






注:本文是关于北京邮电大学鲁鹏老师计算机视觉与深度学习课程全连接神经网络部分内容的笔记与一些个人理解。
课程视频链接
全连接神经网络
全连接神经网络模型
两层全连接神经网络模型如下:
f
=
W
2
m
a
x
(
0
,
W
1
x
+
b
1
)
+
b
2
f = W_2max(0,W_1x+b_1)+b_2
f=W2max(0,W1x+b1)+b2
是由线性分类器组合起来的,max为激活函数。在线性分类器中W可以看作模板,模板个数由类别个数决定。在全连接神经网络中
W
1
W_1
W1也可以看作模板,模板个数人为指定,可以认为是每一个类别可以拥有不止一个模板,一个类别可以有多个模板,然后
W
2
W_2
W2融合这多个模板的匹配结果来实现最终的打分。关于每个参数的维度,
W
1
W_1
W1的行数由我们自己来定义也就是模板个数人为指定,列数就是输入图像的维度,
b
1
b_1
b1的维度就应该是与
W
1
W_1
W1的行数相同,1列,而
W
2
W_2
W2的行数就是类别数,列数就是我们人为指定的
W
1
W_1
W1的行数。例如,有10类,我们输入的图像是
3072
×
1
3072 \times 1
3072×1维,指定
W
1
W_1
W1的行数为100,所以
W
1
W_1
W1的维度就是
100
×
3027
100 \times 3027
100×3027维,
W
1
W_1
W1与x相乘后得到的矩阵维度就是
100
×
1
100 \times 1
100×1维,
b
1
b_1
b1为
100
×
1
100 \times 1
100×1维,加上后维度不变,再通过max函数,维度不会发生变化,而
W
2
W_2
W2为
10
×
100
10 \times 100
10×100维,与
W
1
W_1
W1相乘后就得到了
10
×
1
10 \times 1
10×1维。
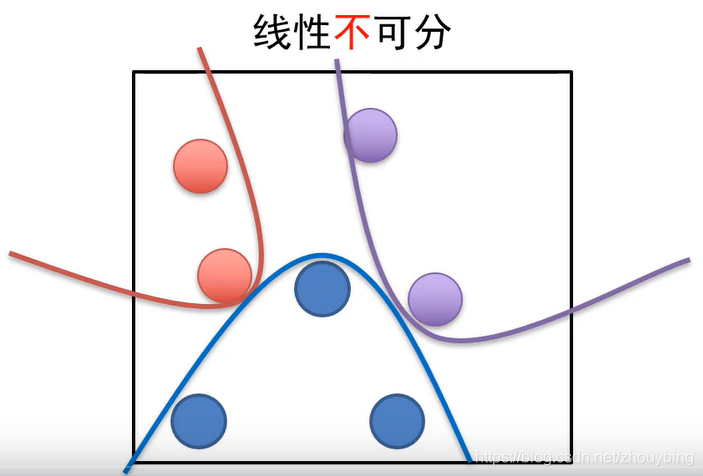
全连接神经网络可以用来解决线性不可分平面的分类问题。
全连接神经网络的表示方法:
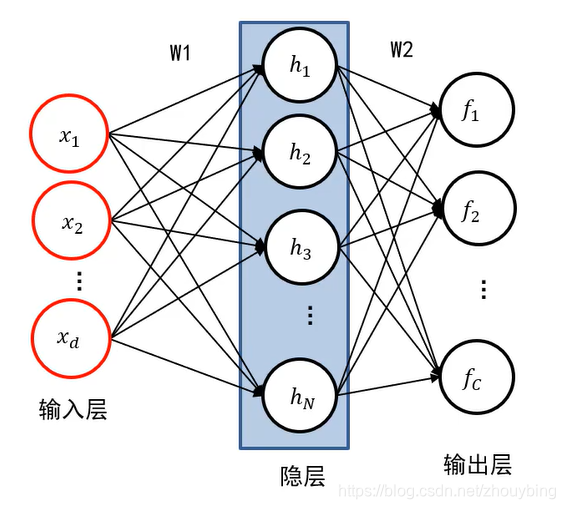
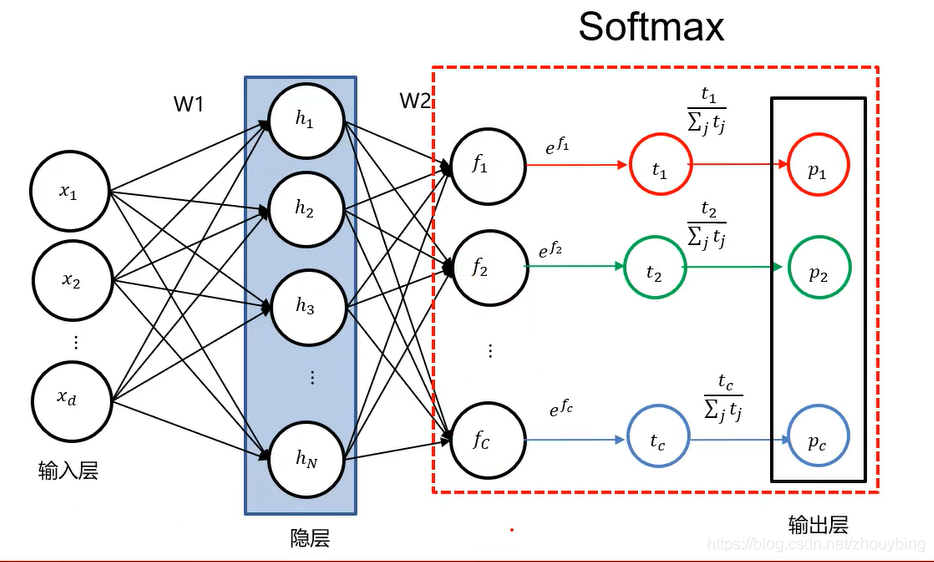
如图为一个两层全连接神经网络的表示,两层就是除输入层还剩下两层。输入层就表示为我们输入的图像,输入层的维度也就是输入图像的维度,也就有d个神经元。中间的隐层就相当于 W 1 × x W_1 \times x W1×x后的结果,其神经元的个数就是我们指定的模板的个数也就是 W 1 W_1 W1的行数。最后是输出层,其神经元的个数就是类别数。其输入层到隐层的边,就相当于 W 1 W_1 W1,x经过与 W 1 W_1 W1相乘的运算后得到隐层,如图可知,上一层的每一个神经元与下一层的每一个神经元都有连接,因此被称为全连接神经网络。
