







一、Btrfs概述
Btrfs(B-tree 文件系统,通常念成 Butter FS,Better FS或B-tree FS),一种支持写入时复制(COW)的文件系统,运行在 Linux 操作系统上。Oracle于 2007 年对外宣布这项计划,并发布源代码,2014 年 8 月发布稳定版。目标是取代Linux 当时主流的 Ext3 文件系统,摆脱 ext3 的一些限制,特別是单文件大小,文件系统总大小和文件校验,并加入 ext3 不支持的一些功能,比如可写快照(writable snapshots)、快照的快照(snapshots of snapshots)、内建磁盘阵列(RAID),以及子卷(subvolumes)。Btrfs 也宣称专注于「容错、修复及易于管理」。
二、Btrfs特性
Btrfs主页给出的特性列表中大致可以分为四个部分:
- 扩展性 (scalability) 相关的特性。Btrfs 最重要的设计目标是应对大型机器对文件系统的扩展性要求。 Extent,B-Tree 和动态 inode 创建等特性保证了 Btrfs 在大型机器上仍有卓越的表现,其整体性能而不会随着系统容量的增加而降低。
- 数据一致性 (data integrity) 相关的特性。系统面临不可预料的硬件故障,Btrfs 采用 COW 事务技术来保证文件系统的一致性。 Btrfs 还支持 checksum,避免了 silent corrupt 的出现。而传统文件系统则无法做到这一点。
- 多设备管理相关的特性。 Btrfs 支持创建快照 (snapshot)和克隆 (clone) 。 Btrfs 还能够方便的管理多个物理设备,使得传统的卷管理软件变得多余。
- 其他特性。这些特性都是比较先进的技术,能够显著提高文件系统的时间 / 空间性能,包括延迟分配,小文件的存储优化,目录索引等。
延伸:
Btrfs有些特性与苹果APFS文件系统类似, 比如,COW, 快照,克隆, 如果感兴趣,请翻阅之前的文章“【文件系统系列专题之三 】苹果革命性黑科技APFS,手机存储空间不足的救星”。
1. 扩展性相关的特性
(1) B-Tree
Btrfs 文件系统中所有的 metadata 都由 BTree 管理。使用 BTree 的主要好处在于查找,插入和删除操作都很高效。可以说 BTree 是 btrfs 的核心。
说Btrfs B-Tree结构之前,不妨先来看看Ext2/3的文件结构。Ext2/3采用的是
其目录的组织方式。目录是一种特殊的文件,在 ext2/3内容是一张线性表格。如下图所示:
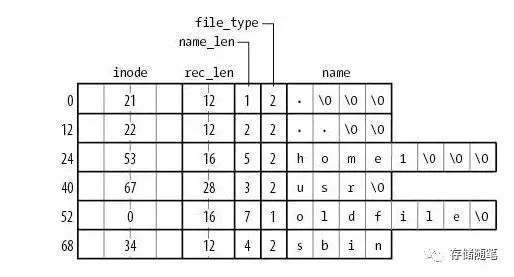
上图 展示了一个 ext2 目录文件的内容,该目录中包含四个文件。分别是 "home1","usr","oldfile" 和 "sbin" 。如果需要在该目录中查找目录 sbin,ext2 将遍历前三项,直至找到 sbin 这个字符串为止。
这种结构在文件个数有限的情况下是比较直观的设计,但随着目录下文件数的增加,查找文件的时间将线性增长。 2003 年,ext3 设计者开发了目录索引技术,解决了这个问题。目录索引使用的数据结构就是BTree 。如果同一目录下的文件数超过 2K,inode 中的 i_data 域指向一个特殊的 block 。在该 block 中存储着目录索引 BTree 。 BTree 的查找效率高于线性表,但为同一个元数据设计两种数据结构总是不太优雅。在文件系统中还有很多其他的元数据,用统一的 BTree 管理是非常简单而优美的设计。
