







基于机器学习的方法做OCR识别详见我其他博客:http://blog.csdn.net/zhubenfulovepoem/article/details/51165887
3.2 字符区域………………………………………………………………………….4
5.1 训练样本制作………………………………………………………………………………….6
5.2设计BP神经网络………………………………………………………………………………6
摘 要
在MATLAB环境下利用USB摄像头采集字符图像,读取一帧保存为图像,然后对读取保存的字符图像,灰度化,二值化,在此基础上做倾斜矫正,对矫正的图像进行滤波平滑处理,然后对字符区域进行提取分割出单个字符,识别方法一是采用模板匹配的方法逐个对字符与预先制作好的字符模板比较,如果结果小于某一阈值则结果就是模板上的字符;二是采用BP神经网络训练,通过训练好的net对待识别字符进行识别。最然后将识别结果通过MATLAB下的串口工具输出51单片机上用液晶显示出来。
关键字: 倾斜矫正,字符分割,模板匹配,BP神经网络,液晶显示
MATLAB代码下载地址:http://www.pudn.com/downloads386/sourcecode/graph/text_recognize/detail1655710.html
Abstract
In the MATLAB environmentusing USB camera capture the character images, saved as an image reading, thenread the saved character images, grayscale, binary, on this basis do tilt correction,the correction image smoothing filter, and then extract the character regionsegmentation of a single character, and then one by one using a templatematching method of character with good character template is a pre-production,if the result is less than a certain threshold, the result is a template of thecharacter. Second, the BP neural network trained by the trained net to identifythe character towards recognition The results will identify the most and thenthe serial port through the MATLAB tool output 51 under microcontroller withLCD display.
Keyword: Tilt correction, character segmentation,template matching, liquid crystal display
一 引言:
光学字符识别(OCR,Optical Character Recognition)是指对文本资料进行扫描,然后对图像文件进行分析处理,获取文字及版面信息的过程。已有30多年历史,近几年又出现了图像字符识别(image character recognition,ICR)和智能字符识别(intelligent character recognition,ICR),实际上这三种自动识别技术的基本原理大致相同。
关于字符识别的方法有很多种,最简单的就是模板匹配,还有根据采集到的字符用BP神经网络或者SVM来训练得到结果的方式。本文主要针对模板匹配的方式,在MATLAB环境下编程实现。
二 字符图像获取:
在MATLAB下利用image acquisition toolbox获取视频帧,并保存图像在工程文件夹内。摄像头采用普通的USB摄像头,由于这种摄像头拍摄的照片延时比较大,所以先用image acquisition toolbox下的对视频进行预览,调整出最佳的效果来,采集的图像效果越好则识别率越高。 根据测试,实验选择640*480的视频获取窗口,颜色空间选取为RGB空间,获取一帧后保存为jpg的存储格式。

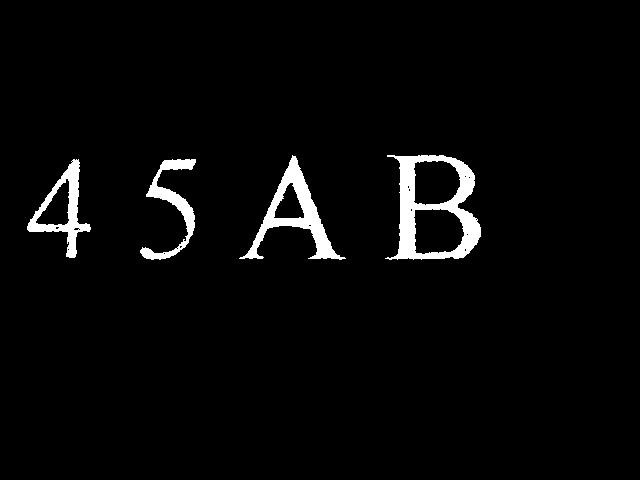
三 字符预处理
3.1字符矫正
由于摄像头拍摄的图像存在一定存在的倾斜度,在分割字符区域时,应先对字符进行矫正。过程如下:
将通过摄像头获取的保存帧图像灰度化,然后对其进行边缘提取,再在1到180度角内对图像进行旋转,记录下边缘提取后的图像在x轴方向上的投影,当x轴方向上的投影最小的时候即表示图像中字符平行于y轴,已经完成矫正,此时记录下旋转的倾斜角。然后利用imrotate函数实现对字符图像的矫正。
3.2 字符区域分割:
在第三步完成对字符图像的倾斜矫正后,将图像分别做x轴和y轴方向上的投影既可以知道字符区域在x轴上的像素分布范围和y轴上的像素分布范围,然后对根据这个范围对图像做分割,在MATLAB中表示为:
goal=I(ix1:iy1,jx1:jy1);
其中goal为分割后的图像,I为分割前的图像,ix1和ix2分别为x轴上投影的像素范围的起始坐标值和终止坐标值,iy1和iy2分别为y轴上投影的像素范围的起始坐标值和终止坐标值。

3.3 单个字体分割:
在分割得到的字符区域图像上,只需要做y轴上的投影就可以知道每个字符在y轴上的分布区间,然后利用这个分布区间就可以分割出单个字符。

3.4 单个字体裁剪
在第五步分割出来的字符基础上进一步对字符的像素区域进行裁剪,原理也是分别做x轴,y轴方向上的投影,求的字符的区间再做剪裁。
四 模板字符识别
4.1字符模板制作:
模板的要求是与要识别的字符的字体格式一致,实验中采用word上的标准字符,通过截图软件截图后按照3-6步的处理过程制作出需要的字符模板,从0到9共10个数字,A到Z共26个字母。
4.2 字符模板归一化
在满足识别率的条件下,尽量采用小模板识别可以提神运算速度,具体的模板大小,可以根据后面的与待识别字符的比较中调节。
4.3识别过程:
将待识别字符与字符模板做同样的归一化处理,然后遍历与字符模板比较,处理方法为先和字符模板做差,然后计算做差后的图像的总像素值,如果小于每一个阈值,则表示该待识别字符和该模板是同一个字符,这样就完成了一次识别。
循环对要识别的字符做同样的处理就可以识别出所有的字符,将结果保存在字符串中。
五 BP神经网络字符识别
BP(Back Propagation)网络是1986年由Rumelhart和McCelland为首的科学家小组提出,是一种按误差逆传播算法训练的多层前馈网络,是目前应用最广泛的神经网络模型之一。BP网络能学习和存贮大量的输入-输出模式映射关系,而无需事前揭示描述这种映射关系的数学方程。它的学习规则是使用最速下降法,通
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 2176
2176











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









