






文章目录
- 前言
- 一、编译和仿真间的关系
- 二、UVM 的各种机制和 域的自动化
- 三、SV 与 UVM 特性对应
- 1 MCDF 里 chnl_pkg 的变化
- 2 run_test作用,set_interface
- 3 TLM 通信
- 3.2 TLM端口通信缓存和mailbox的比较
- 3.3 TLM通信只能在uvm_component之间,而uvm_event不限于此
- 3.4 TLM 单通道 单向通信(两个组件间) 的应用总结(红宝书 p343)
- 3.4 TLM 双向通信(两个组件间) 的应用总结
- 3.4 TLM 多向通信(两个组件间) 的应用总结
- 3.5 带uvm_tlm_fifo(component类型)的数据传递
- 3.5 TLM 多通道(多个组件)通信的应用
- 3.6 TLM 端口总结
- 3.6 TLM的通信
- 3.7 analysis port,analysis export, analysis imp
- 3.8 uvm_tlm_fifo,uvm_tlm_analysis_fifo
- 4 回调函数应用方法
- 5 end_of_elaboration_phase() 仿真前的配置
- 6 virtual_sequence 、virtual_sequencer、test 实例
- 7 寄存器模型
- 8 uvm_evnt 和SV event 对比
- 9 sequence、sequencer、driver关系
- 四、 uvm 问题汇总
- 1. 组件各个phase方法中的super.xx_phase(phase)究竟在做什么?
- 2. virtual interface用那种方式传递适合
- 3. 如何对寄存器的某些域做读写操作?
- 4. force和$hdl_xmr_force,uvm_hdl_force等命令的区别
- 5. 为什么TLM端口的例化放在new函数里边,而mailbox的例化放在build_phase里边?
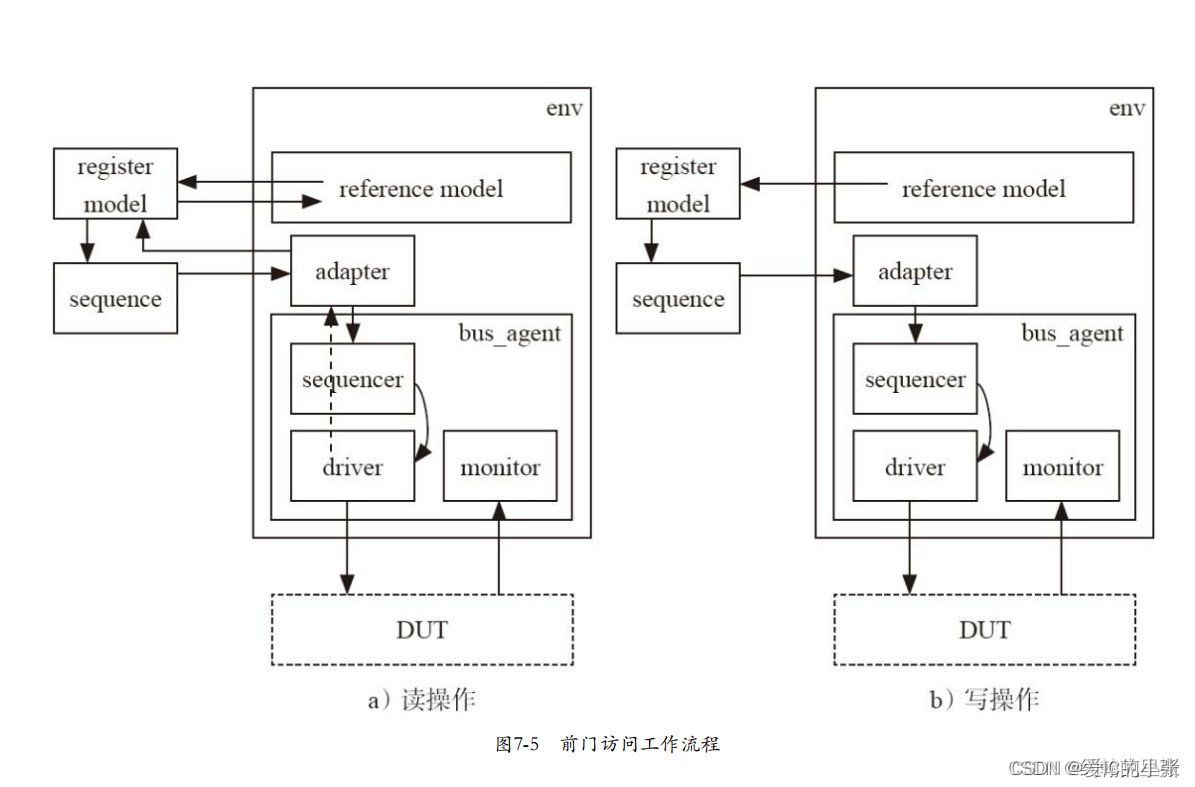
- 6. 前门访问需要通过总线实现,是不是利用前门读取寄存器的时候reg_bus_op在adapter里转换成bus_transaction ,adapter发送到sequencer了。
- 7. 将monitor把 predictor连接上的作用
- 8. DUT actual value和mirror value、desired value以及与update和mirror的方法调用关系
- 9. UVM——寄存器模型相关的一些函数
- 10. 寄存器中rand描述符作用
- 11. 寄存器模型中覆盖组采样选用的变量
- 12. m_sequencer 和 p_sequencer 的区别以及用法
- 12.0 为什么transaction不继承于uvm_transaction,而要从uvm_sequence_item派生?
- 12.1 sequence的启动方式
- 总结
前言
一文总结 UVM 的特性 和 代码示例,以及常见的问题
一、编译和仿真间的关系
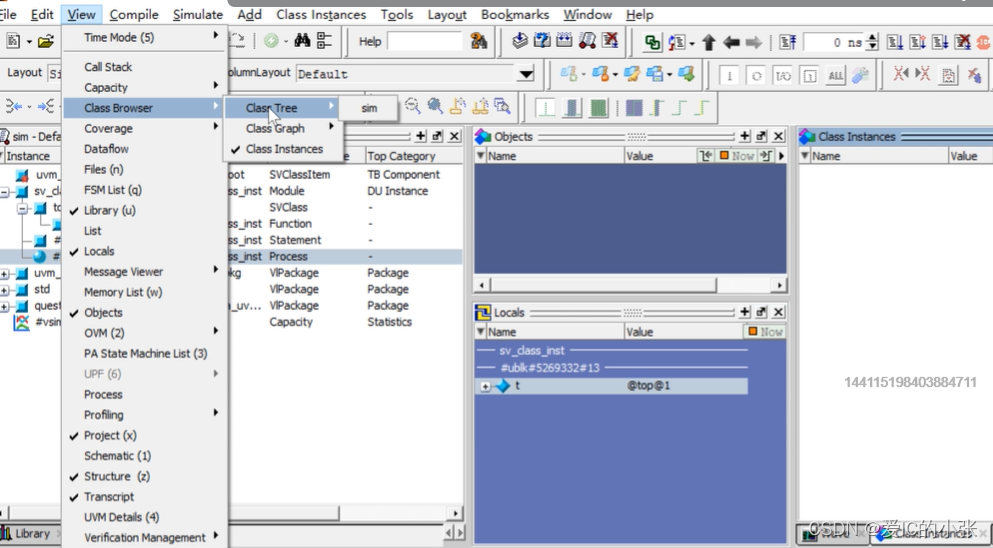
1. Questa: 如何查看class instances
- 仿真时,加入-classdebug选项,
- view -> class Brower -> class Instances(常用) 、tree、graph
- 点击 top,在右侧窗口 显示 实例例化多少次
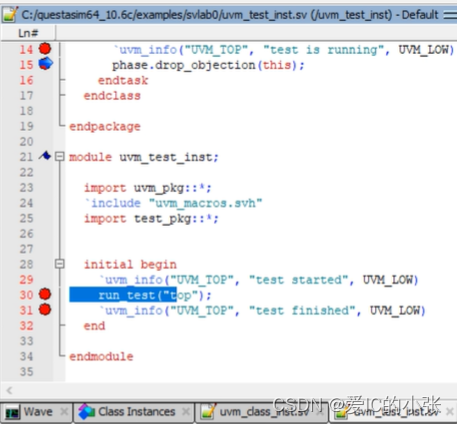
2. UVM 验证的 必要步骤
9个 phase 执行完毕,然后run_test执行完,仿真立即退出,则第31行不会执行。会给出uvm report summary报告。
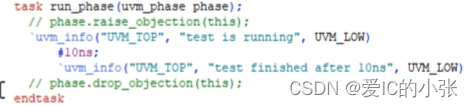
没有phase.raise_objection(this);则#10ns不会执行,一定记得raise_objection!
3. UVM和SV 验证顶层盒子
UVM 顶层:uvm_root -> uvm_test_top;
SV的顶层:test
二、UVM 的各种机制和 域的自动化
1 工厂的注册 和 创建对象
`uvm_object_utils(T)
`uvm_component_utils(T)
UVM 创建对象 的四种方法:
SV只有一种创建例化的方法
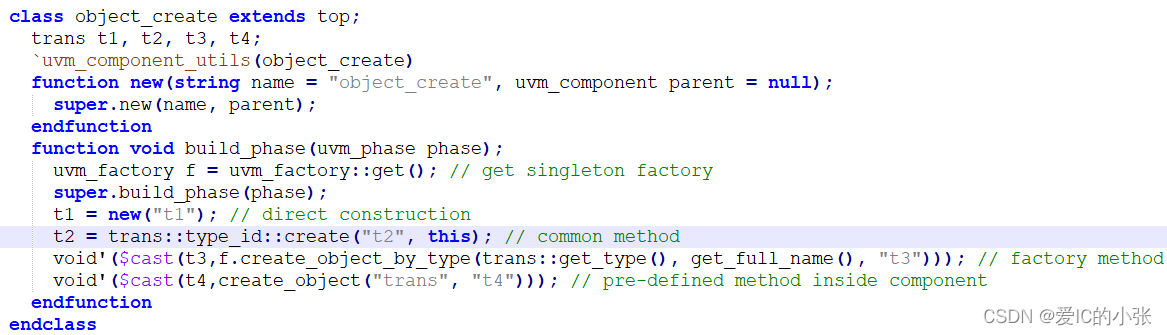
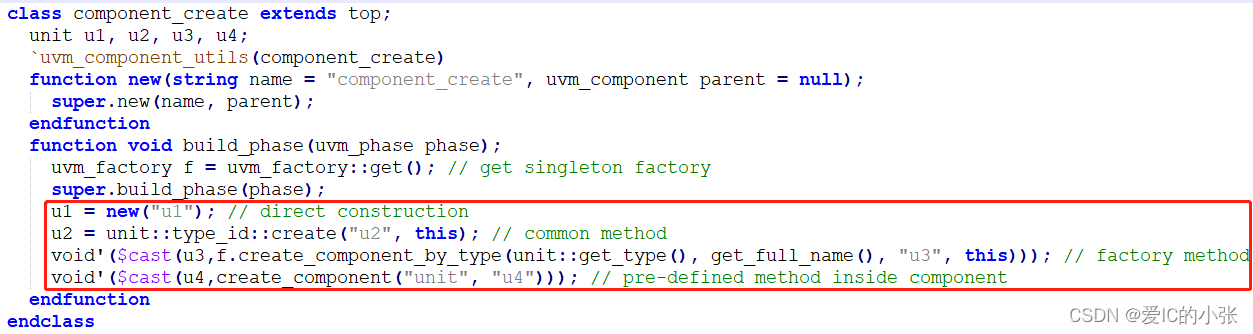
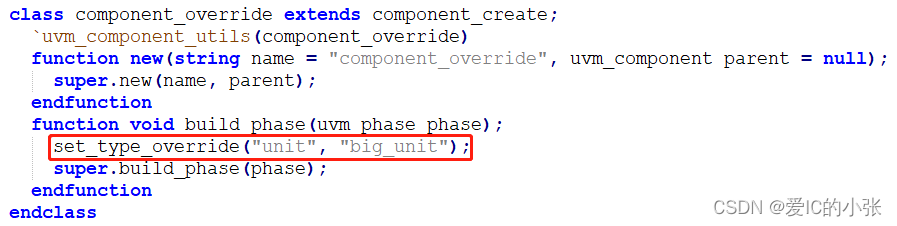
2 UVM override 替换
在 t1是用new创建的,t2、t3、t4是factory创建的,所以利用set_type_override_by_type(original_type, override_type)方法时,t2\t3\t4都会被替换类型,但是t1不会,此外该函数要在build_phase之前运行,才可以替换类型。
例化: 通过 factory create,一定要放在build_phase,不放在new函数里,原因是:uvm在看到build_phase 阶段的factory的create实例,会先检查是否该类型override过,override后再创建替换后的类型。

set_type_override(string original_type_name,
string override_type_name,
bit replace=1) 缺省值是1, 该方法与上述方法效果相同
3 域的自动化
域的自动化: 定义了各自域对应得变量,之后可以直接调用compare、clone、copy、print等函数;
compare函数 使用时,如果比较失败,则会停止仿真,所以需要调用 uvm_default_comparer.show_max = 10 设置为一个数值。
do_compare(详细比较两个数据),是compare的回调函数,在调用compare时,可以自动调用do_compare函数。如果自定义比较函数,注意函数名区别如do_data_compare

