









## 摘要
Meta公司在一项涉及16,384个Nvidia H100 80GB GPU的Llama 3 405B模型训练中,遭遇了频繁的硬件故障。在54天的训练期间,平均每三小时就发生一次组件故障,其中半数故障与GPU或其HBM3内存有关。尽管面临如此挑战,Meta的团队通过一系列策略,成功保持了超过90%的有效训练时间。

## 引言
大规模计算任务的复杂性使得故障几乎成为必然。Meta的Llama 3模型训练集群在持续54天的训练过程中,共记录了419次意外组件故障,凸显了在大规模计算系统中保持稳定性的挑战。
## 故障概览
### GPU和HBM3内存故障
在所有意外中断中,GPU问题占据了58.7%,其中GPU故障(包括NVLink故障)占30.1%,HBM3内存故障占17.2%。Nvidia H100 GPU的高功耗(约700W)和热应力是导致故障的主要因素。
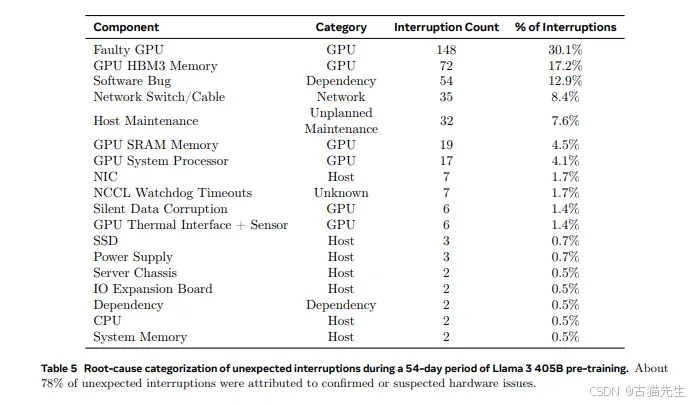
### 其他故障因素
除了GPU和内存故障外,软件缺陷、网络电缆和网络适配器问题也导致了41.3%的意外中断。
## 故障缓解策略
### 自动化与诊断工具
Meta团队通过自动化管理和开发专有诊断工具来提高效率。PyTorch的NCCL飞行记录器被广泛用于快速诊断和解决挂起和性能问题,尤其是与NCCLX相关的问题。
### 故障检测与定位
NCCLX在故障检测和定位中发挥了关键作用,特别是对于NVLink和RoCE相关问题。与PyTorch的集成允许监控并自动超时由NVLink故障引起的通信停滞。
### 环境因素影响
环境因素,如中午的温度波动,影响了训练性能,导致吞吐量变化1-2%。GPU的动态电压和频率调整受到这些温度变化的影响,尽管这并非大问题。
### 电力供应挑战
数万个GPU的同时电力消耗变化对数据中心的电网造成了压力。这些波动有时达到数十兆瓦,考验了电网的极限。
## 结论
Meta的Llama 3模型训练集群在54天内经历了419次故障,平均每三小时一次。这一数据不仅揭示了大规模计算系统的脆弱性,也展示了Meta在故障缓解和系统稳定性维护方面的专业能力。
## 建议
1. **硬件优化**:选择经过严格测试的硬件,并针对高负载环境进行优化。
2. **自动化与监控**:开发自动化工具以减少人为干预,并实施持续监控以快速响应故障。
3. **环境管理**:控制数据中心的环境条件,减少温度波动等环境因素对性能的影响。
4. **电力供应保障**:确保数据中心具备充足的电力供应,以应对大规模GPU集群的电力需求。
5. **系统冗余**:设计系统冗余,以提高容错能力,确保局部故障不会导致整个系统的崩溃。
通过这些措施,Meta展示了即使在极端的计算条件下,也能通过技术创新和策略优化,有效管理和缓解大规模计算集群的故障问题。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