注意在全连接神经网络的模型中我们必须要激活函数,比如下面是一个三层全连接神经网络的模型:
f
=
W
3
m
a
x
(
0
,
W
2
m
a
x
(
0
,
W
1
x
+
b
1
)
+
b
2
)
+
b
3
f=W_3max(0,W_2max(0,W_1x+b_1)+b_2)+b_3
f=W3max(0,W2max(0,W1x+b1)+b2)+b3
如果去掉激活函数:
f
=
W
3
W
2
W
1
x
+
W
3
W
2
b
1
+
W
3
b
2
+
b
3
=
W
x
+
b
f=W_3W_2W_1x+W_3W_2b_1+W_3b_2+b_3=Wx+b
f=W3W2W1x+W3W2b1+W3b2+b3=Wx+b
显然去掉激活函数后全连接神经网络的模型就变成了一个线性分类器。
常用的激活函数
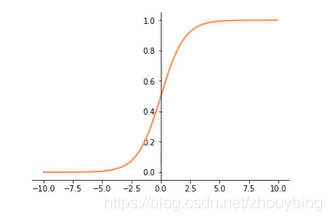
Sigmoid:
f
=
1
(
1
+
e
−
x
)
f = \frac{1}{(1+e^{-x})}
f=(1+e−x)1
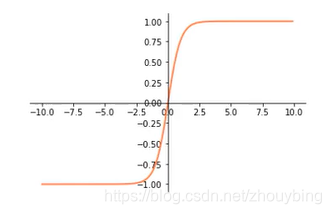
tanh:
f
=
e
x
−
e
−
x
e
x
+
e
−
x
f = \frac{e^x-e^{-x}}{e^x+e^{-x}}
f=ex+e−xex−e−x
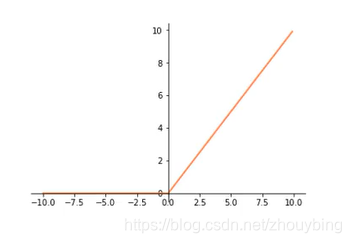
ReLU:
f
=
m
a
x
(
0
,
x
)
f = max(0,x)
f=max(0,x)
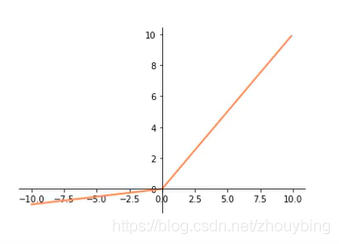
Leaky ReLU:
f
=
m
a
x
(
0.1
x
,
x
)
f = max(0.1x,x)
f=max(0.1x,x)
在选择激活函数时尽量选择ReLU函数或Leakly ReLU函数,相对于Sigmoid和tanh,ReLU和Leakly ReLU函数会让梯度流更加顺畅,训练过程收敛得更快。
网络结构设计
关于要用多少个隐层,每个隐层要设置多少个神经元,并没有一个统一的答案。依据分类任务的难易程度来调整神经网络模型的复杂程度。分类任务越难,我们设计的神经网络结构就应该越深,越宽。但是,需要注意的是对训练集分类精度最高的全连接神经网络模型,在真实场景下识别性能未必是最好的(过拟合)。

