









#include <cstdio>
#include <cuda_runtime.h>
__device__ __inline__ void say_hello() {
printf("Hello, world!\n");
}
__global__ void kernel() {
say_hello();
}
int main() {
kernel<<<1, 1>>>();
cudaDeviceSynchronize();
return 0;
}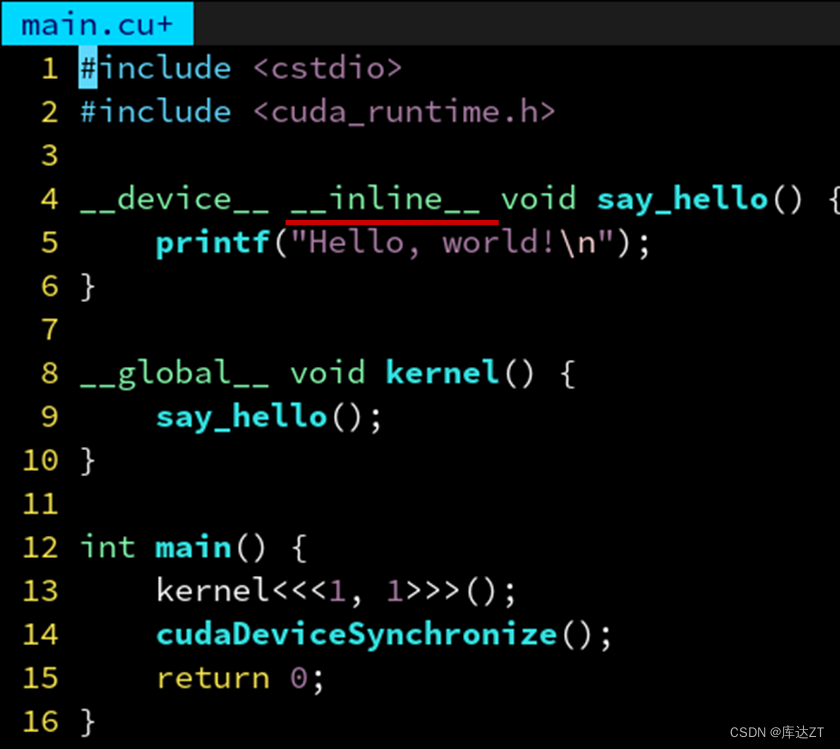
C++中的inline只是一个weak符号,只是一种建议,而CUDA编译器中设立了__inline__这个符号来声明函数为内联。
注意声明为 __inline__ 不一定就保证内联了,如果函数太大编译器可能会放弃内联化。因此 CUDA 还提供 __forceinline__ 这个关键字来强制一个函数为内联。GCC 也有相应的 __attribute__((“always_inline”))。
此外,还有 __noinline__ 来禁止内联优化。
__device__ 将函数定义在 GPU 上,而 __host__ 则相反,将函数定义在 CPU 上。
通过 __host__ __device__ 这样的双重修饰符,可以把函数同时定义在 CPU 和 GPU 上,这样 CPU 和 GPU 都可以调用。
使用constexpr 函数自动变成 CPU 和 GPU 都可以调用
这样相当于把 constexpr 函数自动变成修饰 __host__ __device__,从而两边都可以调用。
因为 constexpr 通常都是一些可以内联的函数,数学计算表达式之类的,一个个加上太累了,所以产生了这个需求。
__host__ __device__也可以根据设备的不同进行区分:
__host__ __device__ void cuthead() {
#ifdef __CUDA_ARCH__
printf("Hello, world from GPU!\n");
#else
printf("Hello, world from CPU!\n");
#endif // __CUDA_ARCH__
}
__global__ void kernel() {
cuthead();
}
int main() {
kernel << <1, 1 >> > ();
cudaDeviceSynchronize();
cuthead();
return 0;
}像上面这个代码,就是根据运行设备的不同进行区分。
CUDA 编译器具有多段编译的特点。
一段代码他会先送到 CPU 上的编译器(通常是系统自带的编译器比如 gcc 和 msvc)生成 CPU 部分的指令码。然后送到真正的 GPU 编译器生成 GPU 指令码。最后再链接成同一个文件,看起来好像只编译了一次一样,实际上你的代码会被预处理很多次。
他在 GPU 编译模式下会定义 __CUDA_ARCH__ 这个宏,利用 #ifdef 判断该宏是否定义,就可以判断当前是否处于 GPU 模式,从而实现一个函数针对 GPU 和 CPU 生成两份源码级不同的代码。
CUDA也可以支持核函数launch:
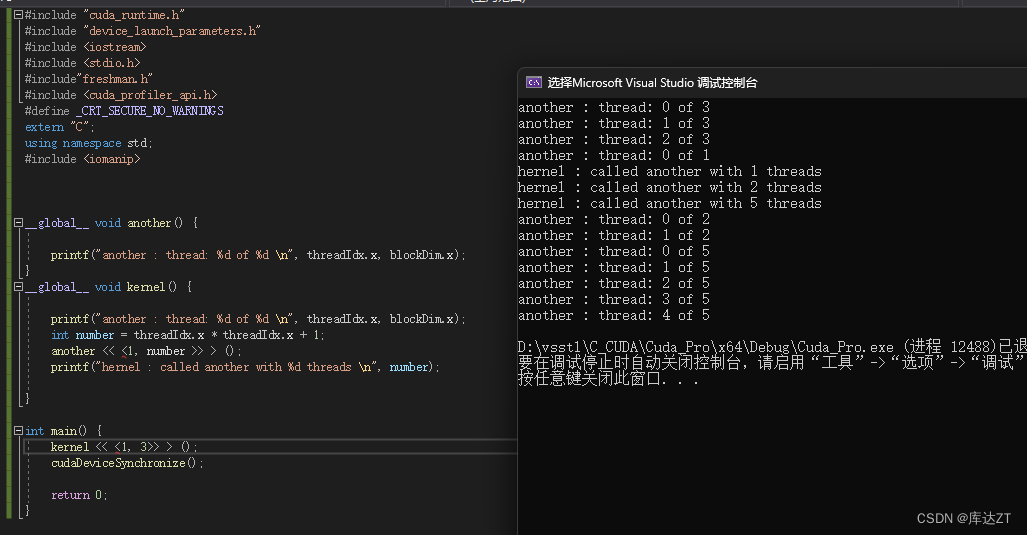
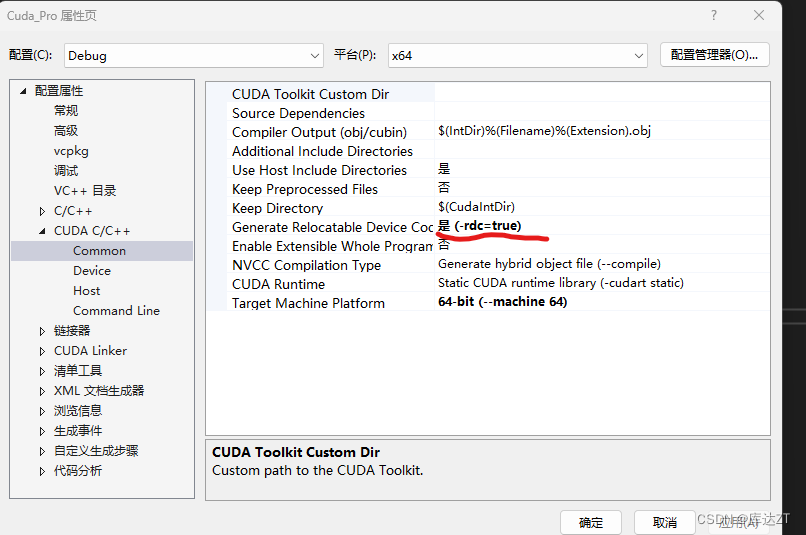
(需要将编译器的rdc改为true)
为什么__global__核函数不能有返回值:
__global__ int kernel() {
return 42;
}
int main() {
int ret = kernel << <1, 1 >> > ();
cudaDeviceSynchronize();
printf("%d\n", ret);
return 0;
}这是因为 kernel 的调用是异步的,返回的时候,并不会实际让 GPU 把核函数执行完毕,必须 cudaDeviceSynchronize() 等待他执行完毕(和线程的 join 很像)。所以,不可能从 kernel 里通过返回值获取 GPU 数据,因为 kernel 返回时核函数并没有真正在 GPU 上执行。所以核函数返回类型必须是 void。
__global__ void kernel(int *pret) {
*pret = 42;
}
int main() {
int* pret;
cudaMalloc((int **)&pret, sizeof(int));
kernel << <1, 1 >> > (pret);
cudaDeviceSynchronize();//cudaMemcpy自带一次同步,所以这次同步可以省略
int ret;
cudaMemcpy(&ret, pret, sizeof(int), cudaMemcpyDeviceToHost);
printf("%d\n", ret);
cudaFree(pret);
return 0;
}最近新出现了一种统一内存地址技术:Unified Memory
只需把 cudaMalloc 换成 cudaMallocManaged 即可,释放时也是通过 cudaFree。这样分配出来的地址,不论在 CPU 还是 GPU 上都是一模一样的,都可以访问。而且拷贝也会自动按需进行(当从 CPU 访问时),无需手动调用 cudaMemcpy,大大方便了编程人员,特别是含有指针的一些数据结构。
网格跨步循环
__global__ void kernel(int* arr, int n) {
for (int i = threadIdx.x; i < n; i += blockDim.x) {
arr[i] = i;
}
}
int main() {
int n = 7;
int* arr;
CHECK(cudaMallocManaged(&arr, n * sizeof(int)));
kernel << <1, 4 >> > (arr, n);
CHECK(cudaDeviceSynchronize());
for (int i = 0; i < n; i++) {
printf("arr[%d]: %d\n", i, arr[i]);
}
cudaFree(arr);
return 0;
}C++ 封装
template <class T>
struct CudaAllocator {
using value_type = T;
T *allocate(size_t size) {
T *ptr = nullptr;
checkCudaErrors(cudaMallocManaged(&ptr, size * sizeof(T)));
return ptr;
}
void deallocate(T *ptr, size_t size = 0) {
checkCudaErrors(cudaFree(ptr));
}
template <class ...Args>
void construct(T *p, Args &&...args) {
if constexpr (!(sizeof...(Args) == 0 && std::is_pod_v<T>))
::new((void *)p) T(std::forward<Args>(args)...);
}
};
__global__ void kernel(int *arr, int n) {
for (int i = blockDim.x * blockIdx.x + threadIdx.x;
i < n; i += blockDim.x * gridDim.x) {
arr[i] = i;
}
}
int main() {
int n = 65536;
std::vector<int, CudaAllocator<int>> arr(n);
kernel<<<32, 128>>>(arr.data(), n);
checkCudaErrors(cudaDeviceSynchronize());
for (int i = 0; i < n; i++) {
printf("arr[%d]: %d\n", i, arr[i]);
}
return 0;
}CUDA 的优势在于对 C++ 的完全支持。所以 __global__ 修饰的核函数自然也是可以为模板函数的。
