







一、感知机

一个感知器有如下组成部分:
- 输入权值 一个感知器可以接收多个输入
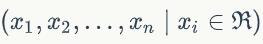 ,每个输入上有一个权值wi此外还有一个偏置项b,就是上图中的w0。
,每个输入上有一个权值wi此外还有一个偏置项b,就是上图中的w0。 - 激活函数 感知器的激活函数可以有很多选择,比如我们可以选择下面这个阶跃函数来作为激活函数:
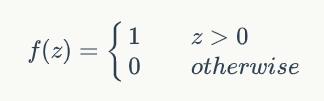
- 输出 感知器的输出由下面这个公式来计算

感知机基础实现代码:
#定义感知机类
class Perceptron(object):
#初始化感知机,设初值为0
def __init__(self, input_num, activator):
self.weights = [0.0 for _ in range(input_num)]
self.bias = 0.0
#输出权重及偏移量
def __str__(self):
return 'weights\t:%s\nbias\t:%f\n' % (self.weights, self.bias)
#输出感知机预测结果
def predict(self, input_vec):
return self.activator( reduce(lambda a, b: a + b, map(lambda x, w: x * w,zip(input_vec, self.weights)), 0.0) + self.bias)
'''
函数解释:
zip():将input_vec[x1,x2,x3...]与weights[w1,w2,w3,...]打包成为[(x1,w1),(x2,w2),(x3,w3),...]
lambda :匿名函数定义方式,形如‘lambda a, b : a * b’,将input_vec与self.weights逐项相乘
map():根据提供的函数对指定序列做映射,将lambda结果映射出来
reduce():函数会对参数序列中元素进行累积,在此处的作用是以“lambda a, b: a + b”的方式逐个累加
注意需要调用from functools import reduce才能使用该函数
'''
#根据训练轮数、学习率训练数据
def train(self, input_vecs, labels, iteration, rate):
for i in range(iteration):
self._one_iteration(input_vecs, labels, rate)
#迭代函数
def _one_iteration(self, input_vecs, labels, rate):
# 把输入和输出打包在一起,成为样本的列表[(input_vec, label), ...],每个训练样本是(input_vec, label)
samples = zip(input_vecs, labels)
# 对每个样本,计算输出并更新权重
for (input_vec, label) in samples:
output = self.predict(input_vec)
self._update_weights(input_vec, output, label, rate)
#更新权重
def _update_weights(self, input_vec, output, label, rate):
delta = label - output
# 把input_vec[x1,x2,x3,...]和weights[w1,w2,w3,...]打包在一起,然后利用感知器规则更新权重
self.weights = map(lambda x, w: w + rate * delta * x, zip(input_vec, self.weights))
self.bias += rate * delta
例子:
用感知器实现and函数
我们设计一个感知器,让它来实现and运算。程序员都知道,and是一个二元函数(带有两个参数和),下面是它的真值表:
| x1 | x2 | y |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 0 |
| 1 | 0 | 0 |
| 1 | 1 | 1 |
实现代码:
#定义激活函数
def f(x):
return 1 if x > 0 else 0
#构建训练数据
def get_training_dataset():
# 输入的向量列表
input_vecs = [[1,1], [0,0], [1,0], [0,1]]
# 期望的输出列表
labels = [1, 0, 0, 0]
return input_vecs, labels
#训练感知器
def train_and_perceptron():
# 创建感知器,输入参数个数为2(因为and是二元函数),激活函数为f
p = Perceptron(2, f)
input_vecs, labels = get_training_dataset()
# 训练,迭代10轮, 学习速率为0.1
p.train(input_vecs, labels, 10, 0.1)
#返回训练好的感知器
return p
if __name__ == '__main__':
# 训练and感知器
and_perception = train_and_perceptron()
# 打印训练获得的权重
print(and_perception)
# 测试
print('1 and 1 = %d' % and_perception.predict([1, 1]))
print('0 and 0 = %d' % and_perception.predict([0, 0]))
print('1 and 0 = %d' % and_perception.predict([1, 0]))
print('0 and 1 = %d' % and_perception.predict([0, 1]))
二、线性单元
感知器有一个问题,当面对的数据集不是线性可分的时候,『感知器规则』可能无法收敛,这意味着我们永远也无法完成一个感知器的训练。为了解决这个问题,我们使用一个可导的线性函数来替代感知器的阶跃函数,这种感知器就叫做线性单元。
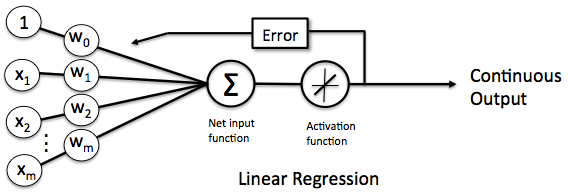
线性单元的模型
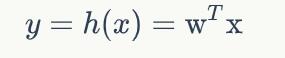
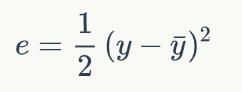