4 Phase 机制
4.1 SV和UVM run点火的不同:
phase机制中,验证环境建立各个组件的层次,这些层次的句柄都在一个类里拿到,并行点火各个组件里边的run_phase或者其他phase;
然而 SV点火是从顶层test向各个agent点火,agent向各个组件点火,组件再向定义的方法点火,逐层点火运行。
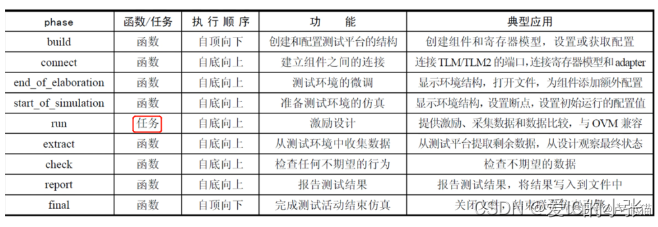
- 一般组件的 例化和创建 都发生在build_phase里
- UVM_root 下边的 uvm_test 一定是整个验证环境的顶层。
- 作为唯一task 的 run_phase 有12个小的phase,最好不要有run_phase 和里边的小phase同时出现。
- build_phase 是自顶向下的,connect_phase 是自底向上的。
- 对于uvm_top或者uvm_test_top尽可能少使用
set_drain_time(uvm_object obj=null, time drain) - 结束仿真的机制有且只有一个,就是利用objection挂起机制来控制仿真结束
- 首先在加载硬件模型调用仿真器之前,需要完成编译和建模阶段
(1)phase 开始仿真之前,分别执行硬件的always/initial语句,以及UVM的调用测试方法run_test和几个phase,分别 build_phase,connect_phase,end_of_elaboration_phase,start_of_simulation_phase;
(2)phase 在仿真开始后,执行run_phase或对应的12个细分的phase;
(3)phase 在仿真结束后,执行剩余的phase,分别是extract_phase,check_phase,report_phase,final_phase
5 config机制
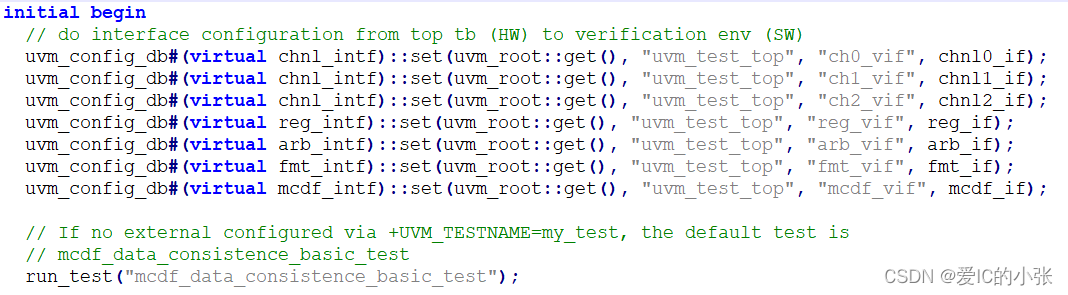
通过uvm_config_db完成了各个接口从TB(硬件一侧)到验证环境mcdf_env(软件一侧)的传递。 传递的方式有赖于config_db的数据存储和层次传递特性。uvm_config_db set 和 get 方法,从而使得mcdf_env与其各个子组件之间也实现“层次剥离”。
5.1 config机制的作用
- 在创建底层组件之前,需要对验证环境进行配置, 为了验证环境的复用性,通过外部的参数配置,使得环境在创建时可以根据不同参数来选择创建的组件类型
- 与重新编译来调节变量比,UVM config机制可以在仿真中通过变量设置来修改环境
5.2 为什么config object层次与验证层次一致?
一般每个agent中都有一个config;
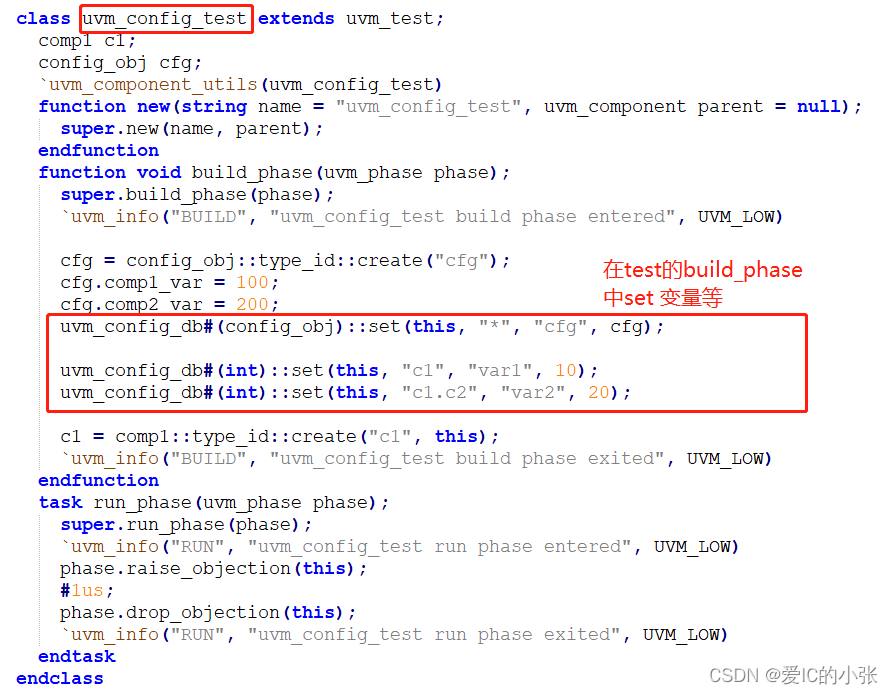
- 作用: 接口传递、单一变量传递(先配置后例化)、对象句柄传递(先例化对象后配置,否则编译通过,但仿真会报错)
虚拟接口传递: 虚拟接口提供了一个访问真实虚接口的入口,我们会把虚拟接口的句柄放到全局的数据库中,uvm中的这些组件会通过get函数拿到虚拟接口的句柄对接口数据进行操作。
配置数据: 负责配置环境的类中包含许多可以控制验证环境的变量,它会改变这些变量,并且通过set函数把它放到我们全局的数据库中,其他的组件通过get函数来取到这些变量的值,再根据这些值去改变工作模式。
sequencers: 在uvm中sequencers负责把我们写的sequence进行排队送到driver上去, 所以sequence需要有对sequencer的访问入口,我们同样通过uvm_config_db的方式来把sequencer的句柄传给sequence。 - 把 变量 封装在config_object
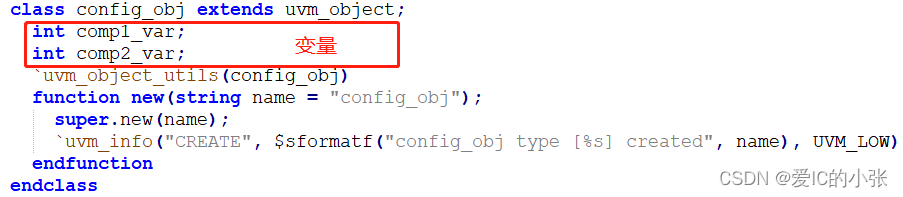
- 在组件当中从config中get 变量、接口、对象句柄
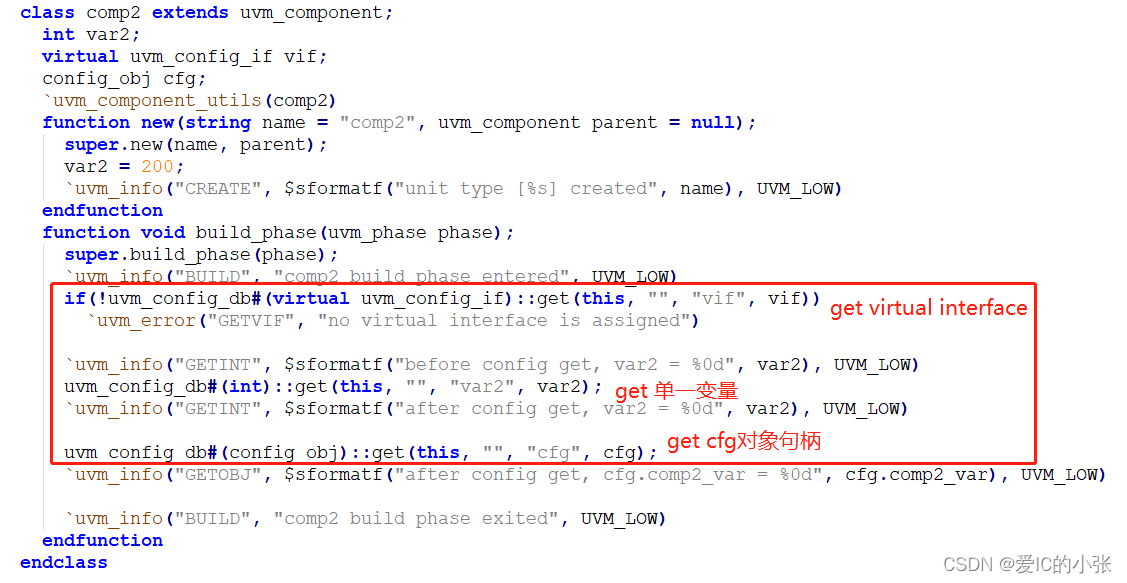
- 在test 的build_phase中set变量 和 config对象句柄
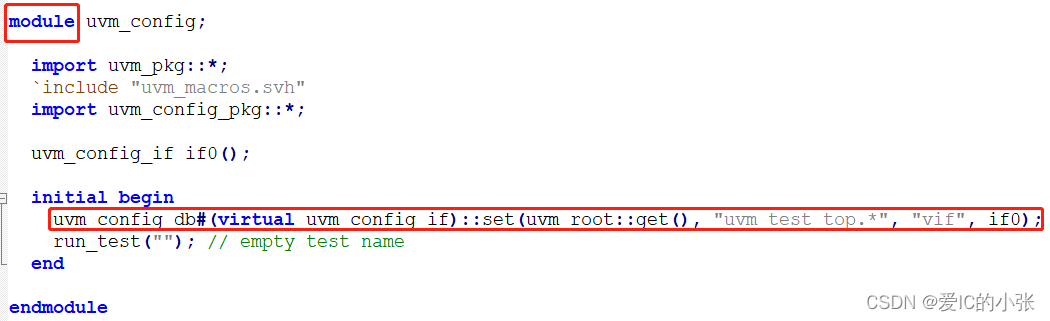
- set interface config at module tb 顶层模块
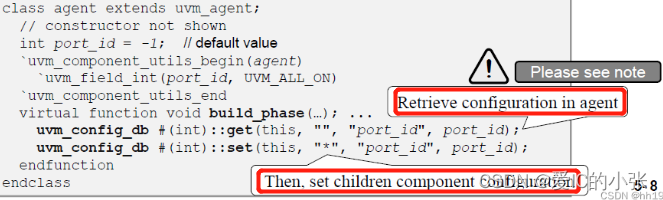
5.3.0 set函数与get函数的参数 总结
两个函数set和get是使用它时要调用的函数,
set表示把要处理的资源放进全局可见的数据库,
get表示从全局可见的数据库输出需要的资源,
如果发信了但是没有收信的,将不会报错;反之,会报错。
uvm_config_db#(T)::set(uvm_component cntxt, string inst_name, string field_name, T value);
uvm_config_db#(T)::get(uvm_component cntxt, string inst_name, string field_name, inout T value);
-
T是传递信息的类型
-
cntxt是一个uvm_component实例的指针,cntxt+inst_name组成目标路径
-
inst_name是相对此实例的路径;对于 :: get 来说,第⼆个参数是相对于此实例的路径,如果第⼀个设置为 this,且传递的变量就在本component层级中,则第⼆个可以是空的字符串。
-
field_name变量名set和get的第三个参数必须一致
-
需要注意的是,当制定第二个参数是一个uvm组件时,uvm会用它的全局名字取替换它,而全局名字会通过uvm的get_full_name来获取。 比如 seq.sv : uvm_config_db#(int)::get(null,get_full_name(),“A”,a); ,* 一个是一般来说seq的层次等级比较高,所以不管在哪里设置的set参数,最好第一个发信地址都写成null。第二个是,虽然在seq中可以获得full name,但seq不存在于整个层次结构,所以不能写成this,必须得写成上述形式。
-
在top_tb中通过config_db机制的set函数设置virtual interface时,set函数的第一个函数为null。在这种情况下,UVM会自动把第一个单数替换为uvm_root::get(),即uvm_top。 换句话说,以下两种写法完全等价:
uvm_config_db#(virtual my_if)::set(null, "uvm_test_top.env.i_agt.drv", "vif", input_vif);
在top_tb中设置virtual interface时,由于top_tb不是一个类,无法使用this指针,所以设置set的第一个参数为null,第二个参数使用绝对路径uvm_test_top.xxx。
uvm_config_db#(virtual my_if)::set(uvm_root::get(), "uvm_test_top.env.i_agt.drv", "vif", input_vif);
- 这里的关键是build_phase中的super.build_phase语句,当执行到driver 的super.build_phase时,会自动执行get语句。
这种做法的前提是:
第一,my_driver必须使用uvm_component_utils宏注册;
第二,pre_num必须使用uvm_field_int宏注册;
第三,在调用set函数的时候,set函数的第三个参数必须与要get函数中变量的名字相一致:
uvm_config_db#(int)::get(this, "", "pre_num", pre_num);
- uvm_config_db中 " " 和 " * " 的区别
-
非直线的设置和获取
在UVM树中,driver的路径为uvm_test_top.env.i_agt.drv。在uvm_test_top,env或者i_agt中,对driver中的某些变量通过config_db机制进行设置,称为直线的设置。但是若在其他component,如scoreboard中,对driver的某些变量使用config_db机制进行设置,则称为非直线的设置。
在UVM树中,build_phase是自上而下执行的,但是对于UVM树来说,scb与i_agt处于同一级别中,UVM并没有明文指出同一级别的build_phase的执行顺序。所以当my_driver在获取参数值时,my scoreboard的build phase可能已经执行了,也可能没有执行。应该避免非直线的设置这种情况的出现。 -
check_config_usege
config_db机制功能非常强大,能够在不同层次对同一参数实现配置。但它的一个致命缺点是,其set函数的第二个参数是字符串,如果字符串写错,那么根本就不能正确地设置参数值。假设要对driver的pre_num进行设置,但是在写第二个参数时,错把iagt写成了iatg。但是也还是一个字符串,SystemVerilog的仿真器也不会给出任何参数错误针对这种情况,UVM提供了一个函数check_config_usage,它可以显示出截止到此函数调用时有哪些参数是被设置过但是却没有被获取过。 由于config_db的set及get语句一般都用于build_phase阶段,所以此函数一般在connect_phase被调用
virtual function void connect_phase(uvm_phase phase);
super.connect_phase(phase);
check_config_usage();
endfunction
————————————————
版权声明:本文为CSDN博主「数字ic攻城狮」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_40051553/article/details/121324004
5.3.1 跨层次的多重设置
假如uvm_test_top和env中都对driver的pre_num的值进行了设置,
- 在set函数的第一个参数为this时:
在uvm_test_top中的设置语句如下:
文件:src/ch3/section3.5/3.5.4/normal/my_case0.sv
32 function void my_case0::build_phase(uvm_phase phase);
33 super.build_phase(phase);
…
39 uvm_config_db#(int)::set(this,
40 "env.i_agt.drv",
41 "pre_num",
42 999);
43 `uvm_info("my_case0", "in my_case0, env.i_agt.drv.pre_num is set to 999",UVM_LOW)
在env的设置语句如下:
文件:src/ch3/section3.5/3.5.4/normal/my_env.sv
19 virtual function void build_phase(uvm_phase phase);
20 super.build_phase(phase);
…
31 uvm_config_db#(int)::set(this,
32 "i_agt.drv",
33 "pre_num",
34 100);
35 `uvm_info("my_env", "in my_env, env.i_agt.drv.pre_num is set to 100",UVM_LOW)
36 endfunction
那么driver中获取到的值是100还是999呢?答案是999。 UVM规定层次越高,那么它的优先级越高。这里的层次指的是在UVM树中的位置,越靠近根结点uvm_top,则认为其层次越高。uvm_test_top的层次是高于env的,所以uvm_test_top中的set函数的优先级高。
2. 假如set函数的第一个参数不是this会如何呢?
假设uvm_test_top的set语句是:
文件:src/ch3/section3.5/3.5.4/abnormal/my_case0.sv
32 function void my_case0::build_phase(uvm_phase phase);
33 super.build_phase(phase);
…
39 uvm_config_db#(int)::set(uvm_root::get(),
40 “uvm_test_top.env.i_agt.drv”,
41 “pre_num”,
42 999);
43 `uvm_info(“my_case0”, “in my_case0, env.i_agt.drv.pre_num is set to 999”, UVM_LOW)
而env的set语句是:
文件:src/ch3/section3.5/3.5.4/normal/my_env.sv
19 virtual function void build_phase(uvm_phase phase);
20 super.build_phase(phase);
…
31 uvm_config_db#(int)::set(uvm_root::get(),
32 “uvm_test_top.env.i_agt.drv”,
33 “pre_num”,
34 100);
35 `uvm_info(“my_env”, “in my_env, env.i_agt.drv.pre_num is set to 100”,UVM_LOW)
36 endfunction
这种情况下,driver得到的pre_num的值是100。 由于set函数的第一个参数是uvm_root::get(),所以寄信人变成了uvm_top。在这种情况下,只能比较寄信的时间。UVM的build_phase是自上而下执行的,my_case0的build_phase先于my_env的build_phase执行。所以my_env对pre_num的设置在后,其设置成为最终的设置。假如uvm_test_top中set函数的第一个参数是this,而env中set函数的第一个参数是uvm_root::get(),那么driver得到的pre_num的值也是100。这是因为env中set函数的寄信人变成了uvm_top,在UVM树中具有最高的优先级。
因此,无论如何,在调用set函数时其第一个参数应该尽量使用this。在无法得到this指针的情况下(如在top_tb中),使用null或者uvm_root::get()。
5.3.2 同一层次的多重设置
当跨层次来看待问题时,是高层次的set设置优先;当处于同一层次时,上节已经提过,是时间优先。
classs base_test extends uvm_test;
function void build_phase(uvm_phase phase);
super.build_phase(phase);
uvm_config_db#(int)::set(this, "env.i_agt.drv", pre_num_max, 7);
endfunction
endclass
class case1 extends base_test;
function void build_phase(uvm_phase phase);
super.build_phase(phase);
endfunction
endclass
…
class case99 extends base_test;
function void build_phase(uvm_phase phase);
super.build_phase(phase);
endfunction
endclass
但是对于第100个测试用例,则依然需要这么写:
class case100 extends base_test;
function void build_phase(uvm_phase phase);
super.build_phase(phase);
uvm_config_db#(int)::set(this, "env.i_agt.drv", pre_num_max, 100);
endfunction
endclass
case100的build_phase相当于如下所示连续设置了两次
uvm_config_db#(int)::set(this, "env.i_agt.drv", "pre_num", 7);
uvm_config_db#(int)::set(this, "env.i_agt.drv", "pre_num", 100);
按照时间优先的原则,后面config_db::set的值将最终被driver得到100
5.3 config_db应用在sequence中的示例
在sequence中get参数:
class case0_sequence extends uvm_sequence#(my_transaction);
...
my_case0.sv
virtual task pre_body();
if(uvm_config_db#(int)::get(null, get_full_name(), "count", count)
`uvm_info("seq0", $sformatf("get count value %0d via config_db", count), UVM_MEDIUM)
else
`uvm_error("seq0", "cannot get count value!")
endtask
...
endclass
在sequence中set参数:
class drv0_seq extends uvm_sequnece #(my_transaction);
...
virtual task body();
void'(uvm_config_db#(bit)::get(uvm_root::get(), get_full_name(), "first_start", first_start));
if(first_start)
`uvm_info("drv0_seq", "this is the first start of the sequence", UVM_MEDIUM)
else
`uvm_info("drv0_seq", "this is not the first start of the sequence", UVM_MEDIUM)
uvm_config_db#(bit)::set(uvm_root::get(), "uvm_test_top.v_sqr.*", "first_start", 0);
由于此sequence在virtual sequence中被启动,所以其get_full_name的结果应该是
uvm_test_top.v_seq.,而不是uvm_test_top.env0.i_agt.sqr.,所以在设置时,第
二个参数应该是前者。
endtask...
endclass
**在test中set参数给 sqr: **
function void my_case0::build_phase(uvm_phase phase);
...
uvm_config_db#(int)::set(this, "env.i_agt.sqr.*", "count", 9);
...
endfunction
5.4 config机制需要注意的
- uvm_config_db::set通过层次和变量名,将这些信息放置到uvm_pkg唯一的全局变量uvm_pkg::uvm_resources。
- 全局变量uvm_resources用来存储和释放配置资源信息(resource
information)。uvm_resources是uvm_resource_pool类的全局唯一实例,该实例中有两个resource数组用来存放配置信息,这两个数组中一个由层次名字索引,一个由类型索引,通过这两个关联数组可以存放任意个通过层次配置的信息。同时,底层的组件也可以通过层次或者类型来取得高层的配置信息。这种方式也完成了信息配置与信息获取的剥离,便于调试和复用。 - 在使用uvm_config_db::get方法时,通过传递的参数构成索引的层次,然后在uvm_resource已有的配置信息池中索引该配置,如果索引到,方法返回1,否则为0。
- 在使用set/get方法时,传递的参数类型应当上下保持一致。对于uvm_object等实例的传递,如果get类型与set类型不一致,应当首先通过$cast()完成类型转换,再对类型转换后的对象进行操作。
- set/get方法传递的参数可以使用通配符“”来表示任意的层次,类似于正则表达式的用法。同时,用户需要懂得“.comp1”与“*comp1”的区别,前者表示在目前层次之下所有名字为“comp1”的组件,而后者表示包括当前层次及当前层次以下的所有名为“comp1”的组件。
- 在module环境中如果要使用uvm_config_db::set,则传递的第一个参数uvm_component
cntxt用来表示当前的层次,由于当前层次为最高层,所以用户可以设置为null,也可以设置为uvm_root::get()来表示uvm_root的全局实例。 - 在使用被配置变量时,应当确保先进行了uvm_config_db::get的操作,获得了正确的值以后再使用。
- 应当尽量确保uvm_config_db::set方法在其相关配置组件创建前调用。这是因为只有先进行了配置,其相关组件在例化时进入build_phase,可以得到期望的值。
- 对于同一实例组件的同一个变量,如果有多个上层组件对该变量进行设置时,更上层组件的配置会覆盖低层的配置;但是如果是同一个层次组件对该变量进行多次配置时,应该遵循后面的配置会覆盖前面的配置。
- 用户应该在使用uvm_config_db::get()方法时,添加便于调试的语句,来通过UVM信息打印得知get方法的变量是否从uvm_config_db获取,如果没有获取,是否需要采取其它的措施。
5.5 虽然uvm_resource_db也可以实现配置数据的读写, 建议用户使用uvm_config_db,而不使用uvm_resouce_db
虽然uvm_resource_db也可以实现配置数据的读写,但是我们更建议用户保持使用uvm_config_db的习惯。这是因为层次化的配置关系以及覆盖原则,符合验证环境复用的原则,即顶层集成时有更高的权利来覆盖底层组件的配置。 之所以我们只建议用户使用uvm_config_db,而不使用uvm_resouce_db,是基于下面的几个原因:
- uvm_resource_db采取的是“last write wins”即对同一个配置,最后的写入有效;而uvm_config_db采取的是“parent wins”,它会首先按照层次采取最顶层的配置优先。
- uvm_resource_db给人带来的困惑是,如果高层次和低层次都对同一个配置变量进行了写入,那么在build阶段,由于是采取top-down的执行顺序,低层次的配置写入发生在最后,反而会作为有效值写入。因此uvm_resouce_db无法实现层次化的覆盖,这就不利于集成和复用。
- 另外uvm_resource_db只需要scope字符串参数,同时上下文的set/read中的scope必须保持一致。对于较简单和透明的环境,这一要求并不难,但是对于复杂的和封装完善的环境,这就对用户提出了更高的要求。因为用户需要对底层环境的验证IP了解更多,得知它们采用的scope参数,才能在顶层做出正确的参数匹配才可以完成配置
5.6 uvm_resource_db 的用法
uvm_resource_db虽然也是一种用来共享数据的类, 但是层次关系在其类中没有作用。 与uvm_config_db相比,尽管uvm_resource_db也有内建的数据库通过字符串或者类型来索引配置数据,但是一个缺点就是层次的缺失和因此带来的自顶向下的配置覆盖关系的缺失。uvm_resource_db的一些常用的API静态方法包括有:
- function void set(input string scope, input string name, T val, input uvm_object accessor = null);
- function rsrc_t get_by_name(string scope, string name, bit rpterr=1);
- function rsrc_t get_by_type(string scope);
- function bit read_by_name(input string scope, input string name,
inout T val, input uvm_object accessor = null); - function bit read_by_type(input string scope, inout T val, input
uvm_object accessor = null); - function bit write_by_name(input string scope, input string name,
input T val, input uvm_object accessor = null); - function bit write_by_type(input string scope, input T val, input
uvm_object accessor = null);
代码示例,uvm_resource_db也可以实现配置的读写。
module config_resource_db;
import uvm_pkg::*;
`include "uvm_macros.svh"
class comp1 extends uvm_component;
`uvm_component_utils(comp1)
int val1 = 1;
string str1 = "null";
function new(string name, uvm_component parent);
super.new(name, parent);
endfunction
function void build_phase(uvm_phase phase);
`uvm_info("SETVAL", $sformatf("val1 is %d before get", val1), UVM_LOW)
`uvm_info("SETVAL", $sformatf("str1 is %s before get", str1), UVM_LOW)
uvm_resource_db#(int)::read_by_name("cfg", "val1", val1);
uvm_resource_db#(string)::read_by_name("cfg", "str1", str1);
`uvm_info("SETVAL", $sformatf("val1 is %d after get", val1), UVM_LOW)
`uvm_info("SETVAL", $sformatf("str1 is %s after get", str1), UVM_LOW)
endfunction
endclass
class test1 extends uvm_test;
`uvm_component_utils(test1)
comp1 c1;
function new(string name, uvm_component parent);
super.new(name, parent);
endfunction
function void build_phase(uvm_phase phase);
uvm_resource_db#(int)::set("cfg", "val1", 100);
uvm_resource_db#(string)::set("cfg", "str1", "comp1");
c1 = comp1::type_id::create("c1", this);
endfunction
endclass
initial begin
run_test("test1");
end
endmodule
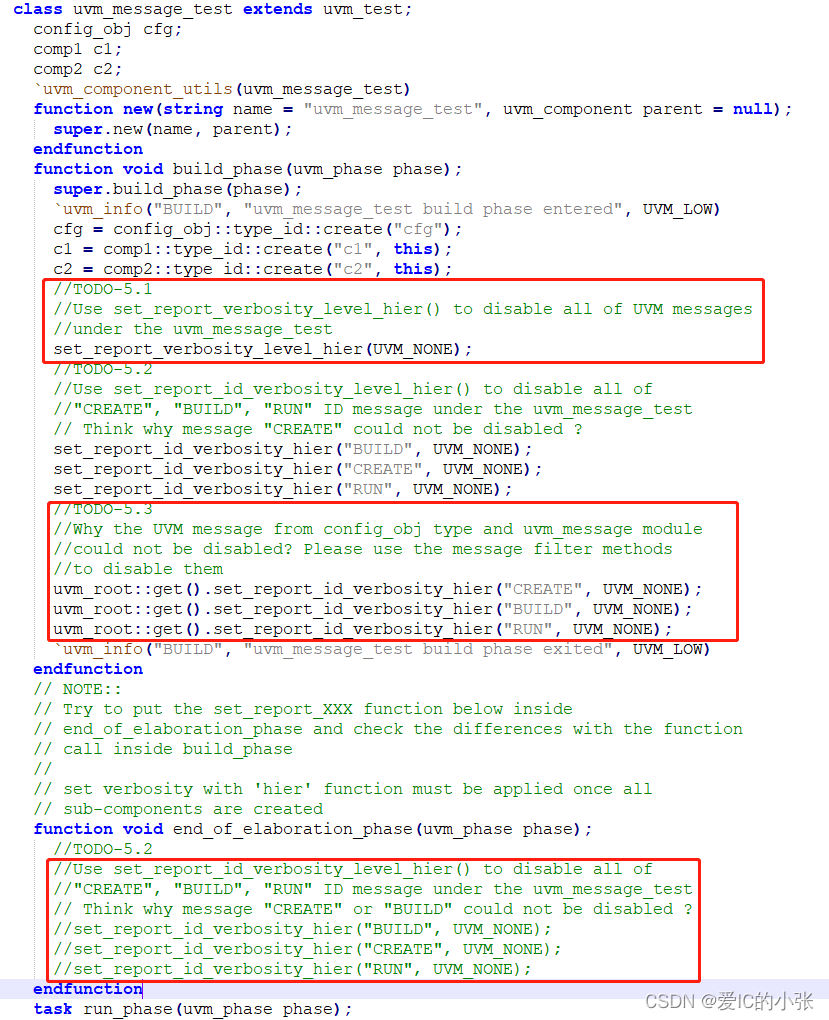
6 reprot机制
消息的过滤:
7 SV & UVM 覆盖率
本文主要介绍,利用system verilog编写功能覆盖率的基本语法。主要内容包括:覆盖组covergroup的定义、覆盖点coverpoints的定义、交叉覆盖率cross的定义、覆盖率选项、覆盖率系统任务和函数。
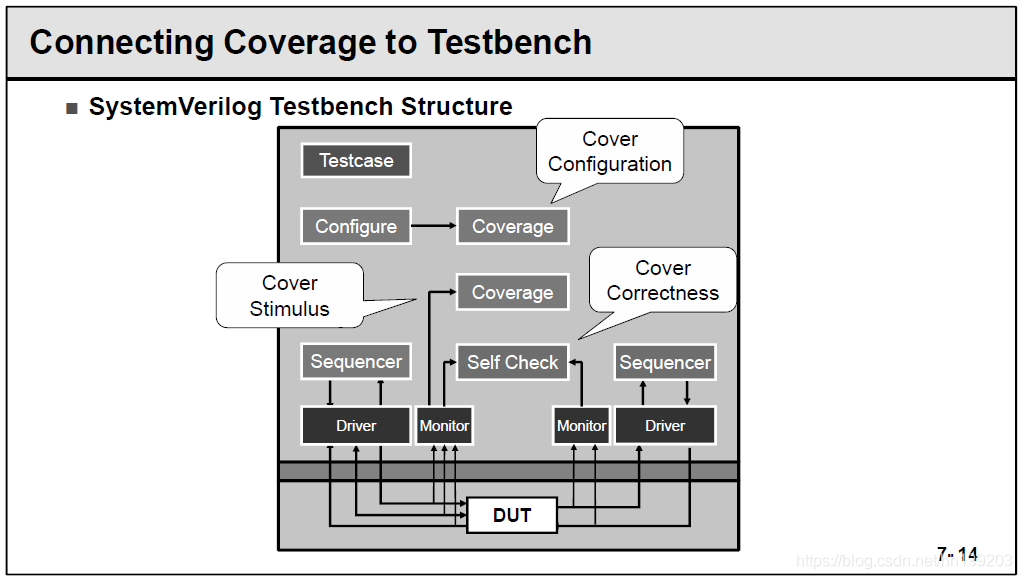
7.1 功能覆盖率的分类
在UVM中,功能覆盖率分为:Configuration、Stimulus、Correctness这三类。分别统计配置、仿真、正确性三大类的功能覆盖率。
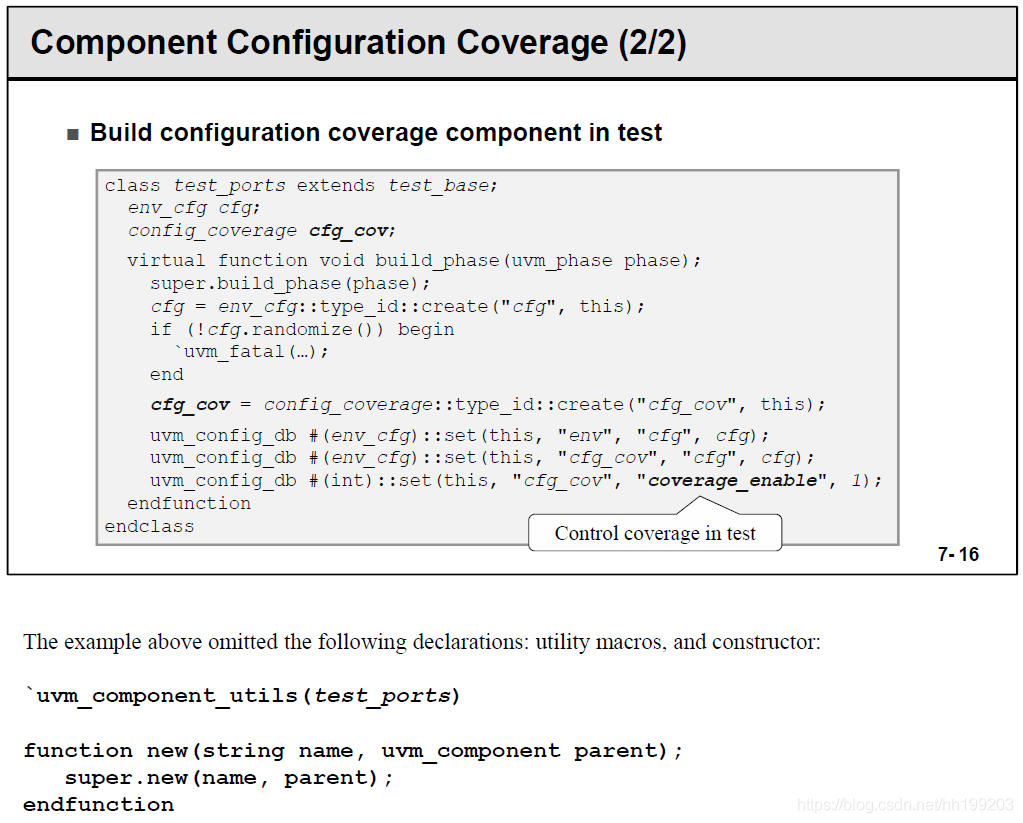
- Configuration Coverage
先编写功能覆盖率组cfg_cg,将env_cfg作为参数传进去;再编写一个独立的组件config_coverage,实现覆盖率的采样。


