







双塔模型: 模型和训练
双塔模型简介
双塔模型可以看作矩阵补充的升级版,用户物品向量中考虑了其他属性,且最后用余弦相似度表示用户对物品的感兴趣程度(两向量之间夹角的余弦值,取值范围[0,1])
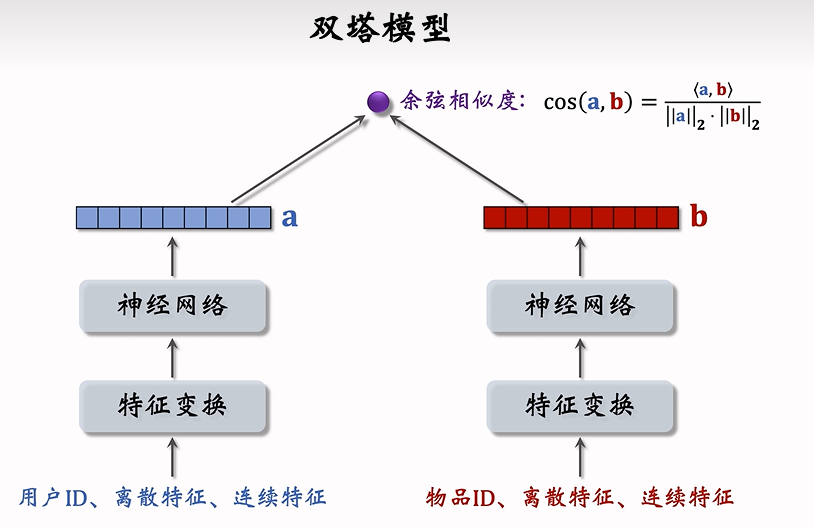
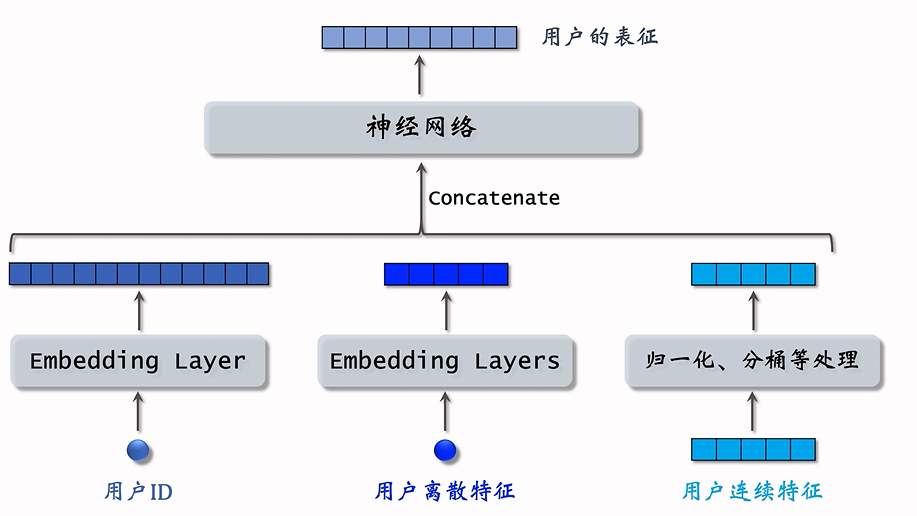
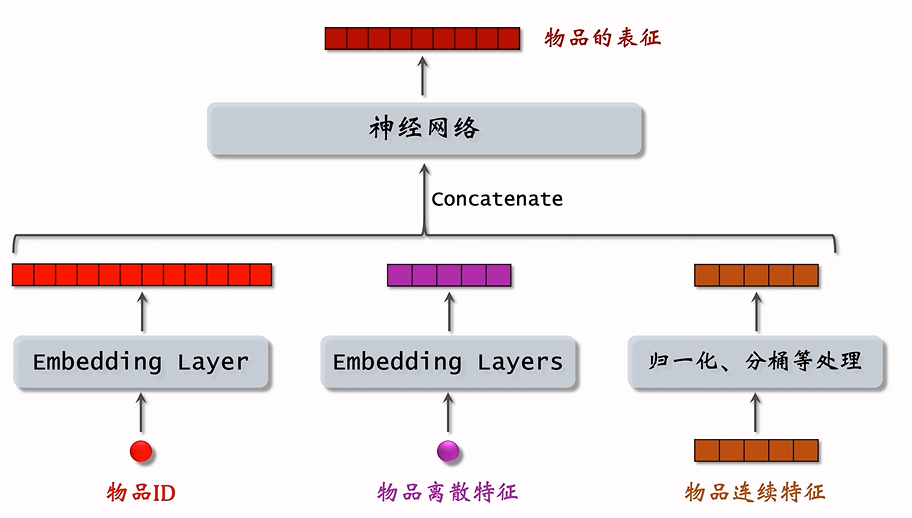
双塔模型的训练
- Pointwise:独立看待每个正,负样本,做简单的二元分类来训练模型。把正样本和负样本组成一个数据集,在数据集上做随机梯度下降来训练双塔模型。
- Pairwise:每次取一个正样本,一个负样本组成一个二元组(参考论文1 - facebook发表)
- Listwise:每次取一个正样本,多个负样本组成一个list(参考论文2 - YouTube发表)