调用模板时一样可以用自动参数类型推导,如有手动指定的模板参数(单尖括号)请放在三重尖括号的前面。
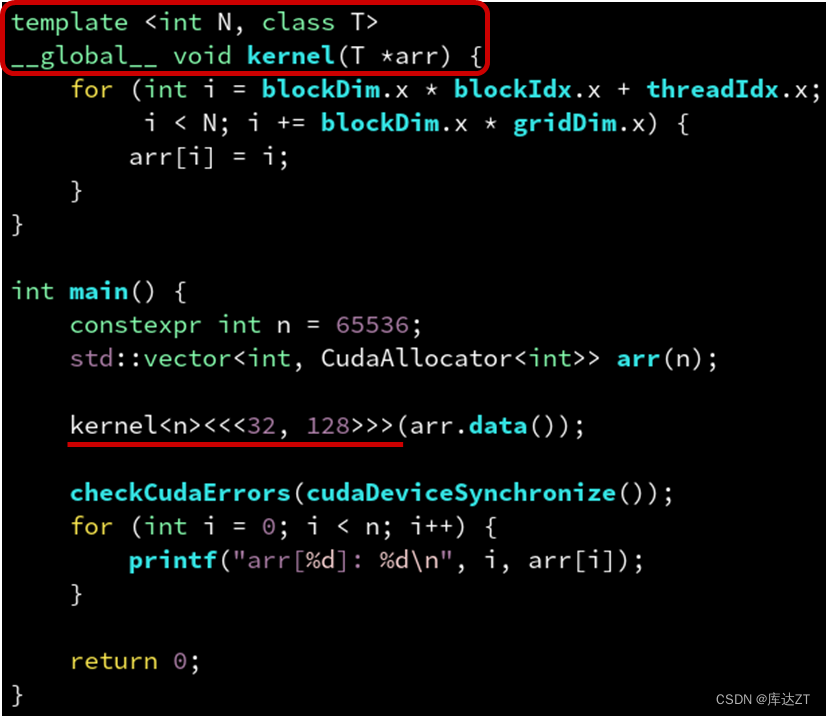
template <class Func>
__global__ void parallel_for(int n, Func func) {
for (int i = blockDim.x * blockIdx.x + threadIdx.x;
i < n; i += blockDim.x * gridDim.x) {
func(i);
}
}
struct MyFunctor {
__device__ void operator()(int i) const {
printf("number %d\n", i);
}
};
int main() {
int n = 65536;
parallel_for << <32, 128 >> > (n, MyFunctor{});
CHECK(cudaDeviceSynchronize());
return 0;
}核函数也可以实现函数式编程
template <class Func>
__global__ void parallel_for(int n, Func func) {
for (int i = blockDim.x * blockIdx.x + threadIdx.x;
i < n; i += blockDim.x * gridDim.x) {
func(i);
}
}
int main() {
int n = 65536;
parallel_for << <32, 128 >> > (n, [] __device__(int i) {
printf("number %d \n", i);
});
CHECK(cudaDeviceSynchronize());
return 0;
}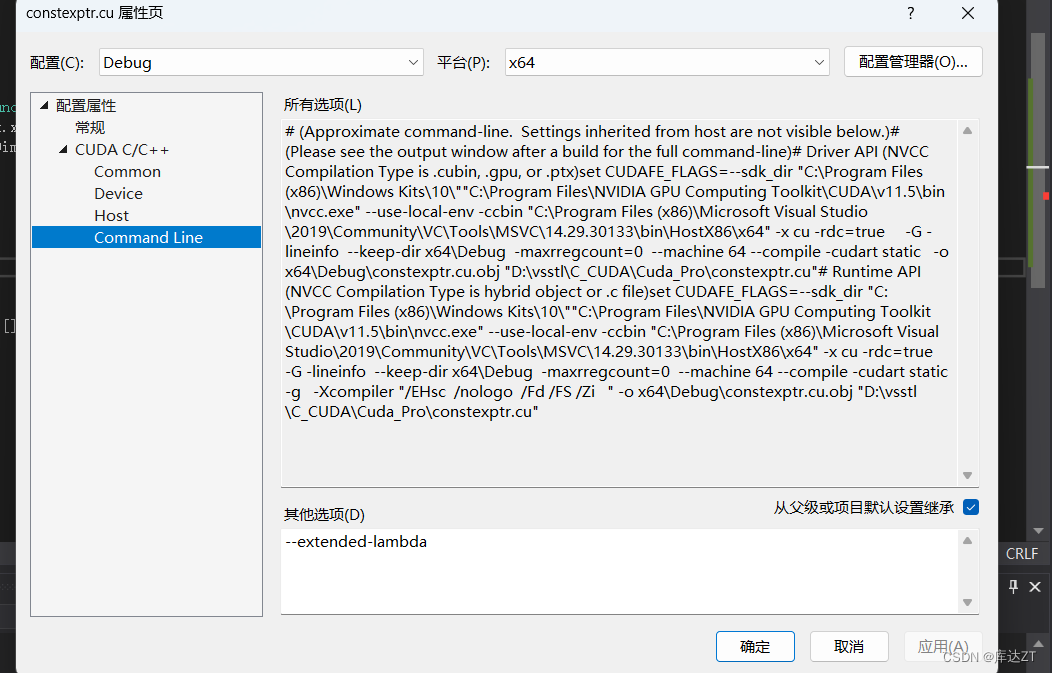
那么晚既然用了函数式编程,那么就可以自然地想到最方便的调用外部变量了。
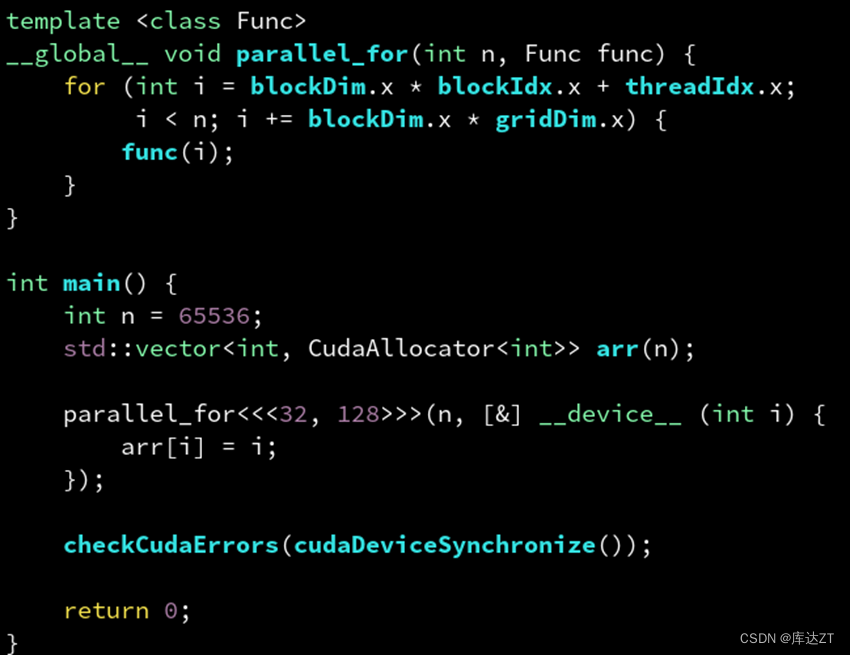
上面这个就是我们最常用的方法了,引用过来,然后赋值,但是这里有一个问题,就是虽然arr是被CudaAllocator分配到GPU上的,但是指向arr的指针还是在CPU栈上,所以GPU无法调用CPU栈上的指针,所以会出错。
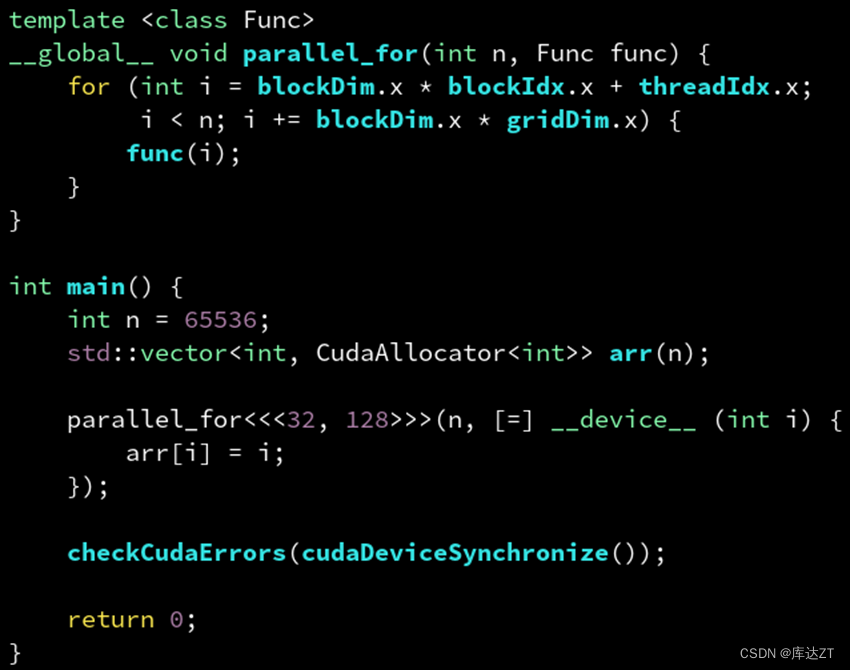
那可能就会想,是不是可以用 [=] 按值捕获,这样捕获到的就是指针了吧?
错了,不要忘了我们说过,vector 的拷贝是深拷贝(绝大多数C++类都是深拷贝,除了智能指针和原始指针)。这样只会把 vector 整个地拷贝到 GPU 上!而不是浅拷贝其起始地址指针。
所以为了从性能上进行优化,最好还是进行浅拷贝,即只将原始指针进行传入。
template <class Func>
__global__ void parallel_for(int n, Func func) {
for (int i = blockDim.x * blockIdx.x + threadIdx.x;
i < n; i += blockDim.x * gridDim.x) {
func(i);
}
}
int main() {
int n = 65536;
std::vector<int, CudaAllocator<int>> arr(n);
int *arr_data = arr.data();
parallel_for<<<32, 128>>>(n, [=] __device__ (int i) {
arr_data[i] = i;
});
checkCudaErrors(cudaDeviceSynchronize());
for (int i = 0; i < n; i++) {
printf("arr[%d] = %d\n", i, arr[i]);
}
return 0;
}这个的本质原因是arr_data虽然也是在CPU端的指针,但是用了值传递之后就仅仅是将对应的主机内存中的地址复制了过去,所以可以进行更改。
经典案例求sin:
template <class T>
struct CudaAllocator {
using value_type = T;
CudaAllocator() noexcept = default;
template <class U>
CudaAllocator(const CudaAllocator<U>&) noexcept {}
T* allocate(std::size_t n) {
T* ptr = nullptr;
cudaMallocManaged(&ptr, n * sizeof(T));
return ptr;
}
void deallocate(T* ptr, std::size_t) noexcept {
cudaFree(ptr);
}
};
//这个头文件可以直接将vector分配到GPU端
template <class Func>
__global__ void parallel_for(int n, Func func) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
int stride = gridDim.x * blockDim.x;
for (int i = idx; i < n; i += stride) {
func(i);
}
}
int main() {
int n = 65536;
std::vector<float, CudaAllocator<float>> arr(n);
parallel_for << <32, 128 >> > (n, [arr = arr.data()] __device__(int i) {
arr[i] = sinf(i);
});
cudaDeviceSynchronize();
for (int i = 0; i < n; i++) {
printf("diff = %f\n", arr[i] - sinf(i));
}
return 0;
}我又用传统的方法设计了一个基础的并行求sinf
template <class Func>
__global__ void parallel_for(int n, Func func) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
int stride = gridDim.x * blockDim.x;
for (int i = idx; i < n; i += stride) {
func(i);
}
}
__global__ void sinfa(float* a,int n ) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
int stride = gridDim.x * blockDim.x;
for (int i = idx; i < n; i += stride) {
a[i] = sinf(i);
}
}
int main() {
int n = 65536;
std::vector<float, CudaAllocator<float>> arr(n);
std::vector<float> cpu(n);
int nByte = sizeof(float) * n;
float* a_h = (float*)malloc(nByte);
float* res_d = (float*)malloc(nByte);
float* a_d;
CHECK(cudaMallocHost((float**)&a_d, nByte));
CHECK(cudaMemcpy(a_d, a_h, nByte, cudaMemcpyHostToDevice));
double t = cpuSecond();
parallel_for << <32, 128 >> > (n, [arr = arr.data()] __device__(int i) {
arr[i] = sinf(i);
});