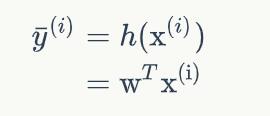

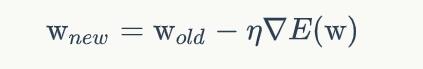
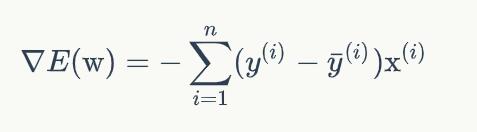
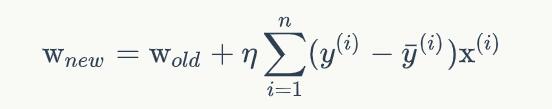

实现代码:
#引用感知机类的定义(见第一节)
from perceptron import Perceptron
#定义激活函数f
f = lambda x: x
class LinearUnit(Perceptron):
#初始化线性单元
def __init__(self, input_num):
Perceptron.__init__(self, input_num, f)
样例分析
def get_training_dataset():
'''
捏造5个人的收入数据
'''
# 构建训练数据
# 输入向量列表,每一项是工作年限
input_vecs = [[5], [3], [8], [1.4], [10.1]]
# 期望的输出列表,月薪,注意要与输入一一对应
labels = [5500, 2300, 7600, 1800, 11400]
return input_vecs, labels
def train_linear_unit():
'''
使用数据训练线性单元
'''
# 创建感知器,输入参数的特征数为1(工作年限)
lu = LinearUnit(1)
# 训练,迭代10轮, 学习速率为0.01
input_vecs, labels = get_training_dataset()
lu.train(input_vecs, labels, 10, 0.01)
#返回训练好的线性单元
return lu
if __name__ == '__main__':
'''训练线性单元'''
linear_unit = train_linear_unit()
# 打印训练获得的权重
print(linear_unit)
# 测试
print('Work 3.4 years, monthly salary = %.2f' % linear_unit.predict([3.4]))
print('Work 15 years, monthly salary = %.2f' % linear_unit.predict([15]))
print('Work 1.5 years, monthly salary = %.2f' % linear_unit.predict([1.5]))
print('Work 6.3 years, monthly salary = %.2f' % linear_unit.predict([6.3]))
运行结果:

三、神经网络和反向传播算法
神经元
神经元和感知器本质上是一样的,只不过我们说感知器的时候,它的激活函数是阶跃函数;而当我们说神经元时,激活函数往往选择为sigmoid函数或tanh函数。
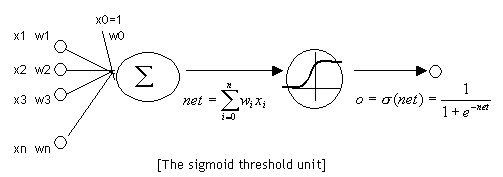
sigmoid函数:

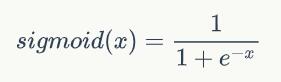
sigmoid函数的导数:
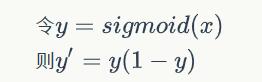
神经网络

要求:输入向量的维度和输入层神经元个数相同
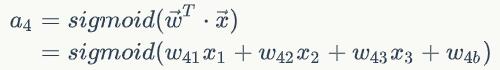
其中w4b为偏置项(bias)

得到:输出向量的维度和输出层神经元个数相同

则每一层的输出向量的计算可以表示为:
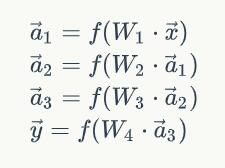
神经网络的训练:反向传播算法(Back Propagation)

求每个节点的误差项:
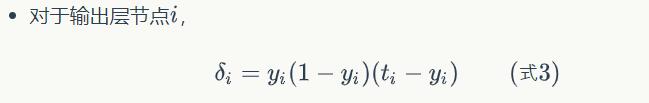
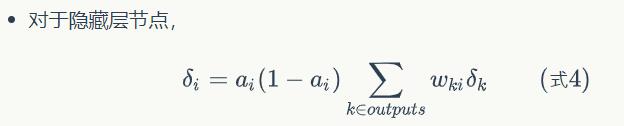
更新每个连接上的权值:
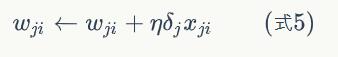
神经网络的实现
采用面向对象的设计方法:

- Network 神经网络对象,提供API接口。它由若干层对象组成以及连接对象组成。
- Layer 层对象,由多个节点组成。
- Node 节点对象计算和记录节点自身的信息(比如输出值、误差项等),以及与这个节点相关的上下游的连接。
- Connection 每个连接对象都要记录该连接的权重。
- Connections 仅仅作为Connection的集合对象,提供一些集合操作。
Node实现:
# 节点类,负责记录和维护节点自身信息以及与这个节点相关的上下游连接,实现输出值和误差项的计算。
class Node(object):
def __init__(self, layer_index, node_index):
'''
构造节点对象。
layer_index: 节点所属的层的编号
node_index: 节点的编号
'''
self.layer_index = layer_index
self.node_index = node_index
self.downstream = []
self.upstream = []
self.output = 0
self.delta = 0
def set_output(self, output):
'''
设置节点的输出值。如果节点属于输入层会用到这个函数。
'''
self.output = output
def append_downstream_connection(self, conn):
'''
添加一个到下游节点的连接
'''
self.downstream.append(conn)
def append_upstream_connection(self, conn):
'''
添加一个到上游节点的连接
'''
self.upstream.append(conn)
def calc_output(self):
'''
根据式1计算节点的输出
'''
output = reduce(lambda ret, conn: ret + conn.upstream_node.output * conn.weight, self.upstream, 0)
self.output = sigmoid(output)
def calc_hidden_layer_delta(self):
'''
节点属于隐藏层时,根据式4计算delta
'''
downstream_delta = reduce(
lambda ret, conn: ret + conn.downstream_node.delta * conn.weight,
self.downstream, 0.0)
self.delta = self.output * (1 - self.output) * downstream_delta
def calc_output_layer_delta(self, label):
'''
节点属于输出层时,根据式3计算delta
'''
self.delta = self.output * (1 - self.output) * (label - self.output)
def __str__(self):
'''
打印节点的信息
'''
node_str = '%u-%u: output: %f delta: %f' % (self.layer_index, self.node_index, self.output, self.delta)
downstream_str = reduce(lambda ret, conn: ret + '\n\t' + str(conn), self.downstream, '')
upstream_str = reduce(lambda ret, conn: ret + '\n\t' + str(conn), self.upstream, '')
return node_str + '\n\tdownstream:' + downstream_str + '\n\tupstream:' + upstream_str
ConstNode对象,为了实现一个输出恒为1的节点(计算偏置项时需要)
class ConstNode(object):
def __init__(self, layer_index, node_index):
'''
构造节点对象。
layer_index: 节点所属的层的编号
node_index: 节点的编号
'''
self.layer_index = layer_index
self.node_index = node_index
self.downstream = []
self.output = 1
def append_downstream_connection(self, conn):
'''
添加一个到下游节点的连接
'''
self.downstream.append(conn)
def calc_hidden_layer_delta(self):
'''
节点属于隐藏层时,根据式4计算delta
'''
downstream_delta = reduce(
lambda ret, conn: ret + conn.downstream_node.delta * conn.weight,
self.downstream, 0.0)
self.delta = self.output * (1 - self.output) * downstream_delta
def __str__(self):
'''
打印节点的信息
'''
node_str = '%u-%u: output: 1' % (self.layer_index, self.node_index)
downstream_str = reduce(lambda ret, conn: ret + '\n\t' + str(conn), self.downstream, '')
return node_str + '\n\tdownstream:' + downstream_str
Layer对象,负责初始化一层
class Layer(object):
def __init__(self, layer_index, node_count):
'''
初始化一层
layer_index: 层编号
node_count: 层所包含的节点个数
'''
self.layer_index = layer_index
self.nodes = []
for i in range(node_count):
self.nodes.append(Node(layer_index, i))
self.nodes.append(ConstNode(layer_index, node_count))
def set_output(self, data):
'''
设置层的输出。当层是输入层时会用到。
'''
for i in range(len(data)):
self.nodes[i].set_output(data[i])
def calc_output(self):
'''
计算层的输出向量
'''
for node in self.nodes[:-1]:
node.calc_output()
def dump(self):
'''
打印层的信息
'''
for node in self.nodes:
print node
Connection对象,主要职责是记录连接的权重,以及这个连接所关联的上下游节点:
class Connection(object):
def __init__(self, upstream_node, downstream_node):
'''
初始化连接,权重初始化为是一个很小的随机数
upstream_node: 连接的上游节点
downstream_node: 连接的下游节点
'''
self.upstream_node = upstream_node
self.downstream_node = downstream_node
self.weight = random.uniform(-0.1, 0.1)
self.gradient = 0.0
def calc_gradient(self):
'''
计算梯度
'''
self.gradient = self.downstream_node.delta * self.upstream_node.output
def get_gradient(self):
'''
获取当前的梯度
'''
return self.gradient
def update_weight(self, rate):
'''
根据梯度下降算法更新权重
'''
self.calc_gradient()
self.weight += rate * self.gradient
def __str__(self):
'''
打印连接信息
'''
return '(%u-%u) -> (%u-%u) = %f' % (
self.upstream_node.layer_index,
self.upstream_node.node_index,
self.downstream_node.layer_index,
self.downstream_node.node_index,
self.weight)
Connections对象,提供Connection集合操作:
class Connections(object):
def __init__(self):
self.connections = []
def add_connection(self, connection):
self.connections.append(connection)
def dump(self):
for conn in self.connections:
print conn
Network对象,提供API:
class Network(object):
def __init__(self, layers):
'''
初始化一个全连接神经网络
layers: 二维数组,描述神经网络每层节点数
'''
self.connections = Connections()
self.layers = []
layer_count = len(layers)
node_count = 0;
for i in range(layer_count):
self.layers.append(Layer(i, layers[i]))
for layer in range(layer_count - 1):
connections = [Connection(upstream_node, downstream_node)
for upstream_node in self.layers[layer].nodes
for downstream_node in self.layers[layer + 1].nodes[:-1]]
for conn in connections:
self.connections.add_connection(conn)
conn.downstream_node.append_upstream_connection(conn)
conn.upstream_node.append_downstream_connection(conn)
def train(self, labels, data_set, rate, iteration):
'''
训练神经网络
labels: 数组,训练样本标签。每个元素是一个样本的标签。
data_set: 二维数组,训练样本特征。每个元素是一个样本的特征。
'''
for i in range(iteration):
for d in range(len(data_set)):
self.train_one_sample(labels[d], data_set[d], rate)
def train_one_sample(self, label, sample, rate):
'''
内部函数,用一个样本训练网络
'''
self.predict(sample)
self.calc_delta(label)
self.update_weight(rate)
def calc_delta(self, label):
'''
内部函数,计算每个节点的delta
'''
output_nodes = self.layers[-1].nodes
for i in range(len(label)):
output_nodes[i].calc_output_layer_delta(label[i])
for layer in self.layers[-2::-1]:
for node in layer.nodes:
node.calc_hidden_layer_delta()
def update_weight(self, rate):
'''
内部函数,更新每个连接权重
'''
for layer in self.layers[:-1]:
for node in layer.nodes:
for conn in node.downstream:
conn.update_weight(rate)
def calc_gradient(self):
'''
内部函数,计算每个连接的梯度
'''
for layer in self.layers[:-1]:
for node in layer.nodes:
for conn in node.downstream:
conn.calc_gradient()
def get_gradient(self, label, sample):
'''
获得网络在一个样本下,每个连接上的梯度
label: 样本标签
sample: 样本输入
'''
self.predict(sample)
self.calc_delta(label)
self.calc_gradient()
def predict(self, sample):
'''
根据输入的样本预测输出值
sample: 数组,样本的特征,也就是网络的输入向量
'''
self.layers[0].set_output(sample)
for i in range(1, len(self.layers)):
self.layers[i].calc_output()
return map(lambda node: node.output, self.layers[-1].nodes[:-1])
def dump(self):
'''
打印网络信息
'''
for layer in self.layers:
layer.dump()
四、卷积神经网络
一个新的激活函数——Relu
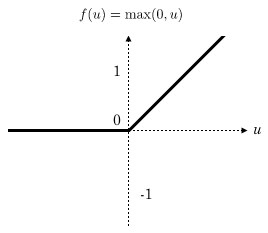
Relu函数作为激活函数,有下面几大优势:
- 速度快 和sigmoid函数需要计算指数和倒数相比,relu函数其实就是一个max(0,x),计算代价小很多。
- 减轻梯度消失问题 在使用反向传播算法进行梯度计算时,每经过一层sigmoid神经元,梯度就要乘上一个。从下图可以看出,函数最大值是1/4。因此,乘一个会导致梯度越来越小,这对于深层网络的训练是个很大的问题。而relu函数的导数是1,不会导致梯度变小。

