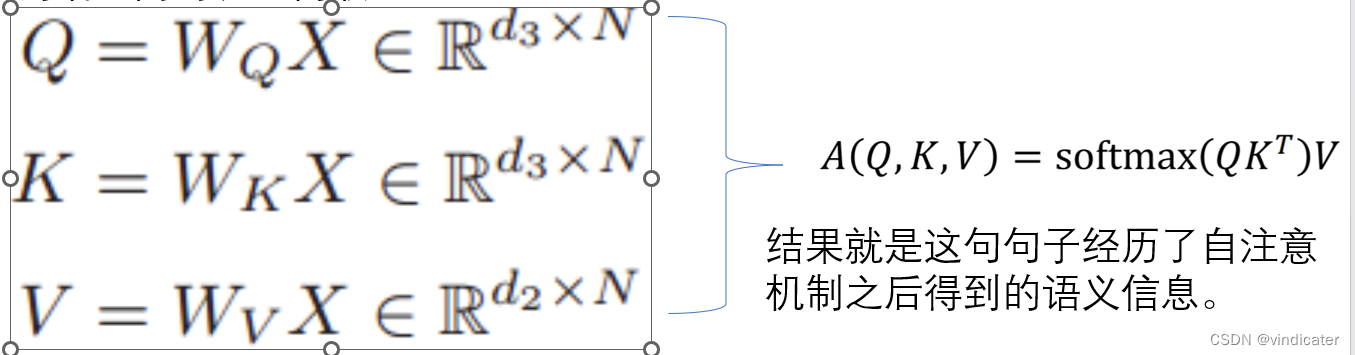
得到了QKV三个矩阵之后就可以类似于之前的操作计算提取句子信息,通过训练,反向传播等方式完成对于QKV三个矩阵的内容的更新和确定最终得到合理的矩阵。
自注意机制被证明是一个相当有意义的机制
正文:基于self-attention的encoder-decoder模型——Transformer结构
(1)Transformer结构简介:
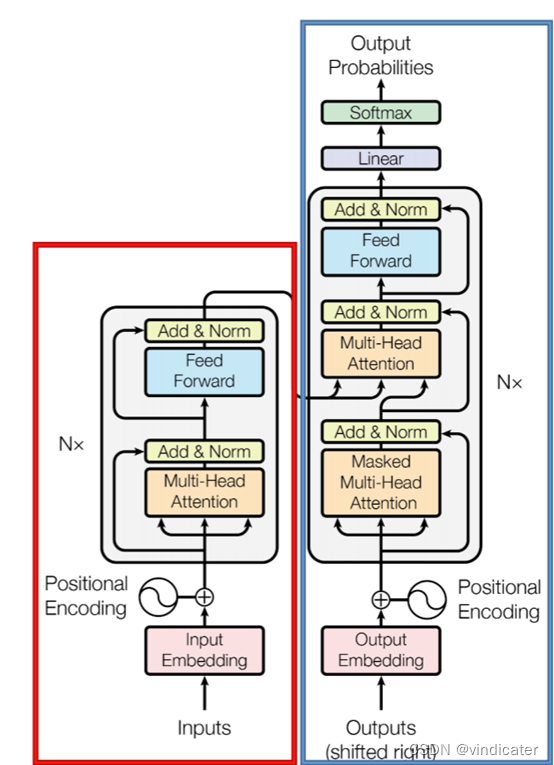
Transformers这一结构主要有三个值得研究的内容:
1.使用的是encoder-decoder框架进行的模型的设计
2.在Transformers中,对于输入内容的处理方式是比较独特的,具体是是有BPE(Byte Pair Encoding)和PE(Positional Encoding)
3.是由一个个相同的transformer块堆叠形成的,而在encoder和decoder中的有略微区别
下面将主要针对第二点和第三点进行介绍和分析
(2)BPE&PE
1.BPE(Byte Pair Encoding):
BPE图示:

具体操作:
1.对于一个句子将其中所有字母全部加入词表之中
2.每次尝试着把词表中两两合并起来,其中出现频率最大的得以保留(比如左侧的es,以及对于2的词表中两两合并后出现次数最多的est)
3.对于被合并的词表内容,带入单词中看是否除了在组合之中就不会再出现了,比如对于左边的1-2中的s,比如对于左边的2-3中的es和t等等(这一点存疑,有真的删除了的,有没有删除的,从道理上来说应该删除更能节省词表中的空间)
4.当词表数量达到需求的最大数量或者发现任意两两组合都没法再获得高出现频率的新的组词后就停止。
以上的处理方法将一个词拆成多个词表中的部分,每个部分被称作的就是一个token,用这些token表达这个词语然后就可以输入到网络之中完成运算。而这个操作方法就是大名鼎鼎的tokenize的方法之一。
最后:Embedding处理:在经历了切分成token之后,形成的句子被送进embedding层转化成词向量。之前提到的Word2Vec就是转化成词向量的方法之一。
2.PE(positional encoding):
这一操作从名字角度来看,是关于位置的编码信息。这就引起了一个问题:为什么突然提出需要位置信息呢?