Btrfs 内部所有的元数据都采用 BTree 管理,拥有良好的可扩展性。 Btrfs 内部不同的元数据由不同的 Tree 管理。在 superblock 中,有指针指向这些 BTree 的根。如下图所示:
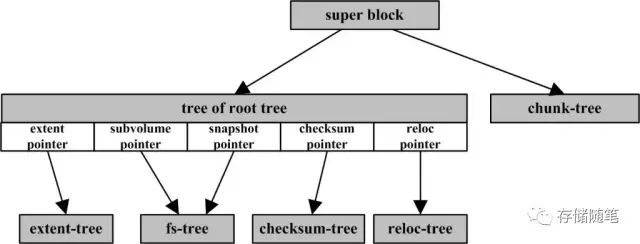
- 所有B+tree的root都由root-tree来管理(除了chunk-tree),而super block指向root-tree的根节点,Tree of tree root 保存很多 BTree 的根节点。比如用户每建立一个快照,btrfs 便会创建一个 FS Tree 。
- 所有extent都由extent-tree管理,extent Tree 管理磁盘空间分配,btrfs 每分配一段磁盘空间,便将该磁盘空间的信息插入到 extent tree 。查询 extent Tree 将得到空闲的磁盘空间信息;
- 所有meta和data信息都采用fs-tree来管理。文件系统相关的meta信息(如inode,dentry等)都放在fs-tree中。这里一棵fs-tree对应一个物理分区或者一个snapshot或者一个clone;每个leaf(单个extent)直接包含meta的数据,而file data的数据则通过指针指向另外分配的extent(对于小文件直接放在leaf extent中,有助于减少磁盘碎片)。
- Chunk tree 管理设备,每一个磁盘设备都在 Chunk Tree 中有一个 item。另外chunk-tree维护了logical chunk到physical chunk的映射,所有的存储分配都是基于logical chunk的(这部分由前面所说的extent-tree来负责完成)。同时physical chunk被分成多个group,目的是为了支持RAID。
- Checksum Tree 保存数据块的校验和。
- Btrfs还维护了一棵relocation-tree,目的是为了支持online的磁盘碎片整理。所谓relocation是基于chunk来操作的(而不是extent),relocation会把需要处理的chunk中的所有extent以及对应的reference找出来,重新分配到新的chunk中。
(2) 基于 Extent 的文件存储
现代很多文件系统都采用了 extent 替代 block 来管理磁盘。
- Extent 是 btrfs 管理磁盘空间的最小单位,由 extent tree 管理。
- Extent就是一些连续的block,一个 extent 由起始的 block 加上长度进行定义。Extent 能有效地减少元数据开销。
- Btrfs 分配 data 或 metadata 都需要查询 extent tree 以便获得空闲空间的信息。
我们同样以Ext2/3来对比:
Ext2/3以block为基本单位,将磁盘划分为多个block 。为了管理磁盘空间,文件系统需要知道哪些 block 是空闲的。 Ext 使用 bitmap 来达到这个目的。 Bitmap 中的每一个 bit 对应磁盘上的一个 block,当相应 block 被分配后,bitmap 中的相应 bit 被设置为 1 。这是很经典也很清晰的一个设计,但不幸的是当磁盘容量变大时,bitmap 自身所占用的空间也将变大。这就导致了扩展性问题,随着存储设备容量的增加,bitmap 这个元数据所占用的空间也随之增加。而人们希望无论磁盘容量如何增加,元数据不应该随之线形增加,这样的设计才具有可扩展性。
下图比较了 block 和 extent 的区别:
