






一、前言
提出了一种新的vision Transformer,称为Swin Transformer,它可以作为计算机视觉的通用骨干。将Transformer从语言应用到视觉的挑战来自于这两个领域之间的差异,例如视觉实体规模的巨大差异以及与文本中的单词相比,图像中像素的高分辨率。为了解决这些差异,我们提出了一个分层的Transformer,它的表示是用移位窗口计算的。分层设计和移位窗口方法也被证明对所有mlp体系结构都是有益的。
二、Swin Transformer所解决的问题
- 超高分辨率的图像所带来的计算量:参考卷积网络的工作方式,获得全局注意力能力的同时,又将计算量从图像大小的平方关系降为线性关系,大大地减少了运算量,串联窗口自注意力运算(W-MSA)以及滑动窗口自注意力运算(SW-MSA)。
- 最初的Vision Transformer不具备多尺度预测:通过特征融合的方式PatchMerging(可参考卷积网络里的池化操作),每次特征抽取之后都进行一次下采样,增加了下一次窗口注意力运算在原始图像上的感受野,从而对输入图像进行了多尺度的特征提取。
- 核心技术:SwinTransformer 针对ViT使用了“窗口”和“分层”的方式来替代长序列进行改进。
三、模型概述
3.1 模型结构
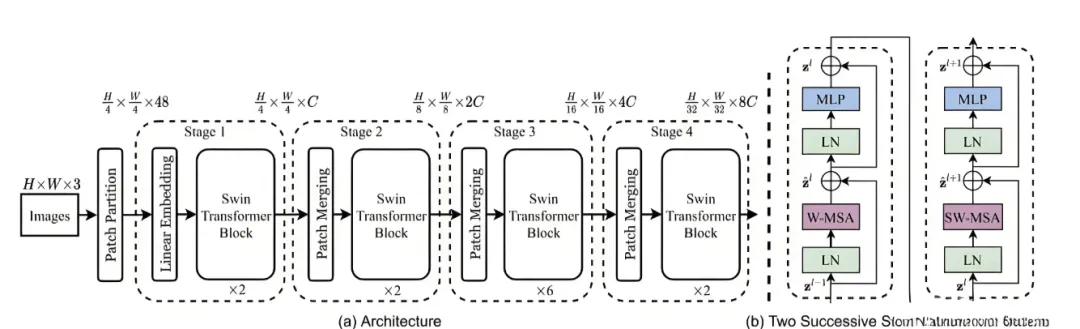
首先将图片输入到Patch Partition模块中进行分块,即每4x4相邻的像素为一个Patch,然后在channel方向展平(flatten)。假设输入的是RGB三通道图片,那么每个patch就有4x4=16个像素,然后每个像素有R、G、B三个值所以展平后是16x3=48。