(1)PE操作的目的:
为何之前的RNN网络不需要表述位置信息呢?因为RNN中按照句中顺序输入。但这样会导致没法并行运算,浪费计算能力。transformer的基础是self-attention结构,而这一结构是并行运算,并没有和RNN一样按照顺序逐一接受词汇。因此对于transformers同时输入的模型只能手动加入位置信息。
(2)具体操作内容:

解析说明:
1.位置向量的结构:利用一个max_len*d_model的矩阵来记录每一个position的词语对应的位置信息。(max_len是一个预先定下的参数,而d_model是模型总共的词语数量)
2.位置向量的内容:根据左边的公式,左边等号左边的括号是公式的两个位置坐标,能从左边的公式看出实际上是每隔一个位置用一个不同的正/余弦函数
3.最后融入x的方式:从forward函数中可以看出来使用了相加的方式。
为什么?
1.从基本角度上,同一个词语在不同的位置,其对应的位置向量一定是不同的。从这个角度上这一种位置编码信息符合基本的需求。
2.原文中是这么介绍的
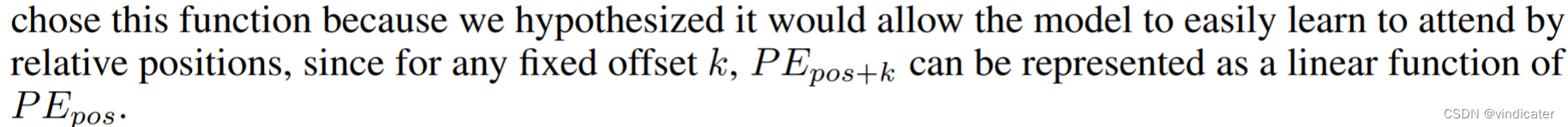
什么意思呢?三角函数的应用可以确保相对位置信息的留存
考虑以下的情形:
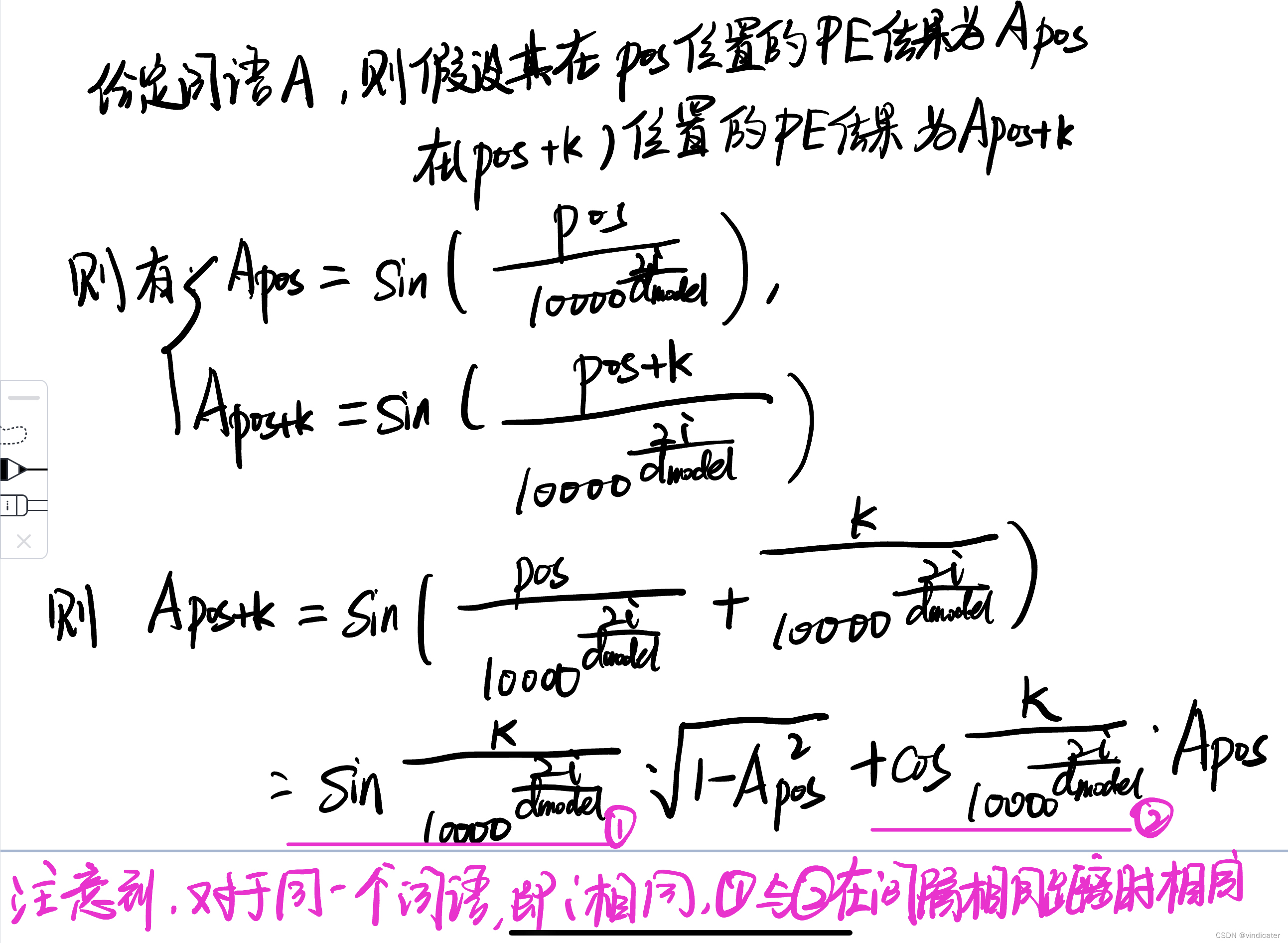
这也就是之前所说的,三角函数的特色保持了相对的位置性:无论这个词在哪两个距离相同的位置出现,其位置向量之间都有同一种关联。这样的特性是独一无二难能可贵的。
(3)encoder部分的分析
在encoder的代码块中,最值得研究的是多头自注意机制以及由于采用了dot-product attention 机制而采用的scaled dot-product attention机制。