正负样本的选择
双塔模型如何正负样本,请参考 双塔模型之如何选择正确的正负样本

Pointwise
Pointwise是最简单的训练方式,它把召回看做二元分类任务。
- 对于正样本,鼓励 cos(a,b)接近 +1。
- 对于负样本,鼓励 cos(a,b)接近 -1。
- 控制正负样本数量为1:2或者1:3 (业内的经验)。
Pairwise
基本想法: 让cos(a,b+) > cos(a,b-),且二者差越大越好
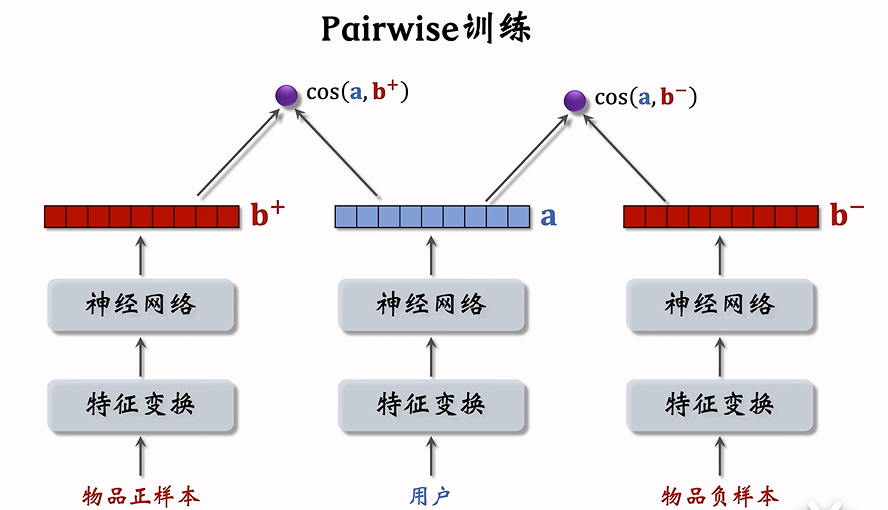
- 如果cos(a,b+)大于cos(a,b)+m,则没有损失。(m是给定的超参数)
- 否则,损失等于cos(a,b) + m - cos(a,b+)
损失函数
训练的过程就是对损失函数求最小化,用梯度更新神经网络的参数

