






方法:
1、字典匹配(容易区分)
2、隐马模型(不容易区分)
3、动态规划(viterbi)
案例1:基于字典匹配的方法

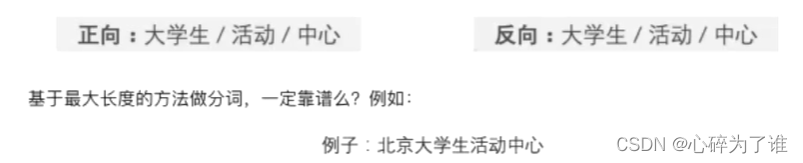
按最大长度匹配!!!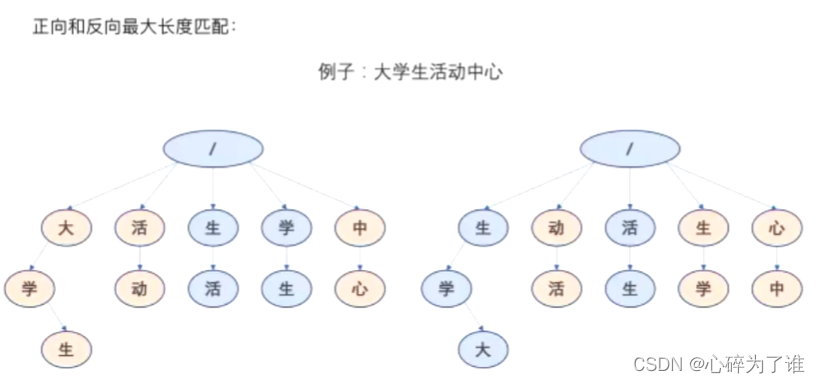
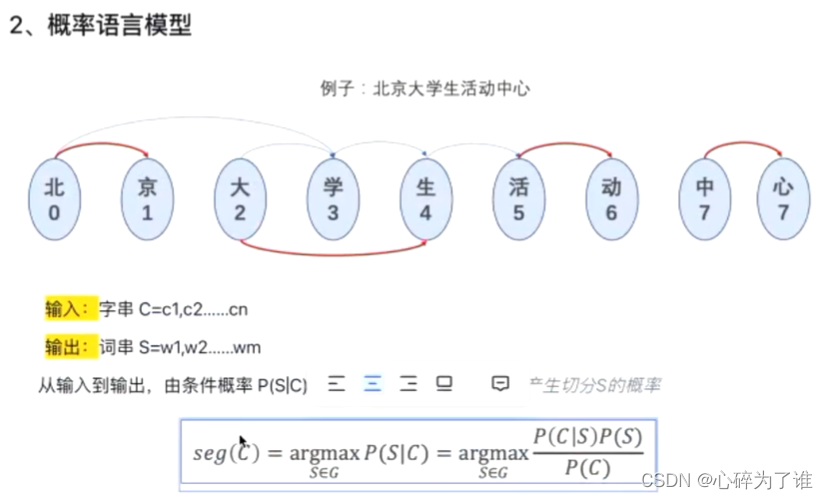
P(S|C): 切成想要的断句的样子的概率。
P(C): 恒定值。例如,100个句子,每个句子的概率为1/100,在这里面可以不用关心这个值。
P(C|S): C原始句子,S分词方案,即分词方案还原成原始句子的概率,这里为1.