1.多头自注意机制
目的:
对于自注意机制,采用的原因是为了能够做到并行运算,同时在目的上能够做到对于输入或者输出的句子进行一次直接的处理。而对于多头自注意机制来说,一个词语可能在语境中有着多层的意思,目的是提取出对于一个句子中词语的不同维度的特征意义。
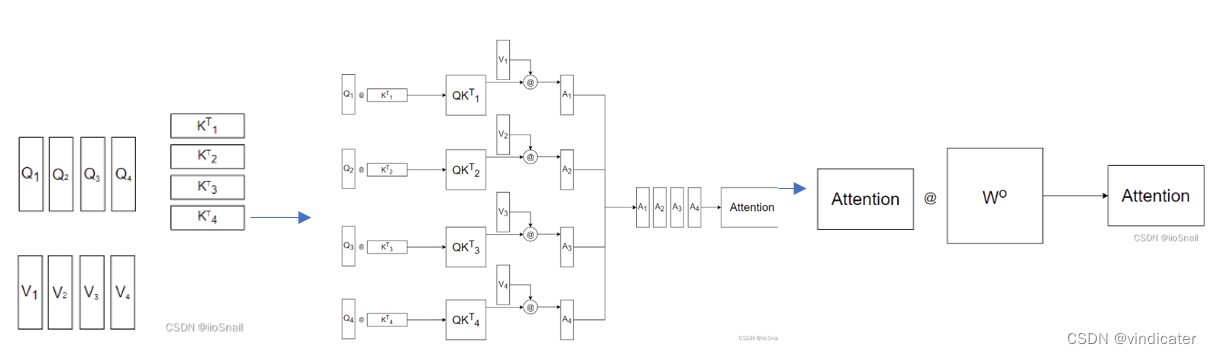
图片来源:CSDN博主:iiosnail
具体的区别:为什么叫多头注意力机制呢?:
回答:对于一个词语来说,Value,key,Query分别在不同特征下有不同的取值(对应矩阵中的某一行)。我们可以将不同的特征对应的信息单独取出来计算获得句子信息再拼起来的方式同时注意多个信息
头的数量不改变参数数量!
2.scale dot-product attention
先给出公式 :

为什么?:
“The two most commonly used attention functions are additive attention , and dot-product (multiplicative) attention.”
“While the two are similar in theoretical complexity, dot-product attention is much faster and more space-efficient in practice, since it can be implemented using highly optimized matrix multiplication code.”
