







 本文探讨了blocked算法在数值应用中的优势,特别是如何通过调整数据块大小来减少数据缺失和提高缓存效率。研究了数据访问的stride对性能的影响,并揭示了传统全缓存策略的局限。文章还介绍了数据局部性和两种形式的重复使用(时空复用),强调了根据矩阵尺寸和内存参数定制块大小的重要性。最后,通过实例展示了在不同层次的内存体系中应用blocking技术以优化矩阵乘法性能。
本文探讨了blocked算法在数值应用中的优势,特别是如何通过调整数据块大小来减少数据缺失和提高缓存效率。研究了数据访问的stride对性能的影响,并揭示了传统全缓存策略的局限。文章还介绍了数据局部性和两种形式的重复使用(时空复用),强调了根据矩阵尺寸和内存参数定制块大小的重要性。最后,通过实例展示了在不同层次的内存体系中应用blocking技术以优化矩阵乘法性能。
Abstract
- Instead of operating on entire rows or columns of an array
- blocked algorithms
- operate on submatrices or block
- so that data loaded into the
- faster levels of the memory hierarchy
- are reused
- 这篇文章
- presents
- cache performance data for blocked programs
- evaluates several optimizations to improve this performance
- data is obtained by
- a theoretical model of data conflicts
- in the cache
- validated
- by large amounts of simulation
第二段
- cache缺失的程度
- highly sensitive to
- the stride of data accesses
- the size of the blocks
- highly sensitive to
- cause wide variations
- in machine performance
- for different matrix sizes
- The conventional wisdom
- trying to use the entire cache
- or even a fixed fraction of the cache
- is incorrect
我草!这不正确吗?
- If a fixed block size is used for a given cache size
- the block size
- that minimizes the expected number of cache misses is small
- Tailoring the block size
- according to the matrix size
- and cache parameters can improve the average performance
- reduce the variance in performance for different matrix sizes
意思是:block的尺寸要根据矩阵的尺寸和cache的参数
- beneficial
- copy non-contiguous reused data
- into consecutive locations
比如把map搞成vector
1 ntroduction
第二段
- data caches
- effective for general-purpose applications
- in bridging the processor and memory speeds
- their effectiveness for numerical code
- has not been established
- A characteristic of numerical applications
- they tend to operate on large data sets
感觉这个指矩阵操作吧??
- A cache
- only be able to hold a small fraction of a matrix
- even if the data are reused
- they may have been displaced from the cache
- by the time they are reused
上面是经典的话语!
1. 1 Blocking
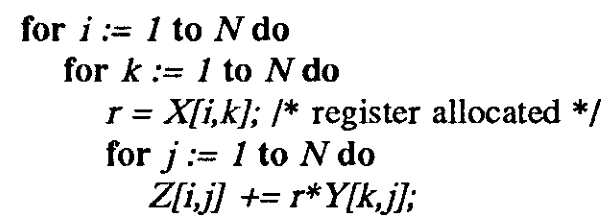
- (a):X(i,k) 重用 by innermost
- can be register allocated and
- fetched from memory only once
- can be register allocated and
- innermost accesses consecutive in Y and Z
- utilizes the cache prefetch mechanism fully
- The same row of Z accessed in an innermost
- reused in the next iteration of middle
- the same row of Y is reused in the outermost
上面说得对啊!
- Whether the data remains in the cache
- at the time of reuse
- depends on the size of cache
- Unless cache is large enough
- to hold at least one N x N matrix
- Y would have been displaced before reuse
Y是最倒霉的,因为他的重利用距离太远啦!
- If the cache cannot hold even one row of the data
- then Z in the cache cannot be reused
- worst case:
-
2
N
3
+
N
2
2N^3+N^2
2N3+N2
- words of data need
- to be read from memory in N 3 N^3 N3 iterations
-
2
N
3
+
N
2
2N^3+N^2
2N3+N2
你每次访存都需要从内存读,那你不就垃圾了吗!,正好是 2 N 3 + N 2 2N^3+N^2 2N3+N2
- high ratio of memory fetches to numerical operations
- can significantl slow down the machine
下一段
- memory hierarchy can be better utilized
- if scientific algorithms are blocked [1, 5, 6,8, 10, 11, 12]
- Blocking
- also tiling.
- Instead of operating on individual matrix entries
- the calculation is performed on submatrices
- Blocking can be applied to
- any and multiple levels of memory hierarchy
- virtual memory,
- caches, vector registers,
- scalar registers
- when blocking is applied at both the register and cache levels,
- matrix multiplication speeds up
- 4.3 on a Decstation 3100
- 3.0 on an IBM RS/6000,
- relatively higher performance memory subsystem
- matrix multiplication
- blocked to reduce cache misses
- looks like
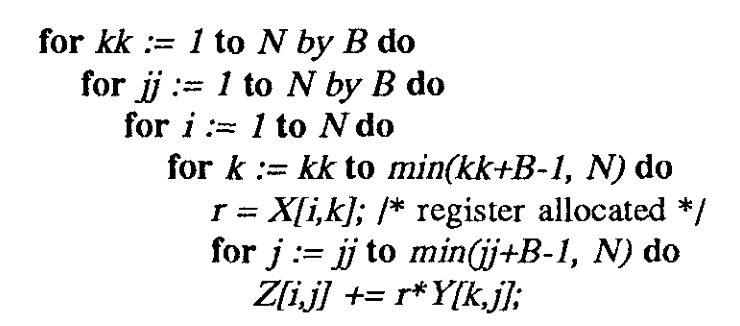
- (b )
- original data access pattern is reproduced here,
- but at a smaller scale.
- The blocking factor, B,
- is chosen so that the B x B submatrix of Y and a row of length B of Z can fit in the cache.
- Y and Z are reused B times each time the data are brought in.
- total memory words accessed
- is 2 N 3 / B + N 2 2N^3/B + N^2 2N3/B+N2
- if there is no interference in the cache
2 Data Locality in Blocked Algorithms
- present our cache model for the simple case
- a direct-mapped cache with one-word cache lines
- illustrate the model with blocked matrix multiplication
- set-associative caches
- and multiple-word line sizes
- described in Section 5
- The reuse of a reference is carried by a loop
- if the same memory locations or cache lines
- are used by different iterations of that loop
- two forms of reuse: temporal and spatial
- Temporal
- when the same data are reused
- in matrix multiplication, the temporal reuse of variablesX, Z and y are carried by the innermost, middle and outermost loops respectively
- In this case
- each variable is reused N times,
- the size of each loop
- the reuse factor
- Spatial reuse occurs when data in the same cache line are used
- For a cache with line size 1
- the reuse factor is if the data is accessed in a stride one manner



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