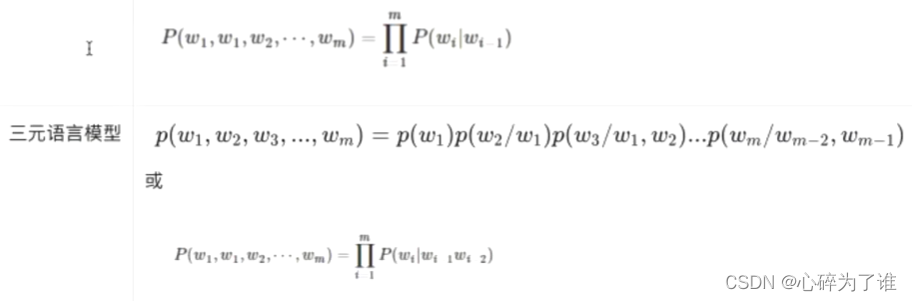
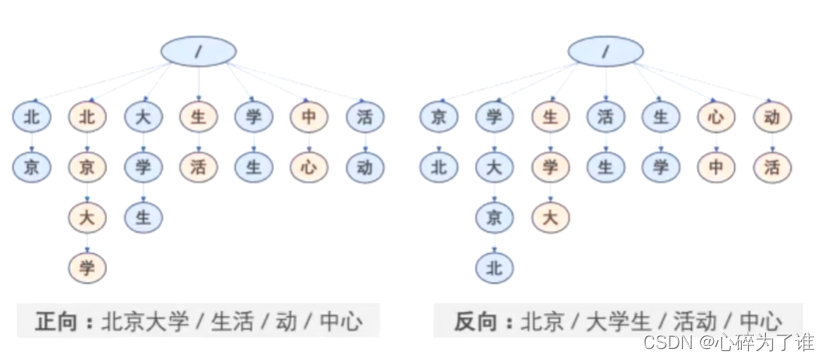
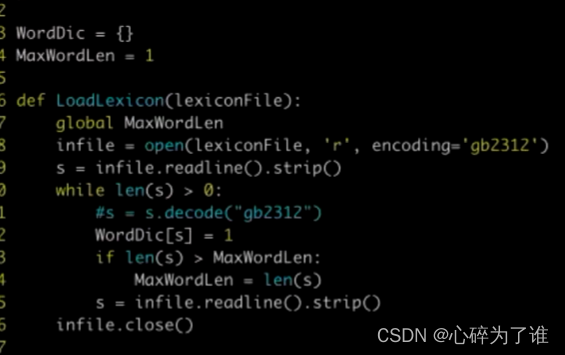
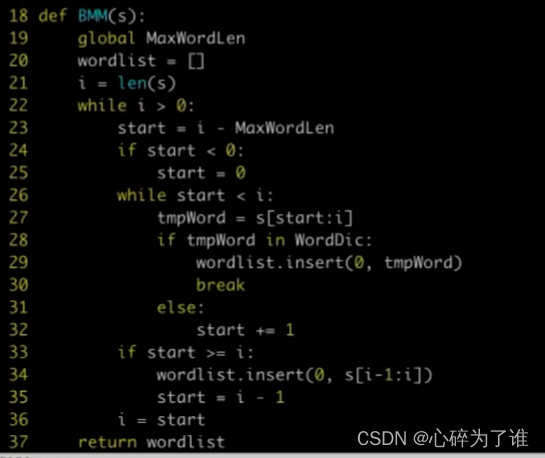
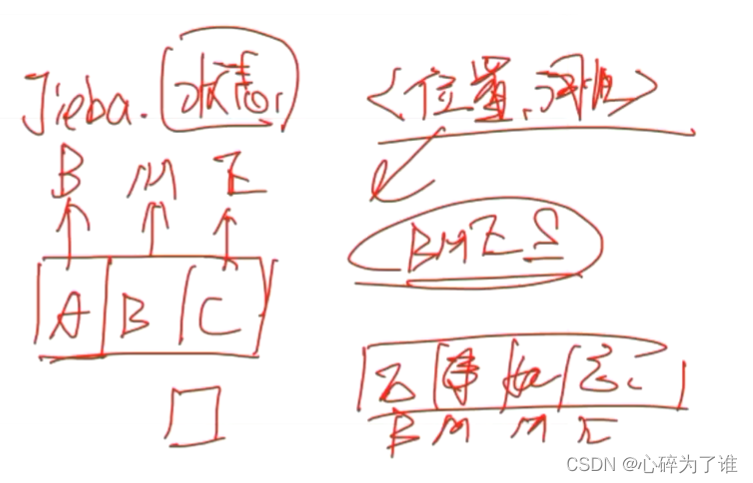
最大长度匹配(反向分词)代码:
词库中确认最大词长度,然后用这个长度在待分词中去截取相应长度,例如7,然后逐渐缩短这个截取长度的词,在词库里面遍历,看是否能够查询到相应词,查询到后记录下标,往前数7,然后重复操作