- 稀疏性 通过对大脑的研究发现,大脑在工作的时候只有大约5%的神经元是激活的,而采用sigmoid激活函数的人工神经网络,其激活率大约是50%。有论文声称人工神经网络在15%-30%的激活率时是比较理想的。因为relu函数在输入小于0时是完全不激活的,因此可以获得一个更低的激活率。
全连接网络 VS 卷积网络
全连接网络的主要问题有:
- 参数数量太多 考虑一个输入10001000像素的图片,输入层有10001000=100万节点。假设第一个隐藏层有100个节点,那么仅这一层就有(1000*1000+1)*100=1亿参数,这实在是太多了
- 没有利用像素之间的位置信息 对于图像识别任务来说,每个像素和其周围像素的联系是比较紧密的,和离得很远的像素的联系可能就很小了。如果一个神经元和上一层所有神经元相连,那么就相当于对于一个像素来说,把图像的所有像素都等同看待,这不符合前面的假设。当我们完成每个连接权重的学习之后,最终可能会发现,有大量的权重,它们的值都是很小的(也就是这些连接其实无关紧要)。努力学习大量并不重要的权重,这样的学习必将是非常低效的。
- 网络层数限制 我们知道网络层数越多其表达能力越强,但是通过梯度下降方法训练深度全连接神经网络很困难,因为全连接神经网络的梯度很难传递超过3层。因此,我们不可能得到一个很深的全连接神经网络,也就限制了它的能力。
卷积神经网络的思路: - 局部连接 这个是最容易想到的,每个神经元不再和上一层的所有神经元相连,而只和一小部分神经元相连。这样就减少了很多参数。
- 权值共享 一组连接可以共享同一个权重,而不是每个连接有一个不同的权重,这样又减少了很多参数。
- 下采样 可以使用Pooling来减少每层的样本数,进一步减少参数数量,同时还可以提升模型的鲁棒性。
卷积神经网络