通过Patch Partition后图像shape由 [H, W, 3]变成了 [H/4, W/4, 48]。然后在通过Linear Embeding层对每个像素的channel数据做线性变换,由48变成C,即图像shape再由 [H/4, W/4, 48]变成了 [H/4, W/4, C]。
接着通过四个Stage构建不同大小的特征图,除了Stage1中先通过一个Linear Embeding层外,剩下三个stage都是先通过一个Patch Merging层进行下采样。重复堆叠Swin Transformer Block,注意这里的Block其实有两种结构,如图(b)中所示,这两种结构的不同之处仅在于一个使用了W-MSA结构,一个使用了SW-MSA结构。
而且这两个结构是成对使用的,先使用一个W-MSA结构再使用一个SW-MSA结构,所以堆叠Swin Transformer Block的次数都是偶数。
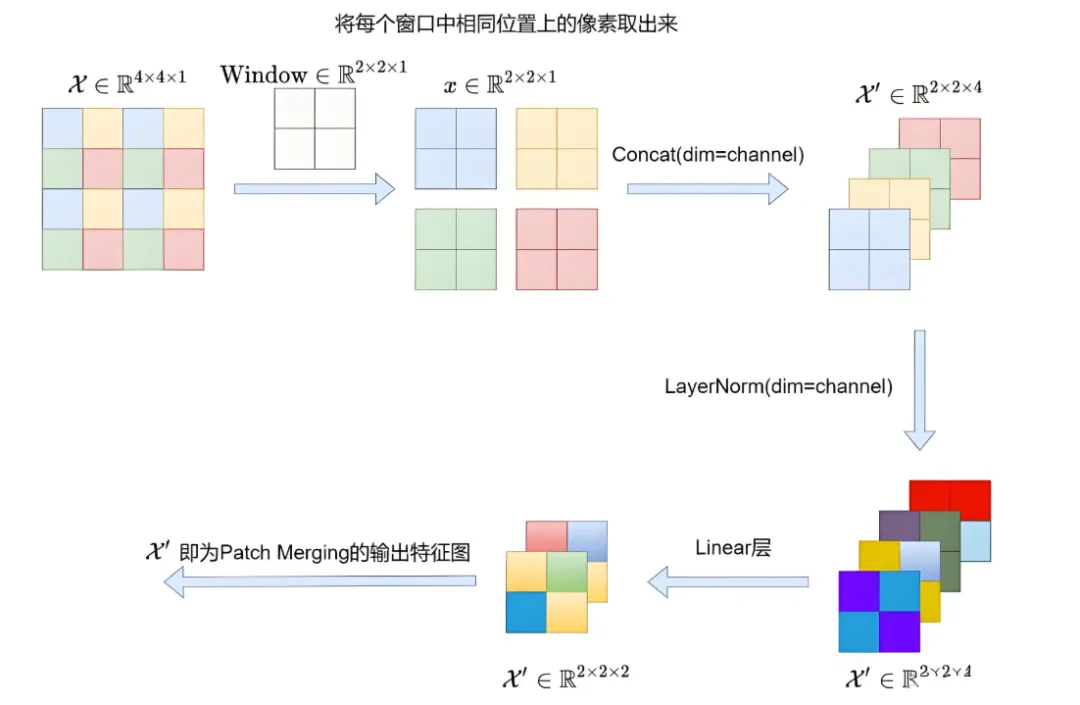
Patch Merging
由图可见在除Stage1外的每个Stage中首先要通过一个Patch Merging层进行下采样。假设输入Patch Merging的是一个4x4大小的单通道特征图(feature map),Patch Merging会将每个2x2的相邻像素划分为一个patch,然后将每个patch中相同位置(同一颜色)像素给拼在一起就得到了4个feature map。
接着将这四个feature map在深度方向进行concat拼接,接着通过一个LayerNorm层。最后通过一个全连接层在feature map的深度方向做线性变化,将feature map的深度由C变成C/2。可以看出,通过Patch Merging层后,feature map的高和宽减半,深度翻倍。
3.2 W-MSA
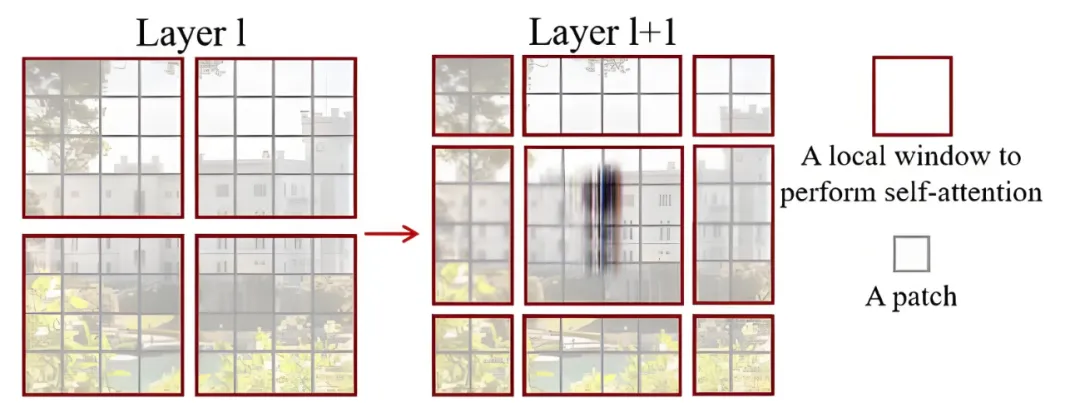