由图可知神经元个数越多,分界面就可以越复杂,在这个集合上的分类能力就越强。
SOFTMAX
在计算出输出层的得分后,我们可以通过softmax操作将得到的分数转换成概率分布。
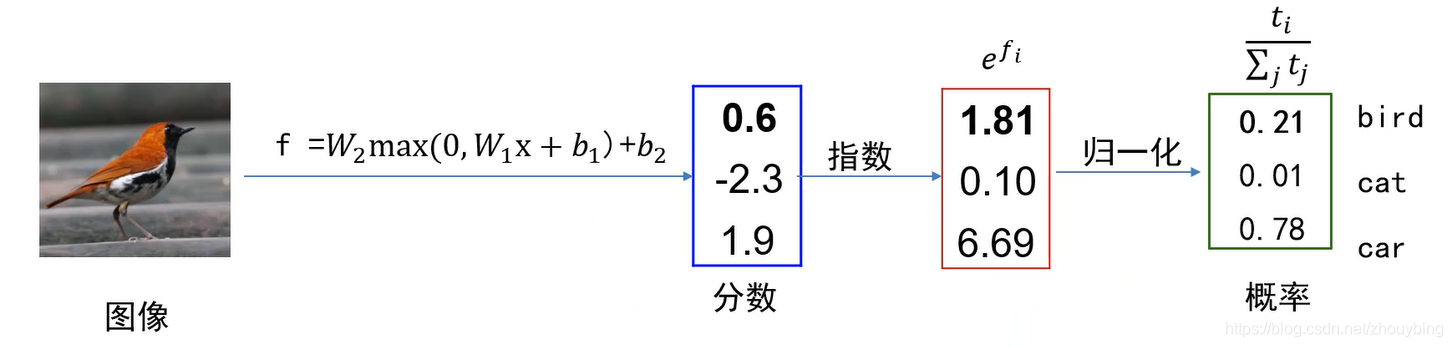
如图所示,先将得到的分数取e的指数得到t,再计算出t的概率,就得到了进过softmax操作后新的输出层,表示为概率。
交叉熵损失
在通过softmax操作后,我们要如何计算损失呢,如图。
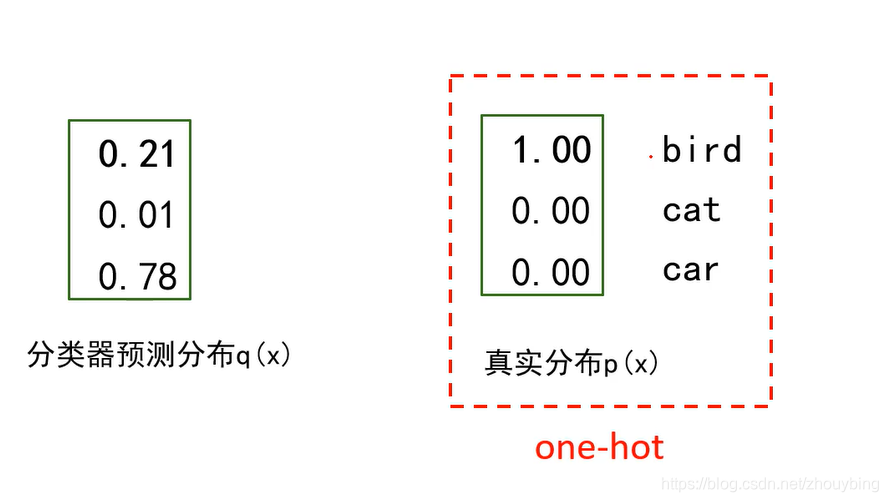
在softmax操作后计算损失就是要计算分类器预测分布于真实分布的距离,就要用到交叉熵。
熵
:
H
(
p
)
=
−
∑
x
p
(
x
)
l
o
g
p
(
x
)
交
叉
熵
:
H
(
p
,
q
)
=
−
∑
x
p
(
x
)
l
o
g
q
(
x
)
相
对
熵
:
K
L
(
p
∣
∣
q
)
=
−
∑
x
p
(
x
)
l
o
g
q
(
x
)
p
(
x
)
\begin{aligned} 熵:H(p)=-\sum_xp(x)logp(x)\\ 交叉熵:H(p,q)=-\sum_xp(x)logq(x)\\ 相对熵:KL(p||q)=-\sum_xp(x)log\frac{q(x)}{p(x)} \end{aligned}
熵:H(p)=−x∑p(x)logp(x)交叉熵:H(p,q)=−x∑p(x)logq(x)相对熵:KL(p∣∣q)=−x∑p(x)logp(x)q(x)
其中相对熵也叫KL散度,可以用来度量两个分布之间的不相似性。那为什么在这里我们不使用相对熵而使用交叉熵,对交叉熵变形:
H
(
p
,
q
)
=
−
∑
x
p
(
x
)
l
o
g
q
(
x
)
=
−
∑
x
p
(
x
)
l
o
g
p
(
x
)
−
∑
x
p
(
x
)
l
o
g
q
(
x
)
p
(
x
)
=
H
(
p
)
+
K
L
(
p
∣
∣
q
)
\begin{aligned} H(p,q)=-\sum_xp(x)logq(x)\\ =-\sum_xp(x)logp(x)-\sum_xp(x)log\frac{q(x)}{p(x)}\\ =H(p)+KL(p||q) \end{aligned}
H(p,q)=−x∑p(x)logq(x)=−x∑p(x)logp(x)−x∑p(x)logp(x)q(x)=H(p)+KL(p∣∣q)
而因为真实分布的特殊,可得
H
(
p
)
H(p)
H(p)为0,也就是交叉熵与相对熵在one-hot形式下的真实分布下是相等的。
交叉熵损失与多类支持向量机损失比较