在testbench中声明并实例化config_coverage,再通过coverage_enable这个参数来控制是否开启Configuration覆盖率统计。
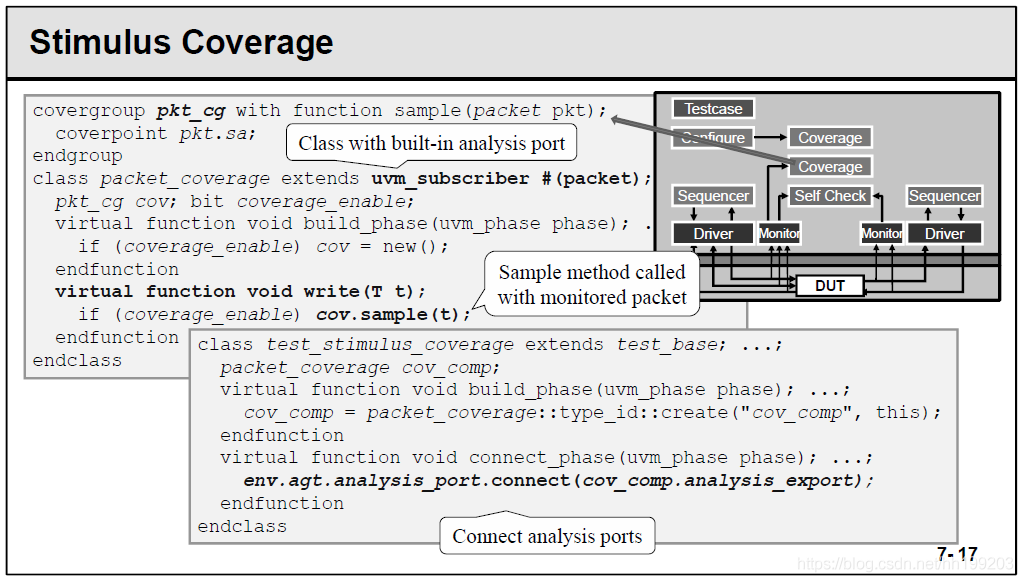
- Stimulus Coverage
先编写功能覆盖率组pkt_cg,将packet作为参数传进去;
再编写一个独立的组件packet_coverage,实现覆盖率的采样;
最后在测试用例中,声明并实例化packet_coverage,在connect_phase中将agent里边monitor收集的数据包,通过TLM连接到packet_coverage中去采样。
- Correctness Coverage
先编写功能覆盖率组sb_pkt_cg,将packet作为参数传进去;
再在scoreboard中比对通过的数据包,送入sb_pkt_cg中去采样。
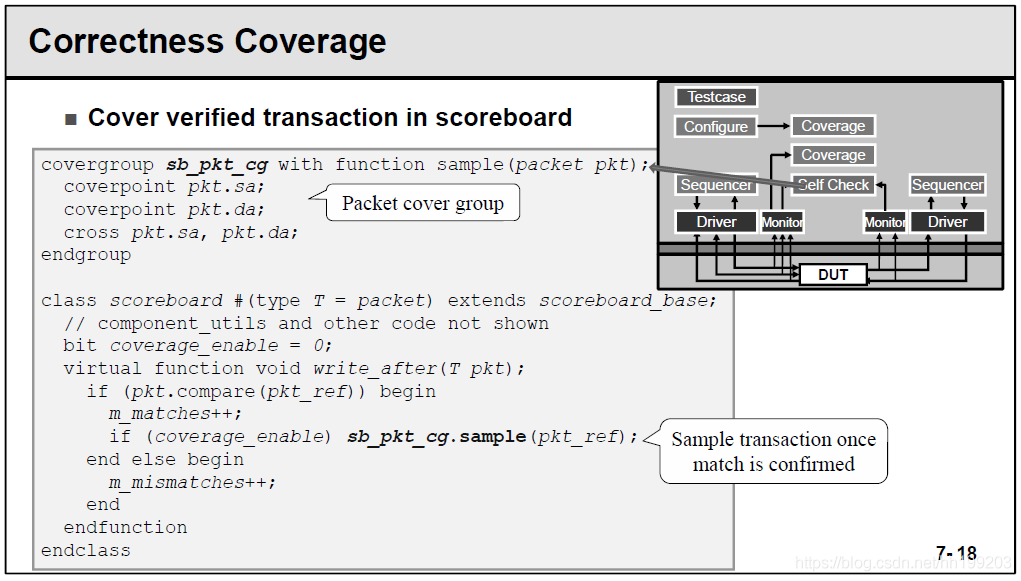
7.2 覆盖组covergroup
covergroup类型构造是用户定义的。类型定义编写一次,可以在不同的上下文中创建该类型的多个实例。与类类似,一旦定义,covergroup实例就可以通过new()操作符创建。
covergroup cg; ... endgroup
cg cg_inst = new();
output或者inout不能作为covergroup的参数。由于covergroup不能修改new操作符的任何实参,因此ref实参将被视为只读的const ref实参。不能使用层次名称访问covergroup的形参(不能在covergroup声明之外访问形参)。
- 如果指定了一个时钟事件,它将在定义的事件上对覆盖点进行采样。因为它在covergroup的范围内,时钟事件可以基于covergroup的ref参数。
- 如果没有指定时钟事件,用户必须通过内置的sample()方法,手动的触发覆盖率采样。预定义的sample()方法不接受参数,但是用户可以通过指定一个带有参数列表的采样方法,作为触发函数来覆盖原有的采样函数。
一个覆盖组可以包含一个或多个覆盖点。覆盖点可以覆盖变量或表达式。
enum { red, green, blue } color;
covergroup g1 @(posedge clk);
c: coverpoint color;
endgroup
上面的例子定义了覆盖组g1,它有一个与变量color相关联的单一覆盖点
变量color的值在指定的时钟事件采样:信号clk的正边缘。因为覆盖点没有显式定义任何仓(bins),所以工具自动创建三个仓,每个仓对应枚举类型的可能值。
7.3 覆盖点coverpoints
- iff关键字
iff构造中的表达式指定了一个可选的条件,该条件禁用该覆盖点的覆盖。如果保护表达式在采样点计算为false,则忽略覆盖点。
covergroup g4;
coverpoint s0 iff(!reset);
endgroup
- default关键字
default关键字,定义了一个不与任何已定义值仓相关联的仓。默认仓捕获覆盖点的值,不属于任何已定义的仓。default对于捕获未计划的或无效的值非常有用。 - bins关键字
bins fixed [4] = { [1:10], 1, 4, 7 }; //13个值被分为四个仓,分别为:<1,2,3>,<4,5,6>,<7,8,9>,<10,1,4,7>。如果仓的数量超过值的数量,那么一些仓将是空的。
bit [9:0] v_a;
covergroup cg @(posedge clk);
coverpoint v_a
{
bins a = { [0:63],65 };
bins b[] = { [127:150],[148:191] }; // 由65个bins组成的集合b[127], b[128],…b[191]。
bins c[] = { 200,201,202 };
bins d = { [1000:$] }; //取值范围为1000到1023($表示变量v_a的上限)。
bins others[] = default;
}
endgroup
- 带参数的bins
covergroup cg (ref int ra, input int low, int high ) @(posedge clk);
coverpoint ra // sample variable passed by reference
{
bins good = { [low : high] };
bins bad[] = default;
}
endgroup
...
int va, vb;
cg c1 = new( va, 0, 50 ); // cover variable va in the range 0 to 50
cg c2 = new( vb, 120, 600 ); // cover variable vb in the range 120 to 600
采样的信号和覆盖范围被指定为参数。稍后 创建coverage组的两个实例,每个实例采样一个不同的信号并覆盖不同范围的值。
- with关键字
with关键字指定covergroup_range_list中,包含在bin中,并满足给定表达式的值。
a: coverpoint x
{
bins mod3[] = {[0:255]} with (item % 3 == 0);
这个bin定义选择从0到255中能被3整除的所有值。
}
- wildcard关键字
wildcard关键字修饰的bin,定义所有的X、Z或?,被视为0或1的通配符。
wildcard bins g12_15 = { 4'b11?? };
当采样变量在12到15之间时,bin g12_15的计数增加:
1100 1101 1110 1111
- ignore_bins关键字
将与覆盖点相关的一组值或表达式,指定为ignore_bins,可以显式地从覆盖中排除。
covergroup cg23;
coverpoint a
{
ignore_bins ignore_vals = {7,8};
ignore_bins ignore_trans = (1=>3=>5);
}
endgroup
- illegal_bins关键字
covergroup cg3;
coverpoint b
{
illegal_bins bad_vals = {1,2,3};
illegal_bins bad_trans = (4=>5=>6);
}
endgroup
如果出现非法值或表达式,仿真将运行时报错。
非法仓优先于任何其他仓,也就是说,即使它们包含在另一个合法仓中,也会导致运行时报错。
非法的仓不能指定一个无边界或未确定可变长度的序列
- 一些异常情况的举例分析
bit [2:0] p1; // type expresses values in the range 0 to 7
bit signed [2:0] p2; // type expresses values in the range –4 to 3
covergroup g1 @(posedge clk);
coverpoint p1 {
bins b1 = { 1, [2:5], [6:10] };
bins b2 = { -1, [1:10], 15 };
}
coverpoint p2 {
bins b3 = {1, [2:5], [6:10] };
bins b4 = { -1, [1:10], 15 };
}
endgroup
——对于b1,对范围[6:10]发出警告。b1被视为{1, [2:5], [6:7]}
——对于b2,对范围[1:10]和值-1和15发出警告。B2被视为具有规范{[1:7]}。
——对于b3,对范围[2:5]和[6:10]发出警告。B3被视为具有规范{1,[2:3]}。
——对于b4,对范围[1:10]和值15发出警告。B2被视为具有规范{-1,[1:3]}。
7.4 交叉覆盖率cross
- cross关键字
bit [3:0] a, b;
covergroup cov @(posedge clk);
aXb : cross a, b;
endgroup
上例中的覆盖组cov指定两个4位变量a和b的交叉覆盖。
SystemVerilog隐式地为每个变量创建一个覆盖点。
每个覆盖点有16个仓,即auto[0]…auto[15]。
因此,a和b的叉乘(标记为aXb)有256个,每个叉乘的值都是aXb的仓。
bit [31:0] a_var;
bit [3:0] b_var;
covergroup cov3 @(posedge clk);
A: coverpoint a_var { bins yy[] = { [0:9] }; }
CC: cross b_var, A;
endgroup
覆盖组cov3将变量b_var与覆盖点A(标记为CC)交叉。变量b_var自动创建16个bin (auto[0]…auto[15])。
覆盖点A明确创建10个仓(yy[0]…yy[9]),两个覆盖点的交叉产生16x10 = 160个交叉仓,即:
<auto[0], yy[0]>
<auto[0], yy[1]>
…
<auto[0], yy[9]>
<auto[1], yy[0]>
…
<auto[15], yy[9]>
- binsof和intersect关键字
binsof构造生成其表达式的bins,可以是覆盖点(为单个变量显式定义或隐式定义)或覆盖点仓。
binsof( x ) intersect { y } //表示覆盖点x的仓,其值与y给出的范围相交。
! binsof( x ) intersect { y } //表示覆盖点x的仓,其值不与y给出的范围相交。
bit [7:0] v_a, v_b;
covergroup cg @(posedge clk);
a: coverpoint v_a
{
bins a1 = { [0:63] };
bins a2 = { [64:127] };
bins a3 = { [128:191] };
bins a4 = { [192:255] };
}
b: coverpoint v_b
{
bins b1 = {0};
bins b2 = { [1:84] };
bins b3 = { [85:169] };
bins b4 = { [170:255] };
}
c : cross a, b
{
bins c1 = ! binsof(a) intersect {[100:200]};// 4 cross products
用户定义的交叉仓c1,指定c1应该只包括,不相交于100到200范围的覆盖点a的交叉积。
c1将只包含<a1,b1>, <a1,b2>, <a1,b3>,和<a1,b4>的四个仓。这个选择表达式排除了仓a2、a3和a4。
bins c2 = binsof(a.a2) || binsof(b.b2);// 7 cross products
这个选择表达式包括以下七个交叉仓:< a2, b1 >, < a2, b2 >,<a2,b3>, <a2,b4>, <a1,b2>, <a3,b2>,和<a4,b2>。
bins c3 = binsof(a.a1) && binsof(b.b4);// 1 cross product
指定c3应该只包括覆盖点a1和b4。因此,这个选择表达式只包括一个交叉仓:<a1,b4>。
}
endgroup
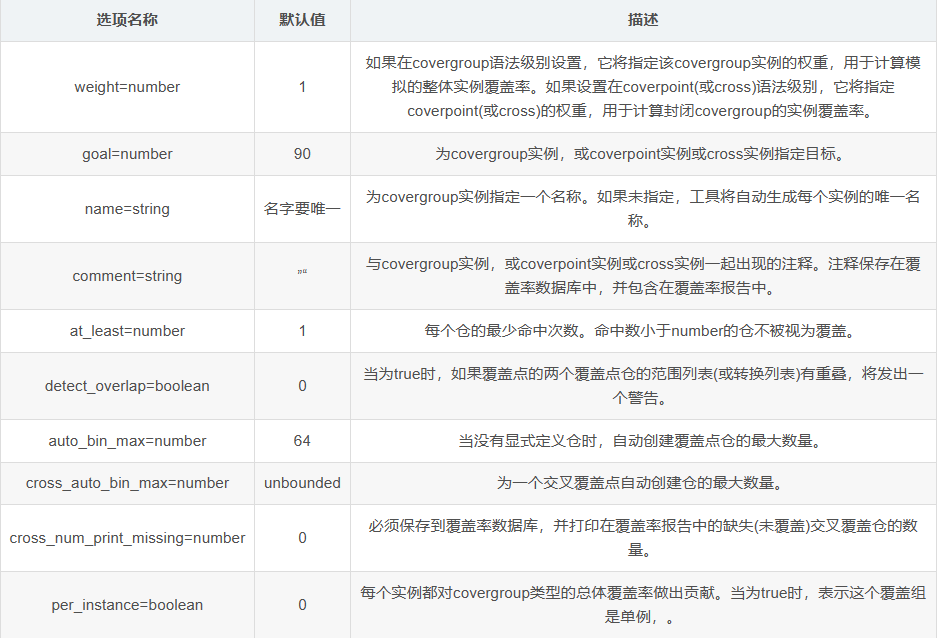
7.5 覆盖率选项
覆盖率选项控制覆盖组、覆盖点和交叉覆盖的行为。
特定于covergroup实例的选项,即option,以及指定covergroup类型整体选项的选项,即type_option。
- option
下表列出了实例特定的covergroup选项及其描述。covergroup的每个实例都可以将实例特定选项初始化为不同的值。初始化的选项值只影响该实例。
covergroup g1 (int w, string instComment) @(posedge clk) ;
// track coverage information for each instance of g1 in addition
// to the cumulative coverage information for covergroup type g1
option.per_instance = 1;
// comment for each instance of this covergroup
option.comment = instComment;
a : coverpoint a_var
{
// Create 128 automatic bins for coverpoint “a” of each instance of g1
option.auto_bin_max = 128;
}
b : coverpoint b_var
{
// This coverpoint contributes w times as much to the coverage of an
instance of g1 than coverpoints "a" and "c1"
option.weight = w;
}
c1 : cross a_var, b_var ;
endgroup
covergroup gc @(posedge clk) ;
a : coverpoint a_var;
b : coverpoint b_var;
endgroup
...
gc g1 = new;
g1.option.comment = "Here is a comment set for the instance g1";
g1.a.option.weight = 3; // Set weight for coverpoint “a” of instance g1
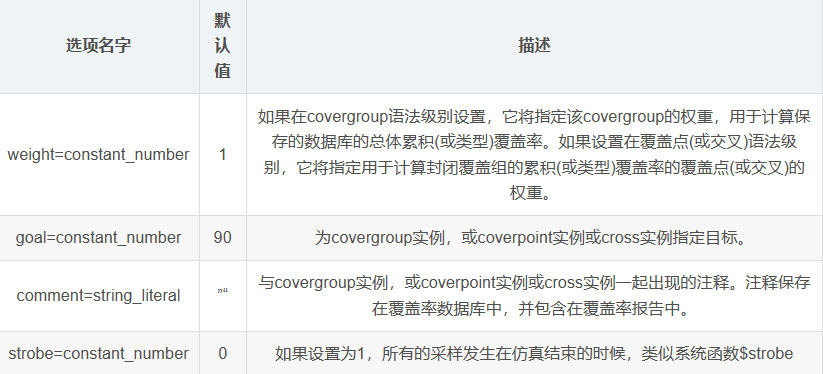
2. type_option
从整体上描述covergroup类型的特定特性(或属性)的选项
covergroup gc @(posedge clk) ;
a : coverpoint a_var;
b : coverpoint b_var;
endgroup
...
gc::type_option.comment = "Here is a comment for covergroup g1";
// Set the weight for coverpoint "a" of covergroup g1
gc::a::type_option.weight = 3;
gc g1 = new;
7.6 覆盖率系统任务和函数
- 预定义的覆盖率方法
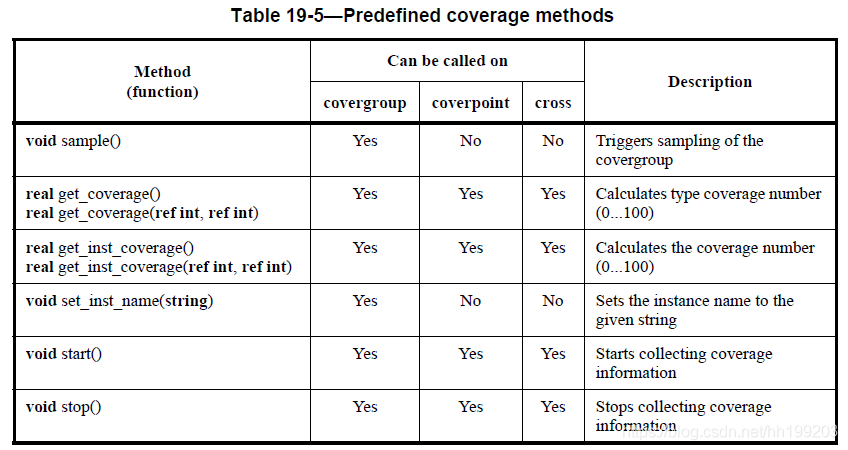
covergroup cg (int xb, yb, ref int x, y) ;
coverpoint x {bins xbins[] = { [0:xb] }; }
coverpoint y {bins ybins[] = { [0:yb] }; }
endgroup
cg cv1 = new (1,2,a,b); // cv1.x has 2 bins, cv1.y has 3 bins
cg cv2 = new (3,6,c,d); // cv2.x has 4 bins, cv2.y has 7 bins
initial begin
cv1.x.get_inst_coverage(covered,total); // total = 2
cv1.get_inst_coverage(covered,total); // total = 5
cg::x::get_coverage(covered,total); // total = 6
cg::get_coverage(covered,total); // total = 16
end
- 覆盖内嵌的采样方法
用一个接受参数的采样函数,覆盖预定义的sample()方法,便于从上下文(而不是包含covergroup声明的范围)中采样覆盖数据。例如,可以使用不同的参数调用覆盖的样例方法,以将要从自动任务或函数中、或从流程的特定实例中、或从并发断言的序列或属性中采样的数据直接传递给covergroup。
由于并发断言具有特殊的采样语义(值在Preponed区域采样),因此将它们的值作为参数传递给覆盖的样本方法有助于管理断言覆盖率的各个方面,例如通过一个属性对多个covergroup进行采样,通过同一个covergroup对多个属性进行采样,或者通过任意覆盖群对序列或属性(包括局部变量)的不同分支进行抽样。
covergroup p_cg with function sample(bit a, int x);
coverpoint x;
cross x, a;
endgroup : p_cg
p_cg cg1 = new;
property p1;
int x;
@(posedge clk)(a, x = b) ##1 (c, cg1.sample(a, x));
endproperty : p1
c1: cover property (p1);
function automatic void F(int j);
bit d;
...
cg1.sample( d, j );
endfunction
上面的例子声明了covergroup p_cg,它的示例方法被覆盖以接受两个参数:a和x。这个covergroup (cg1)实例的示例方法然后从属性p1和自动函数F()中直接调用。
covergroup C1 (int v) with function sample (int v, bit b); // error (v)
coverpoint v;
option.per_instance = b;// error: b may only designate a coverpoint
option.weight = v; // error: v is ambiguous
endgroup
8. sequence 机制使用方法 和 源代码解析
sequence机制是需要sequence、sequencer、driver组件和TLM及其他机制(如config_db机制等)共同密切配合完成激励的下发的。
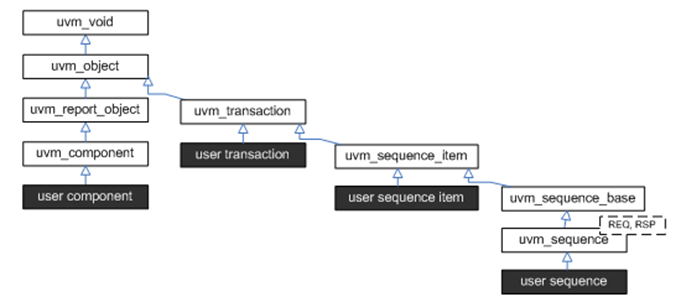
uvm_sequence对象,用户可以封装DUT初始化代码、基于总线的压力测试、网络协议栈——任何程序性的东西——然后让它们都以特定或随机顺序执行,以更快地达到Corner情况和覆盖目标。
uvm_sequence_item: uvm_sequence_item 是用户定义事务的基类,它利用了sequence-sequencer机制的激励生成和控制功能。
uvm_sequence #(REQ,RSP): uvm_sequence 扩展了 uvm_sequence_item 以添加直接或通过递归执行其他 uvm_sequences 生成 uvm_sequence_items 流的能力。
类的方法:
new:uvm_sequence_item 的构造方法。
get_sequence_id:私有方法;Get_sequence_id 是一种内部方法,不适用于用户代码。 sequence_id 不是一个简单的整数。 get_transaction_id 是为了让用户识别特定的transaction。
set_item_context:设置sequence_item的sequence和sequencer执行上下文
set_use_sequence_info、get_use_sequence_info:这些方法用于设置和获取 use_sequence_info 位的状态。
set_id_info:将被引用项目中的 sequence_id 和 transaction_id 复制到调用项目中。
set_sequencer:将序列的默认定序器设置为定序器。
get_sequencer:返回对此序列使用的默认排序器的引用。
set_parent_sequence:设置此 sequence_item 的父序列。
get_parent_sequence:返回对调用此方法的任何序列的父序列的引用。
set_depth:自动计算任何序列的深度。
get_depth:从其父序列返回序列的深度。
is_item:这个函数可以在任何sequence_item 或sequence 上调用。
get_root_sequence_name:提供根序列(最顶层的父序列)的名称。
get_root_sequence:提供对根序列(最顶层的父序列)的引用。
get_sequence_path:提供完整层次路径中每个序列的名称字符串。
报告接口序列项目和序列将使用与它们关联的序列器来报告消息。
uvm_report、uvm_report_info、uvm_report_warning、uvm_report_error、uvm_report_fatal :这些是 UVM 中的主要报告方法。
1. sequence 源代码解析
uvm_sequence_base 类提供了创建序列项和/或其他序列流所需的接口。
通过直接调用或调用任何 `uvm_do_* 宏来调用序列的 start 方法来执行序列。