Swin Transformer使用了类似卷积神经网络中的层次化构建方法(Hierarchical feature maps),比如特征图尺寸中有对图像下采样4倍的,8倍的以及16倍的,这样的backbone有助于在此基础上构建目标检测,实例分割等任务。
而在之前的Vision Transformer中是一开始就直接下采样16倍,后面的特征图也是维持这个下采样率不变。在Swin Transformer中使用了Windows Multi-Head Self-Attention(W-MSA)的概念,比如在下图的4倍下采样和8倍下采样中,将特征图划分成了多个不相交的区域(Window),并且Multi-Head Self-Attention只在每个窗口内进行,这样做的目的是能够减少计算量的,尤其是在浅层特征图很大的时候。
3.3 SW-MSA
采用W-MSA模块时,虽然减少了计算量但也会隔绝不同窗口之间的信息传递,所以在论文中作者又提出了 Shifted Windows Multi-Head Self-Attention(SW-MSA)的概念,通过此方法能够让信息在相邻的窗口中进行传递。
如图所示,左侧使用的是刚刚讲的W-MSA(假设是第L层),那么根据之前介绍的W-MSA和SW-MSA是成对使用的,那么第L+1层使用的就是SW-MSA。根据左右两幅图对比能够发现窗口发生了偏移(可以理解成窗口从左上角分别向右侧和下方各偏移了 M/2 个像素)。看下偏移后的窗口,比如,第二行第二列的4x4的窗口,能够使第L层的四个窗口信息进行交流,其他的同理,那么这就解决了不同窗口之间无法进行信息交流的问题。
通过将窗口进行偏移后,由原来的4个窗口变成9个窗口了。后续对每个窗口内部进行MSA的话又过于繁琐。为了解决这个问题,作者又提出而了Efficient batch computation for shifted configuration ,如下图所示,先将AC移至底部,再将BA移至最右侧。移动完后,A、B、C与初始模块重新组合,又重新变为4块4x4的窗口,所以能够保证计算量是相同的。