cudaDeviceSynchronize();
double h = cpuSecond();
double monent = h - t;
std::cout << "cudalloc time= " << monent << std::endl;
t = cpuSecond();
for (int i = 0; i < n; i++)
{
cpu[i] = sinf(i);
}
h = cpuSecond();
monent = h - t;
std::cout << "cpu time = " << monent << std::endl;
t = cpuSecond();
sinfa << <32, 128 >> > (a_d, n);
cudaDeviceSynchronize();
h = cpuSecond();
monent = h - t;
std::cout << "cpu time = " << monent << std::endl;
CHECK(cudaMemcpy(res_d, a_d, nByte, cudaMemcpyDeviceToHost));
/*for (int i = 0; i < n; i++) {
printf("diff = %f\n", arr[i] - cpu[i]);
}*/
cudaFree(a_d);
cudaFree(a_h);
cudaFree(res_d);
return 0;
}
并且可以看到传统的sinfa速度还是更快一些,可能是由于 涉及到 arr 数据的读写。这种情况下,可能会引入更多的计算开销和数据传输开销,从而导致整体计算时间较长。
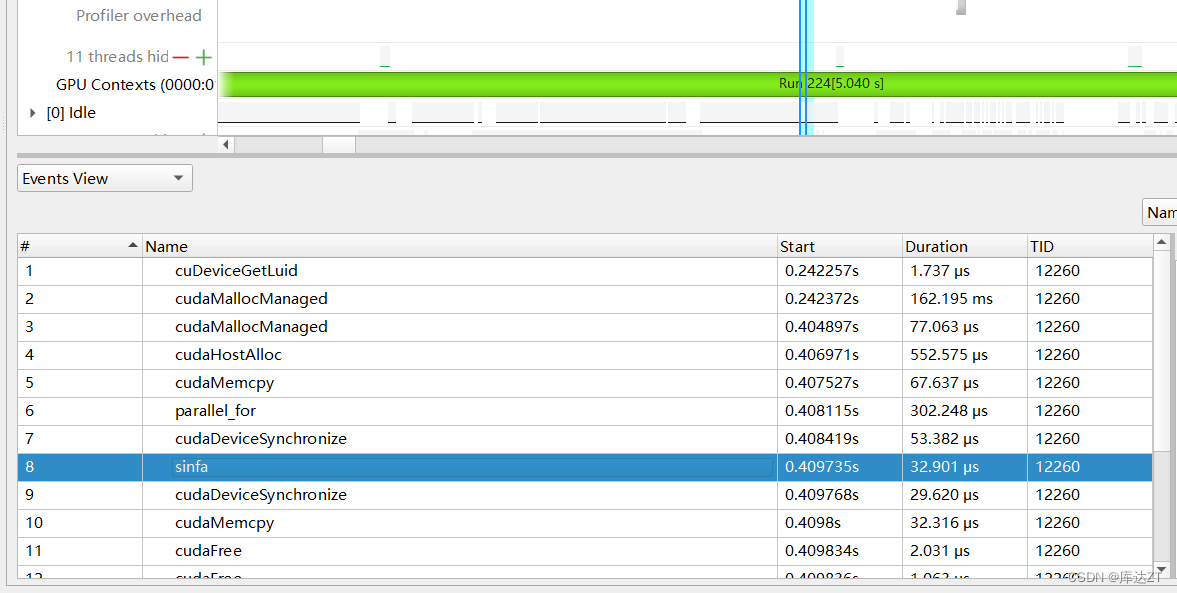
编译器选项:--use_fast_math
开启 --use_fast_math 后会自动开启上述所有
总之一切都是牺牲精度换速度
THRUST:
thrust库是cuda自己提供的库:
#include<cstdio>
#include <iostream>
#include <vector>
#include <cmath>
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <cuda_runtime.h>
#include "freshman.h"
#include<thrust/universal_vector.h>
template<class Func>
__global__ void parallel_for(int n, Func func) {
for (int i = blockDim.x*blockIdx.x+threadIdx.x; i < n ; i += blockDim.x*gridDim.x){
func(i);
}
}
int main() {
int n = 65536;
float a = 3.14f;
thrust::universal_vector<float> x(n);
thrust::universal_vector<float> y(n);
for (int i = 0; i < n; i++){
x[i] = std::rand() * (1.f / RAND_MAX);
y[i] = std::rand() * (1.f / RAND_MAX);
}
parallel_for << <n / 512, 128 >> > (n, [a, x = x.data(), y = y.data()] __device__(int i) {
x[i] = a * x[i] + y[i];
});
CHECK(cudaDeviceSynchronize());
return 0;
}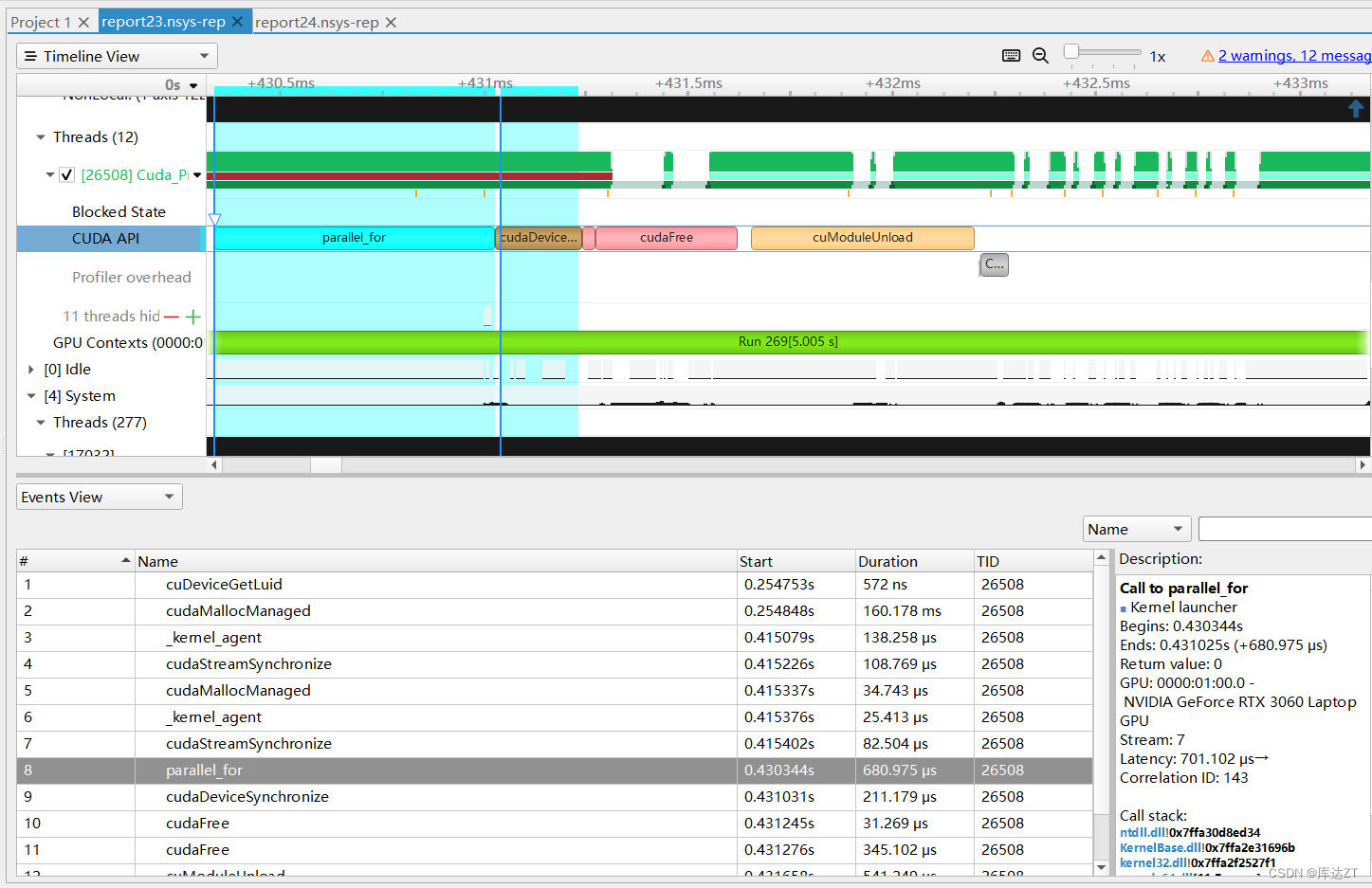
换成分离的host和device
#include<cstdio>
#include <iostream>
#include <vector>
#include <cmath>
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <cuda_runtime.h>
#include "freshman.h"
#include<thrust/device_vector.h>
#include<thrust/host_vector.h>
template<class Func>
__global__ void parallel_for(int n, Func func) {
for (int i = blockDim.x*blockIdx.x+threadIdx.x; i < n ; i += blockDim.x*gridDim.x){
func(i);
}
}
int main() {
int n = 65536;
float a = 3.14f;
thrust::host_vector<float> x_host(n);
thrust::host_vector<float> y_host(n);
for (int i = 0; i < n; i++){
x_host[i] = std::rand() * (1.f / RAND_MAX);
y_host[i] = std::rand() * (1.f / RAND_MAX);
}
thrust::device_vector<float> x_dev = x_host;
thrust::device_vector<float> y_dev = y_host;
parallel_for << <n / 512, 128 >> > (n, [a, x_dev = x_dev.data(), y_dev = y_dev.data()] __device__(int i) {
x_dev[i] = a * x_dev[i] + y_dev[i];
});
x_host = x_dev;
CHECK(cudaDeviceSynchronize());
return 0;
}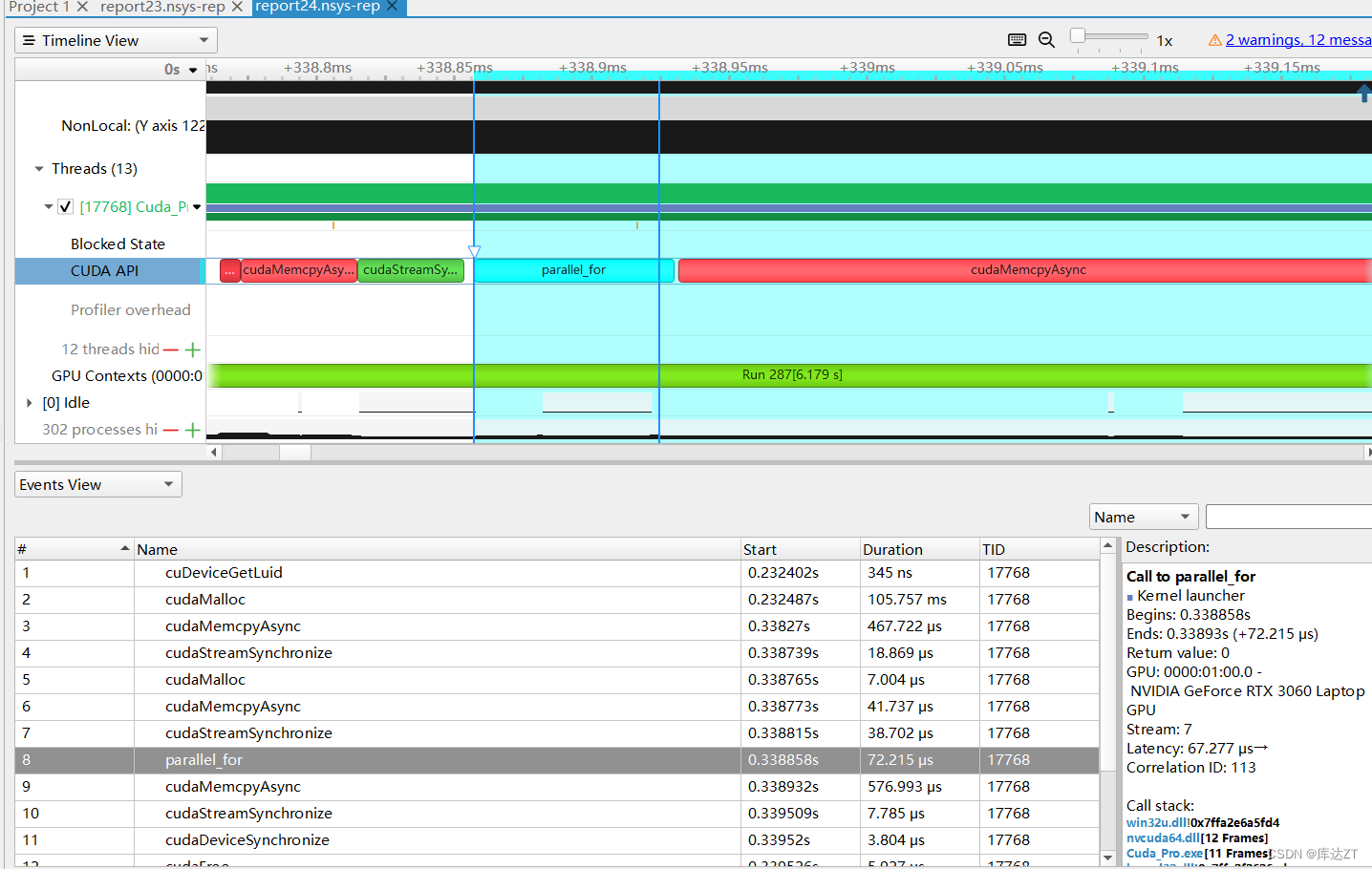
可以看到性能提升巨大
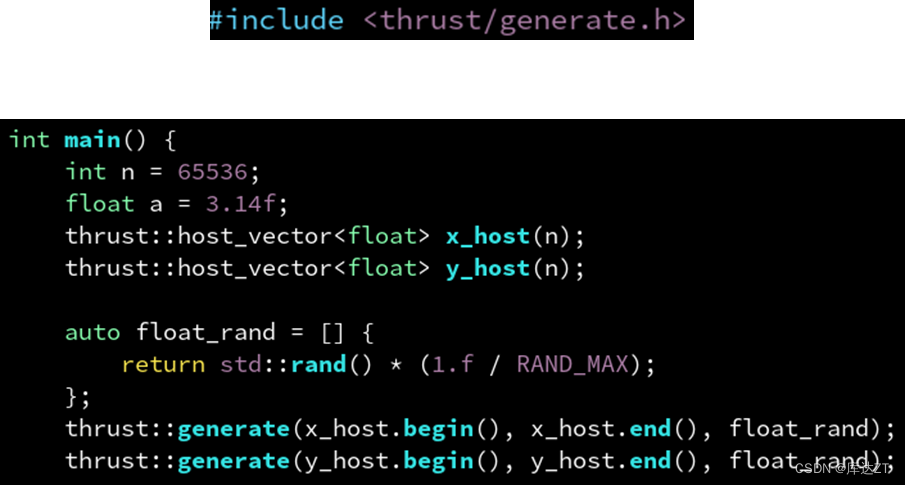
thrust 提供了很多类似于标准库里的模板函数,比如 thrust::generate(b, e, f) 对标 std::generate,用于批量调用 f() 生成一系列(通常是随机)数,写入到 [b, e) 区间。
其前两个参数是 device_vector 或 host_vector 的迭代器,可以通过成员函数 begin() 和 end() 得到。第三个参数可以是任意函数,这里用了 lambda 表达式。
同理,还有 thrust::for_each(b, e, f) 对标 std::for_each。他会把 [b, e) 区间的每个元素 x 调用一遍 f(x)。这里的 x 实际上是一个引用。如果 b 和 e 是常值迭代器则是个常引用,可以用 cbegin(),cend() 获取常值迭代器。
当然还有 thrust::reduce,thrust::sort,thrust::find_if,thrust::count_if,thrust::reverse,thrust::inclusive_scan 等。
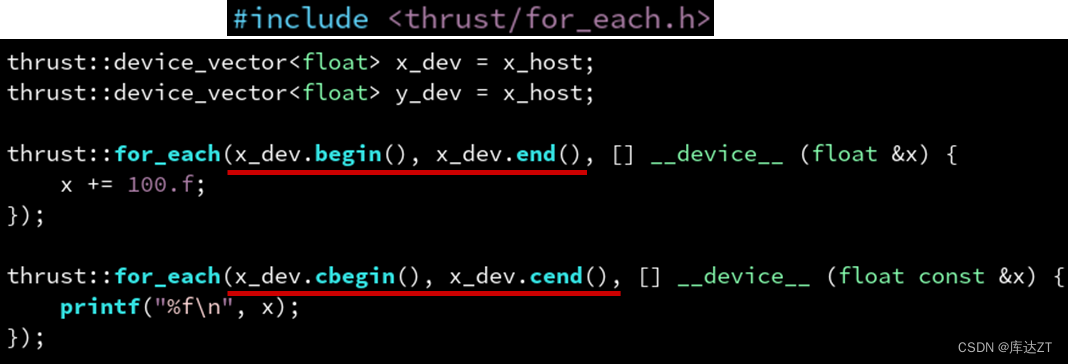
而且thrust可以自动根据device_vector还是host_vector来决定是在CPU还是GPU上执行。
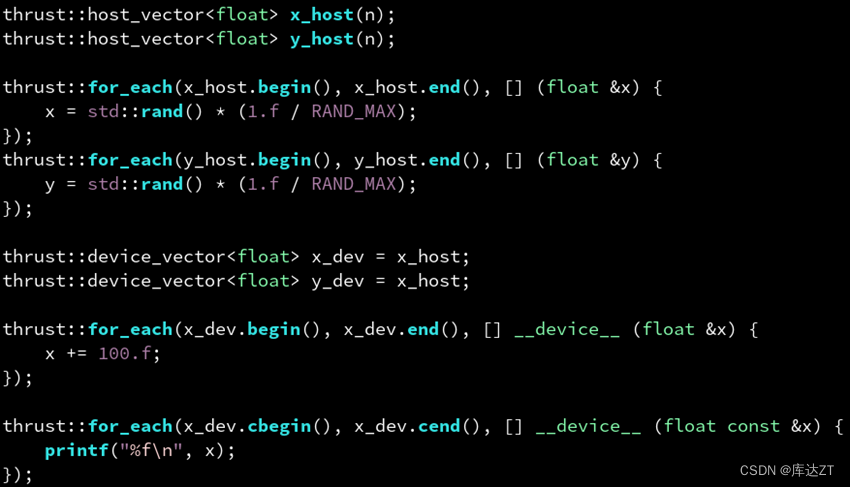
这就是为什么我们用于 x_host 那个 for_each 的 lambda 没有修饰,而用于 x_dev 的那个 lambda 需要修饰 __device__。
合并多个迭代器为一个:zip_iterator
然后在函数体里通过 auto const &tup 捕获,并通过 thrust::get<index>(tup) 获取这个合并迭代器的第 index 个元素
thrust::for_each(
thrust::make_zip_iterator(x_dev.begin(), y_dev.cbegin()),