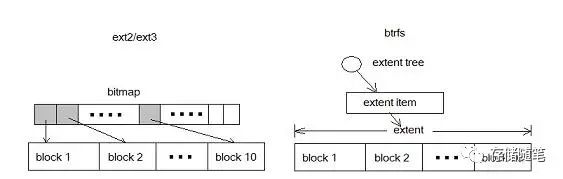
在 ext2/3 中,10 个 block 需要 10 个 bit 来表示;在 btrfs 中则只需要一个元数据。对于大文件,extent 表现出了更加优异的管理性能。
延伸:
关于Extend的内容,我们在之前介绍Ext2/3/4文件系统时有比较详细的解释, 请翻阅之前的文章“文件系统系列专题之四 Ext2/3/4”。
(3)动态 inode 分配
理解Btrfs动态inode分配,我们还是先从Ext2/3入手,
Ext2格式化后基本长下面这个样子:
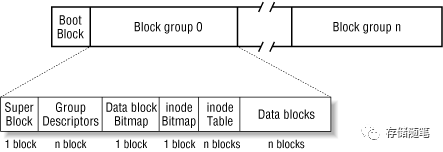
在 Ext2 中 inode 区是被预先固定分配的,且大小固定,比如一个 100G 的分区中,inode table 区中只能存放 131072 个 inode,这就意味着不可能创建超过 131072 个文件,因为每一个文件都必须有一个唯一的 inode 。
为了解决这个问题,必须动态分配 inode 。每一个 inode 只是 BTree 中的一个节点,用户可以无限制地任意插入新的 inode,其物理存储位置是动态分配的。所以 btrfs 没有对文件个数的限制。
(4)针对 SSD 的优化支持
虽然现在市场上的SSD都内部自带Wear leveling优化技术,但毕竟还是有限。文件系统针对 SSD 的特性做优化不仅能提高 SSD 的使用寿命,而且能提高读写性能。 Btrfs 是少数专门对 SSD 进行优化的文件系统。 Btrfs 用户可以使用 mount 参数打开对 SSD 的特殊优化处理。
Btrfs 的 COW 技术从根本上避免了对同一个物理单元的反复写操作。如果用户打开了 SSD 优化选项,Btrfs 将在底层的块空间分配策略上进行优化:将多次磁盘空间分配请求聚合成一个大小为 2M 的连续的块。大块连续地址的 IO 能够让固化在 SSD 内部的微代码更好的进行读写优化,从而提高 IO 性能。
延伸:
除了Btrfs, 有两个移动设备文件系统也有针对SSD做针对性的优化,
1, 华为推出的F2FS。如果感兴趣,请翻阅之前的文章“华为Mate9的杀手锏也将造福SSD”。
2, 苹果推出的APFS。如果感兴趣,请翻阅之前的文章“【文件系统系列专题之三 】苹果革命性黑科技APFS,手机存储空间不足的救星”。
2. 数据一致性相关的特性
(1)COW 事务
理解 COW 事务,必须首先理解 COW 和事务这两个术语。
什么是 COW?
所谓 COW,即每次写磁盘数据时,先将更新数据写入一个新的 block,当新数据写入成功之后,再更新相关的数据结构指向新 block 。
概念注释:写入时复制(英语:Copy-on-write,简称COW)是一种计算机程序设计领域的优化策略。其核心思想是,如果有多个调用者(callers)同时要求相同资源(如内存或磁盘上的数据存储),他们会共同获取相同的指针指向相同的资源,直到某个调用者试图修改资源的内容时,系统才会真正复制一份专用副本(private copy)给该调用者,而其他调用者所见到的最初的资源仍然保持不变。这过程对其他的调用者都是透明的(transparently)。此作法主要的优点是如果调用者没有修改该资源,就不会有副本(private copy)被创建,因此多个调用者只是读取操作时可以共享同一份资源。也就是说,资源的复制只有在需要写入的时候才进行,在此之前以只读方式共享。这种技术使得对地址空间中的页的复制被推迟到实际发生写入的时候。
什么是事务?