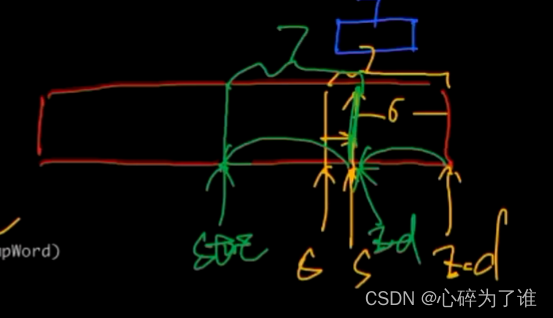
最大概率:
一元语言模型概率:词出现次数/词总数,就是单个词的概率
二元语言模型概率:
P(W1|W2):是条件概率
P(W1,W2):是联合概率,即当W1后面是W2的概率
P(W1):是W1的概率,具体数值看一元概率
这里面的二元概率是 :P(W1|W2)= P(W1,W2)/ P(W1)

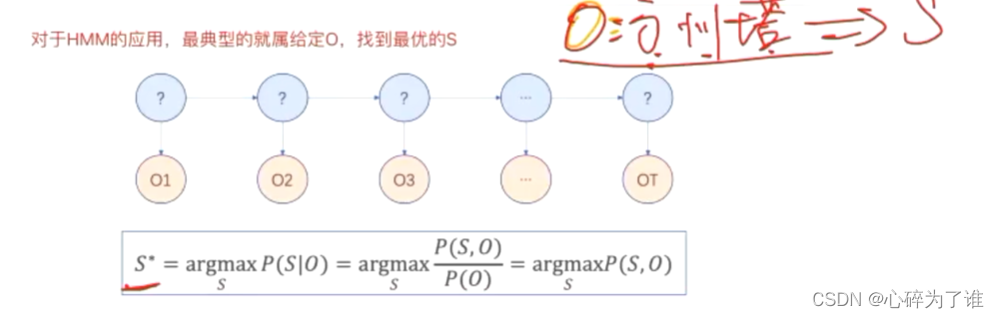
动态规划(viterbi):