thrust::make_zip_iterator(x_dev.end(), y_dev.cend()),
[a] __device__ (auto const &tup) {
auto &x = thrust::get<0>(tup);
auto const &y = thrust::get<1>(tup);
x = a * x + y;
});在这段代码中,auto const &tup 是用来接收迭代器指向的元组类型的参数,并且是一个常量引用。这种设计选择是为了确保在 lambda 表达式中不会对元组进行修改。
这种做法是出于一种良好的设计原则,即尽可能地使用常量引用,以避免不必要的拷贝和修改。在这种情况下,既不需要拷贝元组,也不需要修改它,所以选择使用 auto const &tup 来确保元组的值不被改变。
因此,auto const &tup 的设计选择是为了强调 lambda 表达式中对元组的只读访问,以增加代码的清晰性、可维护性和安全性。
thrust::sort 例子
#include <stdio.h>
#include <thrust/host_vector.h>
#include <thrust/device_vector.h>
#include <thrust/sort.h>
#include <iostream>
using namespace std;
__host__ __device__
int sort_func(int a, int b){
return a > b;
}
int main(){
int data[] = {5, 3, 1, 5, 2, 0};
int ndata = sizeof(data) / sizeof(data[0]);
thrust::host_vector<int> array1(data, data + ndata);
thrust::sort(array1.begin(), array1.end(), sort_func);
thrust::device_vector<int> array2 = thrust::host_vector<int>(data, data + ndata);
thrust::sort(array2.begin(), array2.end(), []__device__(int a, int b){return a < b;});
printf("array1------------------------\n");
for(int i = 0; i < array1.size(); ++i)
cout << array1[i] << endl;
printf("array2------------------------\n");
for(int i = 0; i < array2.size(); ++i)
cout << array2[i] << endl;
return 0;
}原子操作:
主要主题同:https://blog.csdn.net/zhuangtu1999/article/details/130835666?spm=1001.2014.3001.5501
主要对于atomicCAS进行进一步讲解:
atomicCAS:原子地判断是否相等,相等则写入,并读取旧值
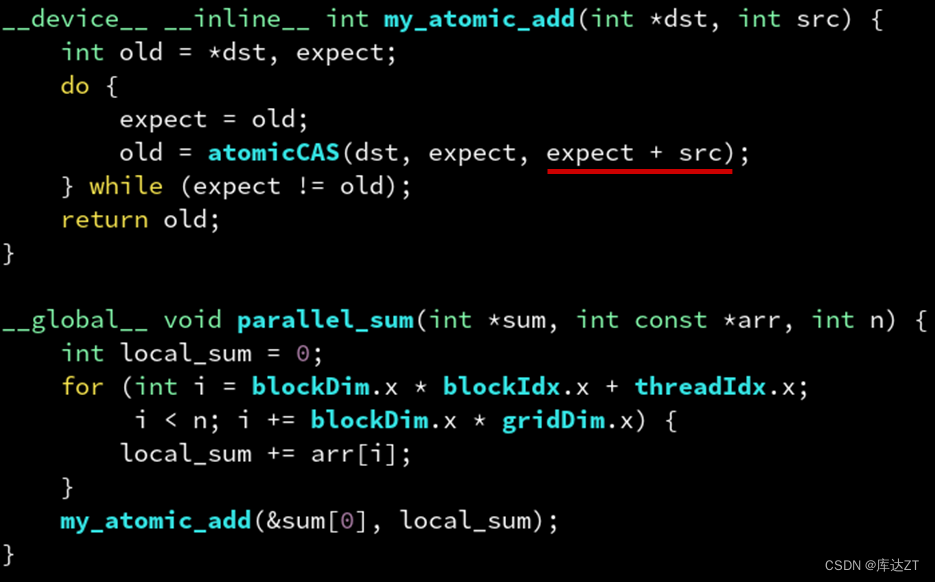
类似的,也可以尝试atomicMul这种。
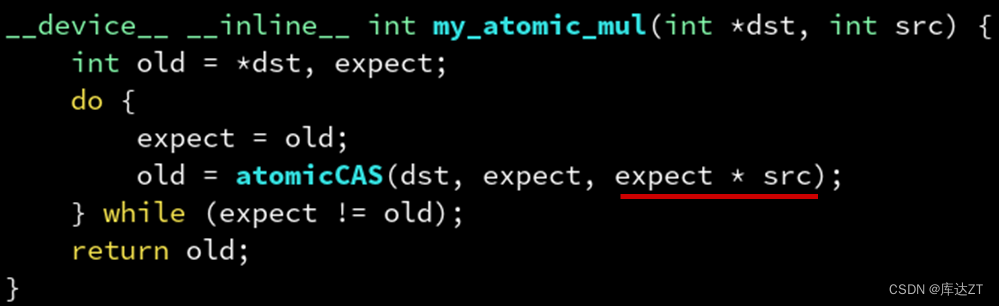
而原子操作也有很多的问题:最大的问题就是影响性能。因为原子操作要保证同一时刻只能有一个线程在修改地址,如果多个线程同时修改同一个就需要像排队那样,一个线程修改完另一个线程才能进去。
/*
当一个线程执行原子操作时,它会尝试使用硬件提供的原子操作指令对共享资源进行修改。如果该操作成功,其他线程在执行相同的原子操作时将会失败,因为硬件会自动保证同一时刻只有一个线程能够成功执行原子操作。
如果其他线程在执行原子操作时发现资源已经被锁定,它们将被阻塞或者进入自旋等待的状态。这些线程会持续尝试执行原子操作,直到资源被解锁,并且它们能够成功地执行原子操作为止。这种等待的机制通常由操作系统的调度器或硬件提供的机制来管理。
具体的等待机制可能因操作系统和硬件的不同而有所区别。一种常见的等待机制是自旋锁,它会在等待期间一直尝试获取锁,而不是进入睡眠状态。这可以减少线程从睡眠状态唤醒的开销,但也可能导致CPU资源被浪费。另一种等待机制是线程的阻塞,其中线程会被挂起并等待唤醒,直到资源可用。
*/
而应对于这个,就要提出线程局部变量
这样每个线程就只有一次原子操作,而不是网格跨步循环的那么多次原子操作了。当然,我们需要调小 gridDim * blockDim 使其远小于 n,这样才能够减少原子操作的次数。这就是胡渊鸣所说的 TLS
__global__ void parallel_sum(int *sum, int const *arr, int n) {
int local_sum = 0;
for (int i = blockDim.x * blockIdx.x + threadIdx.x;
i < n; i += blockDim.x * gridDim.x) {
local_sum += arr[i];
}
atomicAdd(&sum[0], local_sum);
}板块与共享内存:
•刚刚的数组求和例子,其实可以不需要原子操作。
刚刚我们直接用了一个 for 循环迭代所有1024个元素,实际上内部仍然是一个串行的过程,数据是强烈依赖的(local_sum += arr[j] 可以体现出,下一时刻的 local_sum 依赖于上一时刻的 local_sum)
要消除这种依赖,可以通过右边这样的逐步缩减,这样每个 for 循环内部都是没有数据依赖,从而是可以并行的。
__global__ void parallel_sum(int *sum, int const *arr, int n) {
for (int i = blockDim.x * blockIdx.x + threadIdx.x;
i < n / 1024; i += blockDim.x * gridDim.x) {
int local_sum[1024];
for (int j = 0; j < 1024; j++) {
local_sum[j] = arr[i * 1024 + j];
}
for (int j = 0; j < 512; j++) {
local_sum[j] += local_sum[j + 512];
}
for (int j = 0; j < 256; j++) {
local_sum[j] += local_sum[j + 256];
}
for (int j = 0; j < 128; j++) {
local_sum[j] += local_sum[j + 128];
}
for (int j = 0; j < 64; j++) {
local_sum[j] += local_sum[j + 64];
}
for (int j = 0; j < 32; j++) {
local_sum[j] += local_sum[j + 32];
}
for (int j = 0; j < 16; j++) {
local_sum[j] += local_sum[j + 16];
}
for (int j = 0; j < 8; j++) {
local_sum[j] += local_sum[j + 8];
}
for (int j = 0; j < 4; j++) {
local_sum[j] += local_sum[j + 4];
}
for (int j = 0; j < 2; j++) {
local_sum[j] += local_sum[j + 2];
}
for (int j = 0; j < 1; j++) {
local_sum[j] += local_sum[j + 1];
}
sum[i] = local_sum[0];
}
}
•刚刚已经实现了无数据依赖可以并行的 for,那么如何把他真正变成并行的呢?这就是板块的作用了,我们可以把刚刚的线程升级为板块,刚刚的 for 升级为线程,然后把刚刚 local_sum 这个线程局部数组升级为板块局部数组。那么如何才能实现板块局部数组呢?