COW 只能保证单一数据更新的原子性。但文件系统中很多操作需要更新多个不同的元数据,比如创建文件需要修改以下这些元数据:
- 修改 extent tree,分配一段磁盘空间
- 创建一个新的 inode,并插入 FS Tree 中
- 增加一个目录项,插入到 FS Tree 中
任何一个步骤出错,文件便不能创建成功,因此可以定义为一个事务。
下面将演示一个 COW 事务。
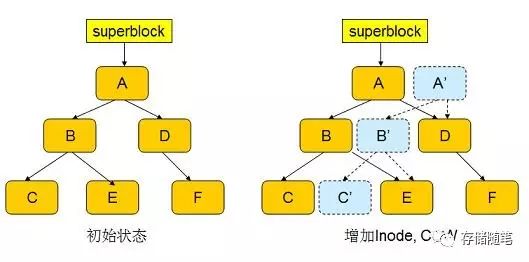
A 是 FS Tree 的根节点,新的 inode 的信息将被插入节点 C 。
- 首先,btrfs 将 inode 插入一个新分配的 block C'中,并修改上层节点 B,使其指向新的 block C';
- 修改 B 也将引发 COW,以此类推,引发一个连锁反应,直到最顶层的 Root A 。
- 当整个过程结束后,新节点 A'变成了 FS Tree 的根。但此时事务并未结束,superblock 依然指向 A 。
接下来,修改目录项(E 节点),同样引发这一过程,从而生成新的根节点 A"。
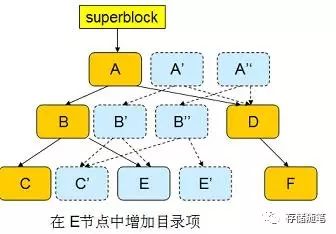
此时,inode 和目录项都已经写入磁盘,可以认为事务已经结束。 btrfs 修改 superblock,使其指向 A",如下图所示:
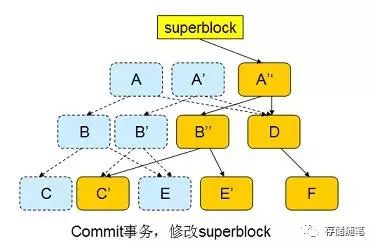
COW 事务能够保证文件系统的一致性,并且系统 Reboot 之后不需要执行 fsck 。因为 superblock 要么指向新的 A",要么指向 A,无论哪个都是一致的数据。
概念注释:fsck(file system check)用来检查和维护不一致的文件系统。若系统掉电或磁盘发生问题,可利用fsck命令对文件系统进行检查。
(2)Checksum
Checksum 技术保证了数据的可靠性,避免 silent corruption 现象。由于硬件原因,从磁盘上读出的数据会出错。比如 block A 中存放的数据为 0x55,但读取出来的数据变是 0x54,因为读取操作并未报错,所以这种错误不能被上层软件所察觉。
概念延伸:对于计算机用户来说最可怕的事情莫过于Silent Data Corruption(无记载数据损坏):文件系统遇到这个问题,往往只是简单的把错误数据直接交给上层应用。结果就是数据看起来是好的,直到你开始使用的时候才发现文件损坏。这种情况最可能出现的原因是硬件设备的问题,比如硬盘,RAID卡硬件问题,或者驱动bug。
解决这个问题的方法是保存数据的校验和,在读取数据后检查校验和。如果不符合,便知道数据出现了错误。
Ext2/3 没有校验和,对磁盘完全信任。而不幸的是,磁盘的错误始终存在。而且随着存储网络的发展,即使数据从磁盘读出正确,也很难确保能够安全地穿越网络设备。