记录到每个节点的最优路线,可重复使用

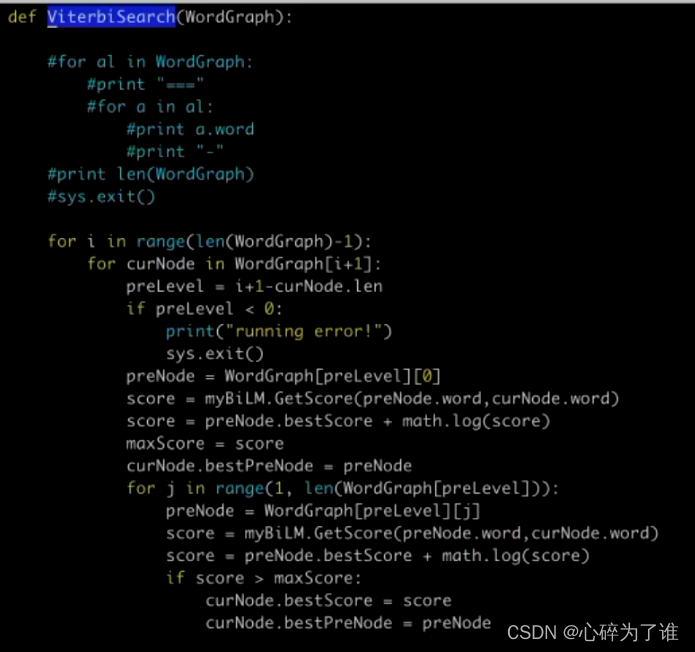
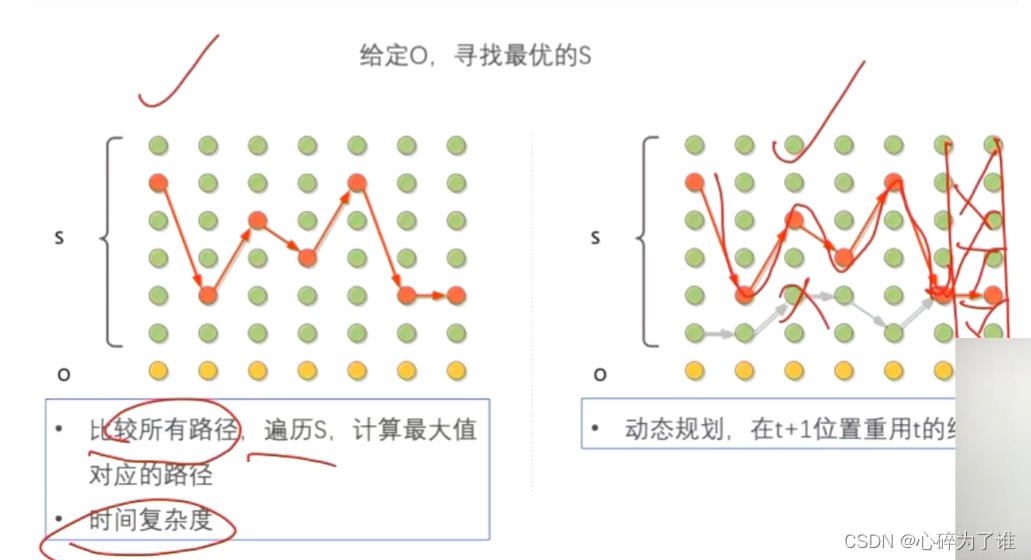
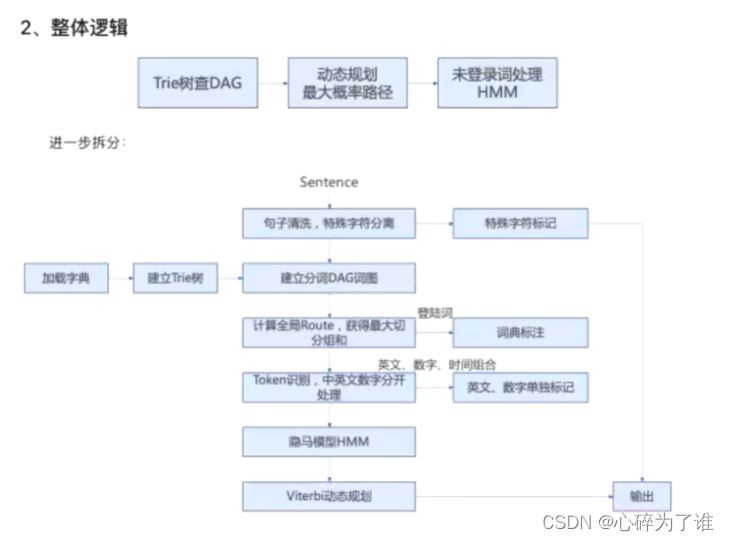
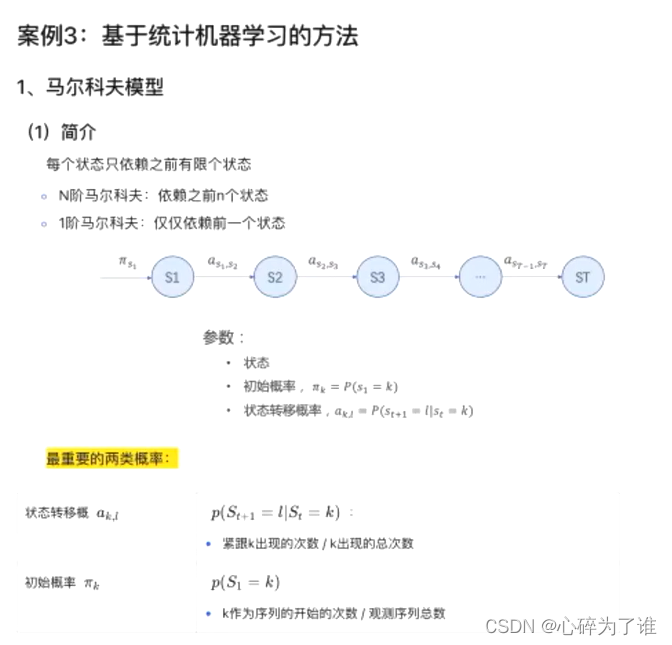
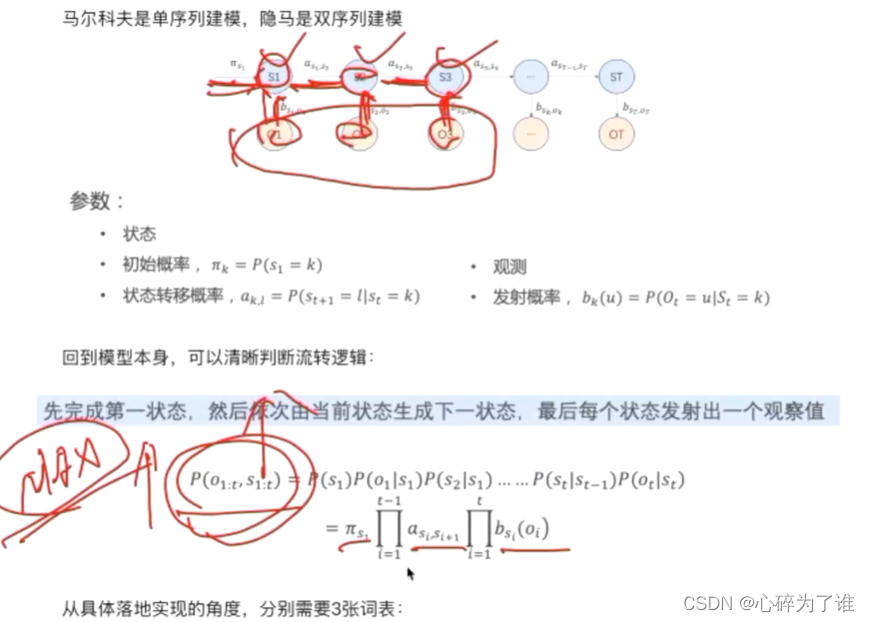


上述框中的图,试一个维特比
既是B又是广的出现次数/B的总次数