依次调用以下方法

调用的是父序列的 pre|mid|post_do,而不是正在执行的序列。
变量
req 该序列包含一个名为req 的请求类型的字段。
rsp 该序列包含一个名为 rsp 的响应类型字段。
方法
new 创建并初始化一个新的序列对象。
send_request 该方法会将请求项发送到排序器,排序器会将其转发给驱动程序。
get_current_item 返回当前由 sequencer 执行的请求项。
get_response 默认情况下,序列必须通过调用 get_response 检索响应。
uvm_config_db#(uvm_object_wrapper)::set(this,“*.m_seqr.run_phase”,“default_sequence”, my_sequence::get_type());
那执行了这个set之后,为什么会在sqr的main_phase或者run_phase中执行此sequence呢?
其实是因为在uvm_task_phase中的m_traverse方法中的第110行调用了seqr.start_phase_sequence(phase);我们知道需要消耗仿真时间的phase(比如reset_phase、main_phase等)都是继承自uvm_task_phase的,也就是在执行main_phase等这些phase时都会执行到下图中的m_traverse方法,也即都会执行到110行的seqr.start_phase_sequence(phase)方法。
2. sequence body()方法
在body()方法中 先声明并创建了transaction,然后调用start_item,之后随机化,然后调用finish_item方法;
class mtrans extends uvm_sequence_item;
bit [7:0] crc;
function new(string name = "");
super.new(name);
endfunction
`uvm_object_utils_begin(mtrans)
`uvm_field_int(crc, UVM_ALL_ON)
`uvm_object_utils_end
endclass
class m_seq extends uvm_sequence #(mtrans);
`uvm_object_utils(m_seq)
function new(string name = "");
super.new(name);
endfunction
task body();
mtrans m;
repeat(5) begin
m = mtrans::type_id::create(.name("m"), .contxt(get_full_name()));
start_item(m);
assert(m.randomize());
end_item(m);
// m.end_event.wait_on();
end
endtask
endclass
3. sequence 挂载到 sequencer的应用
(1)方法1:
class m_test extends uvm_test;
`uvm_component_utils(m_test)
m_env env;
function new(string name = "", uvm_component parent);
super.new(name, parent);
endfunction
function void build_phase(uvm_phase phase);
super.build_phase(phase);
env = m_env::type_id::create("env",this);
endfunction
function void connect_phase(uvm_phase phase);
super.connect_phase(phase);
endfunction
task run_phase();
super.run_phase(phase);
例化seq:m_seq seq = m_seq::type_id::create("seq");
phase.raise_objection(this);
可以选择随机化seq:assert(seq.randomize());
调用start方法: seq.start(env.virt_sqr, null, 200);
//第二个参数是parent sequence,可以设置为null,如果该sequence没有上层的sequence嵌套它,则可以省略为null
//第三个参数是优先级,如果不指定则此值为-1,它同样不能设置为一个小于-1的数字
phase.drop_objection(this);
endtask
endclass
(2)方法2:
class m_test extends uvm_test;
`uvm_component_utils(m_test)
m_env env;
function new(string name = "", uvm_component parent);
super.new(name, parent);
endfunction
function void build_phase(uvm_phase phase);
super.build_phase(phase);
env = m_env::type_id::create("env",this);
uvm_config_db#(uvm_object_wrapper)::set(this,"env.i_agent.xxx_sqr.main_phase",
"default_sequence", m_seq::type_id::get());
1.由于除了main_phase外,还存在其他任务phase,如configure_phase、reset_phase等,
所以必须指定是哪个phase,从而使sequencer知道在哪个phase启动这个sequence。
2.为什么是uvm_object_wrapper而不是uvm_sequence或者其他,
则纯粹是由于UVM的规定,用户在使用时照做即可。
3.设置default_sequence 可以放在 env\test 的build_phase中,和top_tb中,如下:
module top;
initial begin
uvm_config_db#(uvm_object_wrapper)::set(null,"uvm_test_top.env.i_agent.xxx_sqr.main_phase",
"default_sequence", m_seq::type_id::get());
end
endmodule
endfunction
endclass
4. item 挂载到 sequencer 的应用
class bus_trans extends uvm_sequence_item;
rand int data;
`uvm_object_utils_begin(bus_trans)
`uvm_field_int(data, UVM_ALL_ON)
`uvm_object_utils_end
endclass
class child_seq extends uvm_sequence;
`uvm_object_utils(child_seq)
...
task body();
uvm_sequence_item tmp;
bus_trans req;
0. tmp = create_item(bus_trans::get_type(), m_sequencer, "req");
void'($cast(req, tmp));
start_item(req);
req.randomize with{ data == 1;};
finish_item(req);
endtask
endclass
class top_seq extends uvm_sequence;
`uvm_object_utils(top_seq)
...
task body();
uvm_sequence_item tmp;
bus_trans req;
child_seq cseq;
1.// create seq and item
cseq = child_seq::type_id::create("cseq");
tmp = create_item(bus_trans::get_type(), m_sequencer, "req");
2.// send child_seq via start();
cseq.start(m_sequencer,this);
uvm_sequence::start(uvm_sequencer_base sequencer,
uvm_sequence_base parent_sequence null,
int this_priority = -1, bit call_pre_post = 1)
参数1:指明sequencer的句柄;
参数2:如果是顶层的sequence,则用null
参数3:该sequence的parent_sequence(若有)继承其优先值
参数4:pre_body() 和 post_body() 会再body() task前后执行
3.// send item via start()
void'($cast(req, tmp));
start_item(req);
req.randomize with{ data == 10;};
finish_item(req);
uvm_sequence::start_item(uvm_sequence_item item,
int set_priority = 1,
uvm_sequencer_base sequencer=null);
参数3:如果要将item 挂载到 非当前parent_sequence 挂载到的sequencer上,需要指定参数,如virtual_sequence;
如果不需要,则默认情况
uvm_sequence::finish_item(uvm_sequence_item item,
int set_priority = 1);
endtask
endclass
9. seq sqr driver 之间数据传递 总结
driver:
在driver中通过get_next_item任务向 sequencer 申请新的transaction,
get_next_item是阻塞的,它会一直等到有新的transaction才会返回;
try_next_item则是非阻塞的,它尝试着询问sequencer是否有新的transaction,如果有,则得到此transaction,否则就直接返回。
相比于get_next_item,try_next_item的行为更加接近真实driver的行为:当有数据时,就驱动数据,否则总线将一直处于空闲状态。
通信机制图:
(1)在sequence中放sequencer的句柄,在sequencer中放sequence的句柄,进行sequence与sequencer的“双向握手”;
(2)利用TLM机制进行driver、sequencer的握手。下文会对握手机制进行深入的剖析。
1. 先查看env,test, top_tb是否配置了default_sequence, 2. 如果配置了,则创建default_sequence对象,设置该sequence的starting_phase,随机化该sequence,调用该sequence的start()方法,在该phase中启动sequence;如果没配置,则查看平台其他组件如test、env是否手动实例化 sequence 并调用start()方法;
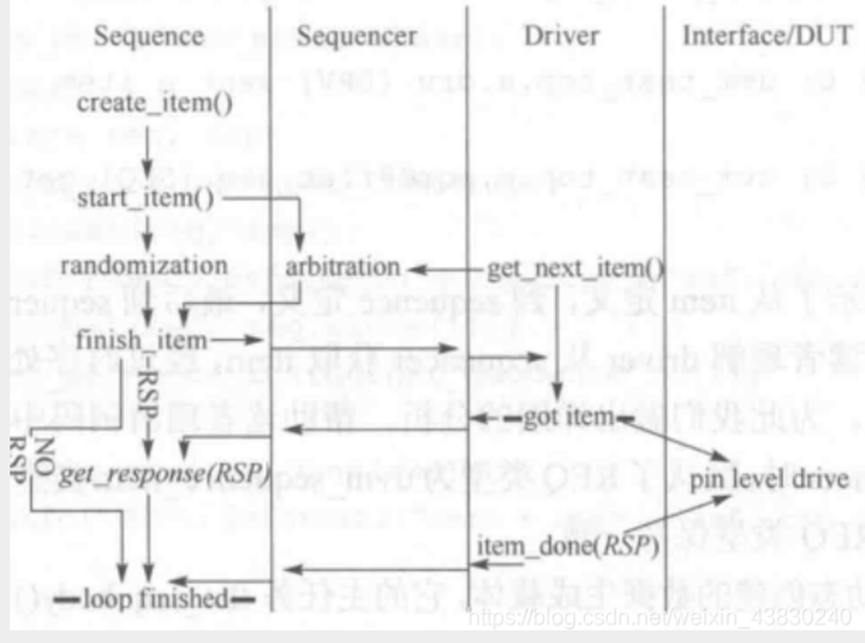
- seq启动后,create_item() , 然后start_item(),送入sqr的arbitration,判断好arbitration后,再送回seq,之后finish_item();
- 放入对应的 sqr 的item_fifo,
- driver 的 get_next_item() 触发 sqr 的arbitration, got_item 获取到事务后,
- driver 处理事务并发送给DUT,处理完事务成功后,给出标识到sqr fifo里, 并给到seq,如果失败,则返回seq重新产生item
- seq调用get_response拿rsp,如果不需要拿rsp,则不用拿,直接loop_finished,
- 同时 driver 调用item_done发送rsp到sqr fifo里,再送到seq ,然后loop_finished.
三、SV 与 UVM 特性对应

1 MCDF 里 chnl_pkg 的变化
uvm注册的第一、二步如图中右侧,注册的目的是想使用 父类的核心方法 如clone sprint compare copy
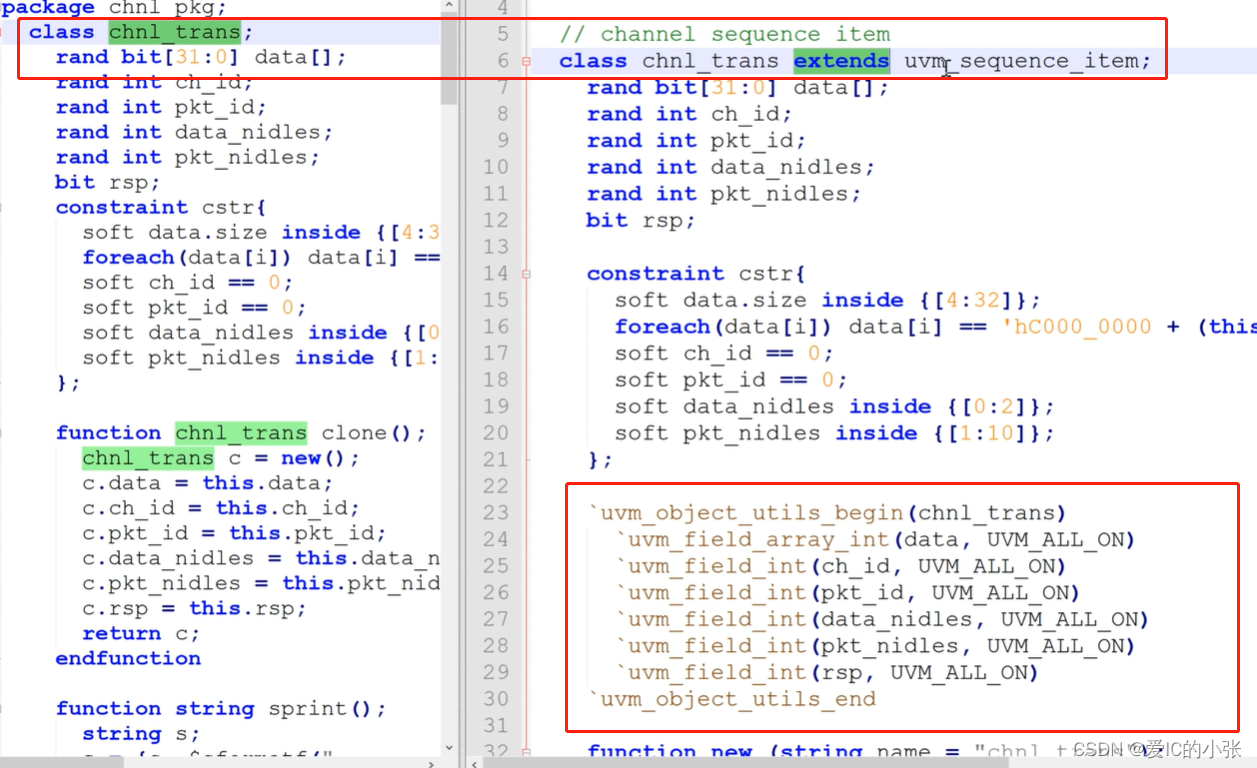
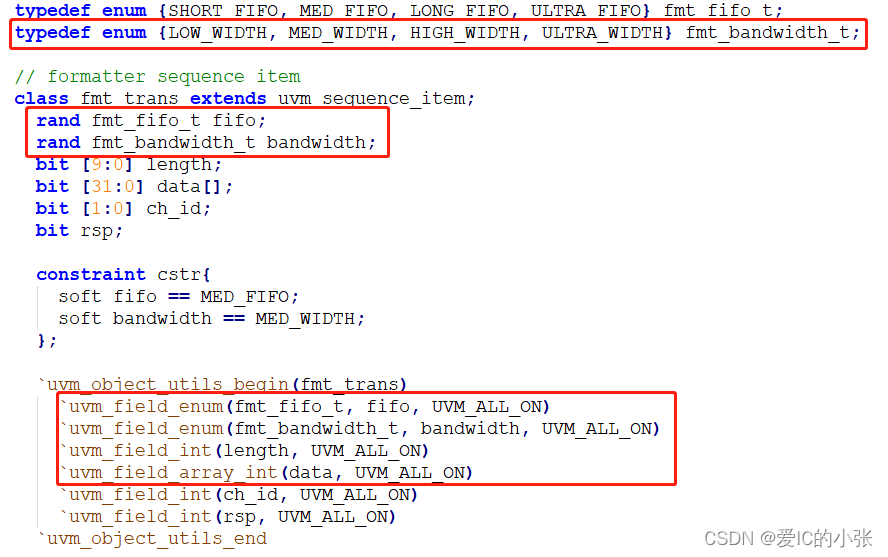
uvm 注册的第三步

UVM 的clone,返回的是uvm_sequence_item 类型,uvm_object类型, 遵循的是父类函数类型,返回的是父类句柄,创建的是子类对象,因此子类rsp指向父类req.clone()时,需要类型转换。
SV 的clone 返回的是chnl_trans 类型, 可以直接赋值; 如下图:
uvm通过 run_phase机制去控制,不用SV中的点火方式 run();

2 run_test作用,set_interface
在tb方面:
SV : 先例化 test 再 test.set_interface() , 然后test.run() ;
SV是可以将所有的test例化,然后逐一仿真;
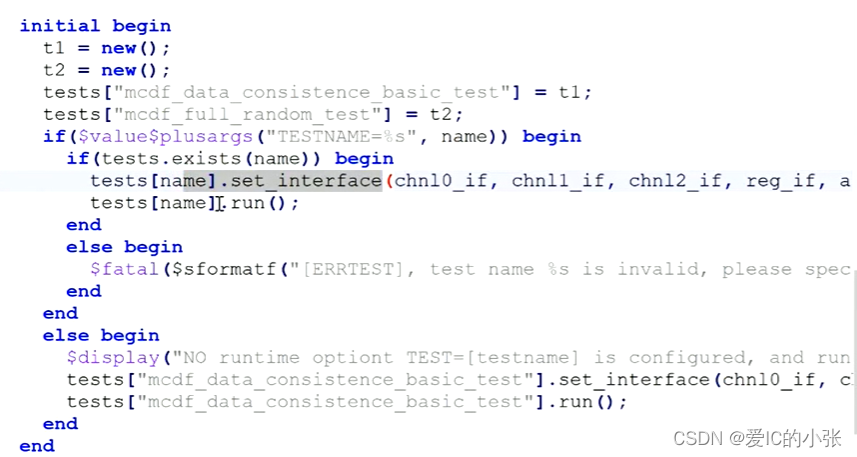
UVM: 是要将set_interface 只能用 config_db 这种方式代替,而且一定要在run_test之前进行。
UVM是需要利用仿真选项 +UVM_TESTNAME=my_test ,仿真运行run_test();
run_test作用:
- 帮你选择正确的test
- 利用这个test构建他的层次
- 执行这的这9个phase,利用objection控制仿真的结束,结束后还需要summary报告。
3 TLM 通信
-
monitor 组件里的 mailbox 被 `uvm_blocking_put_port #(type) bp_port_name;
port声明,new例化
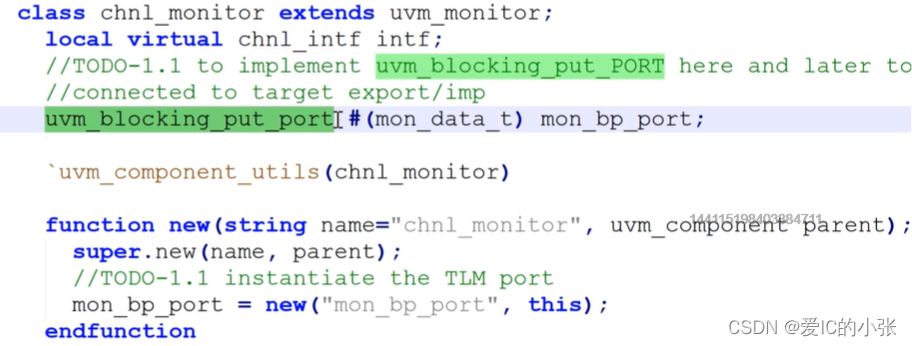
利用端口put(SV使用句柄put)

-
checker 声明与monitor通信的 import 端口类型,以及reference model 通信的import端口类型; 由于多个monitor和reference model 与checker 通信时多方向通信类型。
首先再mcdf_refmod 里放入宏`uvm_blocking_put_imp_decl(_name)
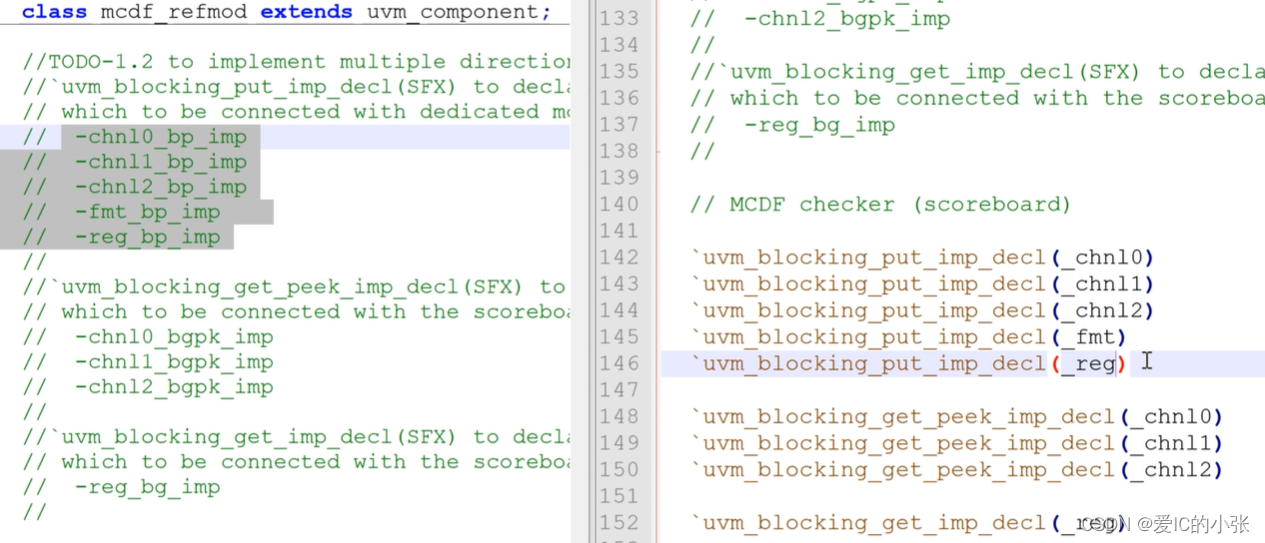

然后在checker里声明put和get_peek端口
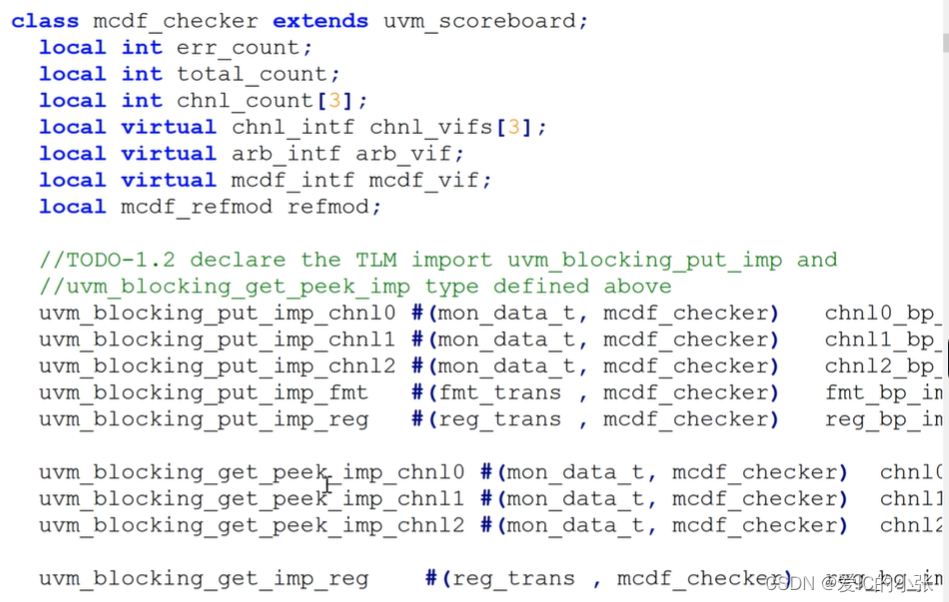
在new函数里例化
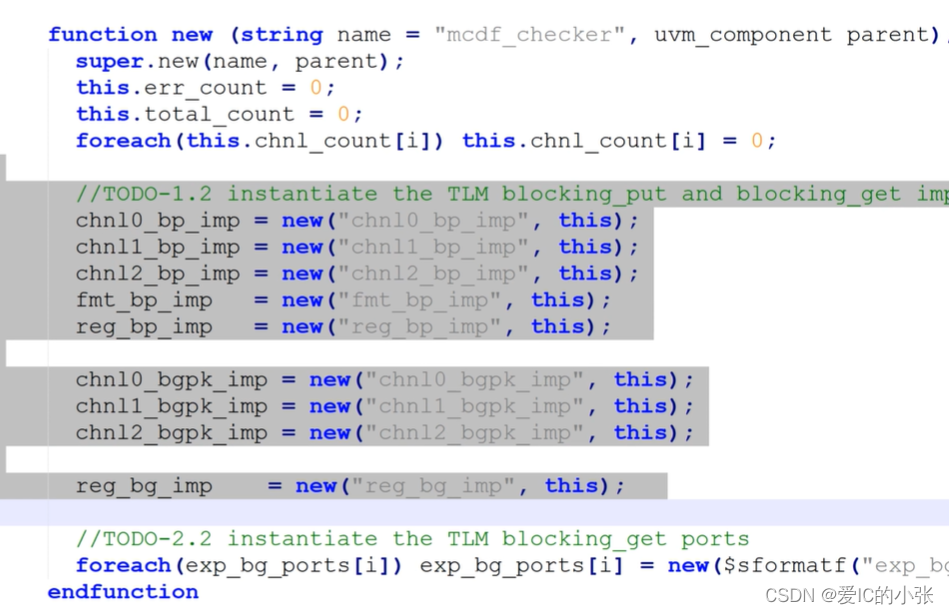
放在了mailbox里

-
reference model
声明get_port 并且例化
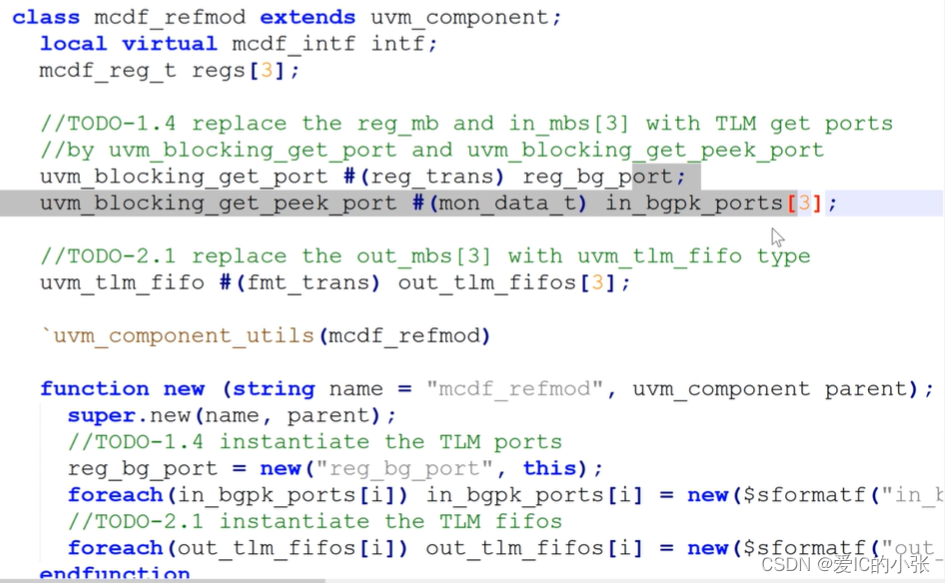
从 reg_mb 里get/peek data到refmod