__global__ void parallel_sum(int *sum, int const *arr, int n) {
__shared__ volitale int local_sum[1024];
int j = threadIdx.x;
int i = blockIdx.x;
local_sum[j] = arr[i * 1024 + j];
__syncthreads();
if (j < 512) {
local_sum[j] += local_sum[j + 512];
}
__syncthreads();
if (j < 256) {
local_sum[j] += local_sum[j + 256];
}
__syncthreads();
if (j < 128) {
local_sum[j] += local_sum[j + 128];
}
__syncthreads();
if (j < 64) {
local_sum[j] += local_sum[j + 64];
}
__syncthreads();
if (j < 32) {
local_sum[j] += local_sum[j + 32];
}
__syncthreads();
if (j < 16) {
local_sum[j] += local_sum[j + 16];
}
__syncthreads();
if (j < 8) {
local_sum[j] += local_sum[j + 8];
}
__syncthreads();
if (j < 4) {
local_sum[j] += local_sum[j + 4];
}
__syncthreads();
if (j < 2) {
local_sum[j] += local_sum[j + 2];
}
__syncthreads();
if (j == 0) {
sum[i] = local_sum[0] + local_sum[1];
}
}
而且是这样做会引起线程组分歧,这样虽然会增加运算的次数,但反而会更快。
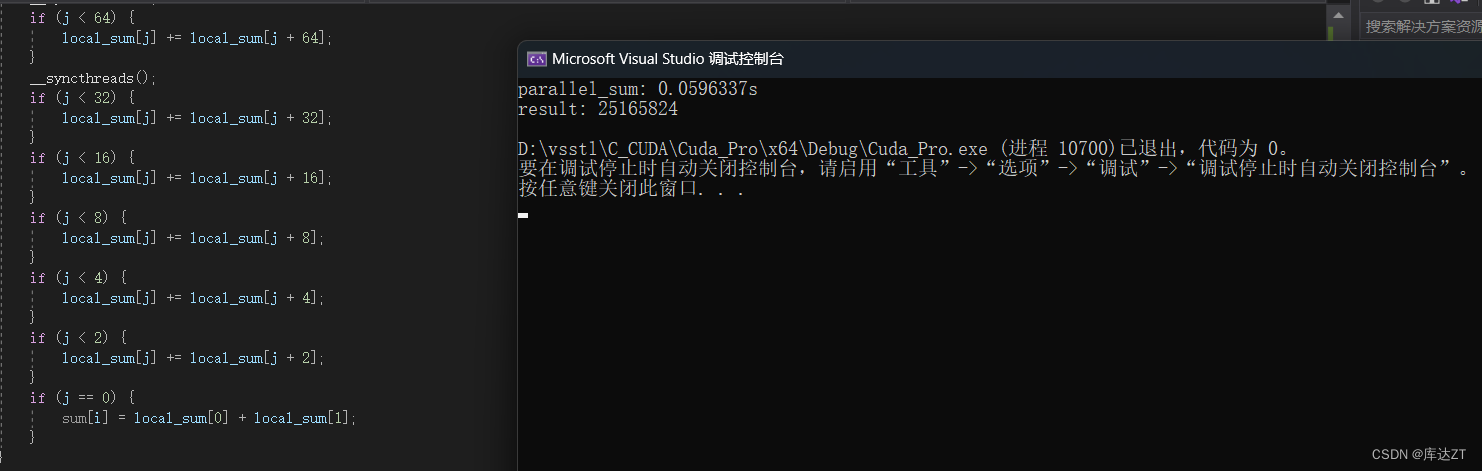
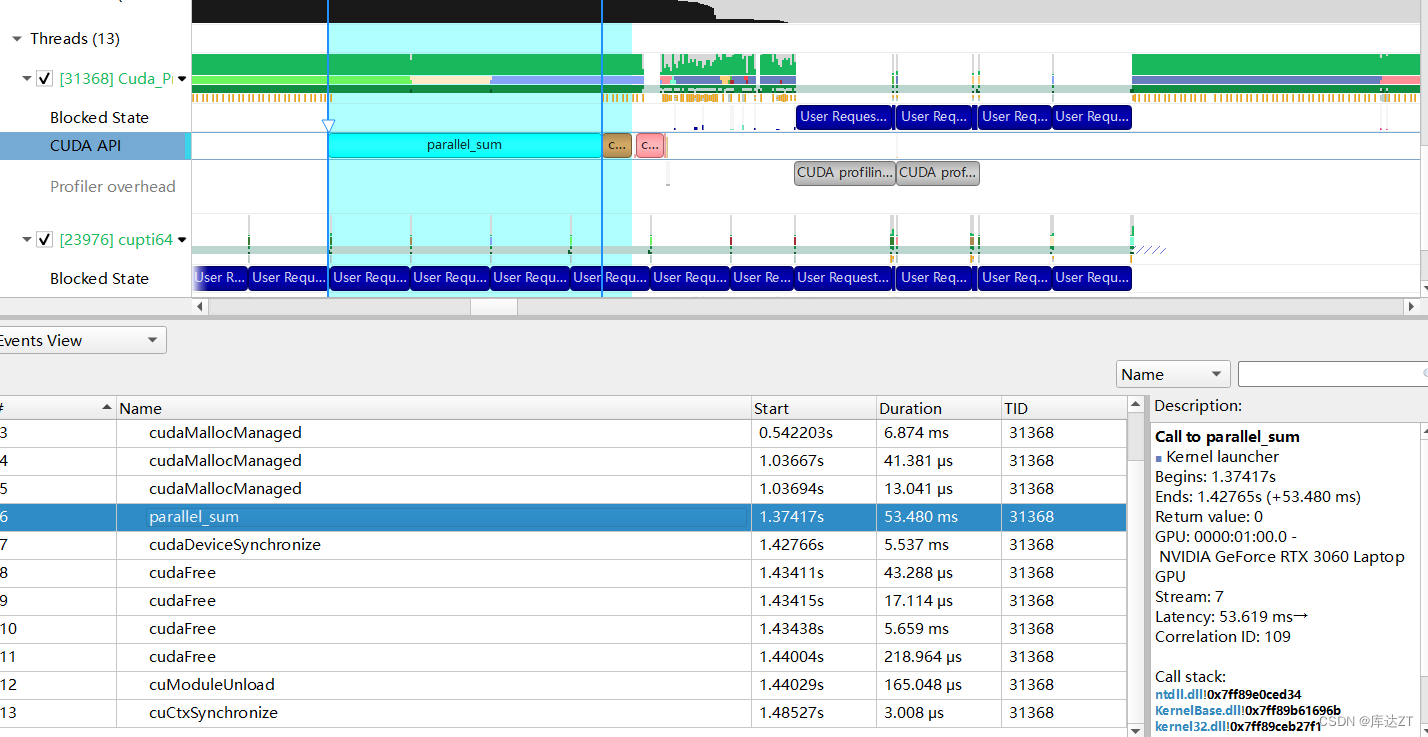
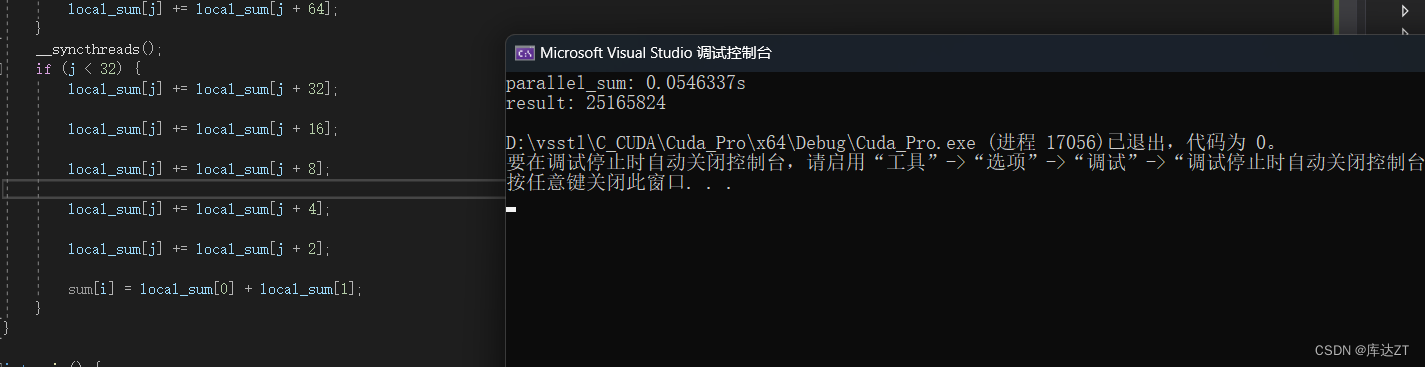
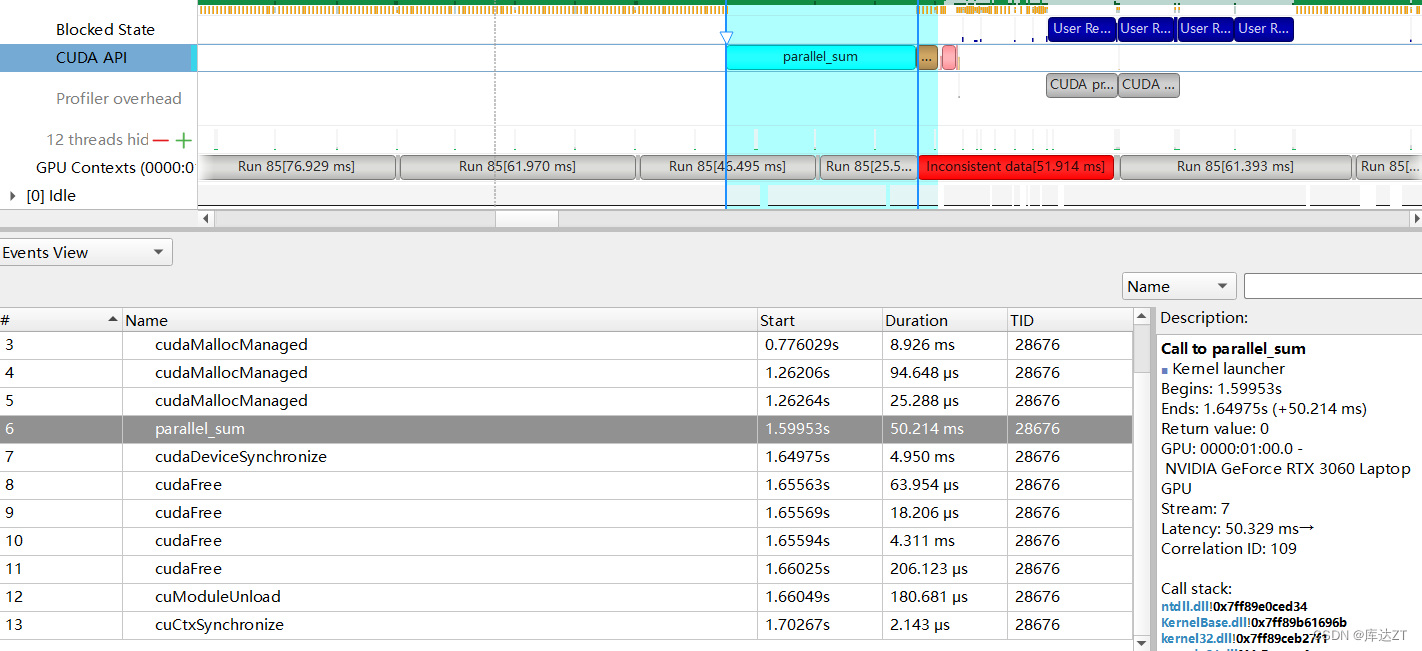
可以看到确实有提速。
但是要是运用上网格跨步,能更快
__global__ void parallel_sum_kernel(T *sum, T const *arr, int n) {
__shared__ volatile int local_sum[blockSize];
int j = threadIdx.x;
int i = blockIdx.x;
T temp_sum = 0;
for (int t = i * blockSize + j; t < n; t += blockSize * gridDim.x) {
temp_sum += arr[t];
}
local_sum[j] = temp_sum;
__syncthreads();
if constexpr (blockSize >= 1024) {
if (j < 512)
local_sum[j] += local_sum[j + 512];
__syncthreads();
}使用板块局部数组(共享内存)来加速数组求和
