







1. 模型提出背景
FM解决的是预测性问题。也就是说给定输入值,给出输出值。但是针对预测性问题的解决,目前有较多的模型可以用,针对factorization machine这篇文章,作者主要是抓住FM和支持向量机的优劣比较,支持向量机最终是解决数值优化问题,如果自变量是稠密的,那么使用支持向量机是有较大优势的。但是如果自变量有较多的类别变量(指示变量),从而导致数据比较稀疏,也就是说一个样本点的输入多数都是零,这种情况在推荐系统中有较多,这时候支持向量机的劣势就体现出来了。那么就出现了如何解决输入比较稀疏时的预测性问题。
2.例子描述
首先我们借用factorization machine中的例子,因为本人也是从事推荐系统相关工作,也比较喜欢这个例子。

上述描述性数据,其中S表示事务型数据,我们把转换成符号型数据,每条记录表示一个事务
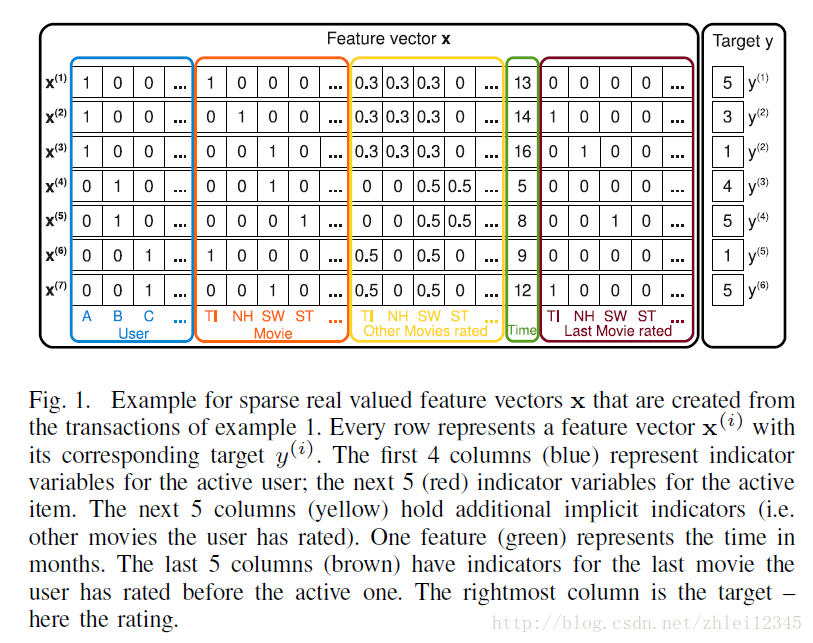
首先上图中蓝框中的数据表示用户信息,是指示型数据,表示一条记录中的用户,蓝框中的第一列表示是否是用户A,第二列表示是否是用户B等等。橘红色框表示这个事务中用户看的是那部电影,橘红框中的每条记录只有一个是1,其他的都为零。黄色框中表示用户都对哪些电影评过分,比如A对TI,NH,SW三部电影评过分,那么前三列为0.3,0.3,0.3 ,这里是将数据标准化了,使得每条记录值相加为1,绿色框表示的是时间,确定一个起始时间,数值表示距离起始时间的时间,最后一个框表示用户在评过事务中的这不电影前,还评过其他的哪些电影,预测值为Y,最后一列,表示用户对这部电影的评分。
我们的输入就类似这种情况,如果用户量非常多,电影量也非常多,那么这个输入是相当稀疏的,使用支持向量机之类的模型就显得力不从心,所以作者引出了因子机。
3.模型描述
因子机有度的概念,其实就是表示是多少个自变量相互影响,我们先从2度开始描述 ,假设需要预测的变量为Y,我们需要通过一个预测值 Y^ 来对Y进行预测,然后给定一个损失函数,最小化Y和 Y^ 之间的差距。
其中
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 24
24

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