-
在mcdf_refmod 里将mailbox存储内容功能替换成uvm_tlm_fifo, tlm_fifo自带import,不需要例化import!
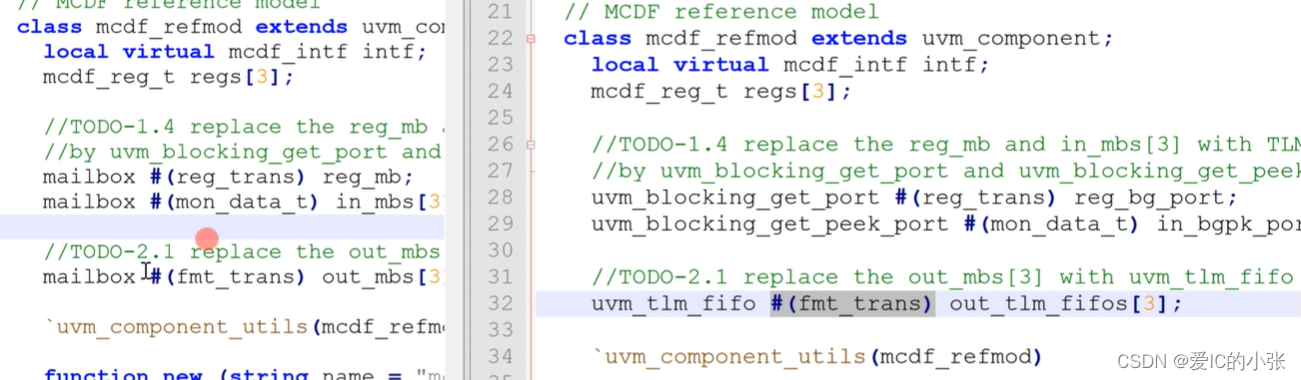
uvm_tlm_fifo例化放在new里


总结:1、2、3、4都要在5里 connect_phase连接
5.在connect phase 里连接



3.2 TLM端口通信缓存和mailbox的比较
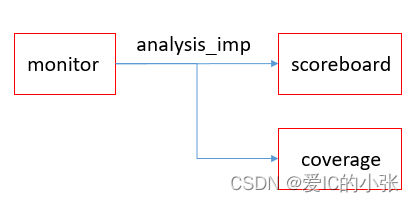
- scoreboard:拿到monitor的数据,用来做缓存,起到mailbox的功能 ;
coverage:拿到monitor的transaction,transaction里有event和data,coverage的write函数会触发event,触发采样sample1…; - 利用TLM通信,如果不想使用scb和cov,可以断掉,monitor的TLM端口支持空发;但是如果是mailbox通信,monitor检测到transaction,但是不连接scb和cov,那么句柄会悬空,put和get也做不到,不支持空发;
- 考虑到层次化;下图的连接如果用mailbox,那么 agnet.monitor.mb = sub.scoreboard.mb, 垮了很多层次,如果在sub里添加了一个agent环境,那么就要改写成sub.agent.scoreboard.mb。
如果用TLM端口连接,则只需要agent.ap.connect(sub.exp) 。跨层次可以一层层的连接。跨层次会带来很多编译的问题。
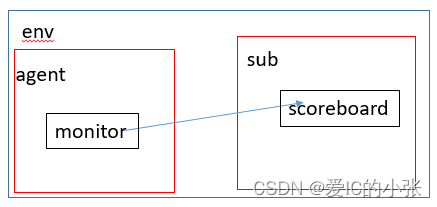
3.3 TLM通信只能在uvm_component之间,而uvm_event不限于此
3.4 TLM 单通道 单向通信(两个组件间) 的应用总结(红宝书 p343)
单向通信:是两个组件间,从comp4 -> agent 1
双向通信:是两个组件间,initiator和target之间,两个组件
多向通信:是两个组件间,initiator和target之间,每个组件有两个相同的TLM端口
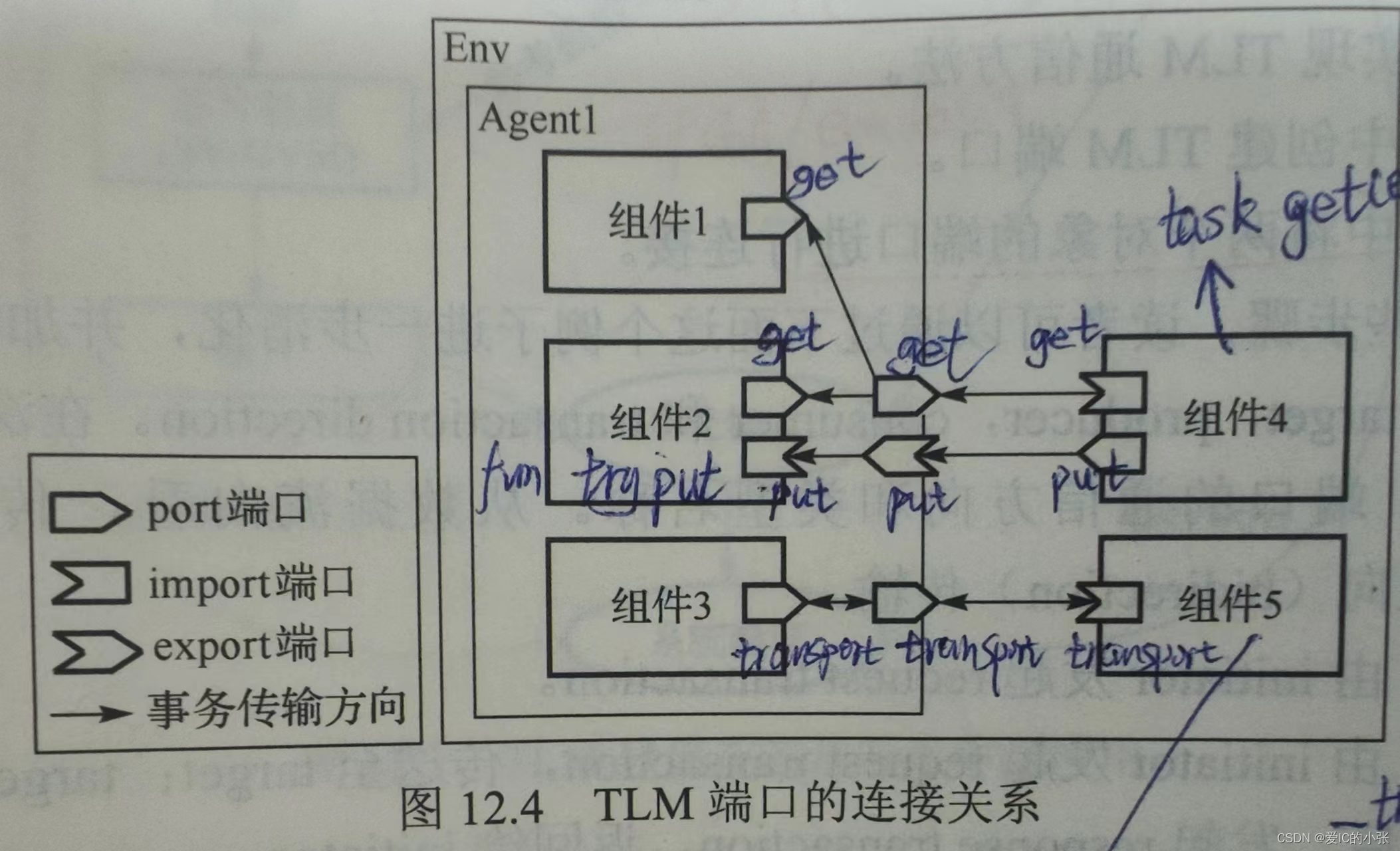
总结:
- 端口声明总结
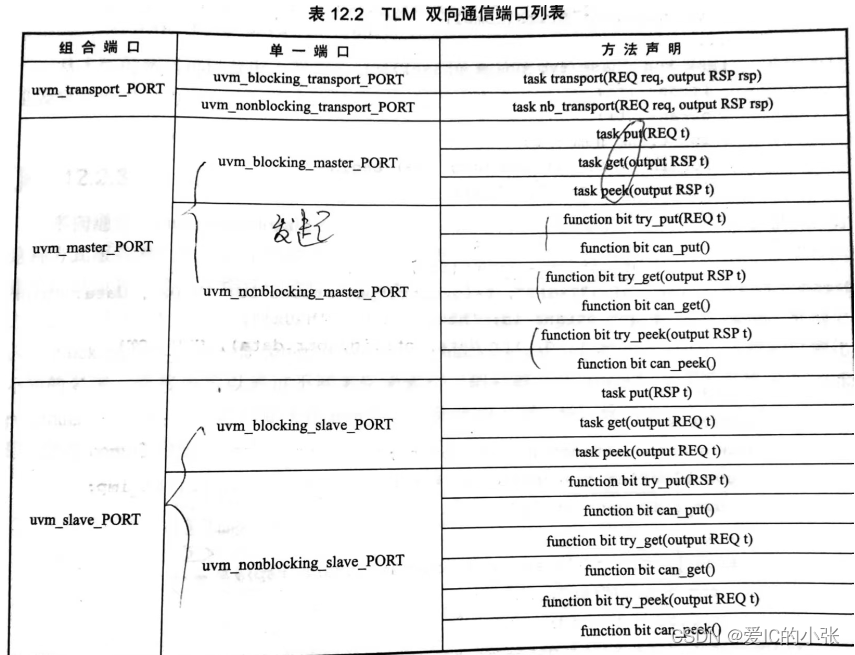
uvm_blocking_get*
uvm_nonblocking_put*
“*”的用法
_port #(request)
_export #(request)
_imp #(request, response)
_transport_port #(request, response)
_transport_imp #(request, response,comp5)
- 方法总结 - 在main_phase里声明方法
方法的声明必须在 imp端口类型的组件里,以供其他组件(initiator)调用该方法;否则即使端口连接也无法实现数据传输

3. get用blocking, 阻塞用task
4. put用nonblocking, 非阻塞用function
5. 要在comp2里声明两个function, 因为uvm_nonblocking_put_imp #(request,comp2) nbp_imp;,非阻塞
function bit try_put(request req);
function bit can_put();
6. comp5: task transport(request req, output response rsp);
7. comp4: task get(output request req)
- 创建和连接总结
在agent / env里的build_phase创建 c1 = comp1::type_id::create(“c1”, this);
在agent / env里的connect_phase连接 A_inst.端口名_port.connect(B_inst.端口名_imp)
3.4 TLM 双向通信(两个组件间) 的应用总结
3.4 TLM 多向通信(两个组件间) 的应用总结

问题:一个组件有两个相同的imp端口一侧实现专属方法,会造成方法命名的冲突。
解决办法:端口宏声明,使不同端口对应不同名的任务
`uvm_blocking_put_imp_decl(_p1)
`uvm_blocking_put_imp_decl(_p2)
class comp1 extends uvm_component;
uvm_blocking_put_port #(itrans) bp_port1;
uvm_blocking_put_port #(itrans) bp_port2;
`uvm_component_utils(comp1)
....
task run_phase(uvm_phase phase);
itrans itr1, itr2;
fork
...
3. 调用方法put而不是put_p1
this.bp_port1.put(itr1);
this.bp_port2.put(itr2);
join
endtask
endclass
class comp2 extends uvm_component;
1. 注意_p1放在imp的端口类型名
uvm_blocking_put_imp_p1 #(itrans, comp2) bt_imp_p1;
uvm_blocking_put_imp_p2 #(itrans, comp2) bt_imp_p2;
itrans itr_q[$];
semaphore key;
`uvm_component_utils(comp2)
..
2. 注意_p1方法put_p1
task put_p1(itrans t);
key.get();
itr_q.push_back(t);
key.put();
endtask
task put_p2(itrans t);
key.get();
itr_q.push_back(t);
key.put();
endtask
endclass
class env1 extends uvm_component;
comp1 c1;
comp2 c2;
`uvm_component_utils(env1)
function void build_phase(uvm_phase phase);
super.build_phase(phase);
c1 = comp1::type_id::create("c1",this);
c2 = comp1::type_id::create("c2",this);
endfunction
function void connect_phase(uvm_phase phase);
super.connect_phase(phase);
c1.bp_port1.connect(c2.bt_imp_p1);
c1.bp_port2.connect(c2.bt_imp_p2);
endfunction
endclass
3.5 带uvm_tlm_fifo(component类型)的数据传递

整个连接过程分为两段,comp_a 的port与 tml_fifo的 expoert 相连(其实是个imp),另一端是comp_b的export/port与tlm_fifo的export相连(其实是个imp)。
对于FIFO的深度,可以通过参数设置,
class env2 extends uvm_component;
component_A compA_inst;
component_B compB_inst;
uvm_tlm_fifo#(simple_packet) fifo_inst; // fifo stores simple_packets
function new(string name, uvm_component parent);
compA_inst= new("compA_inst", this);
compB_inst= new("compB_inst", this);
fifo_inst= new("fifo_inst", this, 16); // set fifo depth to 16
endfunction
virtual function void connect();
compA_inst.put_port.connect(fifo_inst.put_export);
compB_inst.get_port.connect(fifo_inst.get_export);
endfunction
endclass
3.5 TLM 多通道(多个组件)通信的应用
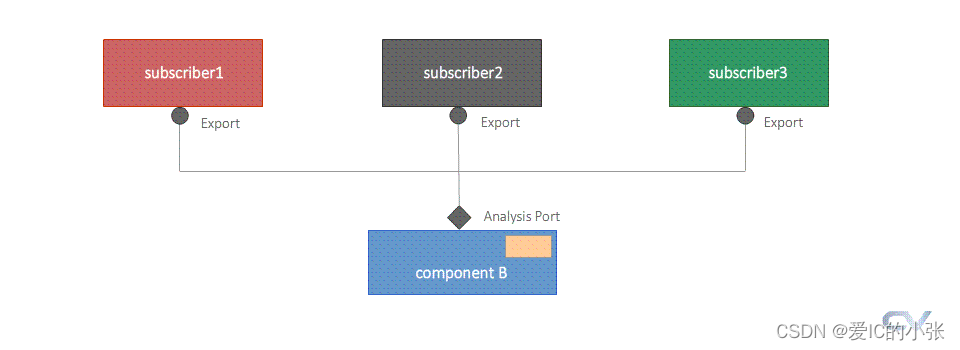
实现一端到多个组件的端口,如果数据源端口发生变化,需要采取observe pattern模式:其核心在于:
- 从一个initiator端到多个target端
- analsis port采取的是 push 模式,即从 initiator 端调用多个 target端的 write() 函数实现数据传输
UVM提供的analysis port,它在组件中是以广播(broadcast)的形式向外发送数据的,而不管存在几个imp或者没有imp。分析端口的根据端口类型的不同分为:
uvm_analysis_port、 uvm_analysis_export、 uvm_analysis_imp
并且只有一个操作:write();
由于是广播操作,理论上来讲,应该是非阻塞的,不然会影响其他模块获取数据。
1 实例采用uvm_analysis_port、 uvm_analysis_export、 uvm_analysis_imp

实现上图连接的代码
class A extends uvm_component;
`uvm_component_utils(A)
uvm_analysis_port#(my_transaction) A_ap;
function new(string name, uvm_component parent);
super.new(name, parent);
endfunction
extern function void build_phase(uvm_phase phase);
extern virtual task main_phase(uvm_phase phase);
endclass
function void A::build_phase(uvm_phase phase);
super.build_phase(phase);
A_ap = new("A_ap", this);
endfunction
task A::main_phase(uvm_phase phase);
my_transaction tr;
repeat(10) begin
#10;
tr = new("tr");
assert(tr.randomize());
A_ap.write(tr);
end
endtas
class B extends uvm_component;
`uvm_component_utils(B)
uvm_analysis_imp#(my_transaction, B) B_imp;
function new(string name, uvm_component parent);
super.new(name, parent);
endfunction
extern function void build_phase(uvm_phase phase);
extern function void connect_phase(uvm_phase phase);
extern function void write(my_transaction tr);
extern virtual task main_phase(uvm_phase phase);
endclass
function void B::build_phase(uvm_phase phase);
super.build_phase(phase);
B_imp = new("B_imp", this);
endfunction
function void B::connect_phase(uvm_phase phase);
super.connect_phase(phase);
endfunction
function void B::write(my_transaction tr);
`uvm_info("B", "receive a transaction", UVM_LOW)
tr.print();
endfunction
task B::main_phase(uvm_phase phase);
endtask
class C extends uvm_component;
`uvm_component_utils(C)
uvm_analysis_imp#(my_transaction, C) C_imp;
function new(string name, uvm_component parent);
super.new(name, parent);
endfunction
extern function void build_phase(uvm_phase phase);
extern function void connect_phase(uvm_phase phase);
extern function void write(my_transaction tr);
extern virtual task main_phase(uvm_phase phase);
endclass
function void C::build_phase(uvm_phase phase);
super.build_phase(phase);
C_imp = new("C_imp", this);
endfunction
function void C::connect_phase(uvm_phase phase);
super.connect_phase(phase);
endfunction
function void C::write(my_transaction tr);
`uvm_info("C", "receive a transaction", UVM_LOW)
tr.print();
endfunction
task C::main_phase(uvm_phase phase);
endtask
class my_env extends uvm_env;
A A_inst;
B B_inst;
C C_inst;
function new(string name = "my_env", uvm_component parent);
super.new(name, parent);
endfunction
virtual function void build_phase(uvm_phase phase);
super.build_phase(phase);
A_inst = A::type_id::create("A_inst", this);
B_inst = B::type_id::create("B_inst", this);
C_inst = C::type_id::create("C_inst", this);
endfunction
extern virtual function void connect_phase(uvm_phase phase);
`uvm_component_utils(my_env)
endclass
function void my_env::connect_phase(uvm_phase phase);
super.connect_phase(phase);
A_inst.A_ap.connect(B_inst.B_imp);
A_inst.A_ap.connect(C_inst.C_imp);
endfunction
上面这3段代码就实现了comp_a 向 comp_b 和 comp_c同时发送数据,所以write函数必然要在comp_b和comp_c上实现,这块没有多少隐藏在源码中的东西,按照这种规则实现就好,下一节我们在讨论tlm_port源码中的内容。
2 在1的基础上,有两个uvm_analysis_imp的IMP
现实情况中,scoreboard除了接收monitor的数据之外,还要接收reference model的数据。相应的scoreboard就要再添加一个uvm_analysis_imp的IMP,如model_imp。
//my_scoreboard.sv
`uvm_analysis_imp_decl(_mon) //宏的声明
`uvm_analysis_imp_decl(_mdl)
class scb extends uvm_component;
……
uvm_analysis_imp_mon#(transaction,scb) mon_imp; //端口声明
uvm_analysis_imp_mdl#(transaction,mdl) mdl_imp;
function write_mon(transaction tr); //方法声明
……
endfunction
function write_mdl(transaction);
……
endfuction
endclass
上述代码通过宏uvm_analysis_imp_decl声明了两个后缀_monitor和_model:
UVM会根据这两个后缀定义两个新的IMP类:uvm_analysis_imp_monitor和uvm_analysis_imp_model,并在my_scoreboard中分别实例化这两个类:monitor_imp和model_imp。当与monitor_imp相连接的analysis_port执行write函数时,会自动调用write_monitor函数,而与model_imp相连接的analysis_port执行write函数时,会自动调用write_model函数。 所以,只要完成后缀的声明,并在write后面添加上相应的后缀就可以正常工作了
uvm_tlm_analysis_fifo
uvm_tlm_analysis_fifo 继承于 uvm_tlm_fifo; 扩展了
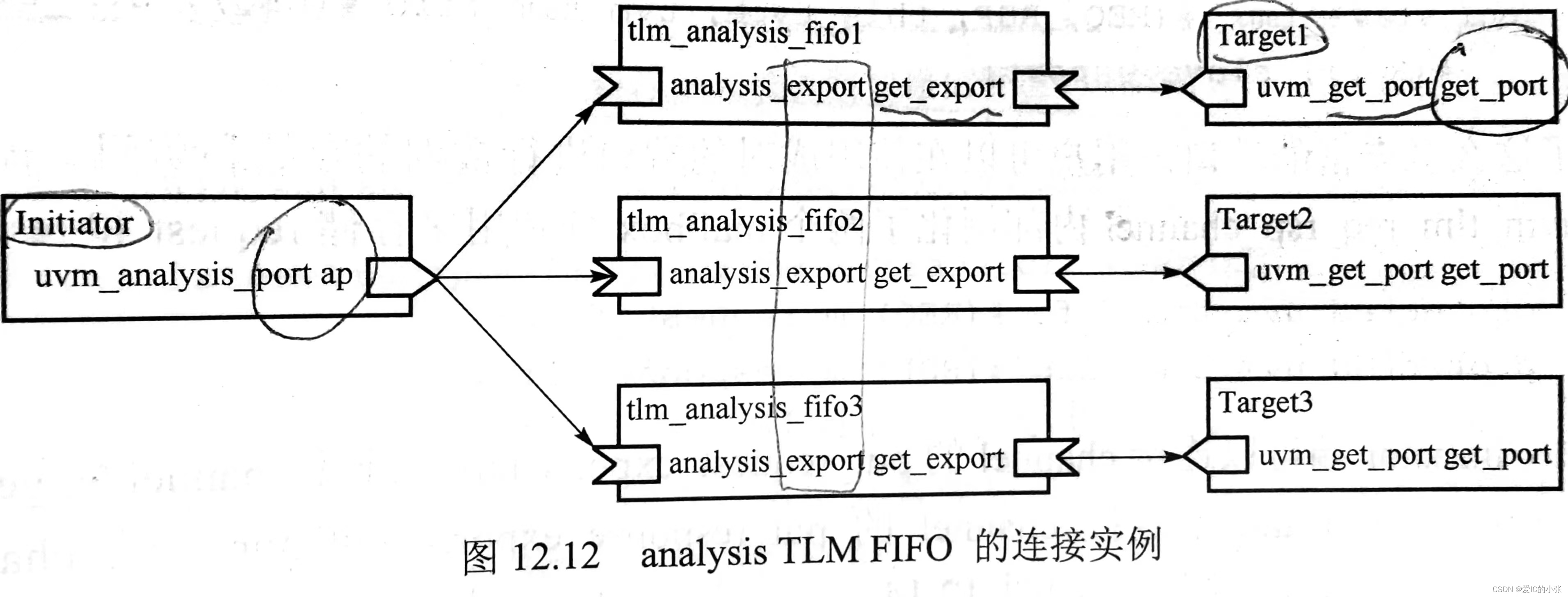
Request & Response 通信管道
在transport实现双向通信的基础上加入fifo数据缓存功能,有两种TLM通信管道:
uvm_tlm_req_rsp_channel
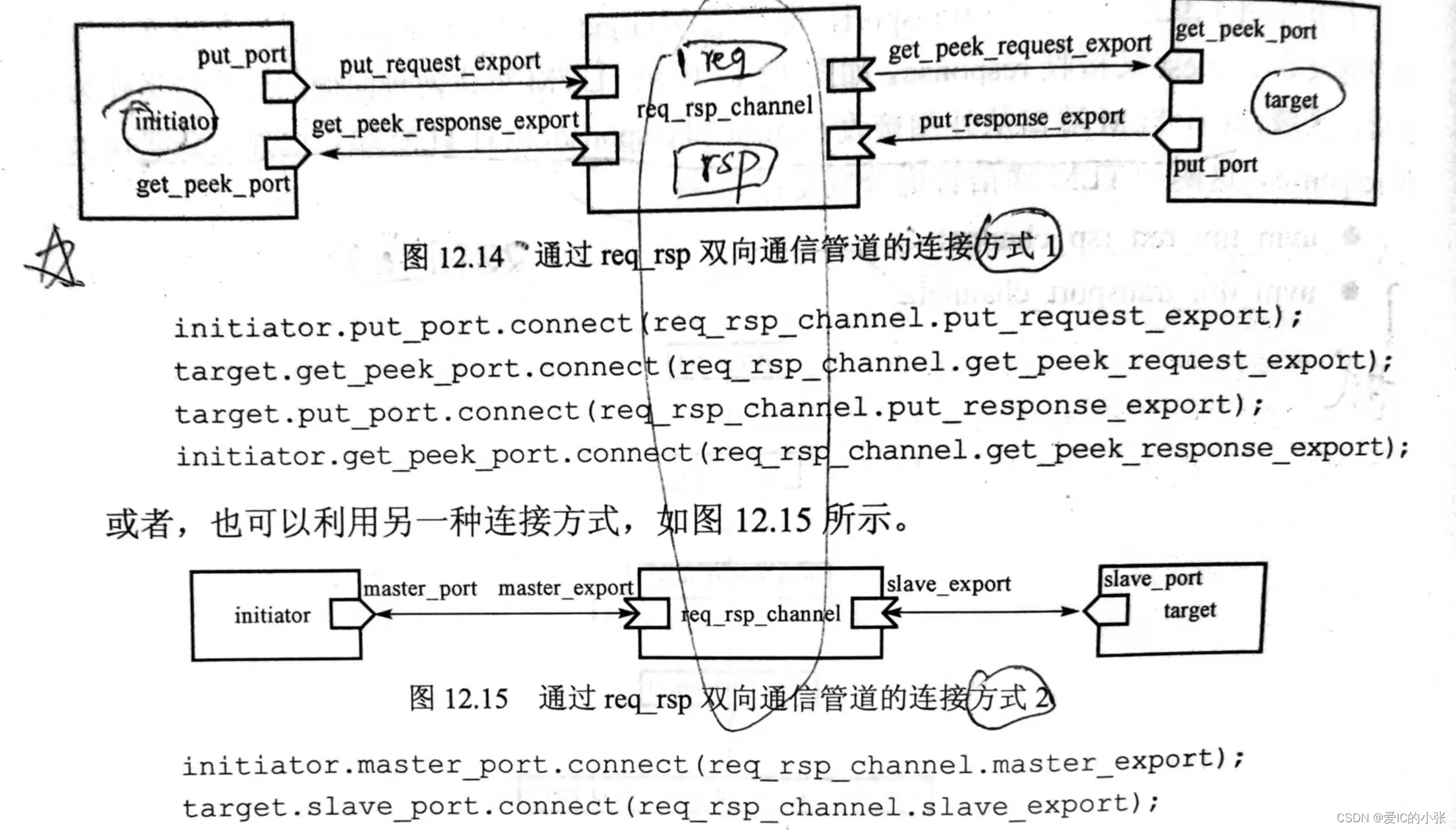