这就是 BLS(block-local storage)
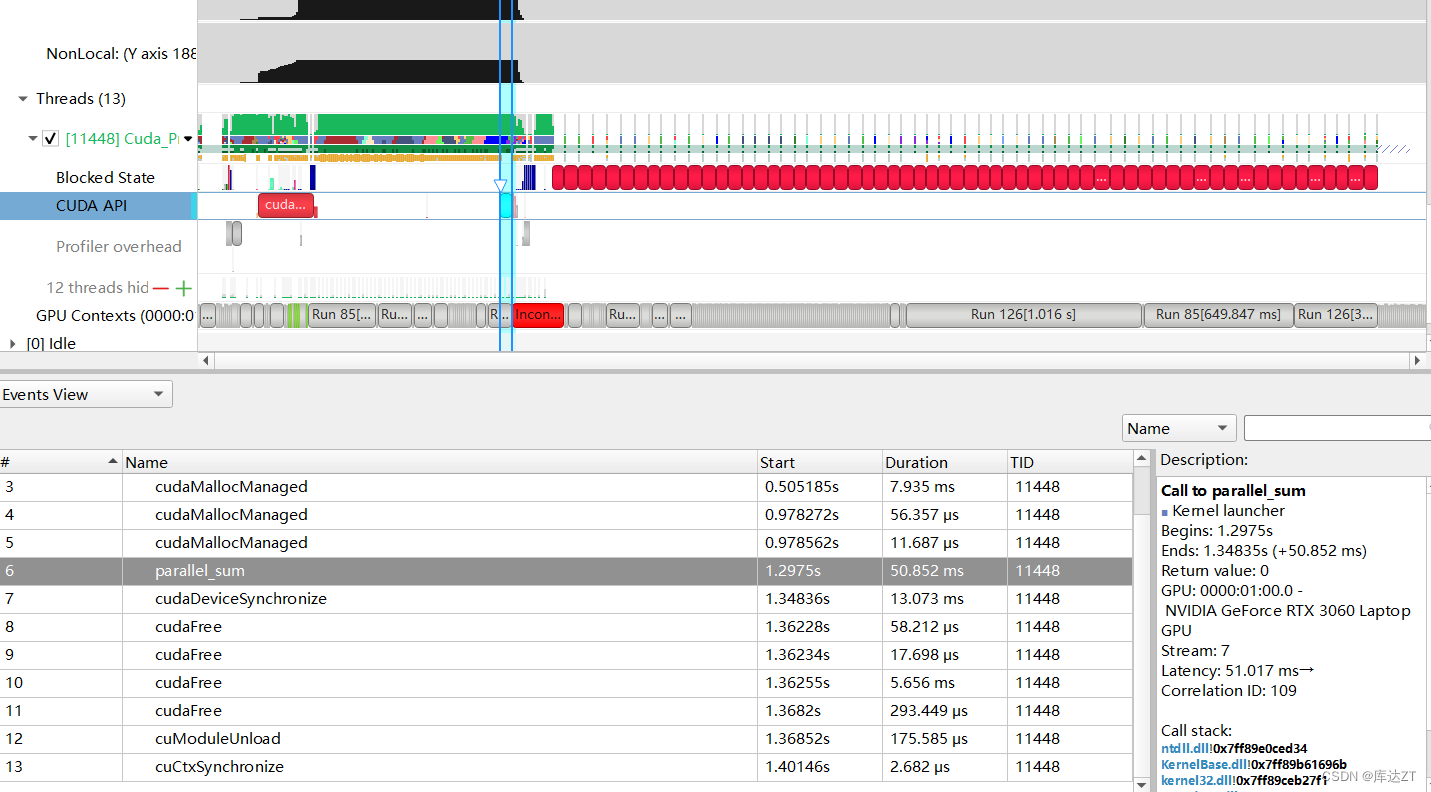
可以发现,使用atomicadd的方法可以达到近似的效果,这也是由于atomicAdd被编译器自动优化为了BLS。
__global__ void parallel_sum(int* sum, int const* arr, int n) {
int local_sum = 0;
for (int i = blockIdx.x * blockDim.x + threadIdx.x; i < n; i += blockDim.x * gridDim.x)
{
local_sum += arr[i];
}
atomicAdd(&sum[0], local_sum);
}
shared_memory 进阶
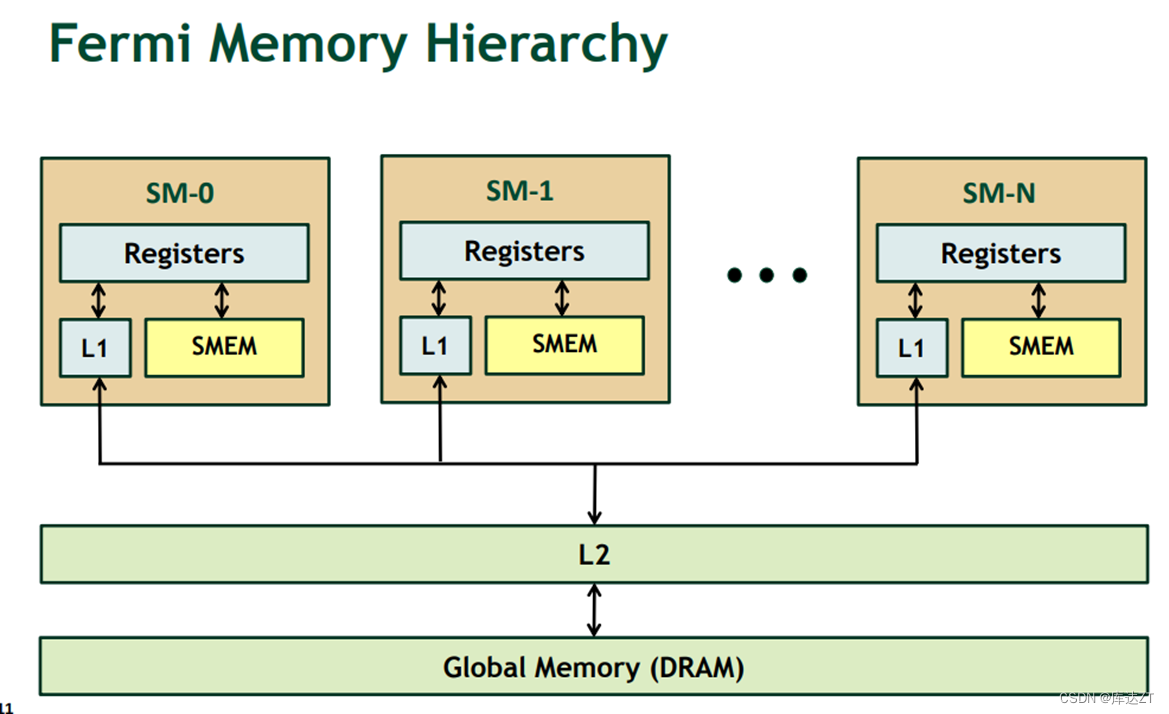
每个SM都有固定数量的寄存器,但是会有问题,
如果blockDim数量太大,就会导致每个SM里的线程数过多。就会造成寄存器打翻现象
而如果blockDim的数量太小,就会造成 延迟隐藏失效 的情况
来看一个最基本的矩阵转置:
template <class T>
__global__ void parallel_transform(T* out, T const* in, int nx, int ny) {
int tid = blockDim.x * blockIdx.x + threadIdx.x;
int y = tid / nx;
int x = tid % nx;
if (x >= nx || y >= ny) return;
out[y * nx + x] = in[x * nx + y];
}
int main() {
int nx = 1 << 14, ny = 1 << 14;
std::vector<int, CudaAllocator<int>> in(nx * ny);
std::vector<int, CudaAllocator<int>> out(nx * ny);
for (int i = 0; i < nx * ny; i++) {
in[i] = i;
}
TICK(parallel_transpose);
parallel_transform << <nx * ny / 1024, 1024 >> >
(out.data(), in.data(), nx, ny);
CHECK(cudaDeviceSynchronize());
TOCK(parallel_transpose);
for (int y = 0; y < ny; y++) {
for (int x = 0; x < nx; x++) {
if (out[y * nx + x] != in[x * nx + y]) {
printf("Wrong At x=%d,y=%d: %d != %d\n", x, y,
out[y * nx + x], in[x * nx + y]);
return -1;
}
}
}
printf("All Correct!\n");
return 0;
}
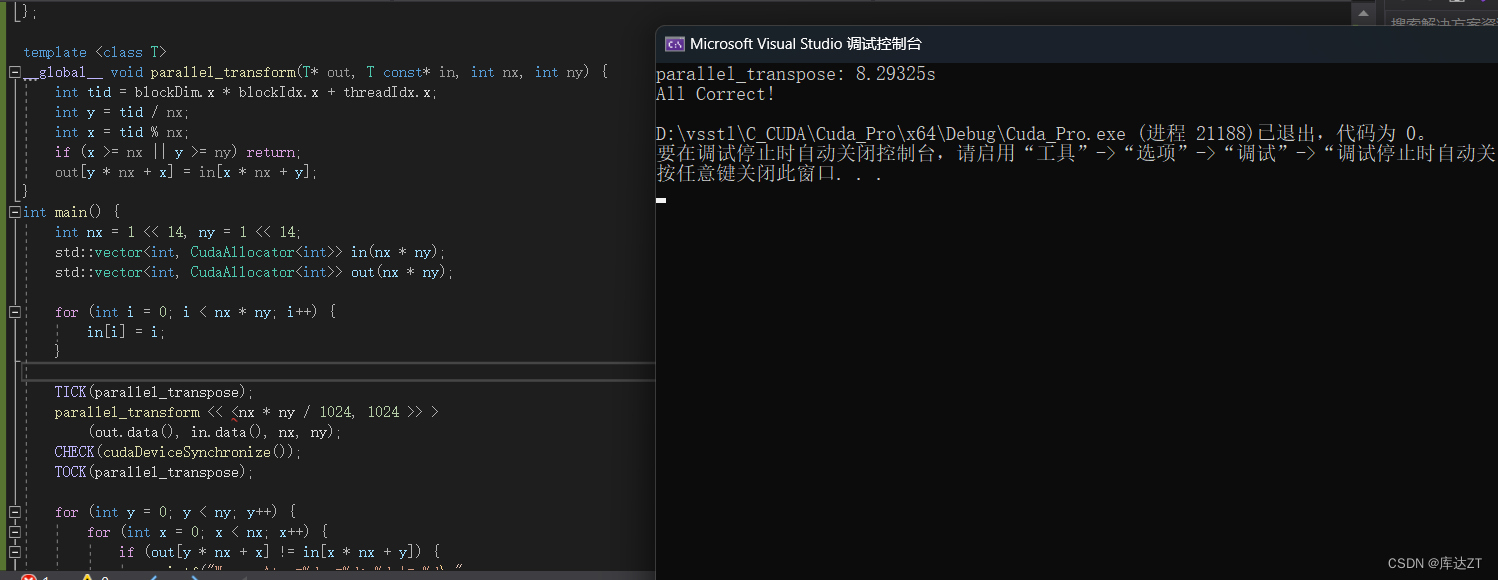
可以看到,这里out是按行读取了,但in没有,所以很低效,在cpu中可以用for来进行循环分块,但在这里没有for那怎么分块呢?