写入磁盘数据之前,Btrfs 采用 crc32 算法计算数据的checksum。然后将 checksum 和数据同时写入磁盘。Btrfs 在读取数据的同时会读取其相应的 checksum 。如果最终从磁盘读取出来的数据和 checksum 不相同,btrfs 会首先尝试读取数据的镜像备份,如果数据没有镜像备份,btrfs 将返回错误。
Btrfs 采用单独的 checksum Tree 来管理数据块的校验和,把 checksum 和 checksum 所保护的数据块分离开,从而提供了更严格的保护。
3. 多设备管理相关的特性
每个 Unix 管理员都曾面临为用户和各种应用分配磁盘空间的任务。多数情况下,人们无法事先准确地估计一个用户或者应用在未来究竟需要多少磁盘空间。磁盘空间被用尽的情况经常发生,此时人们不得不试图增加文件系统空间。传统的 ext2/3 无法应付这种需求。
很多卷管理软件被设计出来满足用户对多设备管理的需求,比如 LVM 。 Btrfs 集成了卷管理软件的功能,一方面简化了用户命令;另一方面提高了效率。
(1)多设备管理
Btrfs 支持动态添加设备。用户在系统中增加新的磁盘之后,可以使用 btrfs 的命令将该设备添加到文件系统中。
为了灵活利用设备空间,Btrfs 将磁盘空间划分为多个 chunk 。每个 chunk 可以使用不同的磁盘空间分配策略。
- 某些 chunk 只存放 metadata,
- 某些 chunk 只存放数据。
- 一些 chunk 可以配置为 mirror,
- 另一些 chunk 则可以配置为 stripe 。
这为用户提供了非常灵活的配置可能性。
(2)Subvolume
Subvolume 是很优雅的一个概念。即把文件系统的一部分配置为一个完整的子文件系统,称之为 subvolume 。
采用subvolume,一个大的文件系统可以被划分为多个子文件系统,这些子文件系统共享底层的设备空间,在需要磁盘空间时便从底层设备中分配,类似应用程序调用 malloc() 分配内存一样。可以称之为存储池。这种模型有很多优点,比如可以充分利用 disk 的带宽,可以简化磁盘空间的管理等。
- 所谓充分利用 disk 的带宽,指文件系统可以并行读写底层的多个 disk,这是因为每个文件系统都可以访问所有的 disk 。传统的文件系统不能共享底层的 disk 设备,无论是物理的还是逻辑的,因此无法做到并行读写。
- 所谓简化管理,是相对于 LVM 等卷管理软件而言。采用存储池模型,每个文件系统的大小都可以自动调节。而使用 LVM,如果一个文件系统的空间不够了,该文件系统并不能自动使用其他磁盘设备上的空闲空间,而必须使用 LVM 的管理命令手动调节。
Subvolume 可以作为根目录挂载到任意 mount 点。子卷是原生的copy-on-write,还有着按需分配的足够的空间,这些空间来自于下层的存储池。它们也可以拥有子卷,也可以使用快照。下图显示了4个子卷,子卷2和子卷3挂靠在其他子卷之上,子卷4显示了自己内部的目录树。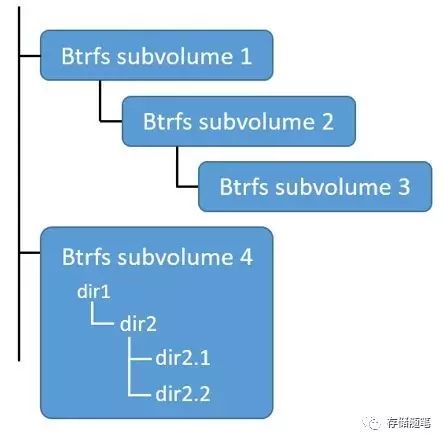