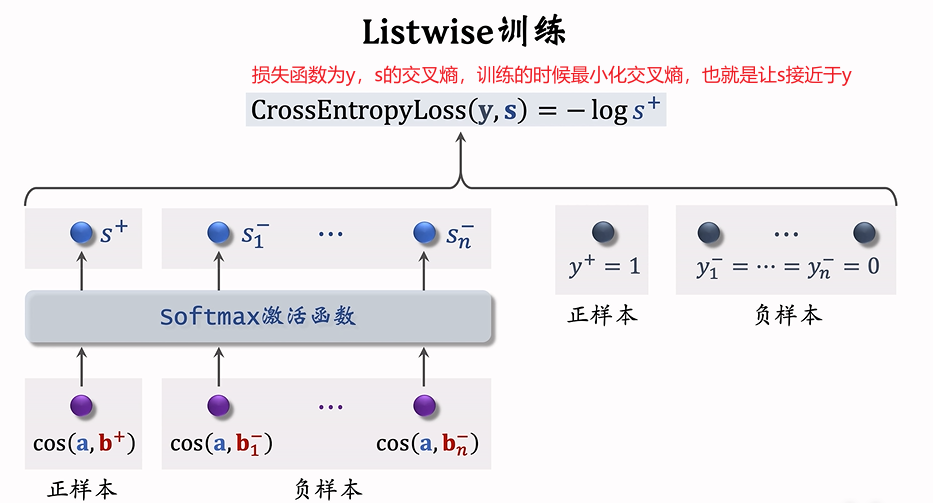
Listwise
Listwise训练每次取一个正样本(如用户的历史记录显示用户喜欢这个样本)和多个负样本
一条数据包含:
一个用户,特征向量记作a。
一个正样本,特征向量记作 b+
多个负样本,特征向量记作 b1-,…,bn-
- 鼓励 cos(a,b+)尽量大。
- 鼓励 cos(a,b1+),…,cos(a,bn+)尽量小。
总结

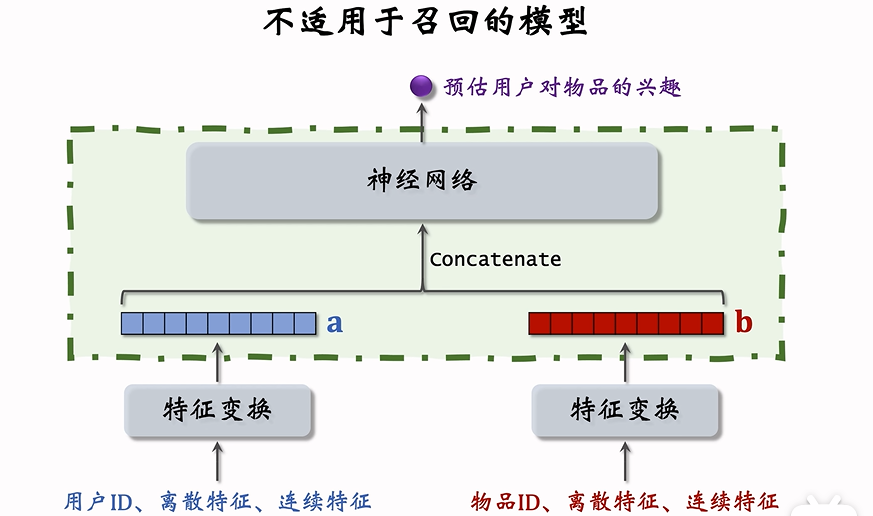
不适合用于召回的模型
下面这种结构是前期融合的模型,前期融合的模型一般就是粗排或精排的模型。召回模型一般是后期融合模型。
原因如下:
- 这种神经网络属于前期融合,在进入全连接层之前就把特征向量拼起来了。而双塔模型属于后期融合,两个塔在最终输出相似度的时候才融合起来
- 假如把这种模型用于召回,就必须把所有物品的特征都挨个输入模型,预估用户对所有物品的兴趣。假如有一亿个物品,每给用户做一次召回,需要跑一亿次模型,计算量太大且无法用近似最近邻查找加大计算。
- 这种模型适用于排序,从几千个物品中选出几百个,计算量不会太大

















 2894
2894

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