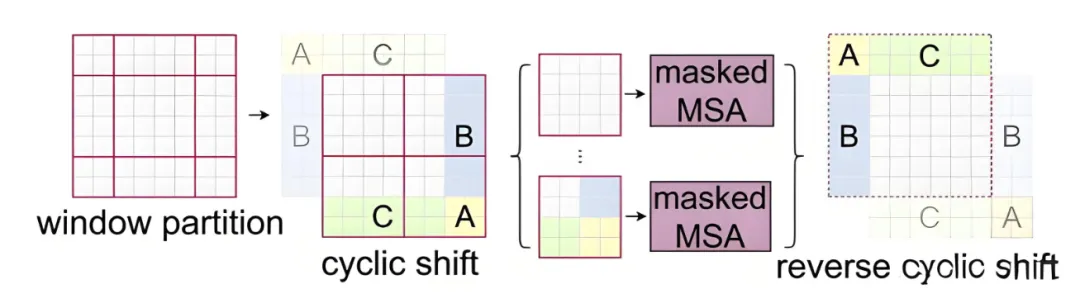
但是由于不同的区域合并在一起进行MSA会导致信息错乱,为了防止这个问题,在实际计算中使用的是masked MSA,这样就能够通过设置蒙板来隔绝不同区域的信息了。关于mask如何使用,以的区域5和区域3为例。
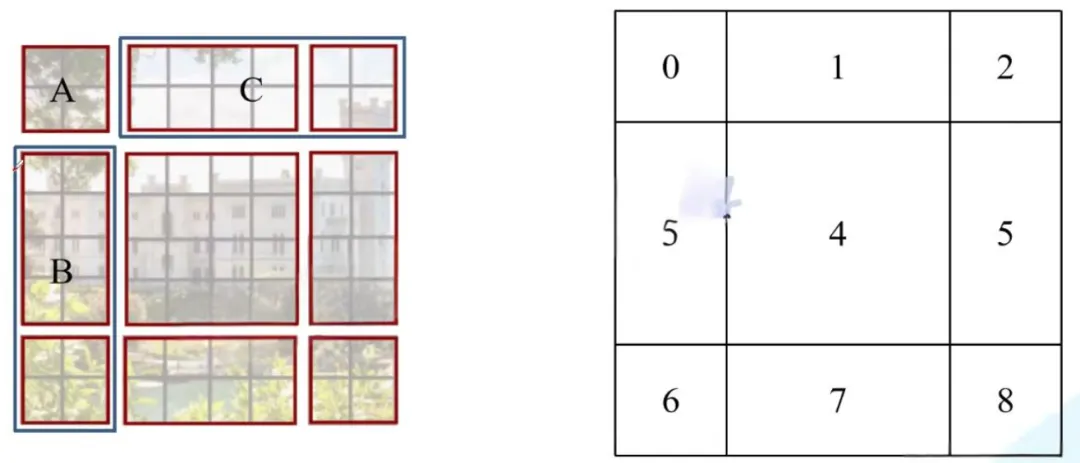
对于该窗口内的每一个像素(或称token,patch)在进行MSA计算时,都要先生成对应的query(q),key(k),value(v)。假设对于上图的像素0而言,得到q0后要与每一个像素的k进行匹配(match),假设α 0,0代表q 0 与像素0对应的k 0进行匹配的结果,那么同理可以得到α 0,0至α 0,15 。按照普通的MSA计算,接下来就是SoftMax操作了。
但对于这里的masked MSA,像素0是属于区域5的,我们只想让它和区域5内的像素进行匹配。那么我们可以将像素0与区域3中的所有像素匹配结果都减去100(例如α 0 , 2 , α 0 , 3 , α 0 , 6 , α 0 , 7 等等),由于α的值都很小,一般都是零点几的数,将其中一些数减去100后再通过SoftMax得到对应的权重都等于0了。所以对于像素0而言实际上还是只和区域5内的像素进行了MSA。在计算完后还要把A,B,C给挪回到原来的位置上。
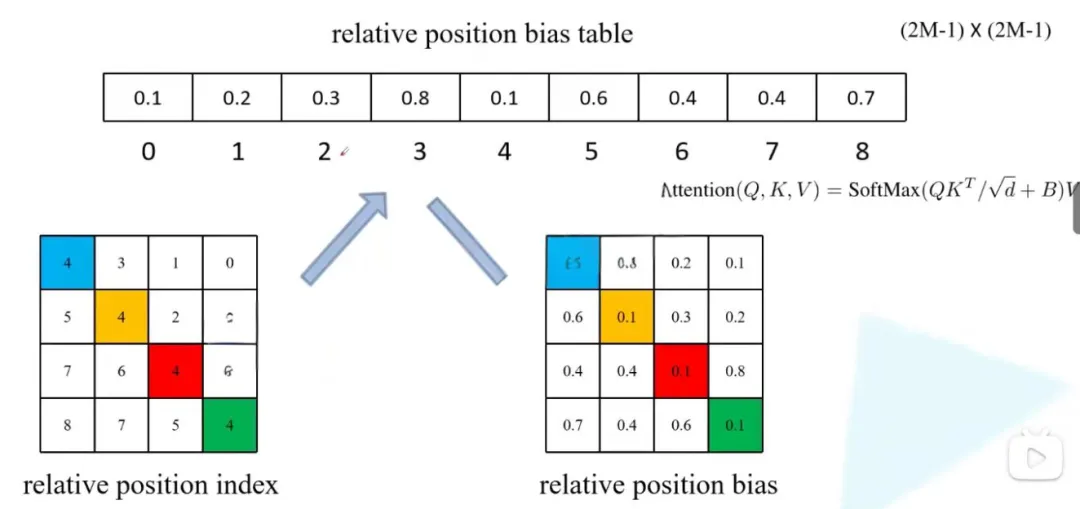
3.4 相对位置偏置
文中提到使用了相对位置偏置后能够带来明显的提升,下图为公式,与自注意力机制公式相比加了B(偏置)。

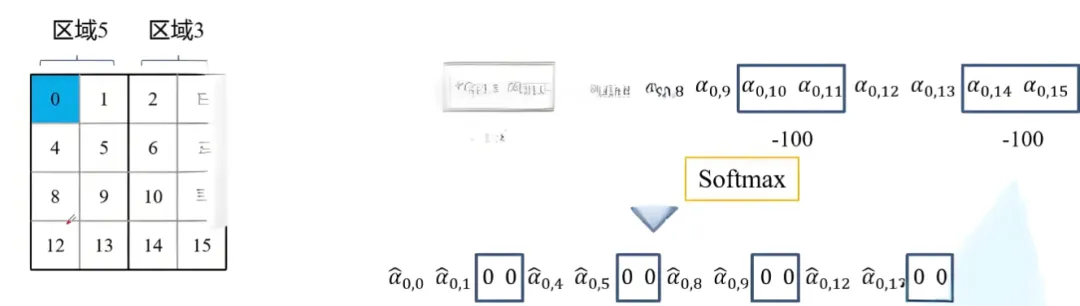