不要忘记这里是GPU啊,nx,ny都有dim3的,有天然的block可以进行分块啊!!!
template <class T>
__global__ void parallel_transform(T* out, T const* in, int nx, int ny) {
int x = blockDim.x * blockIdx.x + threadIdx.x;
int y = blockDim.y * blockIdx.y + threadIdx.y;
if (x >= nx || y >= ny) return;
out[y * nx + x] = in[x * nx + y];
}
int main() {
int nx = 1 << 14, ny = 1 << 14;
std::vector<int, CudaAllocator<int>> in(nx * ny);
std::vector<int, CudaAllocator<int>> out(nx * ny);
for (int i = 0; i < nx * ny; i++) {
in[i] = i;
}
TICK(parallel_transpose);
parallel_transform << <dim3(nx/32, ny / 32,1),dim3(32,32,1) >> >
(out.data(), in.data(), nx, ny);
CHECK(cudaDeviceSynchronize());
TOCK(parallel_transpose);
for (int y = 0; y < ny; y++) {
for (int x = 0; x < nx; x++) {
if (out[y * nx + x] != in[x * nx + y]) {
printf("Wrong At x=%d,y=%d: %d != %d\n", x, y,
out[y * nx + x], in[x * nx + y]);
return -1;
}
}
}
printf("All Correct!\n");
return 0;
}
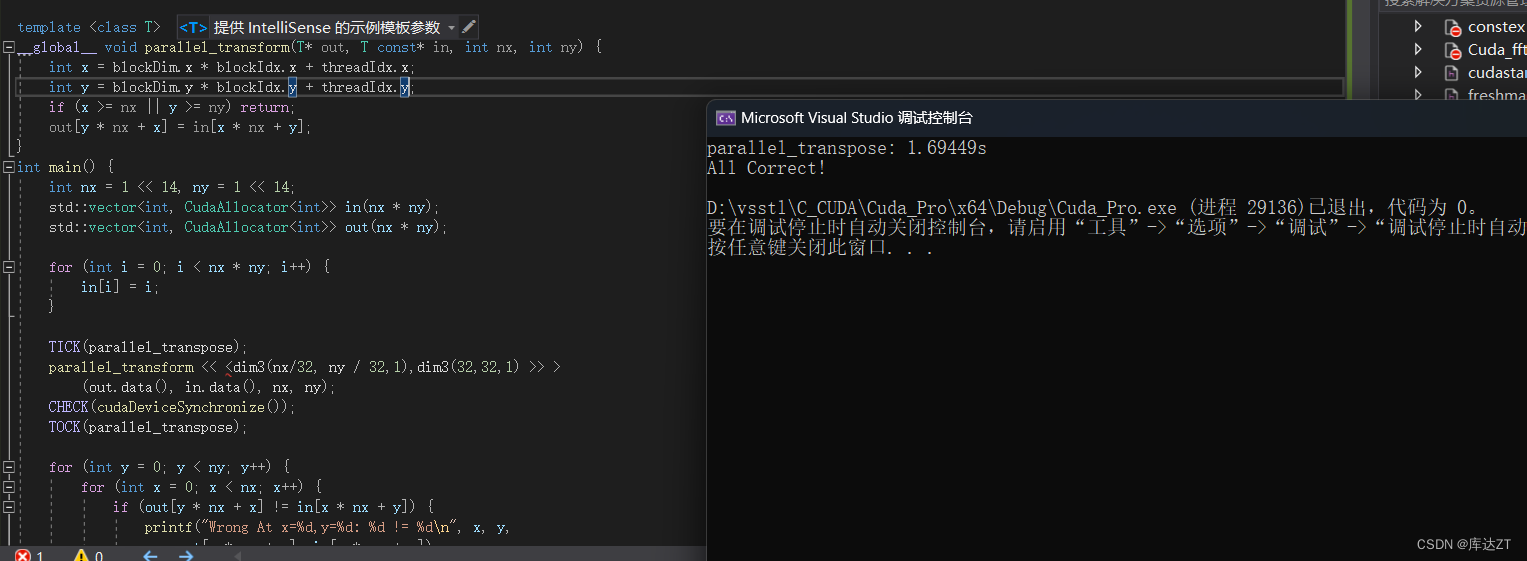
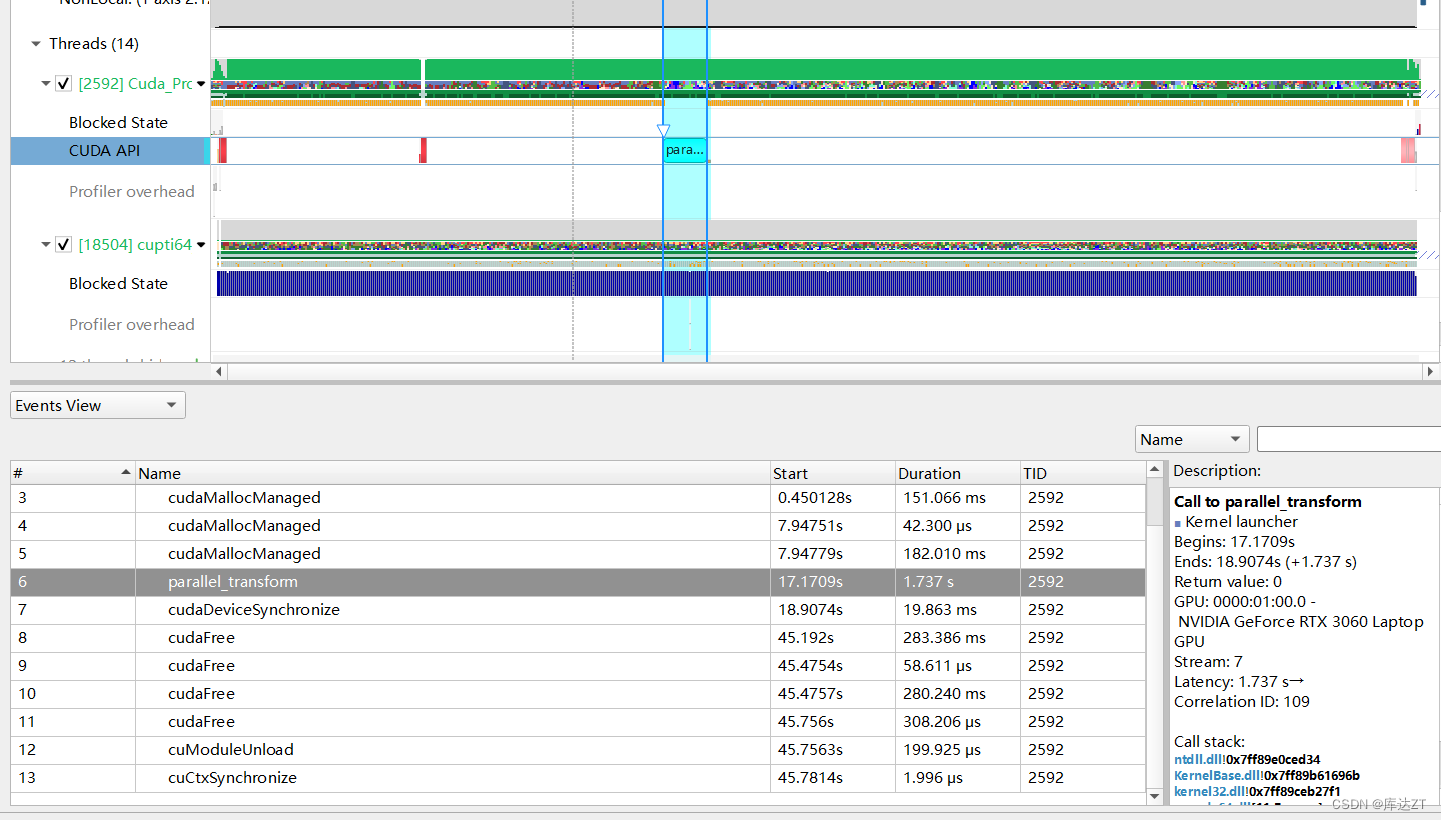
可以看到性能提升巨大。
- 刚刚那样的话对 in 的读取是存在跨步的,而 GPU 喜欢连续的顺序读取,这样跨步就不高效了。
- 但是因为我们的目的是做矩阵转置,无论是 in 还是 out 必然有一个是需要跨步的,怎么办?
- 因此可以先通过把 in 分块,按块跨步地读,而块内部则仍是连续地读——从低效全局的内存读到高效的共享内存中,然后在共享内存中跨步地读,连续地写到 out 指向的低效的全局内存中。
- 这样跨步的开销就开在高效的共享内存上,而不是低效的全局内存上,因此会变快。
template <int blockSize , class T>
__global__ void parallel_transform(T* out, T const* in, int nx, int ny) {
int x = blockDim.x * blockIdx.x + threadIdx.x;
int y = blockDim.y * blockIdx.y + threadIdx.y;
if (x >= nx || y >= ny) return;
__shared__ T tmp[blockSize * blockSize];
//把in分块,按块跨步,就没有按线程那么大的开销
int rx = blockIdx.y * blockSize + threadIdx.x;
int ry = blockIdx.x * blockSize + threadIdx.y;
tmp[threadIdx.y * blockSize + threadIdx.x] = in[ry * nx + rx];
__syncthreads();
out[y * nx + x] = tmp[threadIdx.x * blockSize + threadIdx.y];
}
int main() {
int nx = 1 << 14, ny = 1 << 14;
std::vector<int, CudaAllocator<int>> in(nx * ny);
std::vector<int, CudaAllocator<int>> out(nx * ny);
for (int i = 0; i < nx * ny; i++) {
in[i] = i;
}
TICK(parallel_transpose);
parallel_transform<32> << <dim3(nx/32, ny / 32,1),dim3(32,32,1) >> >
(out.data(), in.data(), nx, ny);
CHECK(cudaDeviceSynchronize());
TOCK(parallel_transpose);
....