这个方法需要调用两次才可以完成request和response的传输。
uvm_tlm_transport_channel
这个方法是在uvm_tlm_req_rsp_channel基础上加了transport的组件
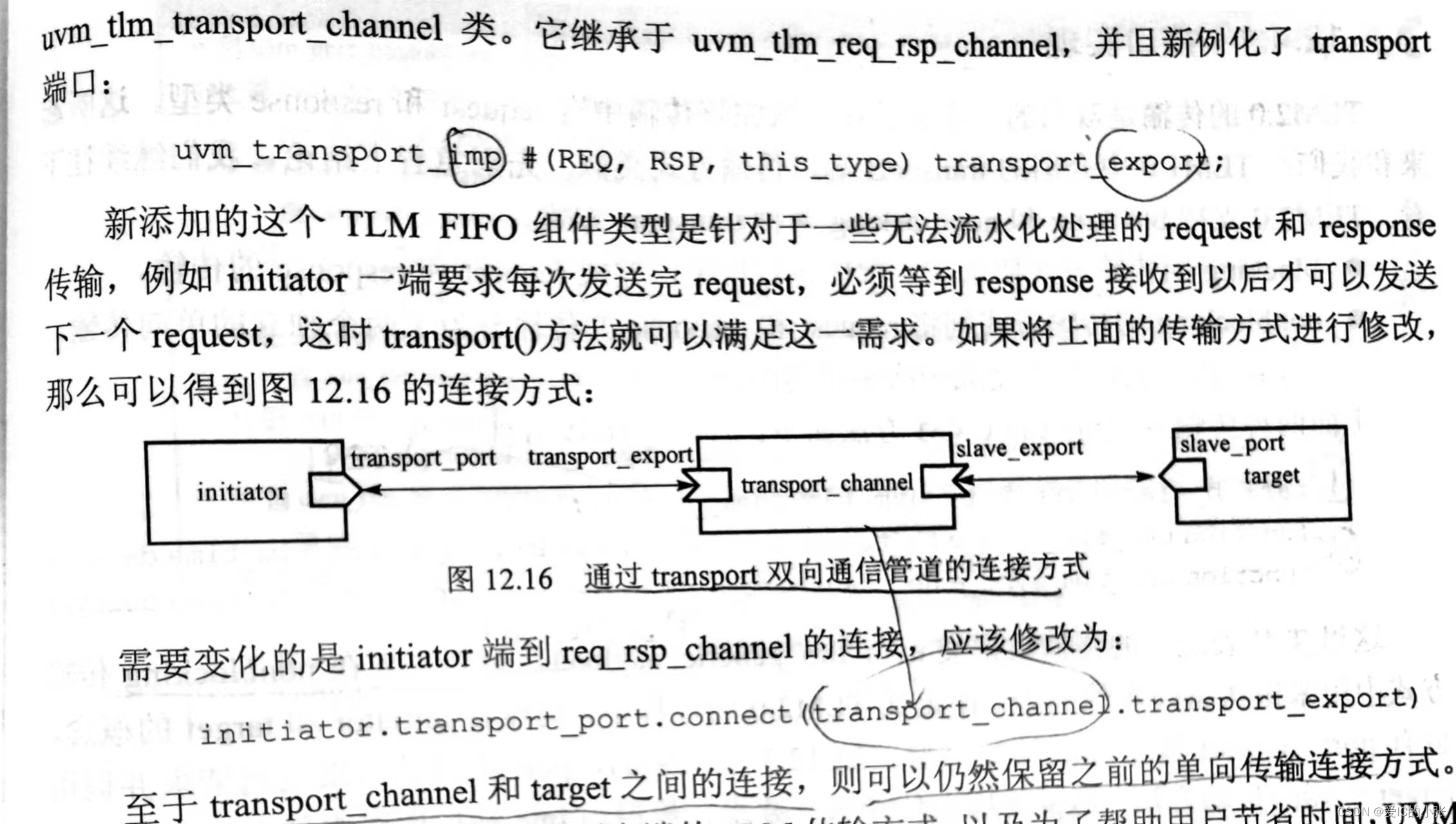
3.6 TLM 端口总结
TLM中的三种端口:PORT、EXPORT、IMP
- Port端口:
uvm_*_port #(T) *可以由下面任意一个代替:
blocking_put
nonblocking_put
put
blocking_get
nonblocking_get
get
blocking_peek
nonblocking_peek
peek
blocking_get_peek
nonblocking_get_peek
get_peek
T:The type of transaction to be communicated by the export
Ports are connected to interface implementations directly via uvm_*_imp #(T,IMP) ports or indirectly via hierarchical connections to uvm_*_port #(T) and uvm_*_export #(T) ports.
uvm_*_port #(REQ,RSP)*可以由下面任意一个代替:
blocking_transport
nonblocking_transport
transport
blocking_master
nonblocking_master
master
blocking_slave
nonblocking_slave
slave
REQ: The type of request transaction to be communicated by the export
RSP: The type of response transaction to be communicated by the export
Ports are connected to interface implementations directly via uvm_*_imp#(REQ,RSP,IMP,REQ_IMP,RSP_IMP) ports or indirectly via hierarchical connections to
uvm_*_port #(REQ,RSP) and uvm_*_export #(REQ,RSP) ports
- EXPORT
与PORT类型相似,同样有与port对应的uvm_export #(T)和uvm_eport #(REQ,RSP) - IMP
与PORT类型相似,同样有与port对应的uvm_imp #(T, IMP)和uvm_imp #(REQ,RSP,IMP,REQ_IMP,RSP_IMP)
T: The type of transaction to be communicated by the imp
IMP:The type of the component implementing the interface. That is, the class to which this imp will delegate
REQ:Request transaction type
RSP Response transaction type
REQ_IMP Component type that implements the request side of the interface.Defaults to IMP. For master and slave imps only.
RSP_IMP Component type that implements the response side of theinterface. Defaults to IMP. For master and slave imps only.
3.6 TLM的通信
首先是connect, 只能有下面几种connection type:

其次要理解控制流和数据流的方向。
控制流: 控制流永远是port到export或imp port的。也就是说,永远去是port作为数据通信的发起者去call put/get等function
数据流: 数据流有可能是从port到export/imp port,也有可能从export/imp port到port.
怎么理解呢,如下对比:
component A有uvm_put_port,component B有uvm_put_export,当A call put task时,数据从A传递到B
component A有uvm_get_port,component B有uvm_get_export,当A call get task时,数据从B传递到A
而不管是put还是get task,都会在component B中进行定义。有点像是A去调了B的task。所以总结起来就是port的task/function都要落到B的task/function上去实现
最后一定注意两件事情:
connect两边的tlm port的type以及transaction type一定要一致,比如blocking_put_port要连接 blocking_put_export或put_export。
更需要注意,一定要使用IMP 来终结连接关系, PORT和EXPORT都不能做为连接关系 的终点。
3.7 analysis port,analysis export, analysis imp
常用analysis port/imp/export(它们有点像是port/export/imp的增强版)。主要有以下区别:
- 一个analysis port可以连接多个analysis export/imp, 也就是说analysis port更像一个广播。
- analysis port只有一个write function。
- analysis port没有阻塞非阻塞的区分,它本身只是广播,不必等待其它相连的port的响应。.
既然是广播,那么就有可能一个analysis port连接到两个以上的imp,但是write function只有一个,我们怎么办呢?
处理方案:
1.通过宏uvm_analysis_imp_decl声明两个后缀不一样的imp,UVM会根据两个后缀内建两个新的imp
`uvm_analysis_imp_decl(_export1)
`uvm_analysis_imp_decl(_export2)
2.声明 port
uvm_analysis_imp_export1 #(transaction, scoreboard) scb_imp1;
uvm_analysis_imp_export2#(transaction, scoreboard) scb_imp2;
3.分别定义两个port的write function
function void write_export1(transaction txn);
function void write_export1(transaction txn);
特别要注意的一点:
analysis port广播出去的是handle,并没有为每一个export/imp的transaction分配alloction,如果如果 export1如果对transaction进行了修改, 那么export2会看到修改后的transaction.所以好的习惯是在write function里面首先 new一个 transaction,并对传输过来的transaction进行copy后,再进行后面的操作。
3.8 uvm_tlm_fifo,uvm_tlm_analysis_fifo
uvm_tlm_fifo其实就是能够在tlm肚子里面buffer很多transaction,就像FIFO一样。
有人可能会这样做,我自己在scoreboard里面申明queue,也一样做到fifo的效果。 确实,很多情况下,直接把analysis port传过来的transaction放queueu里面,是一个不错的方法。但fifo还有以下几个好处:
- uvm_tlm_fifo是被动接收数据和被动发送数据,因此可以把发起端和接收端完全分隔开,发数据和收数据的行为完全独立。
2.如果design的transaction有 outstanding,那么uvm_tlm_fifo就直接可以model design的fifo行为了(当然用queue做也不错,甚至碰到out of order的时候比fifo还好用)。
3.通过imp加后缀可以解决多对port,export的情况,但如果port数据多了呢。比如一个有16进16出的AXI interconnect,在scoreboard的port上去申明16个不同名字的imp显然不方便。那么这时候只需要申明一个uvm_tlm_fifo数组就可以了。(IMP没办法申明数组)
scoreboard:
uvm_tlm_analysis_export (#sb_item) in_expor[10];
uvm_tlm_analysis_fifo(#sb_item) scb_fifo[10];
uvm_blocking_get_port #(sb_item) fecth_port[10];
...
function void connect_phase
foreach(in_export[i]) begin
in_export[i].connect(scb_fifo[i].analysis_export);
fetch_port[i].connect(scb_fifo[i].blocking_get_export);
end
endfunction
env:
function void connect_phase
foreach(mon[i])
mon[i].ap.connect(scb.in_expor[i]);// 为什么要有一个in_export作桥梁,而不直接用mon.op连到scb的fifo呢。可以参考uvm_users_guide 2.3.2,这里不作详细说明
endfunction
在soreboard中,不必再去写一个write function和get task了,因为fifo里面已经做了。mon.ap.write直接把数据放到fifo里面,而fetch_port.get直接出fifo头 拿数据。
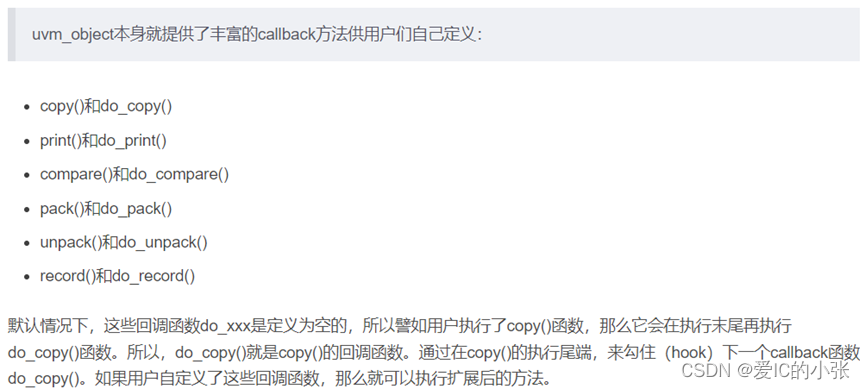
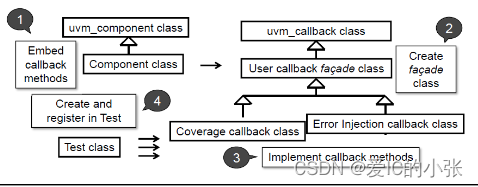
4 回调函数应用方法
-
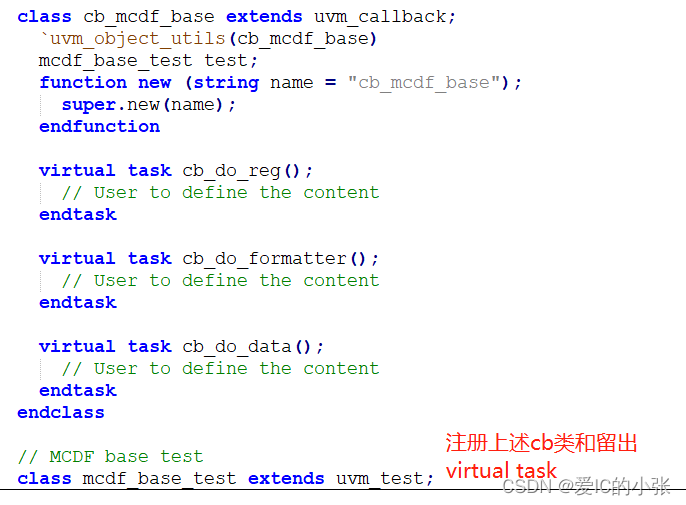
定义回调类,继承于 uvm_callback ;
-
`uvm_register_cb(目的类,回调类) ,绑定回调类和组件;
-
`uvm_do_callback(目的类,回调类 ,回调函数) ,在类中插入回调函数;
-
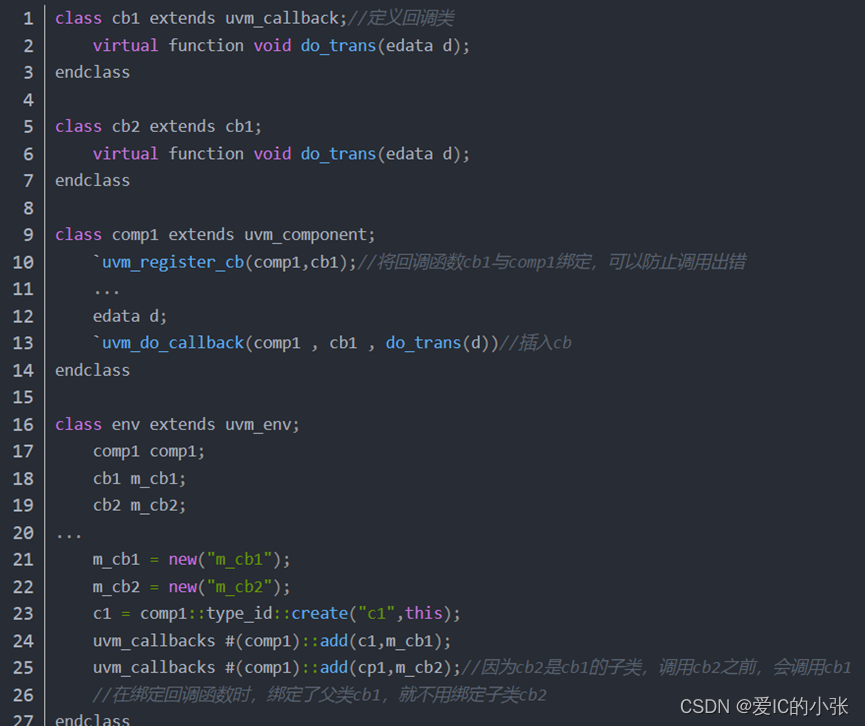
例化callback对象(cb1和cb2)通过uvm_callbacks #(T,CB)类的静态方法 add( ) 来添加成对的uvm_object对象和callback对象;
对于uvm_callbacks#(T, CB)::add(t,cb)方法,其几个参数的含义如下:
T:表示回调类所在的组件名,即实现Callback机制的组件名,回调类与组件类在同一组件文件中;
CB:表示空壳回调类的类名;
t:表示回调类所在的组件的实例名,也就是组件的对象名;
cb:表示回调类的实例名,也就是对象名; -
先定义一个callback类,然后再将几个virtual task定义好,
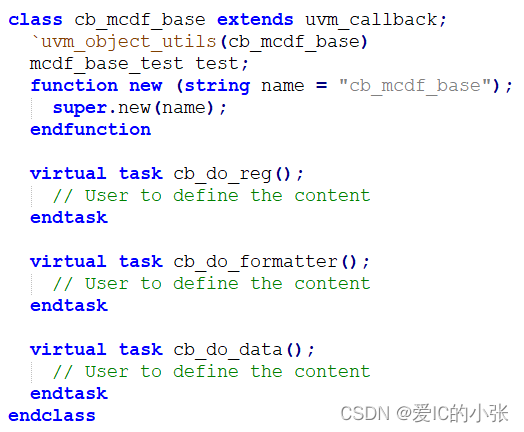
-
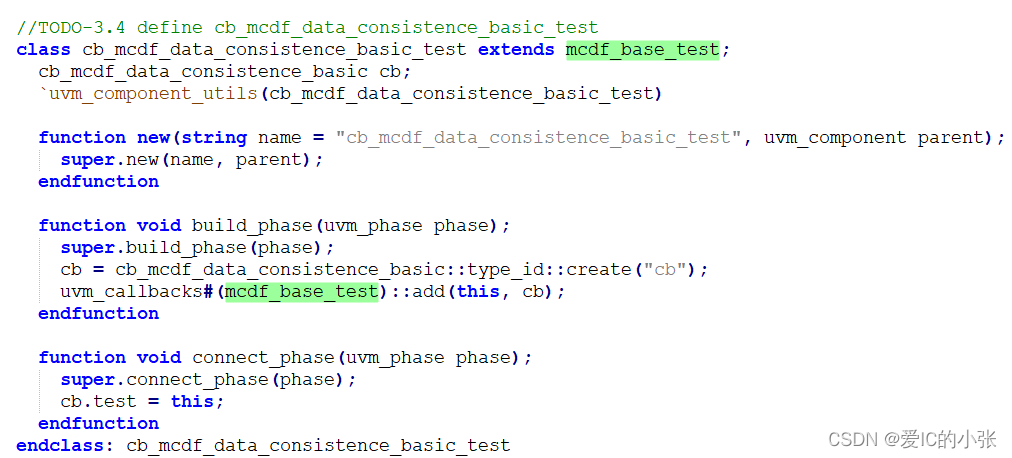
在 mcdf_base_test中 将 cb_mcdf_base和mcdf_base_test绑定;

并且在 mcdf_base_test 的 virtual task do_reg(); 加上`uvm_do_callbacks(mcdf_base_test,cb_mcdf_base,cb_do_reg())
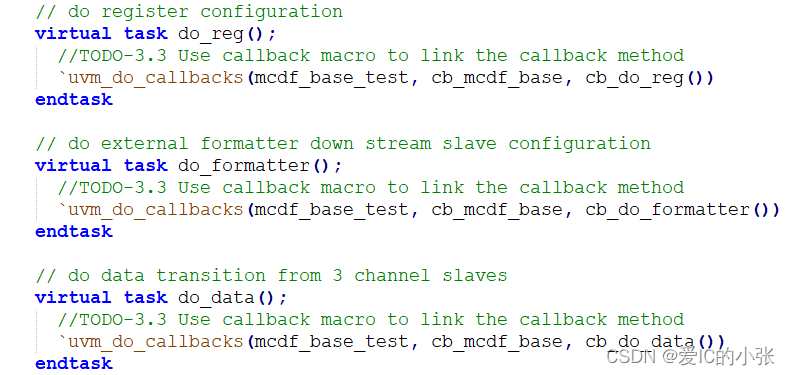
-
新定义的 test类 extends cb_mcdf_base
例化并添加改写任务的类
总结:几个步骤,详细参考 lab3_mcdf_pkg.sv

4.1 回调与继承的应用区别.(没听太懂)
回调函数的定义: 通过一个函数指针调用的函数。我们把将函数的指针(地址)作为参数传递给另一个函数,当这个指针被用来调用其所指向的函数的过程,称为回调函数。
回调函数不是由该函数的实现方直接调用,而是在特定的事件或条件发生时由另外一方的调用的,用于对该事件或条件进行响应。
4中的例子是通过继承的方式,添加的callback;
callback可以单独添加,不依赖继承:可以在driver里加入error_insertion_cb(trans),add ERR_CB,
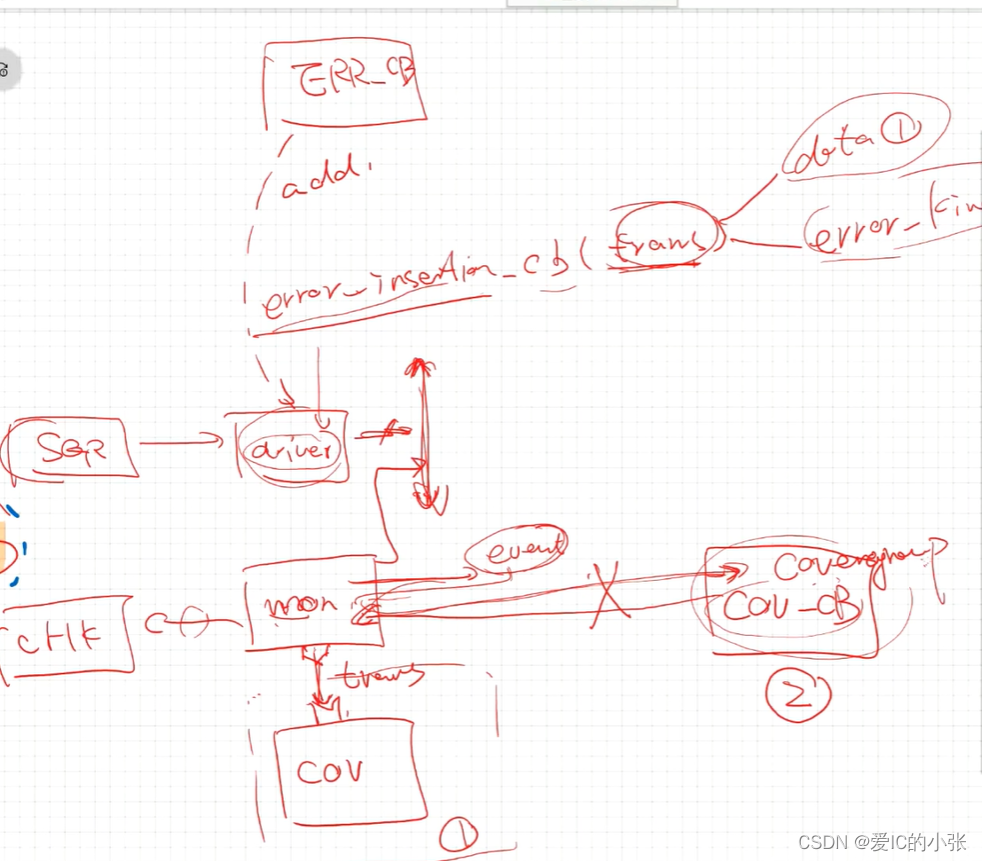
5 end_of_elaboration_phase() 仿真前的配置