如下图,假设输入的feature map高宽都为2,那么首先我们可以构建出每个像素的绝对位置(左下方的矩阵),对于每个像素的绝对位置是使用行号和列号表示的。比如蓝色的像素对应的是第0行第0列所以绝对位置索引是(0,0),接下来再看看相对位置索引。
首先看下蓝色的像素,在蓝色像素使用q与所有像素k进行匹配过程中,是以蓝色像素为参考点。然后用蓝色像素的绝对位置索引与其他位置索引进行相减,就得到其他位置相对蓝色像素的相对位置索引。例如黄色像素的绝对位置索引是(0,1),则它相对蓝色像素的相对位置索引为(0,0)−(0,1)=(0,−1),。
那么同理可以得到其他位置相对蓝色像素的相对位置索引矩阵。同样,也能得到相对黄色,红色以及绿色像素的相对位置索引矩阵。接下来将每个相对位置索引矩阵按行展平,并拼接在一起可以得到下面的4x4矩阵 。
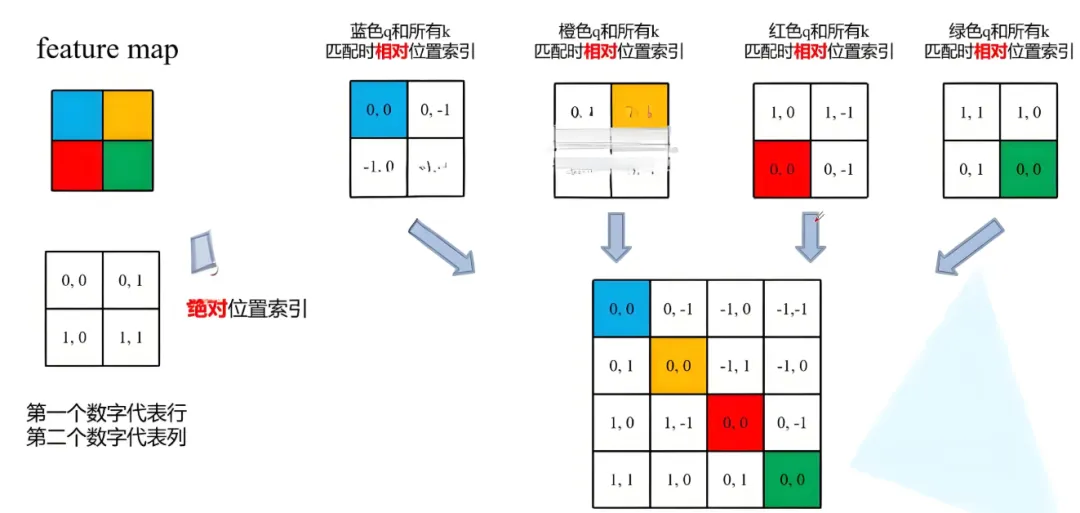
这里描述的一直是相对位置索引,并不是相对位置偏执参数。因为后面我们会根据相对位置索引去取对应的参数。比如说黄色像素是在蓝色像素的右边,所以相对蓝色像素的相对位置索引为(0,−1)。绿色像素是在红色像素的右边,所以相对红色像素的相对位置索引为(0,−1)。可以发现这两者的相对位置索引都是(0,−1),所以他们使用的相对位置偏执参数都是一样的。
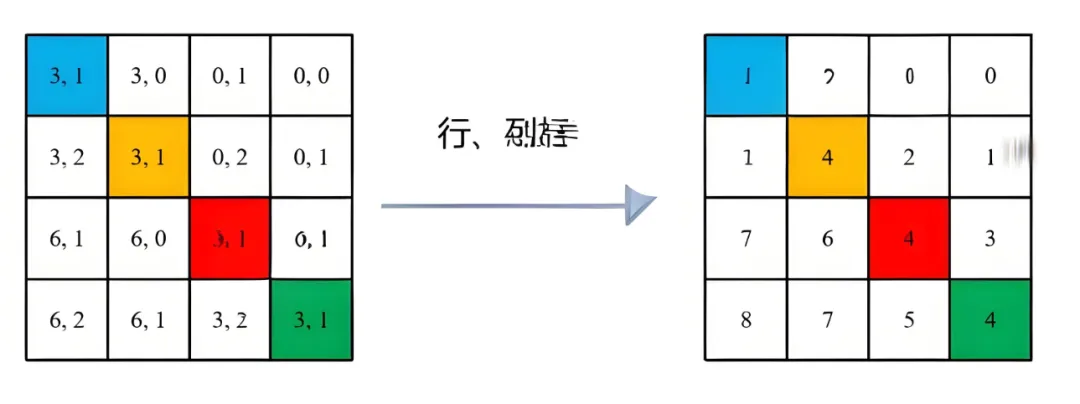
在源码中作者为了方便把二维索引给转成了一维索引。如果直接把行、列索引相加,例如上面的相对位置索引中有(0,−1)和(−1,0),在二维的相对位置索引中明显是代表不同的位置,但如果简单相加都等于-1就出问题了。源码中首先在原始的相对位置索引上加上M-1(M为窗口的大小,在本示例中M=2),加上之后索引中就不会有负数了。