假如管理员只希望某些用户访问文件系统的一部分,比如希望用户只能访问 /var/test/ 下面的所有内容,而不能访问 /var/ 下面其他的内容。那么便可以将 /var/test 做成一个 subvolume 。 /var/test 这个 subvolume 便是一个完整的文件系统,可以用 mount 命令挂载。比如挂载到 /test 目录下,给用户访问 /test 的权限,那么用户便只能访问 /var/test 下面的内容了。
(3)快照和克隆
快照是对文件系统某一时刻的完全备份。建立快照之后,对文件系统的修改不会影响快照中的内容。这是非常有用的一种技术。
Btrfs 支持 snapshot 和 clone。这个特性极大地增加了 btrfs 的使用范围,用户不需要购买和安装昂贵并且使用复杂的卷管理软件。下面简要介绍一下 btrfs 实现快照的基本原理。
如前所述 Btrfs 采用 COW 事务技术,从下图可以看到,COW 事务结束后,如果不删除原来的节点 A,C,E,那么 A,C,E,D,F 依然完整的表示着事务开始之前的文件系统。这就是 snapshot 实现的基本原理。
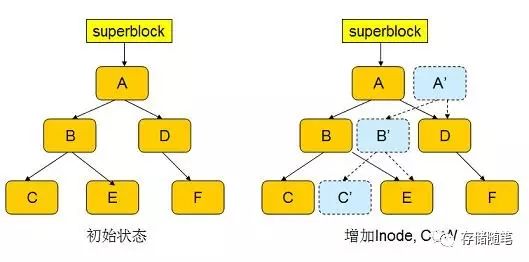
Btrfs 采用引用计数决定是否在事务 commit 之后删除原有节点。对每一个节点,btrfs 维护一个引用计数。
- 当该节点被别的节点引用时,该计数加一,
- 当该节点不再被别的节点引用时,该计数减一。
- 当引用计数归零时,该节点被删除。
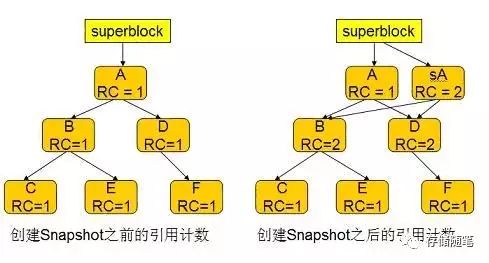
对于普通的 Tree Root, 引用计数在创建时被加一,因为 Superblock 会引用这个 Root block 。很明显,初始情况下这棵树中的所有其他节点的引用计数都为一。

当 COW 事务 commit 时,superblock 被修改指向新的 Root A'',原来 Root block A 的引用计数被减一,变为零,因此 A 节点被删除。 A 节点的删除会引发其子孙节点的引用计数也减一,上图中的 B,C,E节点的引用计数因此也变成了 0,从而被删除。 D节点在 COW 时,因为被 A''所引用,计数器加一,因此计数器这时并未归零,从而没有被删除。
创建 Snapshot 时,btrfs 将的 Root A 节点复制到 sA,并将 sA 的引用计数设置为 2 。在事务 commit 的时候,sA 节点的引用计数不会归零,从而不会被删除,因此用户可以继续通过 Root sA 访问 snapshot 中的文件。
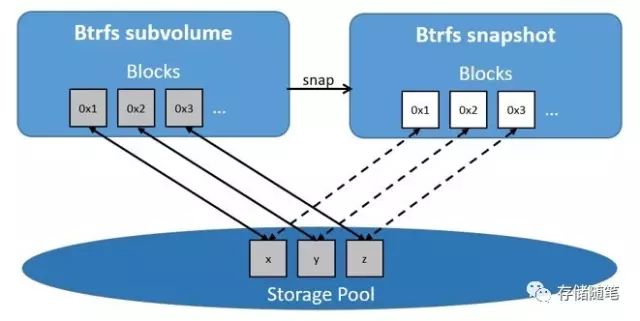
快照是Btrfs文件系统的“一等公民”,它操作时就像普通的子卷。由于Btrfs原生的copy-on-write设计,创建快照可以直接在Btrfs文件系统中构建。这意味着Btrfs快照空间利用率很高,很少或是没有性能消耗。下图显示了子卷和它快照如何分享相同数据的。
(4)软件 RAID
Btrfs 很好的支持了软件 RAID,RAID 种类包括 RAID0,RAID1 和 RAID10.