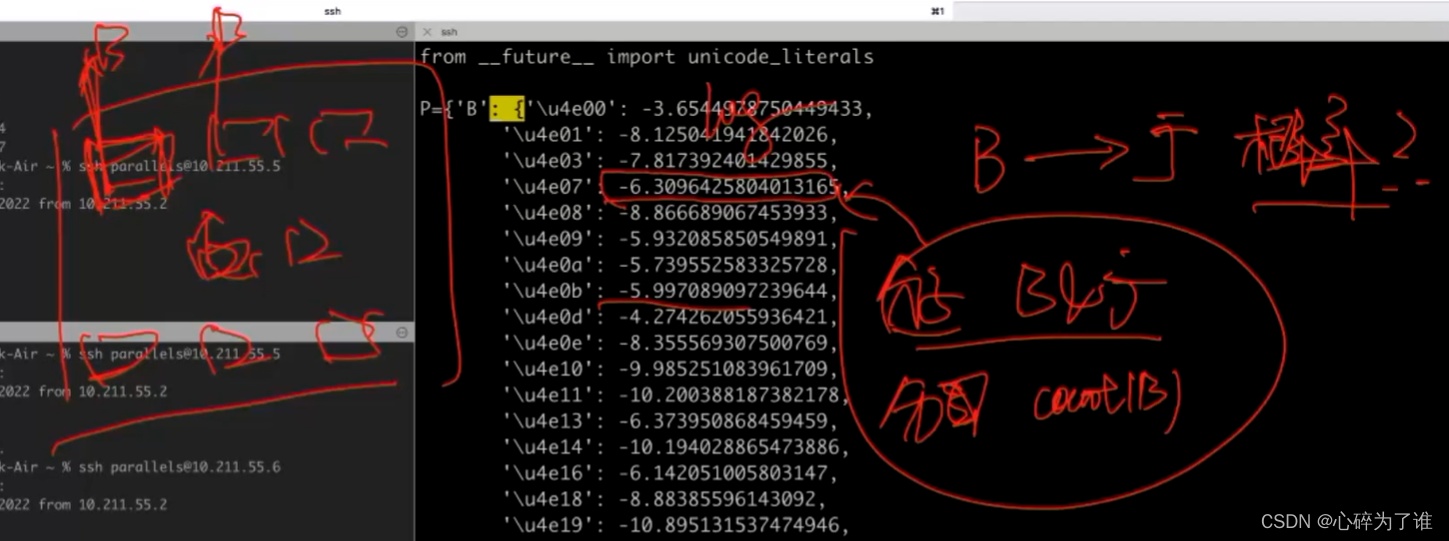

P(O):1,因为给定的字是固定的
1、批量分词
2、增量分词
这里面讲了一个数据的存储逻辑,这块很重要,去看第4节课
对不会在实时更新的数据可以用MapReduce进行处理,但是他没法处理实时数据。(批处理)MapReduce原理 - 知乎
数据处理:(流式处理:可以处理实时数据)
1、spark
2、storm过时
3、flink















 8万+
8万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