从图1我们可以发现卷积神经网络的层结构和全连接神经网络的层结构有很大不同。全连接神经网络每层的神经元是按照一维排列的,也就是排成一条线的样子;而卷积神经网络每层的神经元是按照三维排列的,也就是排成一个长方体的样子,有宽度、高度和深度。
卷积神经网络输出值的计算

用xi,j表示图像的第i行第j列元素;对filter的每个权重进行编号,用wm,n表示第m行第n列权重,用wb表示filter的偏置项;对Feature Map的每个元素进行编号,用ai,j表示Feature Map的第i行第j列元素;用f表示激活函数(这个例子选择relu函数作为激活函数)。然后,使用下列公式计算卷积:
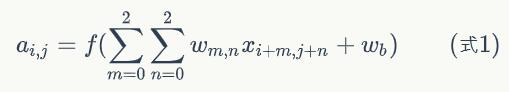

当步幅设置为2的时候,Feature Map就变成2*2了。这说明图像大小、步幅和卷积后的Feature Map大小是有关系的。事实上,它们满足下面的关系: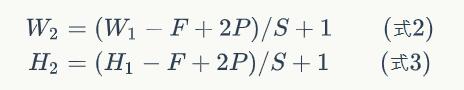
注:P是Zero Padding数量,Zero Padding是指在原始图像周围补几圈0
如果深度大于1:
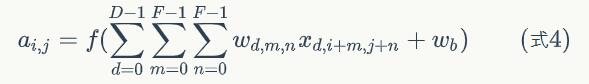

用卷积公式来表达卷积层计算
二维卷积公式:
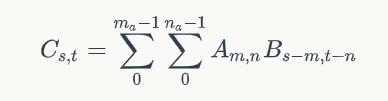
亦可以写作:
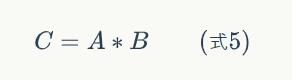

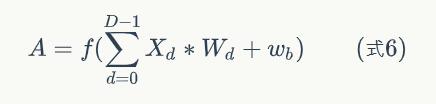
Pooling层输出值的计算
Pooling层主要的作用是下采样,通过去掉Feature Map中不重要的样本,进一步减少参数数量。Pooling的方法很多,最常用的是Max Pooling。Max Pooling实际上就是在nn的样本中取最大值,作为采样后的样本值。下图是22 max pooling:

卷积神经网络的训练
五、循环神经网络
基本循环神经网络

计算方法:
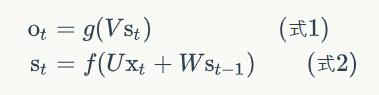
式1是输出层的计算公式,输出层是一个全连接层,也就是它的每个节点都和隐藏层的每个节点相连。V是输出层的权重矩阵,g是激活函数。式2是隐藏层的计算公式,它是循环层。U是输入x的权重矩阵,W是上一次的值st-1作为这一次的输入的权重矩阵,f是激活函数。
循环层和全连接层的区别就是循环层多了一个权重矩阵 W。
双向循环矩阵

双向卷积神经网络的隐藏层要保存两个值,一个A参与正向计算,另一个值A’参与反向计算。最终的输出值y2取决于A2和A2’。其计算方法为:
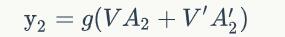















 1754
1754











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