Btrfs对 metadata 进行 RAID1 保护。前面已经提及 btrfs 将设备空间划分为 chunk,一些 chunk 被配置为 metadata,即只存储 metadata 。对于这类 chunk,btrfs 将 chunk 分成两个条带,写 metadata 的时候,会同时写入两个条带内,从而实现对 metadata 的保护。
延伸:
关于RAID相关内容,我们在之前的文章中有比较详细的解释, 如果感兴趣,请翻阅之前的文章“【技术干货贴】如何实现SSD系统级的可靠性?”。
4. 其他特性
Btrfs 主页上罗列的其他特性不容易分类,这些特性都是现代文件系统中比较先进的技术,能够提高文件系统的时间或空间效率。
(1)Delay allocation
延迟分配技术能够减少磁盘碎片。在 Linux 内核中,为了提高效率,很多操作都会延迟。在文件系统中,小块空间频繁的分配和释放会造成碎片。
延迟分配是这样一种技术,当用户需要磁盘空间时,先将数据保存在内存中。并将磁盘分配需求发送给磁盘空间分配器,磁盘空间分配器并不立即分配真正的磁盘空间。只是记录下这个请求便返回。
磁盘空间分配请求可能很频繁,所以在延迟分配的一段时间内,磁盘分配器可以收到很多的分配请求,一些请求也许可以合并,一些请求在这段延迟期间甚至可能被取消。通过这样的“等待”,往往能够减少不必要的分配,也有可能将多个小的分配请求合并为一个大的请求,从而提高 IO 效率。
(2)Inline file
系统中往往存在大量的小文件,比如几百个字节或者更小。如果为其分配单独的数据 block,便会引起内部碎片,浪费磁盘空间。 btrfs 将小文件的内容保存在元数据中,不再额外分配存放文件数据的磁盘块。改善了内部碎片问题,也增加了文件的访问效率。
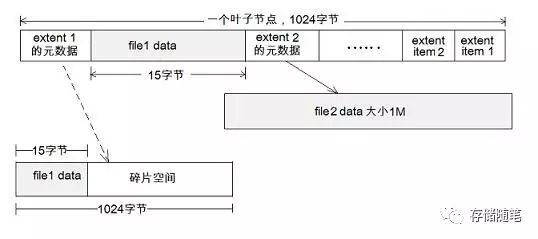
上图显示了一个 BTree 的叶子节点。叶子中有两个 extent data item 元数据,分别用来表示文件 file1 和 file2 所使用的磁盘空间。假设 file1 的大小仅为 15 个字节; file2 的大小为 1M 。
- file2 采用普通的 extent 表示方法:extent2 元数据指向一段 extent,大小为 1M,其内容便是 file2 文件的内容。
- 而对于 file1, btrfs 会把其文件内容内嵌到元数据 extent1 中。如果不采用 inline file 技术。如虚线所示,extent1 指向一个最小的 extent,即一个 block,但 file1 有 15 个字节,其余的空间便成为了碎片空间。
(3)目录索引 Directory index
当一个目录下的文件数目巨大时,目录索引可以显著提高文件搜索时间。 Btrfs 本身采用 BTree 存储目录项,所以在给定目录下搜索文件的效率是非常高的。
(4)压缩
大家都曾使用过 zip,winrar 等压缩软件,将一个大文件进行压缩可以有效节约磁盘空间。 Btrfs 内置了压缩功能。
在某些情况下,花费一定的 CPU 时间和一些内存,但却能大大节约磁盘 IO 的数量,这反而能够增加整体的效率。
比如一个文件不经过压缩的情况下需要 100 次磁盘 IO 。但花费少量 CPU 时间进行压缩后,只需要 10 次磁盘 IO 就可以将压缩后的文件写入磁盘。在这种情况下,IO 效率反而提高了。当然,这取决于压缩率。目前 btrfs 采用 zlib 提供的 DEFALTE/INFLATE 算法进行压缩和解压。在将来,btrfs 应该可以支持更多的压缩算法,满足不同用户的不同需求。
对于某些类型的文件,比如 jpeg 文件,已经无法再进行压缩。尝试对其压缩将纯粹浪费 CPU 。为此,当对某文件的若干个 block 压缩后发现压缩率不佳,btrfs 将不会再对文件的其余部分进行压缩操作。这个特性在某种程度上提高了文件系统的 IO 效率。
(5)预分配
很多应用程序有预先分配磁盘空间的需要。他们可以通过 posix_fallocate 接口告诉文件系统在磁盘上预留一部分空间,但暂时并不写入数据。如果底层文件系统不支持 fallocate,那么应用程序只有使用 write 预先写一些无用信息以便为自己预留足够的磁盘空间。
参考文献:
维基百科;


















 5571
5571

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