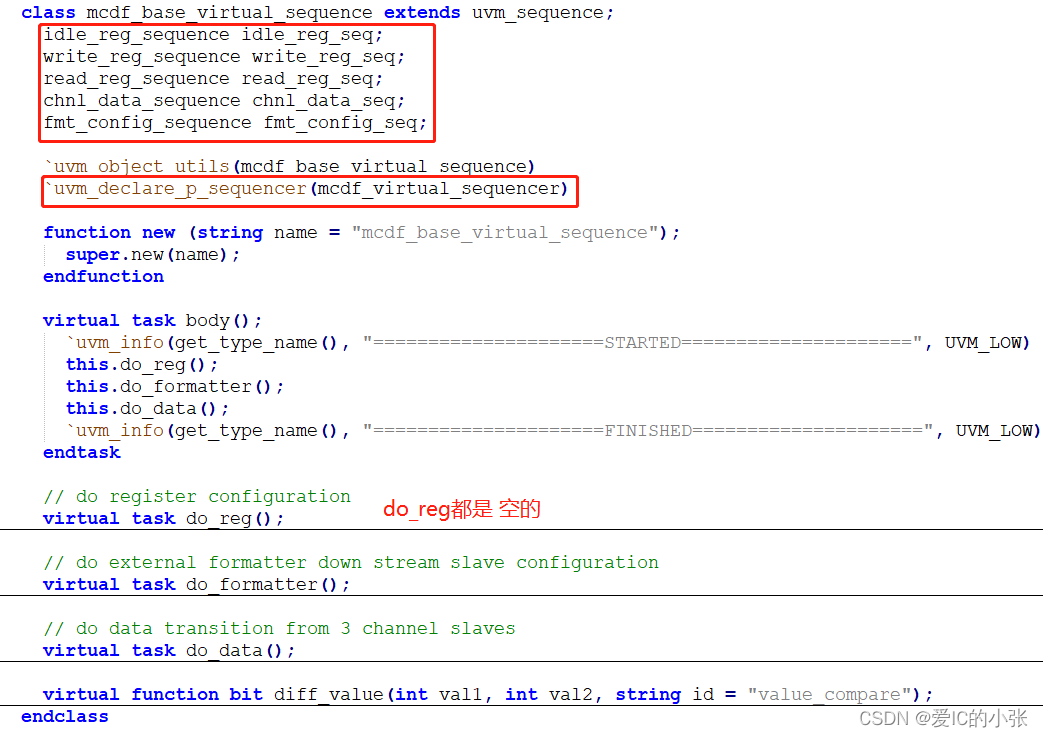
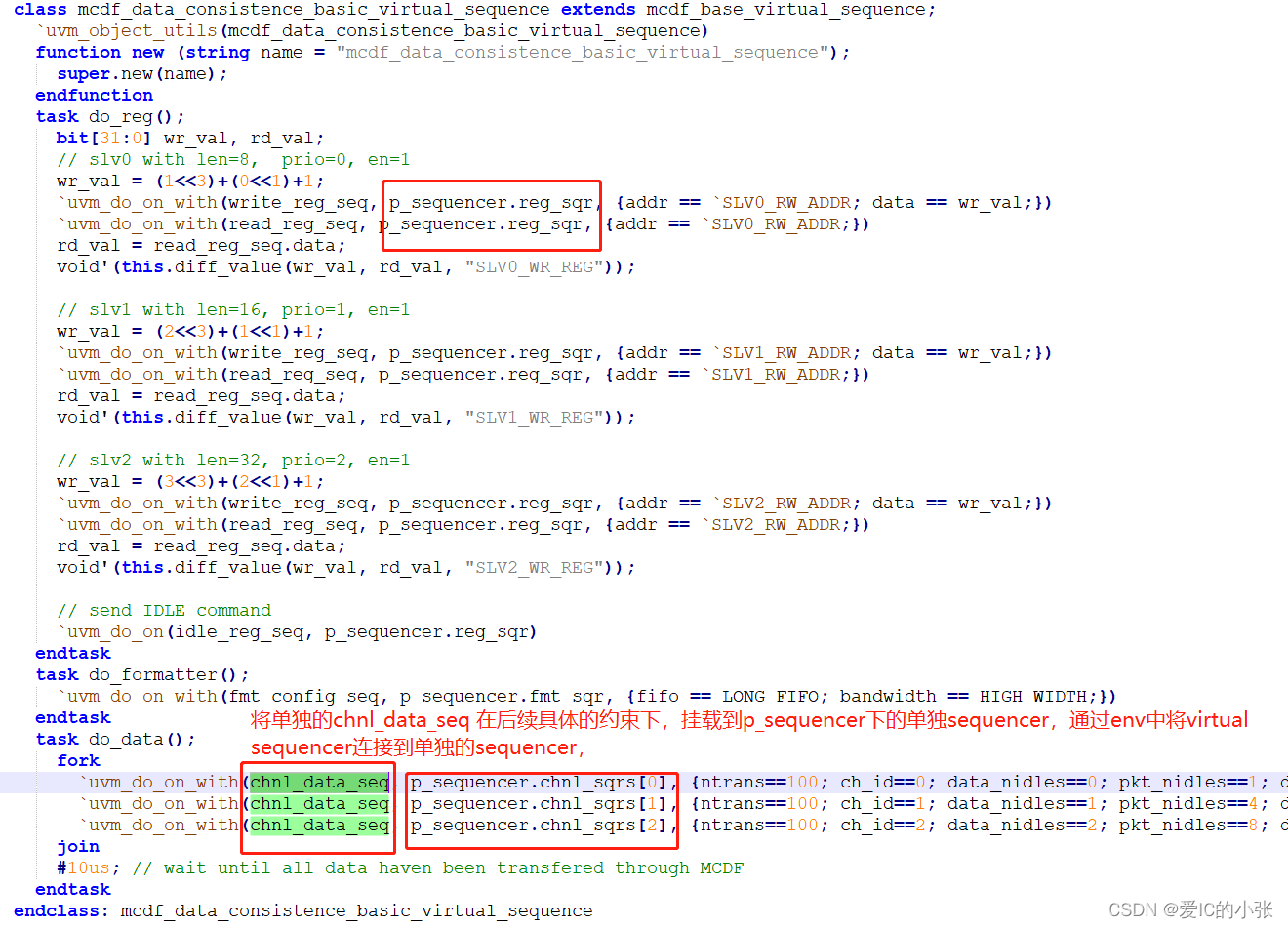
6 virtual_sequence 、virtual_sequencer、test 实例
test: 在build_phase阶段 配置 VIP;
virtual_sequence里发送激励,做配置给对应的test,在test里通过start方法将seq发送给对应的sqr
总的virtual sequence:
具体的virtual sequence
与具体的virtual sequence 对应的test,点火seq

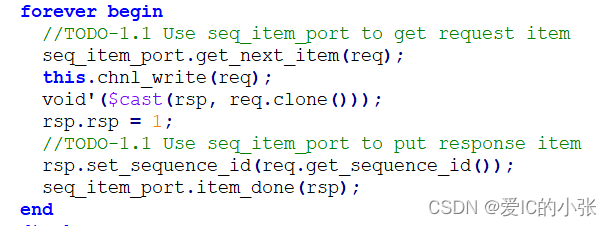
**单独的driver:**利用seq_item_port 发送req
总的sequencer:

单独的sequencer:

单独的sequence:
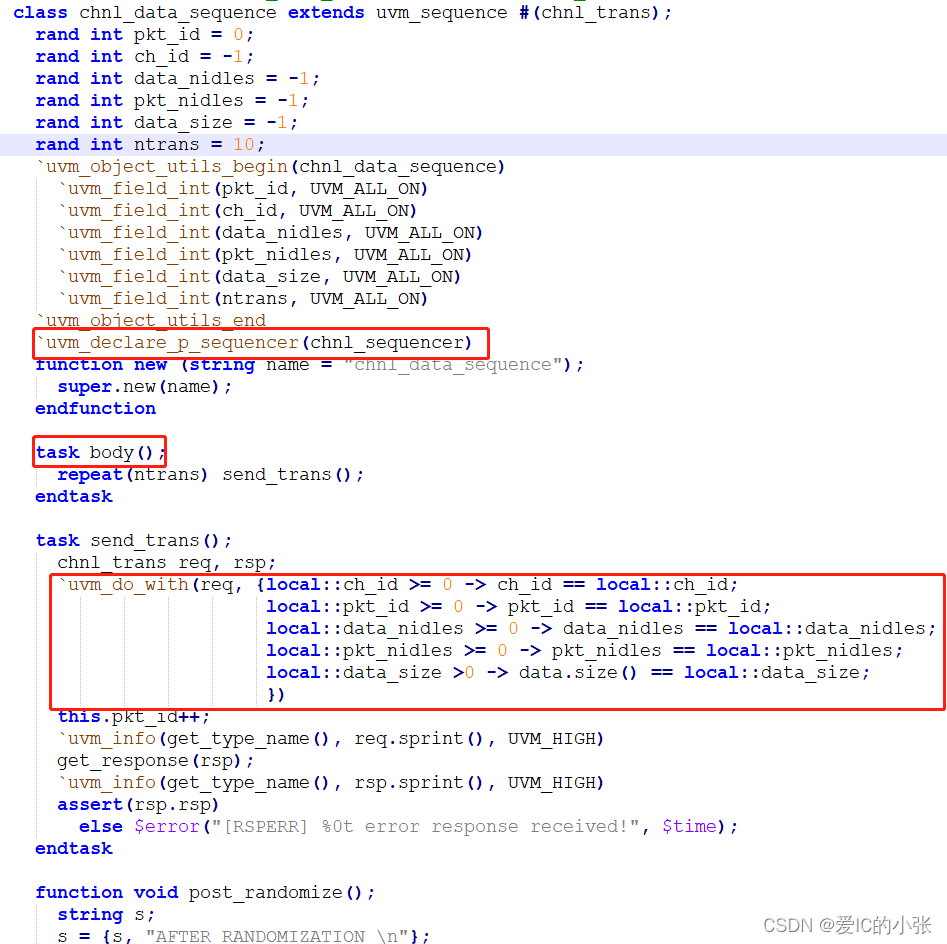
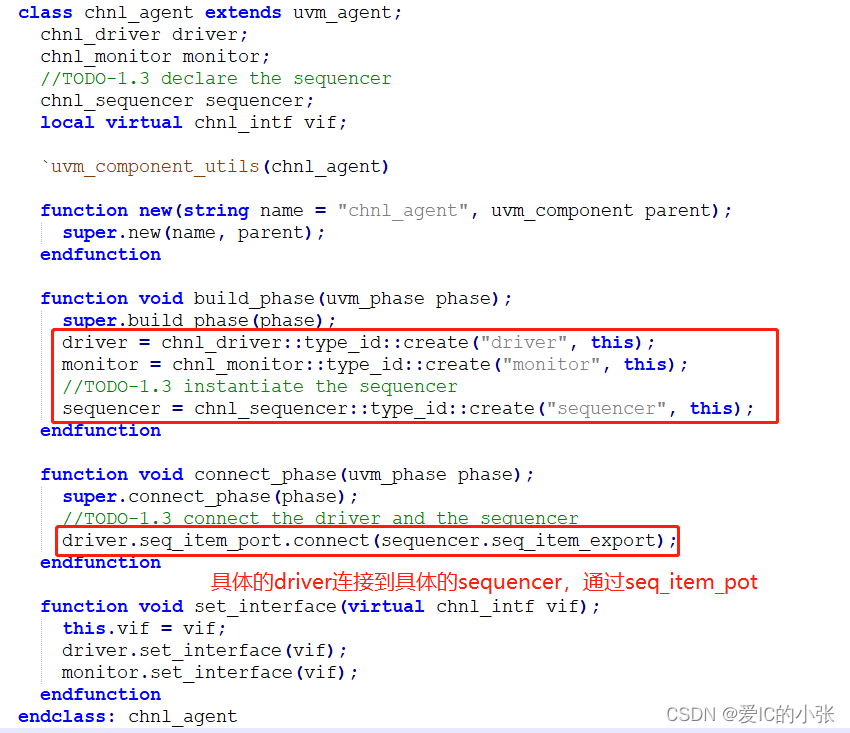
单独的agent: 连接sequencer和driver
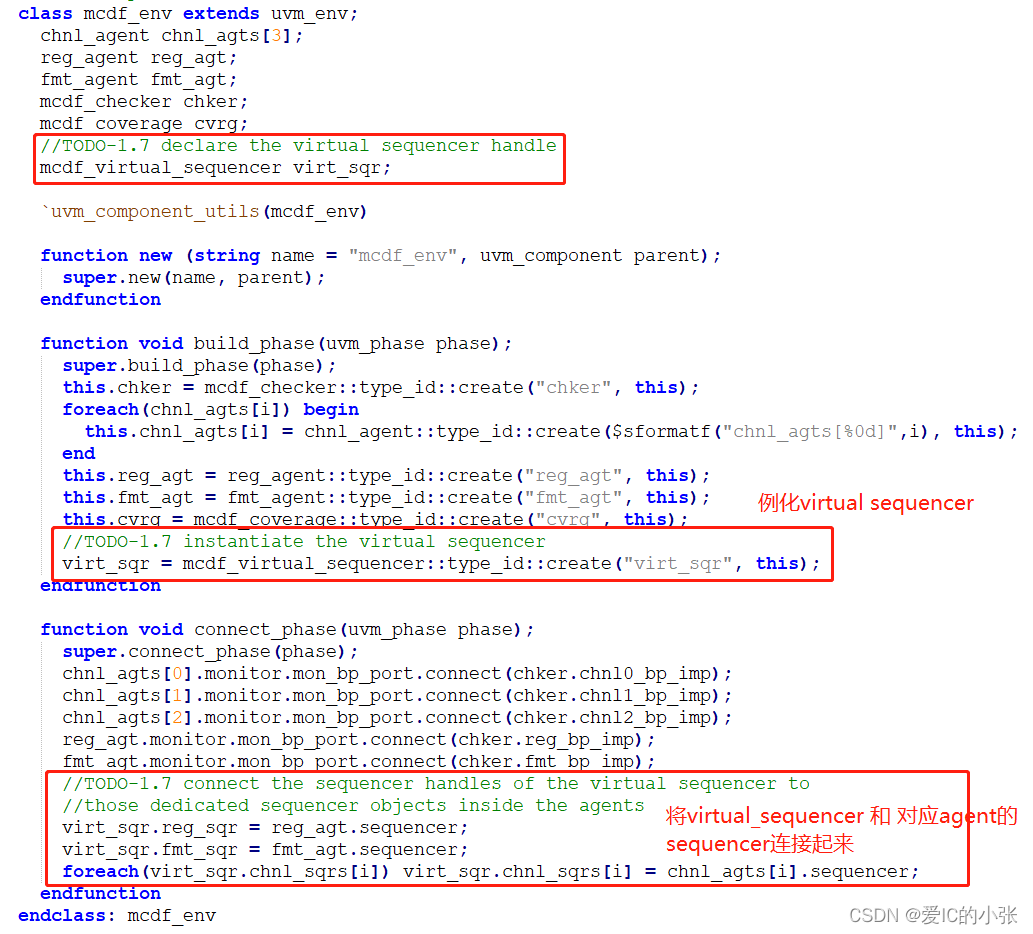
总的env:
6.0 virtual_sequence 中嵌套的sequence 和 普通的sequence中嵌套sequence区别:
普通的sequence中嵌套sequence 都在同一个sequencer上启动,通过sequencer仲裁决定;
virtual_sequence 中嵌套的sequence 可以在不同sequencer实体上同时启动;
6.1 virtual seq 和virtual sqr 不直接作用在driver上,不处理具体的transaction,那他的作用是什么?实现方式?
Virtual sequence 的作用: 和virtual sequencer相关联的就是virtual sequence,它的作用是协调不同的subsequencer中sequence的执行顺序。
Virtual sequencer 的特点: 含有sub sequencer的句柄,用以控制这些sub sequencer。它并不和任何driver相连 Virtual sequencer,本身并不处理具体的trans/seq。
作用: 主要是来做不同类型sequence间的控制和调度的。处理具有多个agent和处理不同transactions的tb的复杂性。
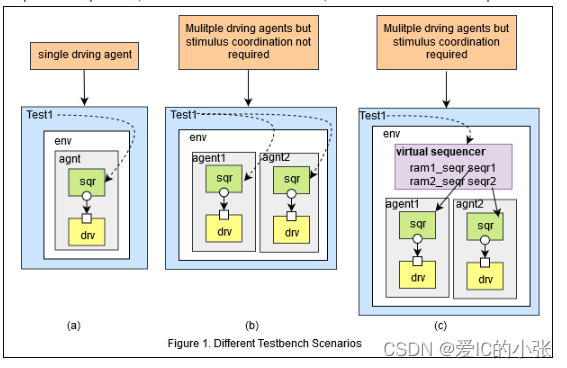
UVM中没有单独的virtual sequencer或virtual sequence类。他们只是现有UVM class的扩展。
class v_sequence extends uvm_sequence #(uvm_sequence_item);
…
…
endclass
class v_sequencer extends uvm_sequencer;
…
…
endclass
实现方式:
默认情况下,uvm_sequence类有一个名为m_sequencer的uvm_sequencer句柄。因此,这个句柄将出现在所有从uvm_sequence扩展的子类中。
当使用start方法从test case启动sequence时,该sequence中的m_sequencer将指向作为start方法参数传递的sequencer。在此操作之后,将执行sequence主体。
此m_sequencer用于连接virtual sequence和virtual sequencer。
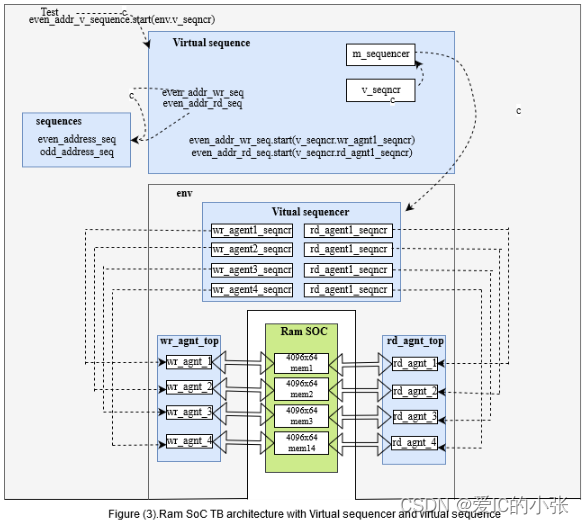
第一种实现方式: 在virtual sequencer 中利用对应的sequencer启动对应的sequence
- 通常我们在test case 中,将virtual sequencer 中的sub sequencer 进行连接,以使virtual sequencer 中的sub sequence 指向特定的实际sequencer:
function void base_test::build_phase(uvm_phase phase);
super.build_phase(phase);
env = my_env::type_id::create("env", this);
v_sqr = my_vsqr::type_id::create("v_sqr", this);
endfunction
function void base_test::connect_phase(uvm_phase phase);
super.connect_phase(phase);
v_sqr.p_my_sqr = env.i_agt.sqr;
v_sqr.p_bus_sqr = env.bus_agt.sqr;
endfunction
- 然后 virtual sequencer 中例化实际的sub sequencer
class my_vsqr extends uvm_sequencer;
my_sequencer p_my_sqr;
bus_sequencer p_bus_sqr;
function new(string name, uvm_component parent);
super.new(name, parent);
endfunction
`uvm_component_utils(my_vsqr)
endclass
- virtual sequence 中 例化实际生成激励的sub sequence,并利用 virtual sequencer中对应的实际sub sequencer启动对应的实际sub sequence:
class case0_vseq extends uvm_sequence;
`uvm_object_utils(case0_vseq)
`uvm_declare_p_sequencer(my_vsqr) //指定virtual sequence的m_sequencer 句柄为my_vsqr
function new(string name= "case0_vseq");
super.new(name);
endfunction
virtual task body();
case0_sequence dseq;
case0_bus_seq bseq;
if(starting_phase != null)
starting_phase.raise_objection(this);
bseq = case0_bus_seq::type_id::create("bseq");
bseq.start(p_sequencer.p_bus_sqr);
dseq = case0_sequence::type_id::create("dseq");
dseq.start(p_sequencer.p_my_sqr);
if(starting_phase != null)
starting_phase.drop_objection(this);
endtask
endclass
- virtual sequencer 是从environment类(示例中为env)构建的。它们包含所有物理sequencer的句柄。这些句柄指向其分层高级组件env的连接阶段中agent的物理sequencer。
virtual sequencer类将具有物理sequencer的句柄。
virtual sequencer中的sequencer句柄用于指向环境build phase构建阶段的物理sequencer。
wr_agent1_seqncr
.
.
wr_agent4_seqncr
rd_agent1_seqncr
.
.
rd_agent4_seqncr
这些句柄指向env连接阶段的实际或物理sequencer,也可以在test case中connect。
class ram_env extends uvm_env;
..
..
function void connect_phase(uvm_phase phase);
wr_agent1_seqncr =wr_agnt_top.wr_agnt1.sequencer;
.
.
wr_agent4_seqncr =wr_agnt_top.wr_agnt4.sequencer;
rd_agent1_seqncr =rd_agnt_top.rd_agnt1.sequencer;
.
.
rd_agent4_seqncr =rd_agnt_top.rd_agnt1.sequencer;
endfunction
endclass
- vrtual sequence
从test case构建vrtual sequence。此类包含:1. virtual sequencer类的句柄; 2. 所有物理sequencers的句柄; 3.所有sequences的句柄。
testc ase的start方法:1. 启动virtual sequence,而不是直接调用物理 sequence。2. 传递virtual sequencer的层次路径作为start方法的参数,而不是物理sequencer的路径。
virtual sequence具有物理sequencer和virtual sequencer的句柄。
sequence类中的m_sequencer将指向由test case中的start方法传递的sequencer。 - p_sequencer
sequence类里有一个uvm_sequencer_base类型m_sequencer指针,当sequence和sequencer关联后,m_sequencer会自动指向该sequencer,但通过m_sequencer不能直接使用seqr里的变量,否则会出现编译错误。只能使用cast强制向子类转换后,才能通过m_sequencer.xxx来访问该seqr内的xxx变量。
UVM引入p_sequencer,可以自动的实现上面所述的cast动作,从而可以在sequence中自由使用关联sequencer内的变量。
p_sequencer并不是UVM自动地在sequence的创建的,需要用户使用**`uvm_declare_p_sequencer宏声明,之后UVM会自动实现指向seqr及cast的动作。**
6.2 seq和driver之间传递的参数类型是否需要转换