printf("All Correct!\n");
return 0;
}
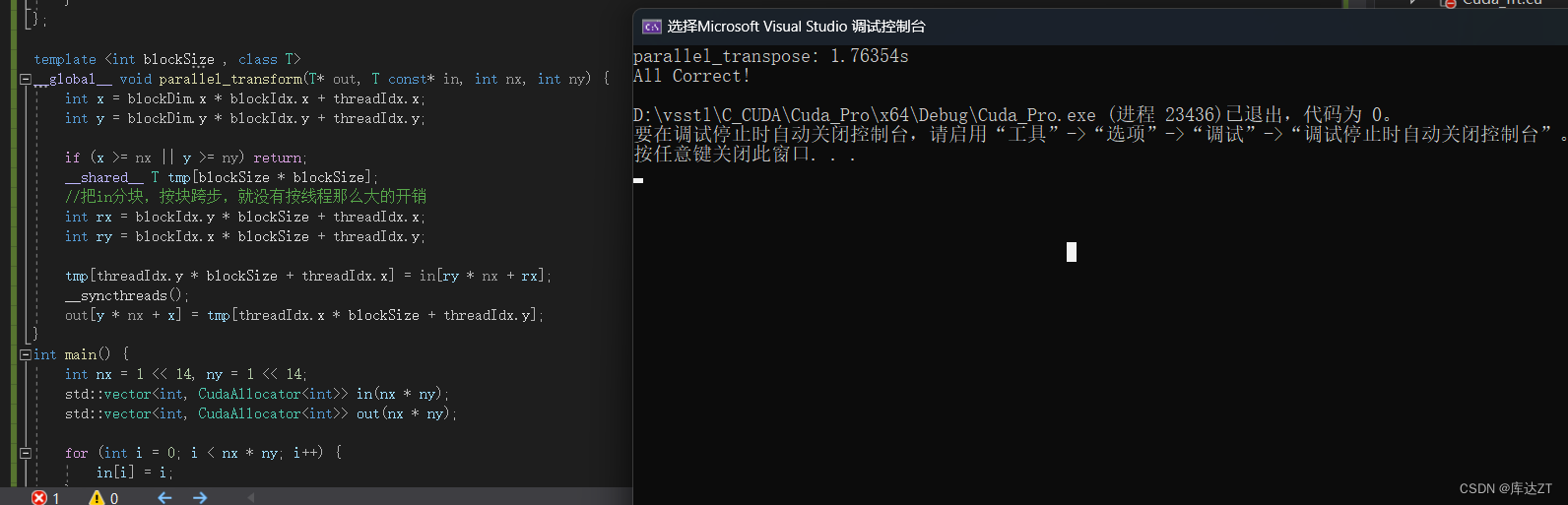
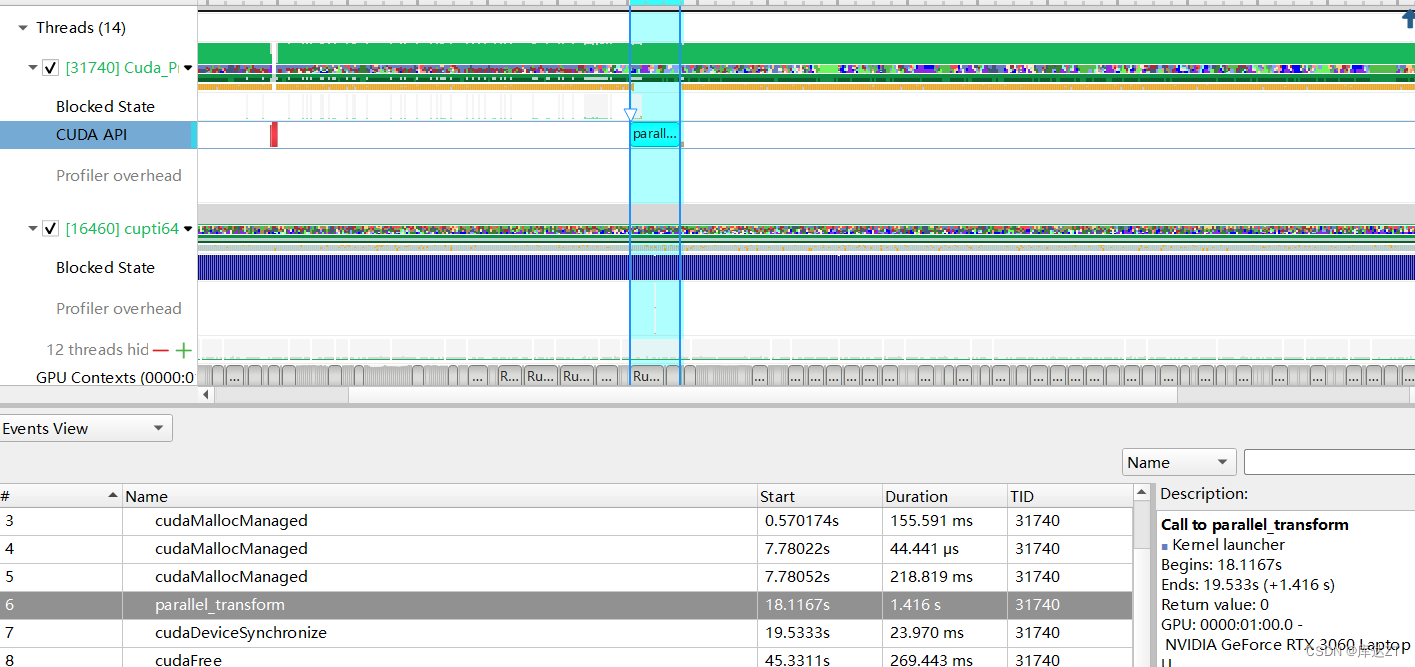
可以看到速度提升了一些。
Bank conflict
而刚刚那个矩阵转置的例子,这里的 blockSize 是 32。可以看到第一个对 tmp 的访问是没冲突的。
而分析一下第二个对 tmp 的访问:threadIdx=(0,0) 的线程 0 会访问 tmp[0] 位于 bank 0;threadIdx=(0,1) 的线程 1 会访问 tmp[32] 也位于 bank 0;threadIdx=(0,1) 的线程 2 会访问 tmp[64] 也位于 bank 0……也就是说,同一个 warp 的所有线程都在访问 bank 0
所以就可以使用移位的方法来减少bank conflict
template <int blockSize , class T>
__global__ void parallel_transform(T* out, T const* in, int nx, int ny) {
int x = blockDim.x * blockIdx.x + threadIdx.x;
int y = blockDim.y * blockIdx.y + threadIdx.y;
if (x >= nx || y >= ny) return;
__shared__ T tmp[(blockSize+1) * blockSize];
//把in分块,按块跨步,就没有按线程那么大的开销
int rx = blockIdx.y * blockSize + threadIdx.x;
int ry = blockIdx.x * blockSize + threadIdx.y;
tmp[threadIdx.y * (blockSize+1) + threadIdx.x] = in[ry * nx + rx];
__syncthreads();
out[y * nx + x] = tmp[threadIdx.x * (blockSize+1) + threadIdx.y];
}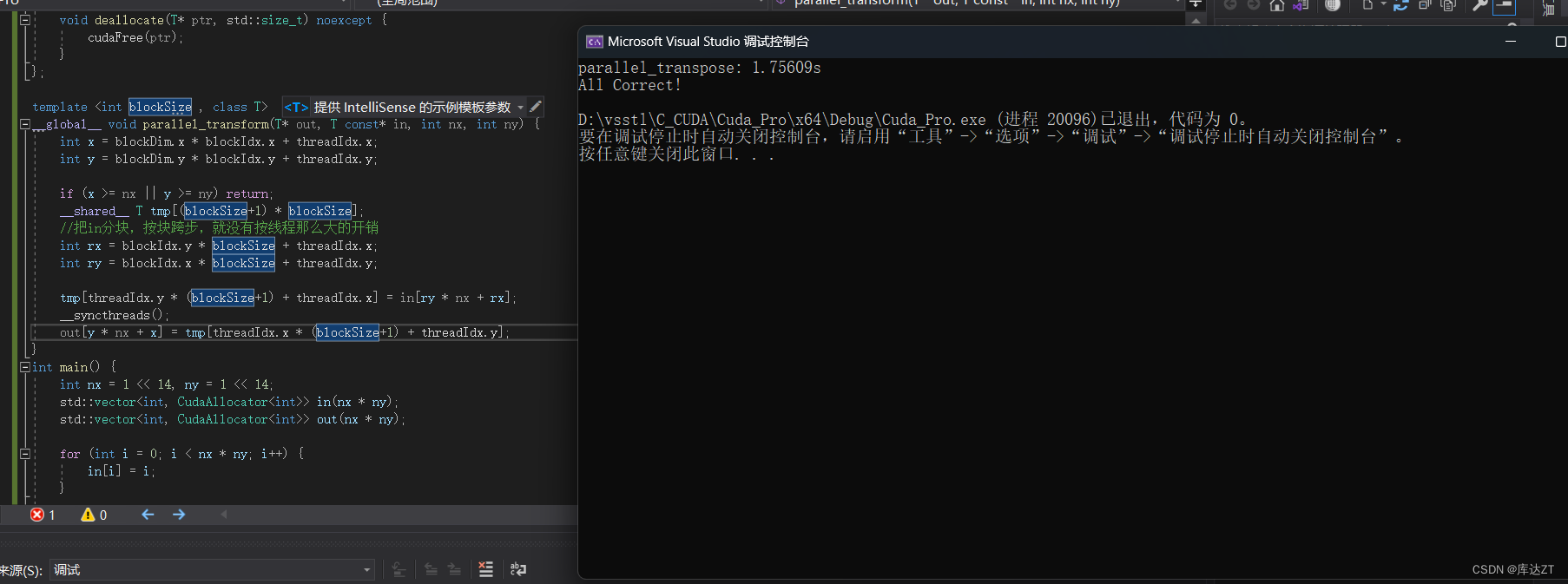
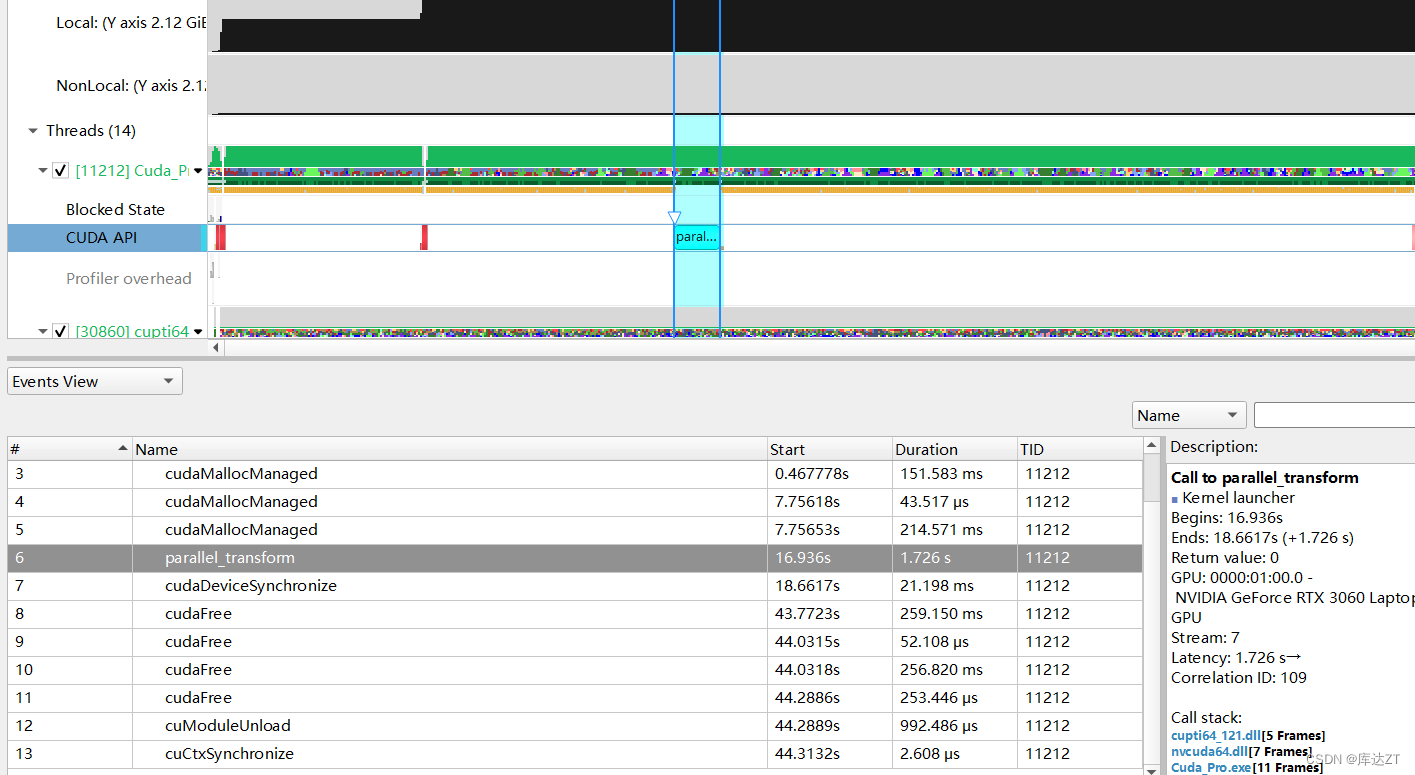
但是这样好像效果提升的也没有很好,感觉是blocksize设置的不太好,我再改改。















 165
165











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