接着将所有行标都乘上2M-1,最后将行标和列表进行相加,就不会出现上述问题了。
由于之前计算的是相对位置索引,并不是相对位置偏执参数。真正使用到的可训练参数B是保存在relative position bias table表里的,这个表的长度是等于(2M−1)×(2M−1)的。那么公式中的相对位置偏置参数B是根据上面的相对位置索引表根据查relative position bias table表得到的,如下图所示。
四、代码
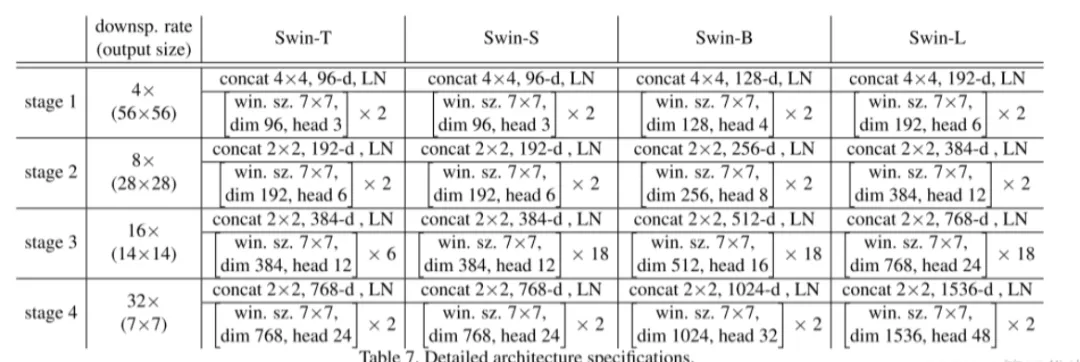
下图是原论文中给出的关于不同Swin Transformer的配置,T(Tiny),S(Small),B(Base),L(Large),其中:
- win. sz. 7x7表示使用的窗口(Windows)的大小
- dim表示feature map的channel深度(或者说token的向量长度)
- head表示多头注意力模块中head的个数
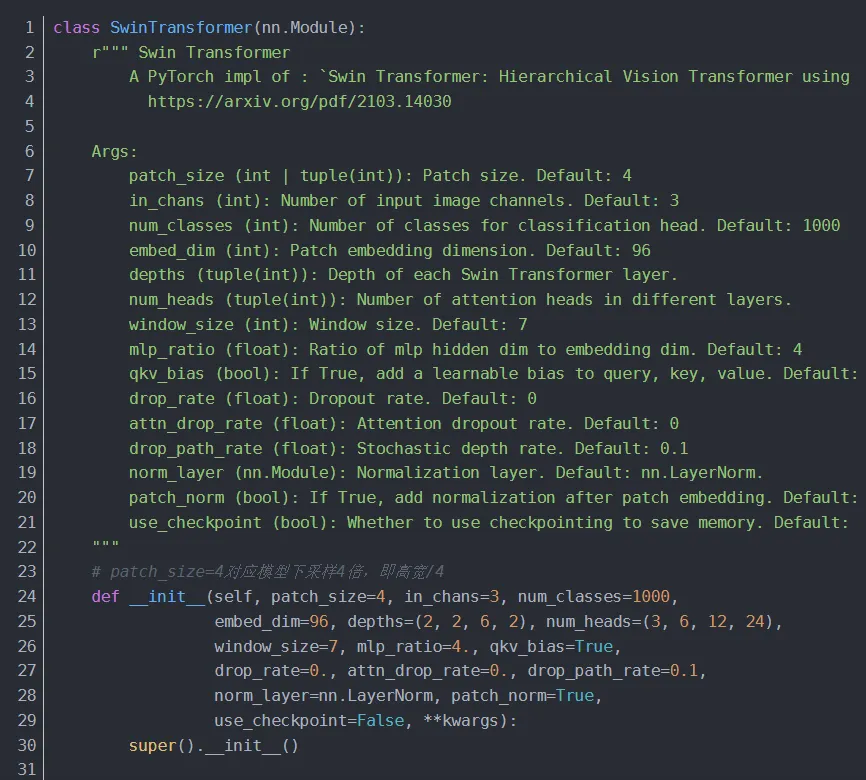
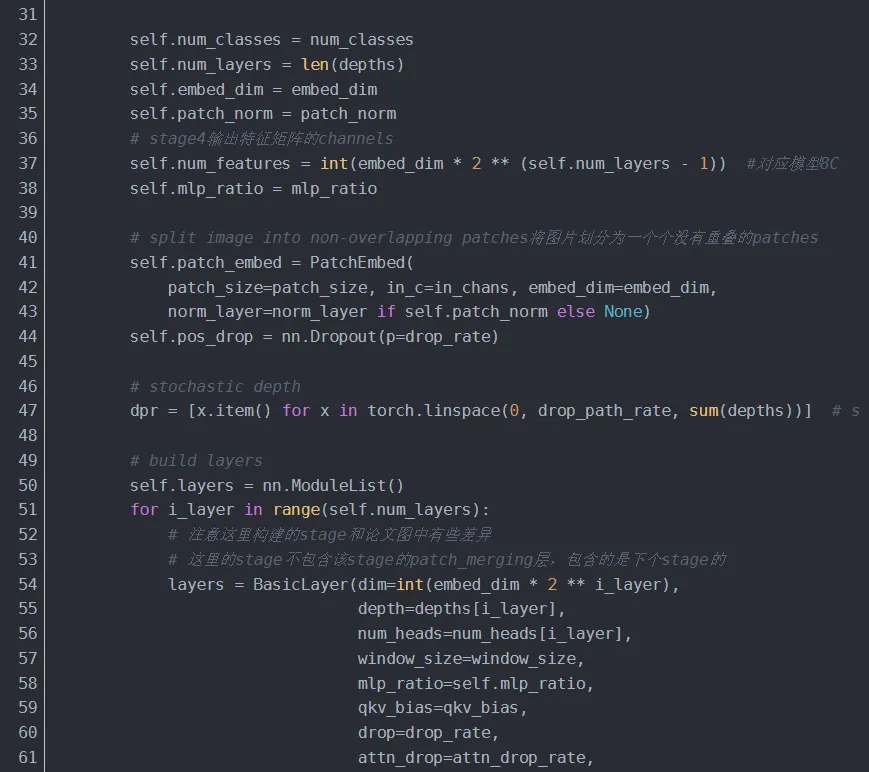
4.1 Swin Transformer
展示 Swin Transformer 的整体架构,参数与上图对应。
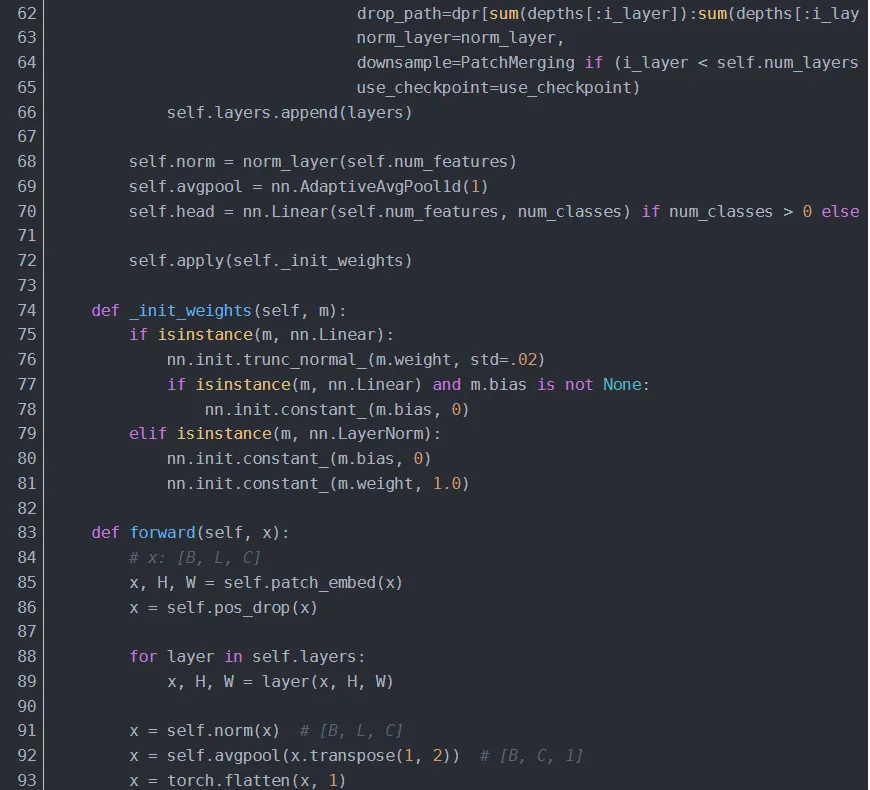

4.1.1 PatchEmbed
将图片输入 Swin Transformer Block 前,需将图片划分成若干 patch tokens 并投影为嵌入向量。更具体地,将输入原始图片划分成一个个 patch_size * patch_size 大小的 patch token,然后投影嵌入。可通过将 2D 卷积层的 stride 和 kernel_size 的大小设为 patch_size,并将输出通道数设为 embed_dim 来实现投影嵌入。最后,展平并置换维度。