“We suspect that for large values of dk, the dot products grow large in magnitude, pushing the softmax function into regions where it has extremely small gradients”
以上三段文字摘自“attention is all you need”论文,也就是Transformer模型结构第一次被提出的论文。
第一段提出的是attention机制的两个应用途径:第一个是additive attention,第二个是dot-product attention。这两者的差别正如其名字所体现的那样,一个使用的是点积操作,另一个是得到权重之后相加的方式。
第二段是模型叙述其具体采用哪种attention机制:两者在理论的复杂性上是差不多的,但是在速度和内存管理上,点积的attention机制更快,对于空间的运用更加合理,因为对于矩阵乘法的运算已经存在有被很好的优化过的代码了。
第三段是谈论为何需要scale 这样一步操作:当dk的值很大的时候,也就是key矩阵和query矩阵的维度很大的时候,那么点积的大小会变得很夸张,这时如果采用softmax操作那么某些步骤的梯度就会非常小。梯度非常小就意味着,经历反向传播的时候每一次调整效果会不明显,因此我们引入scale,让大小数值之间的差距变小有助于后续训练。
3.对于每一层引入参数不同的feed-forward 操作
公式:

效果:
通过两个线性层以及中间夹着的ReLU激活函数,模型完成了类似于全连接层的操作,确保神经元之间的关系被进一步总结出来。
(4)decoder分析
差别1:使用了masked multi-head attention
 图示
图示
具体改变:

分析:将矩阵中某一些元素置零的方式来获得一个上三角矩阵,其最核心的目的就是使得每一次把矩阵扩充的时候不改变某些内容结果的大小。
在decode的时候,其是一个一个词语输出的,那么这个时候输出某一个词语的时候就不应该知道后续要输出的词语是什么。
因此需要将其上三角部分的内容用mask遮起来得到一个在填空时只能见到前文,不能见到后文的矩阵。
差别2:输入部分的一部分内容的来源是encoder的结果
 图示
图示
理由分析:
对于encoder-decoder模型,虽然模型被分成了两个部分,但是顺序是从encoder到decoder。所以key矩阵使用encoder的结果是合理的,Value矩阵也是如此,这两个矩阵不再通过decoder的输入信息而随机生成。而Query矩阵这里采用的就是从masked多头自注意机制中得到的关于输入信息的矩阵。
最终通过线性层linear全连接之后通过softmax输出概率得分得到输出的词语结果。
(5)细节改变(normalization):
在transformer中采用的是Layer normalization
是什么?:
LN实际上做的是对于一个句子的样本进行归一化,其特点是对于同一个样本的不同特征,可以更明显的体现出某一个特征的占比之大,和之前BN操作将同一个Batch的不同样本的相同特征进行比较是完全不同的。
为什么?:
"However, the summed inputs to the recurrent neurons in a recurrent neural network (RNN) often vary with the length of the sequence so applying batch normalization to RNNs appears to require different statistics for different time-steps.Furthermore, batch normalization cannot be applied to online learning tasks or to extremely large distributed models where the minibatches have to be small."(摘自Layer Normalization的论文)
部分翻译&解析:
但是,对于RNN中的神经元来说,对于输入的求和结果时常会因为句子长度的不同而产生非常巨大的变化,所以如果要应用批标准化就会需要对于不同的time_step有不同的统计数据。
此外,BN不能被用在在线学习任务或者大的分布式训练模型,因为对于那样的模型来说,用于更新损失函数的mini-batch必须特别小。
关于上述的内容说实话作者是有些费解和疑惑的,但是作者阅读了别的一些博客之后结合自己的理解尝试给出下述解释:
对于图片来说,每一个像素格做平均之后得到归一化的结果是合理的:因为可以将图片通过压缩或者补充空白的方式获得统一尺寸的图片结果。
但是对于语句来说,根本不可能做到将所有的语句全部归成相同的长度,毕竟缩句而不显著影响句子内容人类也不能完全做到。
因此,如果把每个位次对应的值进行归一化操作会出现问题:长句和短句的某一个向量维度进行同样方式的归一化从句子本身来看并不十分合理。
从结果角度上来说,实验证明,将句子采用另一方式归一化效果更好。
(6)从代码的角度解析Transformer中的前馈层:forward部分
对于YOLO V5中的Transformerlayer的解析:
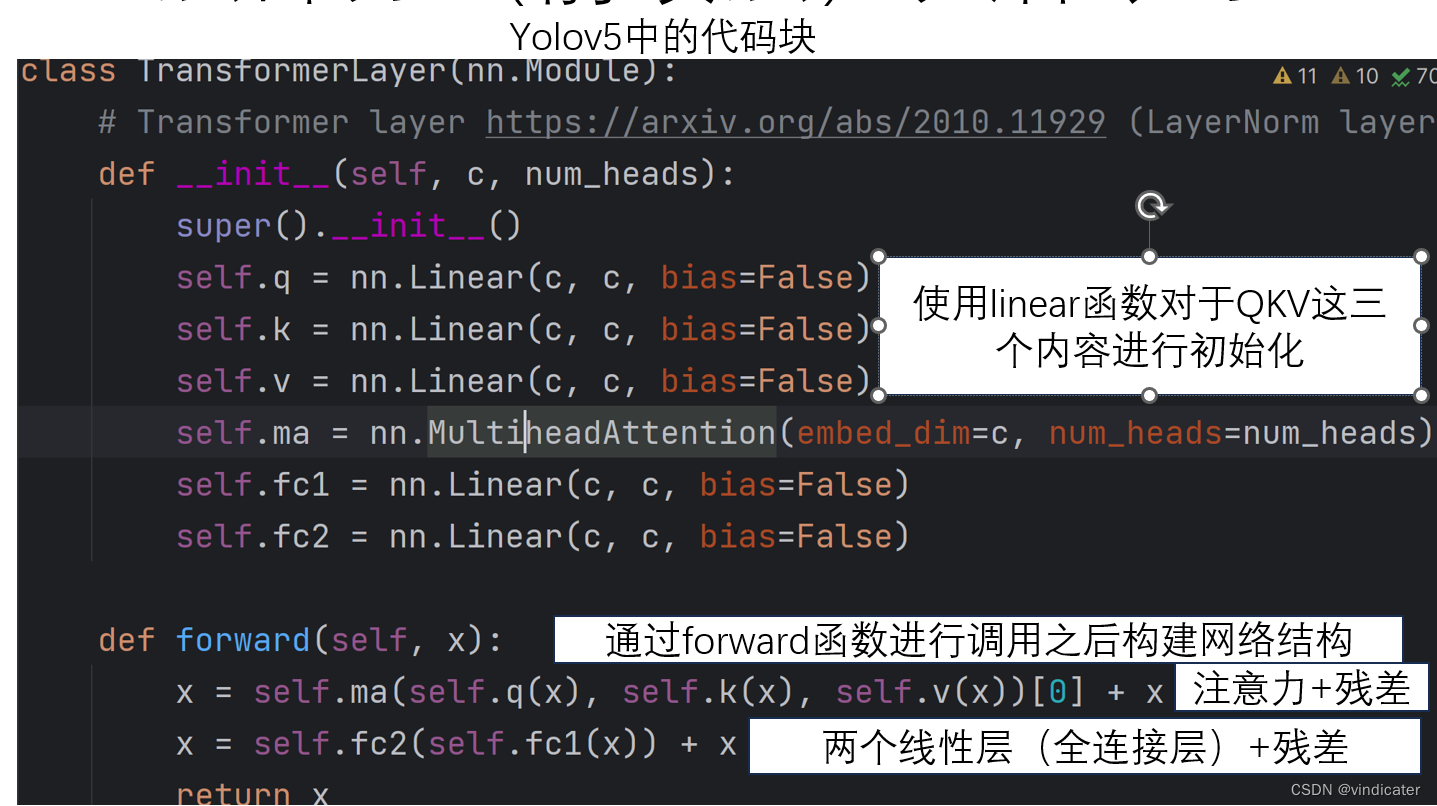
对于前馈层,其本质是两个全连接层的叠加。而对于全连接层来说,其本质就是用线性的方式构建输入的n个数据和输出的m个数据相连接。这里采用线性变换不改变输入输出通道数实际上起到的就是全连接层的目的。
总结:Transformer的利和弊
利:Transformer的有利性是来自attention机制的高性能性,因此对于这样一个利用了多头自注意机制的模型,那Transformer性能一定属于是很高的。其次由于Transformer的self-attention是通过矩阵运算的方式进行的,所以其可以经过并行运算。
弊:1.每一层都使用了self-attention机制在保证效果优异的同时也意味着其每一层都是o(n^2)的复杂度计算量巨大。
2.每一层都经历了self-attention机制大大增加了参数量,调参压力巨大。
后记:
本文介绍阐述了模型结构的一个巨大的发展,从attention机制入手,介绍了Transformer的模型。到现在为止,大型的网络结构上的变动已经完全介绍完毕。最近似乎微软研究团队和清华大学共同推出了RetNet结构,学习之后我可能会后续出专栏解析。下一篇文章是作者对于暑假实习的最后一篇文章:大模型相关的知识的一个介绍。如果觉得本文对于您有帮助,球球点赞关注awa。















 1512
1512











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