观察第二行数据,多类计算出来的损失为0,而交叉计算出来的损失为0.2差距有点大,为什么呢,因为根据多类的规则只要真实的分数比其他的分数都大于1就认为损失为0,在第二行中10恰好比其他分数都大1,因此多类计算出来的损失为0,而对于交叉来说,是根据概率分布来计算损失的,而10在所有分数中占的比重就比0.3大一点,计算出来的损失自然比0要大一些。因此可以看出交叉熵不仅仅要求真实标签对应的分数要是最大的还要求其对应的分数占的比重要大,也就是其他的分数要小。
计算图与反向传播
计算图是一种有向图,它用来表达输入,输出以及中间变量之间的计算关系,图中的每个节点对应着一种数学运算。

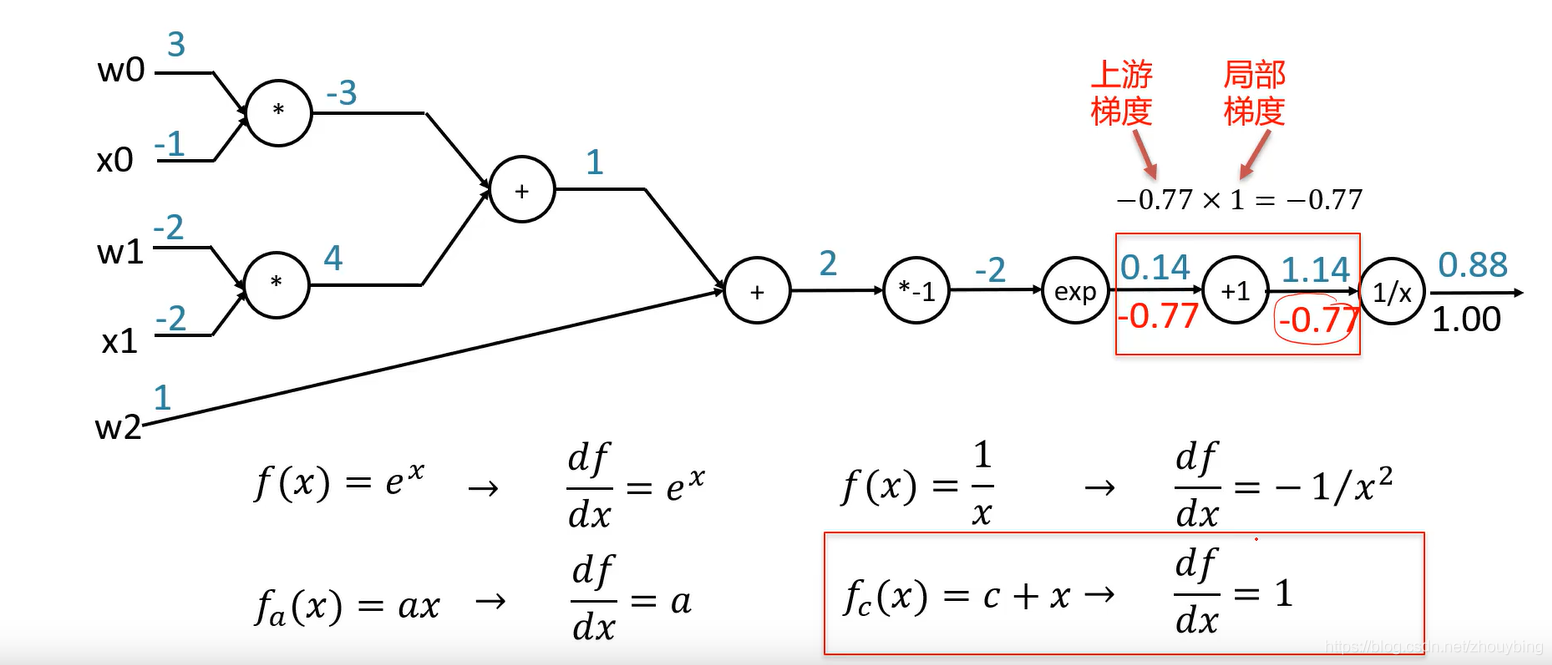
所谓反向传播就是从后往前计算局部梯度,并利用链式法则一步步计算出最终的梯度。例如。
f
(
w
,
x
)
=
1
1
+
e
w
0
x
0
+
w
1
x
1
+
w
2
f(w,x)=\frac{1}{1+e^{w_0x_0+w_1x_1+w_2}}
f(w,x)=1+ew0x0+w1x1+w21
的计算图。
梯度算法的改进
梯度下降算法容易在山壁间震荡,往谷底方向的行进较慢。
动量法
利用累加历史梯度信息更新梯度

动量法有机会能摆脱局部最小点和鞍点,达到全局最小点。
自适应梯度与RMSProp