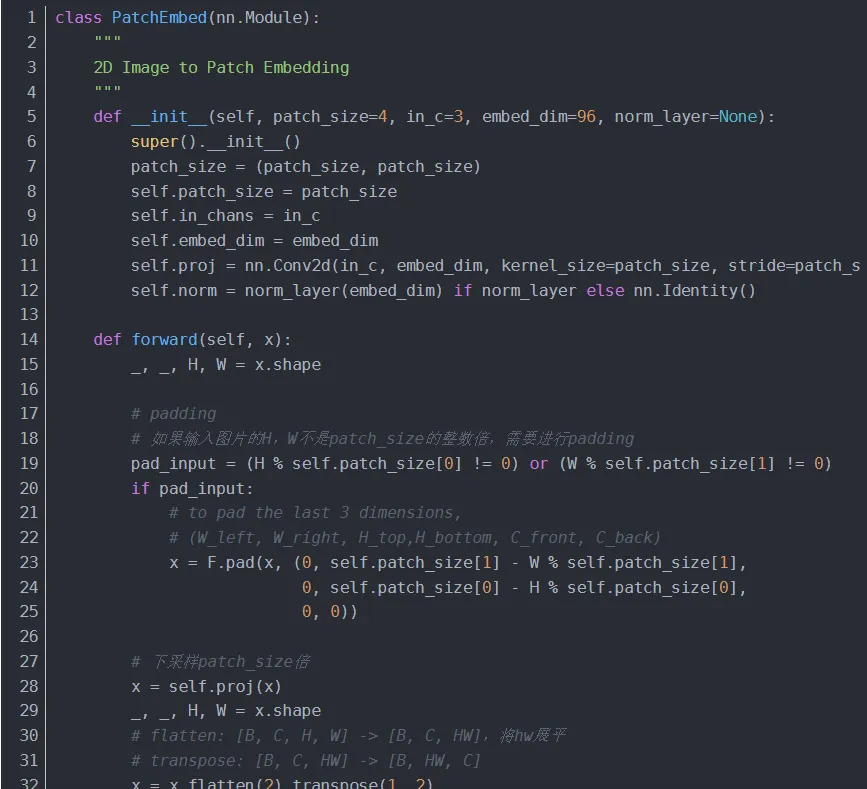

4.1.2 PatchMerging
在每个 Stage 前下采样缩小分辨率并减半通道数,从而形成层次化设计并降低运算量。
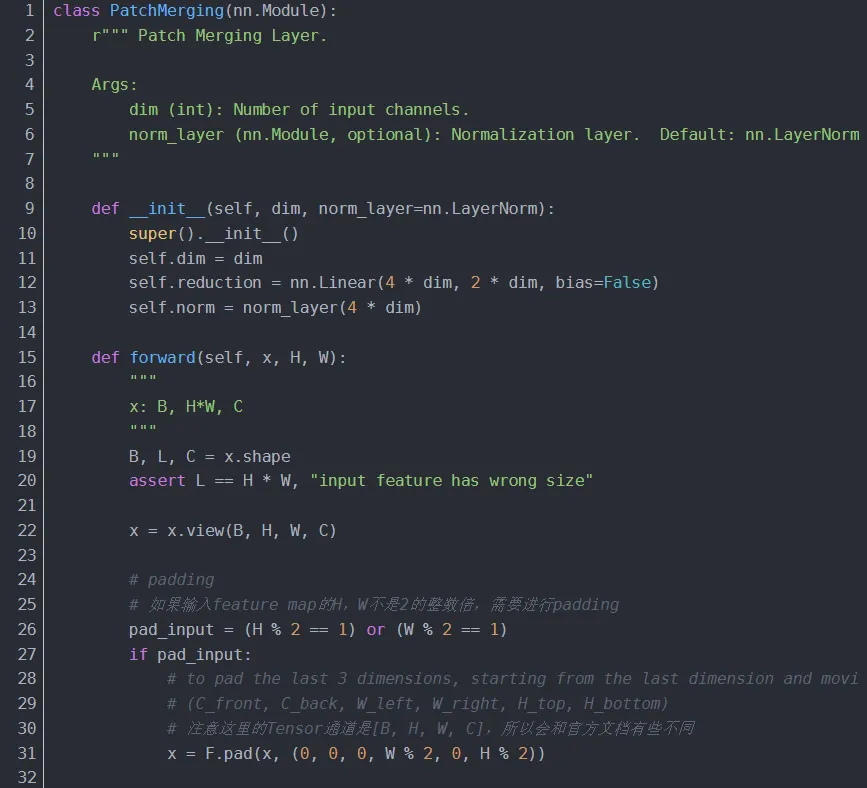
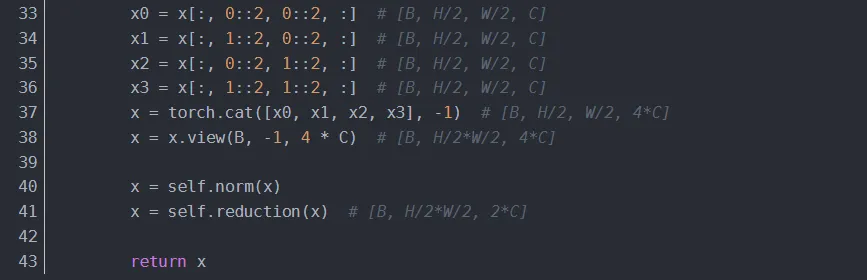
4.1.3 BasicLayer
Basic Layer 即 Swin Transformer 的各 Stage,包含了若干 Swin Transformer Blocks 及 其他层。一个 Stage 包含的 Swin Transformer Blocks 的个数必须是 偶数,因为需交替包含一个含有 Window Attention (W-MSA) 的 Layer 和含有 Shifted Window Attention (SW-MSA) 的 Layer。
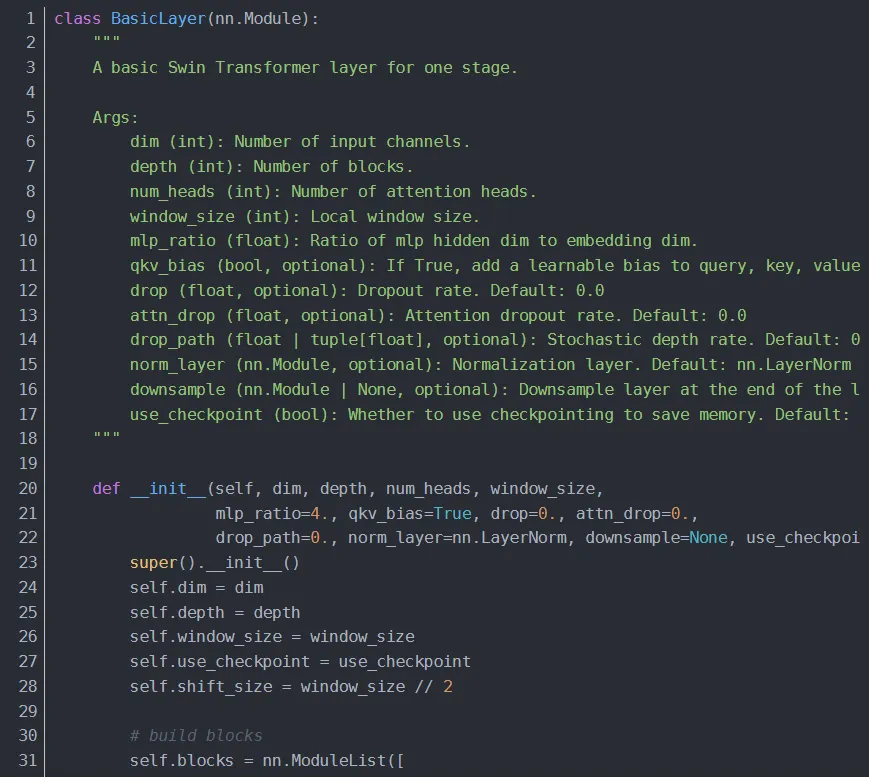
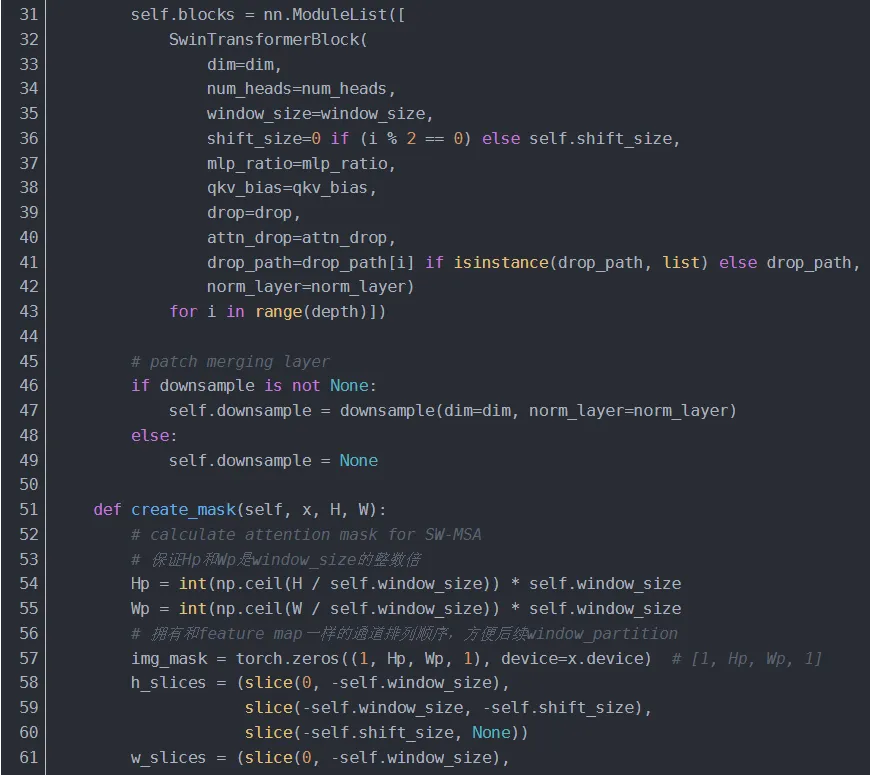
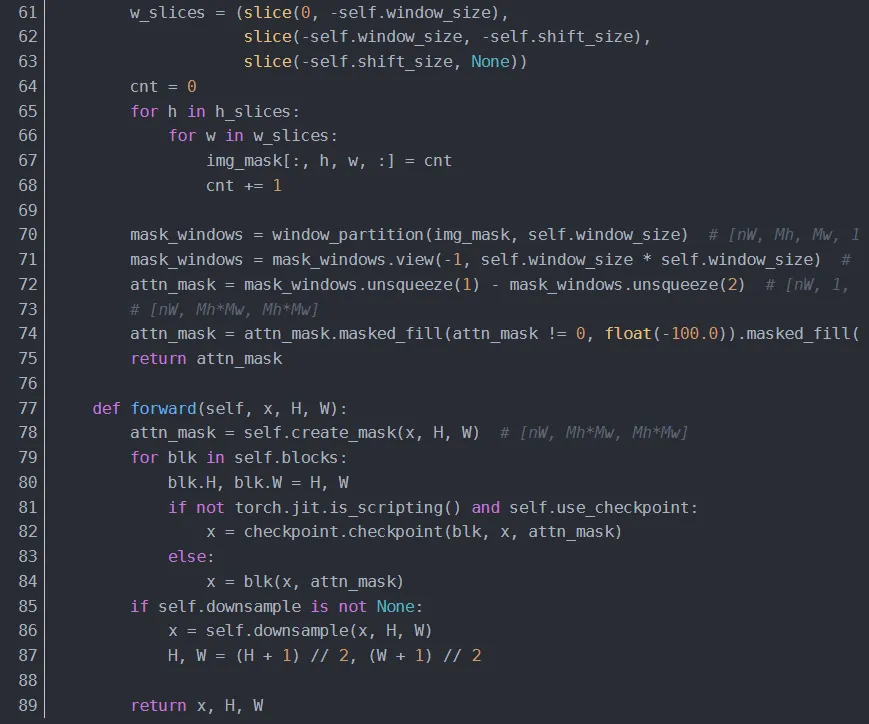
4.1.3.1 creat_mask
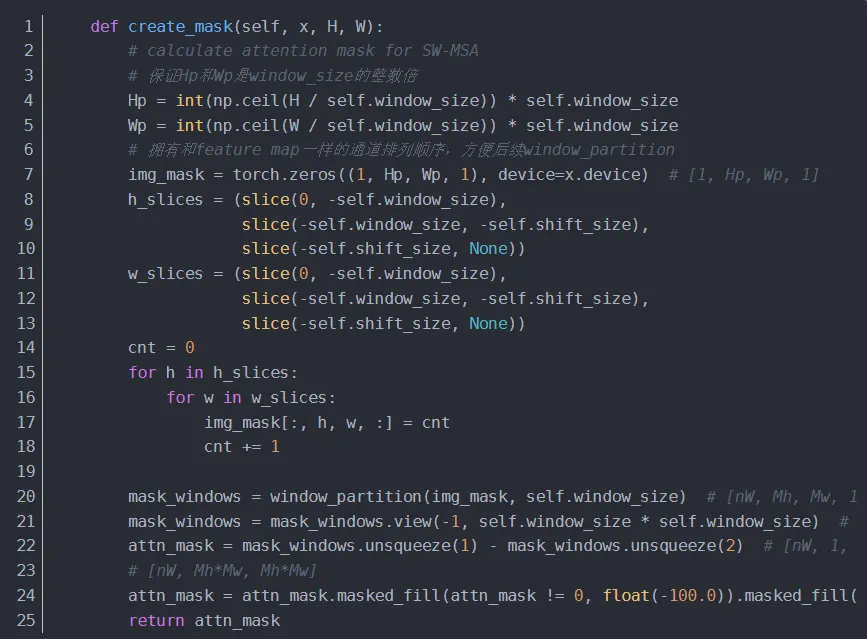
window_partition
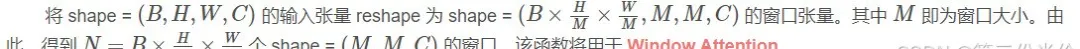
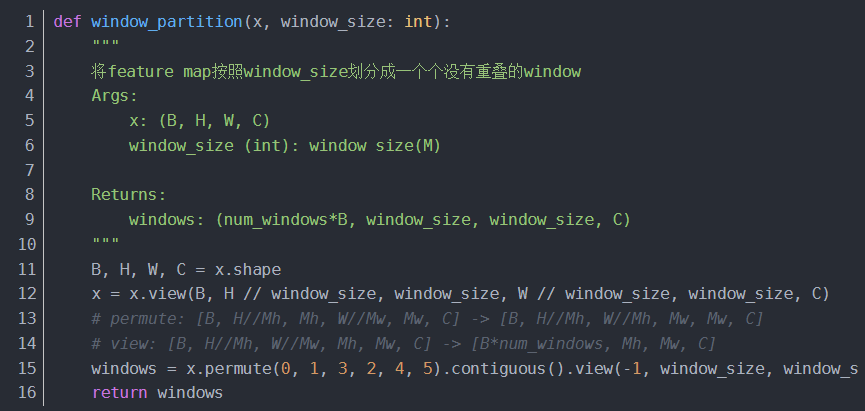
window_reverse

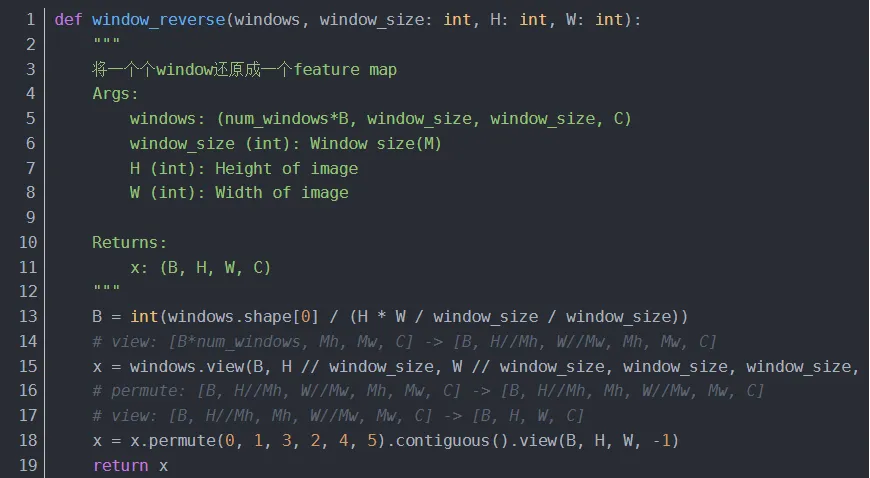
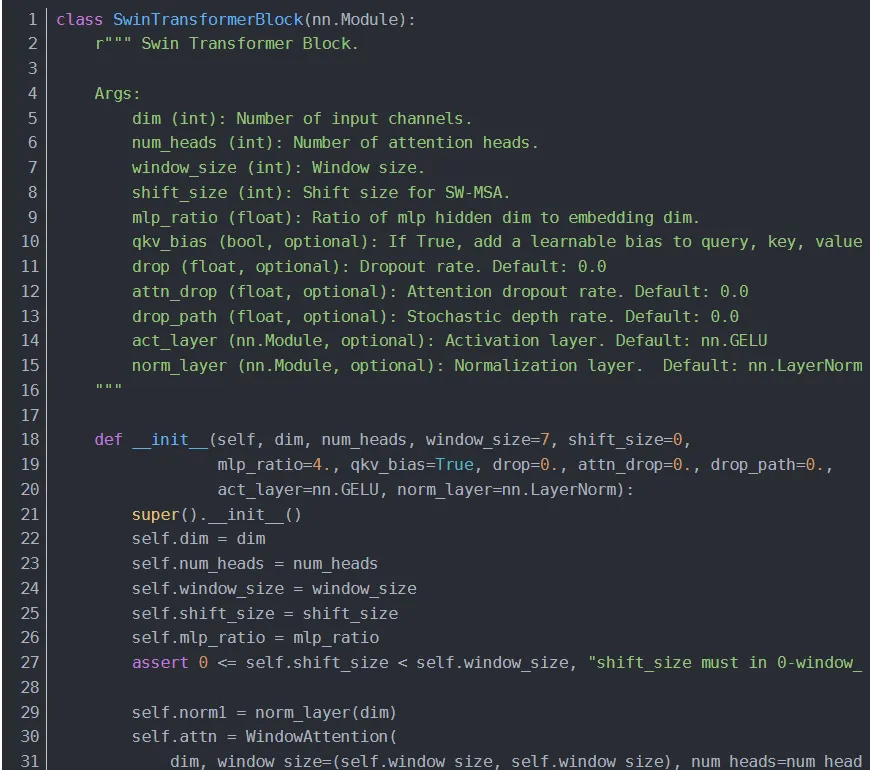
