






相关名词解释:
Agent:智能体;
s—state:状态(放在格子游戏中,就是智能体的位置坐标(x,y))
a—action:智能体采取的动作(例如上下左右)
r—reward:奖励(格子世界中智能体每走一步离目的地的远近程度,离目的地近了,说明动作很好,奖励很好)
s_—state_:下一状态,由智能体把动作输入到环境中后,环境所给出的(就是执行动作后,下一个位置)
Environment:试验环境
transition:就是一个类,类中有四个属性s,a,r,s_,经验回放池就是一个transition对象队列,先进先出
经验回放池Replay Buffer/Experience Replay:因为智能体在探索环境时,采集到的样本是个时间序列,样本之间具有很强的连续性和相关性(例如:一个人物一段视频中的前后两帧,其面部表情几乎是没有什么变化的,而且前后两帧还具有很强的因果关系,比如你要想笑,面部肌肉或者就要先变化),但实际上,我们在训练过程中,每条数据之间都要是“独立同分布”的,而经验回放池的目的就是将每一条transition放入其中,并从里边随机取出一定的batchsize,这样就能实现数据的“独立同分布”
经验回访池容量:经验回放池中最多放多少条数据,满了就“先进先出”
经验回访池当前容量:当前池子中有多少条数据
batch_size:每次从池子中随机抽取数据的数量
贪婪策略ε:不考虑全局最优解,只是选择某个阶段的最优解,虽然贪婪策略不一定能找到全局最优解,但胜在简单
动作空间:智能体每一步所有可能运动的方向,例如A=[上,下,左,右]
Q值和Target Q值:完整性态是Q(s,a;w)——状态动作价值函数,即只要给智能体一个状态和相应的动作,就有这么一个Q值
超参数:强化学习中,有些参数并不能推导,是需要提前设定的,这些参数在实际应用中能够解决相关问题
1>折扣率γ:对奖励进行打折的比率,举例来说:在一个格子世界中,有猫(终止状态)、奶酪(奖励)和老鼠(Agent),老鼠周围有小块奶酪,猫周围有大量奶酪,也就是说越靠近猫能吃到的奶酪越多,但同时危险也越大,相比风险而言,奖励也就不重要了,这也就是时间步越长,奖励越低(人家跑马拉松几个小时,你跑马拉松跑一年,哪还有奖励了),所以时间步越少,奖励越大(γ的方次越小);反之,奖励越小
# greedy policy
if np.random.randn() <= EPISILO: # 如果随机值<=ε值,则选择最大Q值对应的动作
action_value = self.eval_net.forward(state)
action = torch.max(action_value, 1)[1].data.numpy()
action = action[0] if ENV_A_SHAPE == 0 else action.reshape(ENV_A_SHAPE)
else: # 如果随机值>ε值,则在动作空间中随机选择一个动作
action = np.random.randint(0,NUM_ACTIONS)
action = action if ENV_A_SHAPE ==0 else action.reshape(ENV_A_SHAPE)
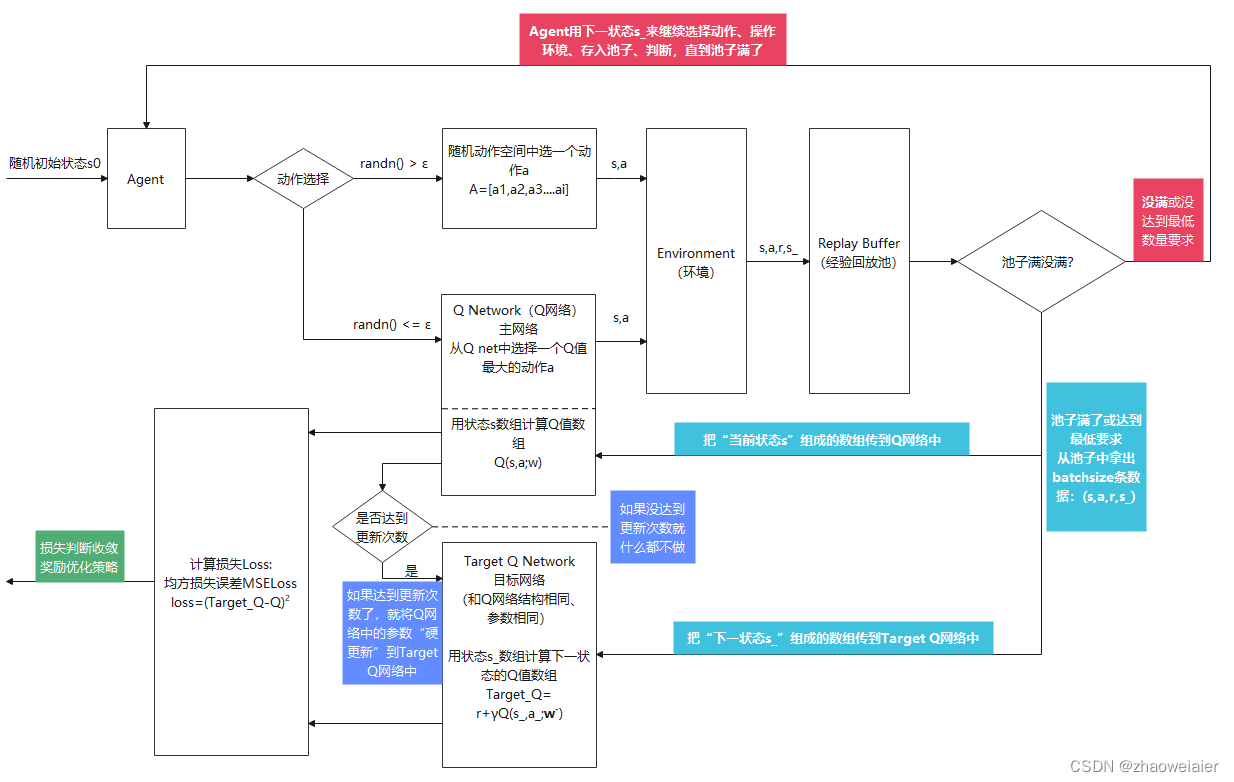
return actionDQN流程
1. 循环迭代400~1000轮,定义奖励数组reward_list,损失数组loss_list,将每一个episode的奖励之和以及损失存入响应数组中,每一个episode执行2、3、4步操作
2. Agent先随机选择一个初始状态s0,并使用贪婪策略选择动作a,将s0、a输入到环境中执行,环境会反馈出奖励r以及下一状态s_,并将这四个元素组成一个资源组transition:(s0,a,r,s_),存入到经验回放池中,并将奖励累加
3. 判断经验回放池中数据满没满(有的算法是判断是否到达最低数据限度),没满就继续执行第1步;满了就执行第3步
4. 池子如果满了(或达到最低数据限度),就从中随机抽取batch_size条数据,具体操作如下
1>将随机抽取数据中的状态s组成一个数据,分别输入到Q网络和Target Q网络中,计算Q值和Target Q值(算出的值都是一个数组)
2>使用均方误差,对Q值和Target Q值计算损失函数
















 1031
1031











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









