







广度优先搜索算法BFS(Breadth First Search)
对于广度优先搜索的原理,在CSDN上有很多博主已经介绍过了,可以参考下边的几篇博客。简单来讲的话广度优先搜索算法(Breadth First Search)就是优先搜索完距离自己最近的节点,然后一层一层像是摊饼一样进行搜索,是一种面积最大化的搜索方式。
广度优先搜索 - 一只程序猿 - CSDN博客 https://blog.csdn.net/hihozoo/article/details/51173175
算法(三):图解广度优先搜索算法 - 风无言 - CSDN博客 https://blog.csdn.net/a8082649/article/details/81395359
相信大家已经对广度优先搜索算法BFS有了一个最初步的概念,下面来讲一下他的python算法实现。
对于python实现部分主要是参考GitHub上几个印度小哥做的python算法新手入门大全,github链接如下: https://github.com/TheAlgorithms/Python ,整个项目包含很多基础的算法,包括排序算法、搜索算法、插值算法、跳跃搜索算法、快速选择算法、禁忌搜索算法、加密算法等。在这里就不一一介绍了,这篇文章相关的主要是图形搜索算法,对应的模块是 https://github.com/TheAlgorithms/Python/tree/master/graphs
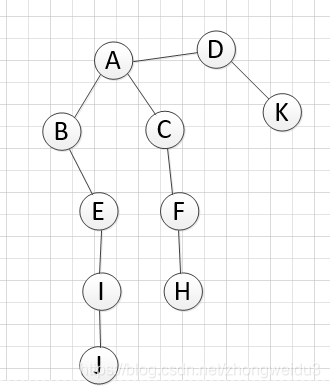
以这样一个图的搜索作为例子,目标是从A点出发遍历所有节点。
广度优先度算法BFS的python代码实现
# encoding=utf8
"""pseudo-code"""
"""
BFS(graph G, start vertex s):
// all nodes initially unexplored
mark s as explored
let Q = queue data structure, initialized with s
while Q is non-empty:
remove the first node of Q, call it v
for each edge(v, w): // for w in graph[v]
if w unexplored:
mark w as explored
add w to Q (at the end)
"""
# collections 是 python 内建的一个集合模块,里面封装了许多集合类,其中队列相关的集合只有一个:deque。
# deque 是双边队列(double-ended queue),具有队列和栈的性质,在 list 的基础上增加了移动、旋转和增删等。
import collections
def bfs(graph, start):
explored = set() # 已经访问过的节点集合
queue = collections.deque([start]) # 初始化队列
explored.add(start)
print("========explored sort=========")
while queue: # 只要队列queue不是空的,就一直循环(隐含的意思就是只要这个点还有新的相邻点,那么就一直往下面进行搜索)
# print(queue)
v = queue.popleft() # queue.popleft() #popleft,左边弹出元素,弹出的元素作为起始点,去查找相邻的点
print(explored)
for w in graph[v]: # 遍历当前起始点的相邻点
if w not in explored:
explored.add(w) # 如果这个相邻点没有在已经探索过的集合里,那么就把这个相邻点加到探索过的集合里
queue.append(w) # 如果这个相邻点没有在已经探索过的集合里,那么就把这个相邻点压到队列里,在队列尾添加元素
print("============All explored result==========")
return explored
G = {'A': ['B','C','D'], # 无向图,表示A和B\C\D直接连接
'B': ['A','E'],
'C': ['A','F'],
'D': ['A','K'],
'E': ['B','I'],
'F': ['C','H'],
'H':['F'],
'I':['E','J'],
'J':['I'],
'K':['D']}
print(bfs(G, 'A'))
BFS执行结果,可以看出广度优先搜索先把A相邻的节点BCD全都搜索完了,然后搜索“第三层”EFK,然后搜索“第四层”HI,最后才是第五层 J,也就是面积优先的一层一层往外搜索。queue遵循先进先出的选择
python BFS.py
========explored sort=========
set(['A'])
set(['A', 'C', 'B', 'D'])
set(['A', 'C', 'B', 'E', 'D'])
set(['A', 'C', 'B', 'E', 'D', 'F'])
set(['A', 'C', 'B', 'E', 'D', 'F', 'K'])
set(['A', 'C', 'B', 'E', 'D', 'F', 'I', 'K'])
set(['A', 'C', 'B', 'E', 'D', 'F', 'I', 'H', 'K'])
set(['A', 'C', 'B', 'E', 'D', 'F', 'I', 'H', 'K'])
set(['A', 'C', 'B', 'E', 'D', 'F', 'I', 'H', 'K', 'J'])
set(['A', 'C', 'B', 'E', 'D', 'F', 'I', 'H', 'K', 'J'])
============All explored result==========
set(['A', 'C', 'B', 'E', 'D', 'F', 'I', 'H', 'K', 'J'])
深度优先算法 DFS
# encoding=utf8
"""pseudo-code"""
"""
DFS(graph G, start vertex s):
// all nodes initially unexplored
mark s as explored
for every edge (s, v):
if v unexplored:
DFS(G, v)
"""
def dfs(graph, start):
"""The DFS function simply calls itself recursively for every unvisited child of its argument. We can emulate that
behaviour precisely using a stack of iterators. Instead of recursively calling with a node, we'll push an iterator
to the node's children onto the iterator stack. When the iterator at the top of the stack terminates, we'll pop
it off the stack."""
# explored, stack = set(), [start]
explored = set()
stack = [start] # 相当于list类型变量实现stack
explored.add(start)
print("========explored sort=========")
while stack:
v = stack.pop() # the only difference from BFS is to pop last element here instead of first one
print(explored)
for w in graph[v]:
if w not in explored:
explored.add(w)
stack.append(w)
print("============All explored result==========")
return explored
G = {'A': ['B','C','D'], # 无向图,表示A和B\C\D直接连接
'B': ['A','E'],
'C': ['A','F'],
'D': ['A','K'],
'E': ['B','I'],
'F': ['C','H'],
'H':['F'],
'I':['E','J'],
'J':['I'],
'K':['D']}
print(dfs(G, 'A'))
深度优先算法DFS在终端的执行结果,可以看出来优先一条一条的进行搜索, ADK ACFH ABEIJ 除了一开始搜了三个分支 BCD后面就开始对每个分支进行搜索下去了。stack遵循后进先出的原则。
python DFS.py
========explored sort=========
set(['A'])
set(['A', 'C', 'B', 'D'])
set(['A', 'C', 'B', 'D', 'K'])
set(['A', 'C', 'B', 'D', 'K'])
set(['A', 'C', 'B', 'D', 'F', 'K'])
set(['A', 'C', 'B', 'D', 'F', 'H', 'K'])
set(['A', 'C', 'B', 'D', 'F', 'H', 'K'])
set(['A', 'C', 'B', 'E', 'D', 'F', 'H', 'K'])
set(['A', 'C', 'B', 'E', 'D', 'F', 'I', 'H', 'K'])
set(['A', 'C', 'B', 'E', 'D', 'F', 'I', 'H', 'K', 'J'])
============All explored result==========
set(['A', 'C', 'B', 'E', 'D', 'F', 'I', 'H', 'K', 'J'])


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