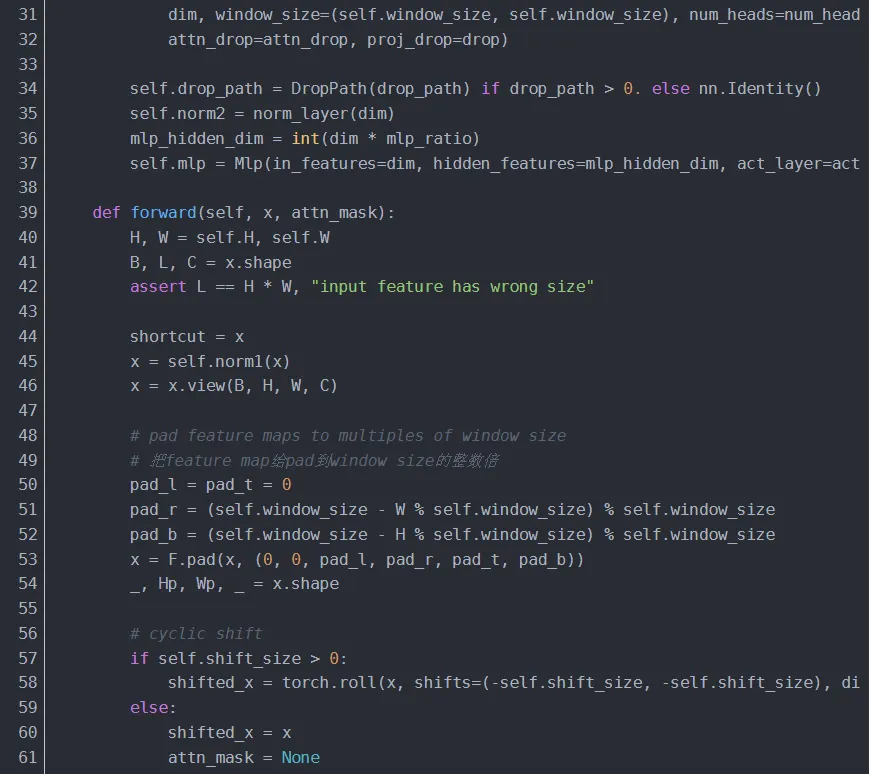
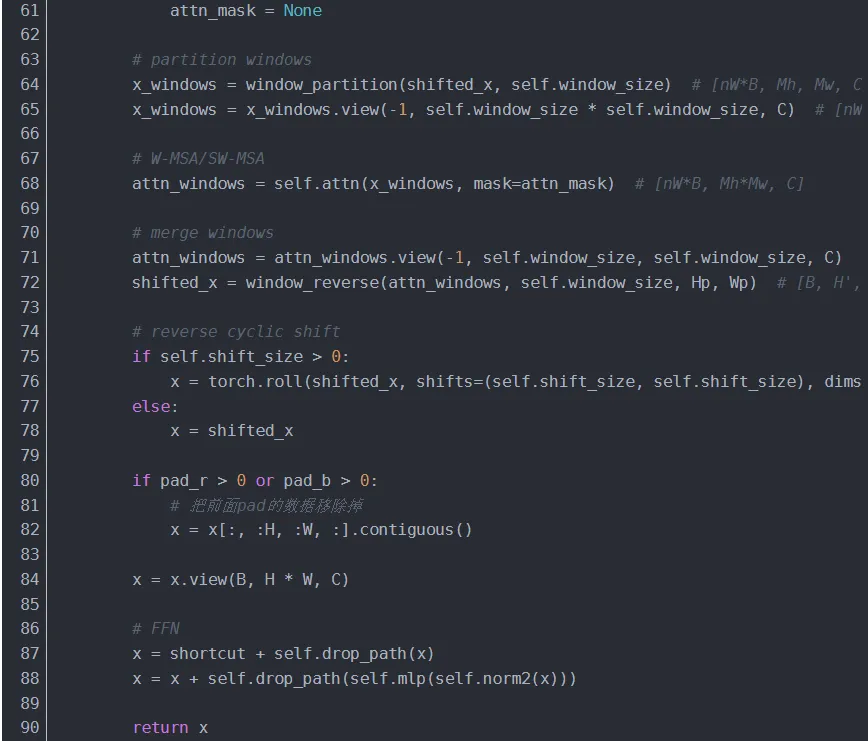
4.1.3.2 SwinTransformerBlock
如何零基础入门 / 学习AI大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
想正式转到一些新兴的 AI 行业,不仅需要系统的学习AI大模型。同时也要跟已有的技能结合,辅助编程提效,或上手实操应用,增加自己的职场竞争力。
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
那么我作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,希望可以帮助到更多学习大模型的人!至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

👉 福利来袭CSDN大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈
全套AGI大模型学习大纲+路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。




👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉 福利来袭CSDN大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

















 1393
1393

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