自适应梯度法通过减小震荡方向的歩长,增大平坦方向歩长来减小震荡,加速通往谷底的方向。那么就要区分震荡方向与平坦方向,我们认为梯度幅度的平方较大的方向是震荡方向,梯度幅度的平方较小的方向是平坦方向。
AdaGrad

AdaGrad是一种自适应的梯度算法。如果是震荡方向,那么梯度的平方就会较大,对应的r就会大,因此学习率就会小,歩长也就小了,反之同理。但是这个算法也存在一个缺点,因为r是一直在累加,会一直慢慢变大,当r越来越大,学习率就会保持很小,也就失去了对歩长的调节作。
RMSProp

在AdaGrad的基础上给r设置了衰减。
ADAM
ADAM结合了动量法和自适应梯度的思想。

注意在ADAM中存在修正偏差的一个操作,这是为了解决冷启动的问题,所谓冷启动就是在算法执行的初期,v和r都是0,梯度和梯度的平方的权重都很小,那么一开始v和r一定是一个很小的值,这样的话不利于算法的启动,因此需要修正v和r,t代表迭代次数,最开始t为1,v和r都除以一个小于0的数,就会放大v和r的值,就可以让算法很快的启动起来,等迭代许多次后,t一直增大,慢慢的分母的部分就趋于1,这是修正后的v和r就接近原本的v和r。















 1574
1574











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