7 寄存器模型

7.1 register model 简介
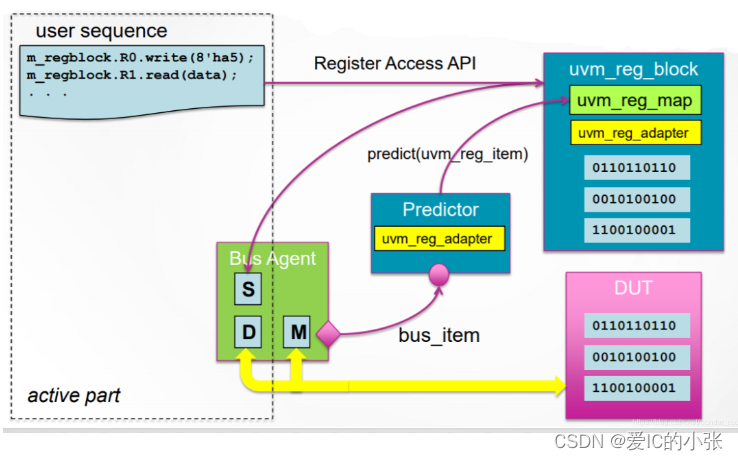
- UVM的寄存器模型是一组高级抽象的类,用来对DUT中具有地址映射的寄存器和存储器进行建模。 反映DUT中寄存器的各种特性,可以产生激励只有哦那个与DUT并进行寄存器功能检查。通过UVM的寄存器模型,可以简单高效的实现对DUT的寄存器进行前门或后门操作。它本身也提供了一些寄存器测试的sequence,方便用户直接使用。
- register model 使用一个中间变量 uvm_reg_bus_op 描述register 的访问信息,用户必须创建一个继承自uvm_reg_adapter的类,实现uvm_reg_bus_op与真正作用到具体dut上的transaction的互相转换。
- RAL:register abstraction layer
- uvm_reg_adapter 实现了bus driver需要的transaction和中间变量uvm_reg_bus_op之间的相互交换。
- 寄存器前门访问是依靠寄存器模型自动产生sequence,并发送给 bus driver完成。
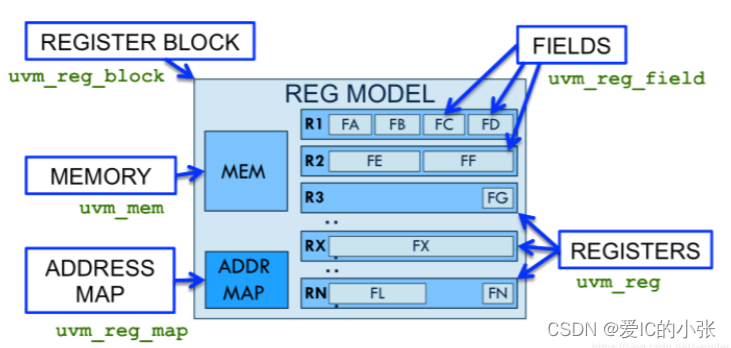
7.2 uvm 寄存器模型的层次结构
- uvm_reg_field 是寄存器模型的最小单位,和DUT的每个register里的bit filed对应。
- uvm_reg 和DUT 中每个 register 对应,其宽度一般和总线位宽一致,里面可以包含多个uvm_reg_field
- uvm_reg_block 包含uvm_reg,uvm_reg_block内也可包含其他低层次的reg_block。
reg_block里有含有uvm_reg_map类的对象default_map,进行地址映射,以及用来完成寄存器前后门访问操作。 - uvm_mem是对dut中memory进行建模使用的。
- uvm_reg_map: 每个寄存器在加入寄存器模型时都有其地址, uvm_reg_map就是存储这些地址, 并将其转换成可以访问的物理地址( 因为加入寄存器模型中的寄存器地址一般都是偏移地址, 而不是绝对地址) 。
当寄存器模型使用前门访问方式来实现读或写操作时, uvm_reg_map就会将地址转换成绝对地址, 启动一个读或写的sequence, 并将读或写的结果返回。
在每个reg_block内部, 至少有一个( 通常也只有一个) uvm_reg_map
- Synopsy VCS中自带的ralgen工具可以产生uvm 寄存器模型,具体使用方法可参考UVM Register
Abstraction Layer Generator User Guide(uvm_ralgen_ug.pdf)。
7.3 创建和使用寄存器模型
Step1: 对每个寄存器进行定义
class cfs_dut_reg_ctrl extends uvm_reg;
rand uvm_reg_field reserved; //reserved
rand uvm_reg_field enable; //control for enabling the DUT
`uvm_object_utils(cfs_dut_reg_config)
function new(string name = "cfs_dut_reg_config");
//specify the name of the register, its width in bits and if it has coverage
// 如对于一个16位的寄存器, 其中可能只使用了8位, 那么这里要填写的是16,
// 而不是8。 这个数字一般与系统总线的宽度一致。
// 1 means UVM_NO_COVERAGE
super.new(name, 32, 1);
endfunction
virtual function void build(); // 每一个派生自uvm_reg的类都有一个build,
// 这个build与uvm_component的build_phase并不一样, 它不会自动执行,
// 而需要手工调用,
reserved = uvm_reg_field::type_id::create("reserved");
//specify parent, width, lsb position, rights, volatility,
//reset value, has reset, is_rand, individually_accessible
reserved.configure(this, 31, 1, "RO", 0, 0, 1, 1, 1);
enable = uvm_reg_field::type_id::create("enable");
enable.configure(this, 1, 0, "RW", 0, 0, 1, 1, 1);
endfunction
endclass
-
在uvm_reg的new中,要将寄存器的宽度传入super.new()的第二个参数,super.new()的第三个参数是
uvm_coverage_model_e类型,用以设置寄存器是否参与加入覆盖率:
-
uvm_reg类有一个build函数,这个build和UVM_component的bulid_phase并不一样,并不会自动执行,需要手动调用。
-
要使用uvm_field的configure函数对各个field进行详细配置,它有9各参数:
enable.configure( .parent ( this ),
.size ( 3 ),
.lsb_pos ( 0 ),
.access ( "RW" ),
.volatile ( 0 ),
.reset ( 0 ),
.has_reset ( 1 ),
.is_rand ( 1 ),
.individually_accessible( 0 ) );
参数一是此域的父辈,也就是此域位于哪个寄存器中,即是this;
参数二是此域的宽度;
参数三是此域的最低位在整个寄存器的位置,从0开始计数;
参数四表示此字段的存取方式;
参数五表示是否是易失的(volatile),这个参数一般不会使用;
参数六表示此域上电复位后的默认值;
参数七表示此域时都有复位;
参数八表示这个域是否可以随机化;
参数九表示这个域是否可以单独存取。
Step2: 将寄存器放入register block容器中,并加入到对应的Address Map
class cfs_dut_reg_block extends uvm_reg_block;
`uvm_object_utils(cfs_dut_reg_block)
//Control register
rand cfs_dut_reg_ctrl ctrl;
//Status register
rand cfs_dut_reg_status status;
function new(string name = "cfs_dut_reg_block");
super.new(name, UVM_CVR_ALL);
ctrl = cfs_dut_reg_ctrl::type_id::create("ctrl");
status = cfs_dut_reg_status::type_id::create("status");
endfunction
virtual function void build();
default_map = create_map(“default_map”,0,4,UVM_BIG_ENDINA,0);
ctrl.configure(this, null, "");
ctrl.build();
default_map.add_reg(ctrl,`h10,"RW")
status.configure(this, null, "");
status.build();
default_map.add_reg(status,`h14,"RO")
endfunction
endclass
- reg block中也有build函数,在其中要做如下事情:
- 调用create_map函数完成default_map的实例化,
default_map = create_map(“default_map”,0,2,UVM_BIG_ENDINA,0);
create_map的第一个参数是名字,第二个参数是该reg block的基地址,第三个参数是寄存器所映射到的总线的宽度(单位是byte,不是bit),第四个参数是大小端,第五个参数表示该寄存器能否按byte寻址。
-
完成每个寄存器的build及configure操作
uvm_reg的configure函数原型:
function void configure ( uvm_reg_block blk_parent, uvm_reg_file regfile_parent = null, string hdl_path = "" )其第一个参数是所在reg block的指针,第二个参数是reg_file指针,第三个是寄存器后面访问路径—string类型。 -
把每个寄存器加入到default_map中。uvm_reg_map存有各个寄存器的地址信息。
default_map.add_reg(ctrl, `h10,"RW")
第一个参数是要添加的寄存器名,第二个是地址,第三个是寄存器的读写属性。
如果一个寄存器可以通过两个物理总线访问,则需要将其添加到多个address map中。
Step3: 创建Register Adapter
寄存器模型的前门操作都会通过sequence产生一个uvm_reg_bus_op类型的变量,他不能直接被bus sequencer和driver接受。需要定义一个继承自uvm_reg_adpater的adapter,来完成与bus transaction之间的转换,之后才能交给交给bus_sequencer和bus_driver,实现前门访问。 而从bus_driver返回的rsp,也需要由adapter转换成uvm_reg_bus_op类型变量,返回给寄存器模型,用来更新内部值。
在adapter中,要实现:
- reg2bus: 其作用是将uvm_reg_bus_op类型变量转换成bus_sequencer能够接受的transaction。
virtual function uvm_sequence_item reg2bus(const ref uvm_reg_bus_op rw);
- bus2reg: 其将收集到的transaction转换成寄存器模型使用的uvm_reg_bus_op类型变量,用以更新寄存器模型中相应寄存器的值。
virtual function void bus2reg(uvm_sequence_item bus_item, ref uvm_reg_bus_op rw);
class cfs_dut_reg_adapter extends uvm_reg_adapter;
`uvm_object_utils(cfs_dut_reg_adapter)
function new(string name = "cfs_dut_reg_adapter");
super.new(name);
endfunction
virtual function uvm_sequence_item reg2bus(const ref uvm_reg_bus_op rw);
acme_apb_drv_transfer transfer = acme_apb_drv_transfer::type_id::create("transfer");
if(rw.kind == UVM_WRITE) begin
transfer.direction = APB_WRITE;
end
else begin
transfer.direction = APB_READ;
end
transfer.data = rw.data;
transfer.address = rw.addr;
return transfer;
endfunction
virtual function void bus2reg(uvm_sequence_item bus_item, ref uvm_reg_bus_op rw);
acme_apb_mon_transfer transfer;
if($cast(transfer, bus_item)) begin
if(transfer.direction == APB_WRITE) begin
rw.kind = UVM_WRITE;
end
else begin
rw.kind = UVM_READ;
end
rw.addr = transfer.address;
rw.data = transfer.data;
rw.status = UVM_IS_OK;
end
else begin
`uvm_fatal(get_name(), $sformatf("Could not cast to acme_apb_mon_transfer: %s",
bus_item.get_type_name()))
end
endfunction
endclass
Step4: 顶层reg block对象的创建及使用
整个仿真平台只创建一个reg model对象,在其他地方使用指针调用。一般在test中创建顶层reg_block,及adapt和predictor.
在reg_block传完要调用其configure函数,配置后面访问路径。
// in base test class
...
irtual function void build_phase(uvm_phase phase);
super.build_phase(phase);
//create all the elements of the environment
reg_block = cfs_dut_reg_block::type_id::create("reg_block",this);
apb_agent = acme_apb_agent::type_id::create("apb_agent", this);
adapter = cfs_dut_reg_adapter::type_id::create("adapter");
predictor = uvm_reg_predictor#(acme_apb_mon_transfer)::type_id::create("predictor", this);
reg_block.configure(null,"");
reg_block.build();
reg_block.lock_model();
reg_block.reset("HARD");
endfunction
...
Step5: 将Address Map连接到Bus sequencer和Adapter
在test或env的connect phase中,调用default_map或其他用户自定义的address map对象中的set_sequencer方法, 并把前门操作的bus sequencer及adaptor作为参数传入。
virtual function void connect_phase(uvm_phase phase);
super.connect_phase(phase);
//required to start physical register accesses using the registers
reg_block.default_map.set_sequencer(apb_agent.sequencer, adapter);
predictor.map = reg_block.default_map;
predictor.adapter = adapter;
apb_agent.monitor.output_port.connect(predictor.bus_in);
endfunction
Step6: 在sequence或其他component中使用寄存器模型
- 在sequence中使用:
要先在对应的sequencer中定义一个顶层reg_block的指针,并指向base_test的reg_block对应,之后再sequence中调用p_sequencer访问,如:
p_sequencer.p_reg_block.enable.wirte(status,1,UVM_FRONTDOOR); // 前门访问 front-door 默认方式
p_sequencer.p_reg_block.enable.read(status,value,UVM_BACKDOOR);// 后门访问 back-door
7.4 寄存器访问方法
前门访问和后面访问的区别
- 前门访问是通过物理总线向dut发起寄存器访问操作,消耗仿真时间
- 后面操作不通过物理总线,不消耗仿真时间
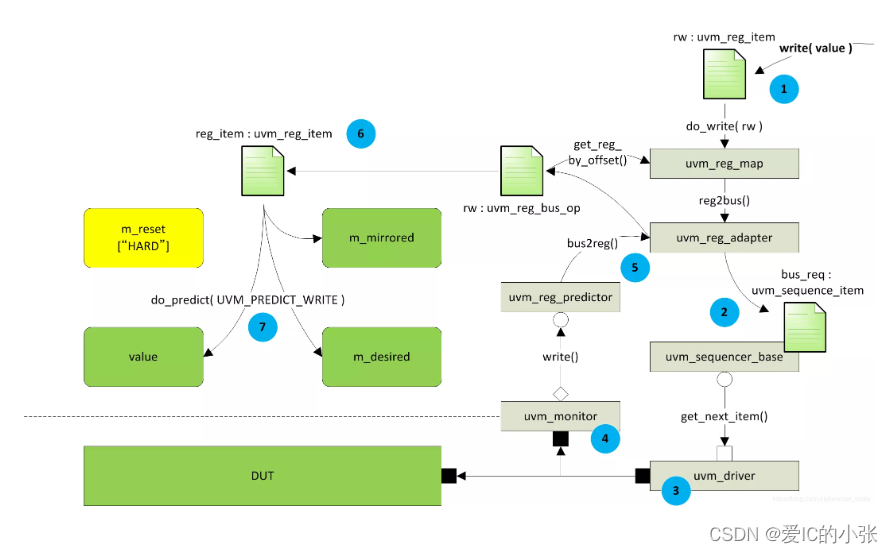
前门访问过程
以write为例:
- 当调用寄存器的write()任务后,产生uvm_reg_item类型的transaction:rw,之后调用uvm_reg::do_write()。
- 在uvm_reg_map中,调用reg_adapter.reg2bus将rw转换成bus driver对应的transaction。
- 把transaction交给sequencer,最终由bus driver驱动到对应的bus interface上。
- bus monitor在bus interface上检测到bus transaction 。
- reg_predictor会调用reg_adapter.bus2reg将该bus transaction转换成uvm_reg_item。
- 从driver中返回的req会转换成uvm_reg_item类型,如防止sequencer的response队列溢出,需要在adapter中设置provides_reponses.
- 寄存器模型根据返回的uvm_reg_item来更新寄存器的value,m_mirrored和m_desired三个值
7.5 应用实例
// -reset the register block
// -set all value of WR registers via uvm_reg::set()
// -update them via uvm_reg_block::update()
// -compare the register value via uvm_reg::mirror() with backdoor access
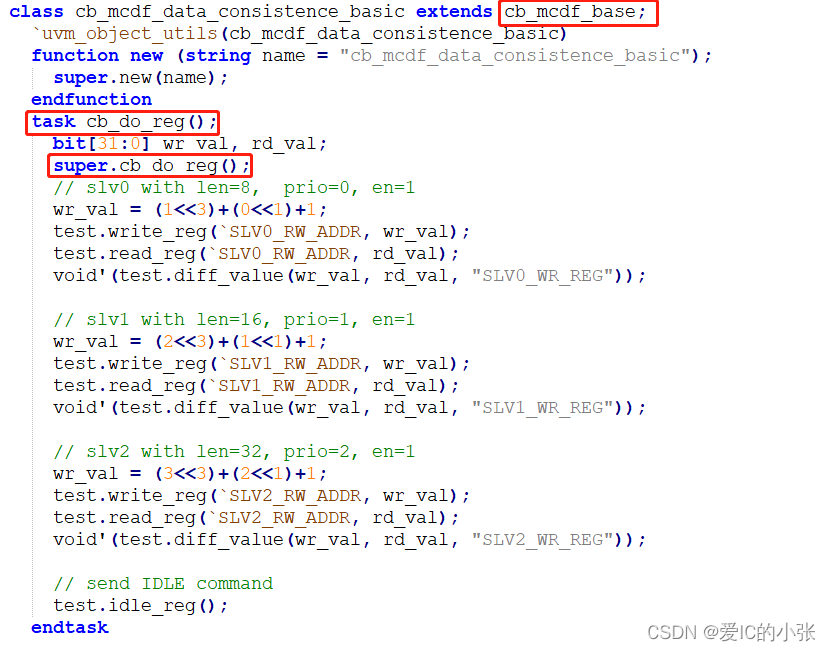
task do_reg();
bit[31:0] ch0_wr_val;
bit[31:0] ch1_wr_val;
bit[31:0] ch2_wr_val;
uvm_status_e status;
//reset the register block
rgm.reset();
//slv0 with len={4,8,16,32}, prio={[0:3]}, en={[0:1]}
ch0_wr_val = ($urandom_range(0,3)<<3)+($urandom_range(0,3)<<1)+$urandom_range(0,1);
ch1_wr_val = ($urandom_range(0,3)<<3)+($urandom_range(0,3)<<1)+$urandom_range(0,1);
ch2_wr_val = ($urandom_range(0,3)<<3)+($urandom_range(0,3)<<1)+$urandom_range(0,1);
//set all value of WR registers via uvm_reg::set()
rgm.chnl0_ctrl_reg.set(ch0_wr_val);
rgm.chnl1_ctrl_reg.set(ch1_wr_val);
rgm.chnl2_ctrl_reg.set(ch2_wr_val);
//update them via uvm_reg_block::update()
rgm.update(status);
//wait until the registers in DUT have been updated
#100ns;
//compare all of write value and read value
rgm.chnl0_ctrl_reg.mirror(status, UVM_CHECK, UVM_BACKDOOR);
rgm.chnl1_ctrl_reg.mirror(status, UVM_CHECK, UVM_BACKDOOR);
rgm.chnl2_ctrl_reg.mirror(status, UVM_CHECK, UVM_BACKDOOR);
rgm.mirror(status, UVM_CHECK, UVM_BACKDOOR);
// send IDLE command
`uvm_do_on(idle_reg_seq, p_sequencer.reg_sqr)
endtask

在virtual sequence里
task do_reg();
uvm_reg_hw_reset_seq reg_rst_seq = new();
uvm_reg_bit_bash_seq reg_bit_bash_seq = new();
uvm_reg_access_seq reg_acc_seq = new();
// wait reset asserted and release
@(negedge p_sequencer.intf.rstn);
@(posedge p_sequencer.intf.rstn);
`uvm_info("BLTINSEQ", "register reset sequence started", UVM_LOW)
rgm.reset(); // 先复位
reg_rst_seq.model = rgm; // 将rgm句柄赋给 reg_rst_seq
reg_rst_seq.start(p_sequencer.reg_sqr); // 挂载到对应的sequencer
`uvm_info("BLTINSEQ", "register reset sequence finished", UVM_LOW)
`uvm_info("BLTINSEQ", "register bit bash sequence started", UVM_LOW)
// reset hardware register and register model
p_sequencer.intf.rstn <= 'b0; // 先复位
repeat(5) @(posedge p_sequencer.intf.clk);
p_sequencer.intf.rstn <= 'b1;
rgm.reset(); // 先复位
reg_bit_bash_seq.model = rgm;
reg_bit_bash_seq.start(p_sequencer.reg_sqr);
`uvm_info("BLTINSEQ", "register bit bash sequence finished", UVM_LOW)
`uvm_info("BLTINSEQ", "register access sequence started", UVM_LOW)
// reset hardware register and register model
p_sequencer.intf.rstn <= 'b0;
repeat(5) @(posedge p_sequencer.intf.clk);
p_sequencer.intf.rstn <= 'b1;
rgm.reset();
reg_acc_seq.model = rgm;
reg_acc_seq.start(p_sequencer.reg_sqr);
`uvm_info("BLTINSEQ", "register access sequence finished", UVM_LOW)
endtask
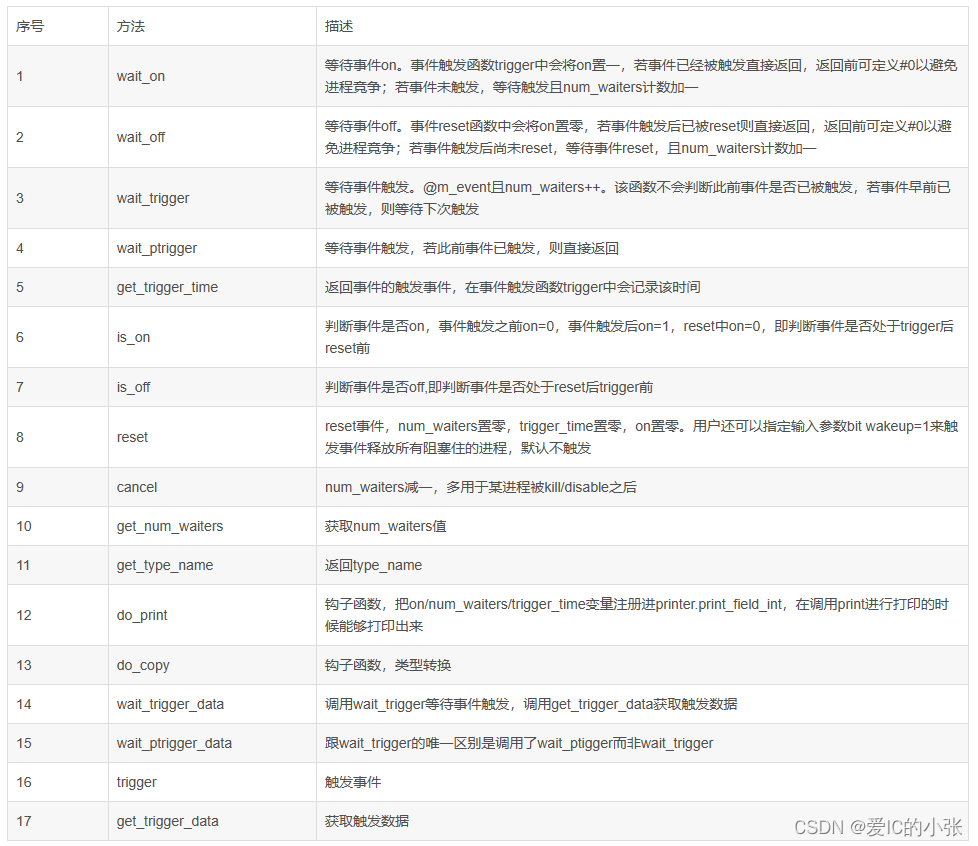
8 uvm_evnt 和SV event 对比
uvm_event的基础其实还是event,只不过event的触发和等待两个动作进行了很多扩展。
uvm_event和event的主要区别:
- event被->触发之后,会触发使用@等待该事件的对象;uvm_event通过trigger()来触发,会触发使用wait_trigger()等待的对象。如果要再次等待事件触发,event只需要再次用->来触发,而uvm_event需要先通过reset()方法重置初始状态,再使用trigger()来触发。
- event无法携带更多的信息,而uvm_event可以通过trigger(uvm_event data = null)的可选参数,将所要伴随触发的数据信息都写入到该触发事件中,而等待该事件的对象可以通过方法wait_trigger_data(output uvm_object data)来获取事件触发时写入的数据对象。这实际上是一个句柄的传递,句柄的类型是uvm_object,也就是说传递的对象句柄得是uvm_object类型的。那如何传递非uvm_object类型的对象呢,首先这个对象必须是uvm_object的子类或者子类的子类,然后才能将其句柄作为trigger()方法的参数,然后wait_trigger ()的参数必须是uvm_object类型的,可以用一个uvm_object类型的tmp作为参数传递句柄,然后使用$cast赋值给目标类型句柄。
- event触发时无法直接触发回调函数,而uvm_event可以通过add_callback(uvm_event_callback cb, bit append = 1)函数来添加回调函数。
- event无法直接获取等待它的进程数目,而uvm_event不但可以通过get_num_waiters()来获取等待它的进程数目。
uvm_evnt: 通过全局资源池对象(唯一的),在环境中任何一个地方的组件都可以从资源池中获取共同的对象,这就避免了组件之间的互相依赖。
8.1 uvm event的用法
关于uvm_event的使用,最大的好处是摆脱了system Verilog中对event使用时必须按照路径引用的办法, 而在uvm中只需要将 uvm_event放到 uvm_event_pool中即可,这在进行移植验证环境时,是非常便利的事情,并且我们在使用时,也不需要关心event的路径,只需要从event_pool中get到这个event就可以了。比如说,我们在tc里的main_phase中发完包之后,一般都会设置drain_time来等带dut将数据吐完,我们就可以在scoreboard中设置一个uvm_event等待socreboard接收完数据,然后再通过uvm_event通知tc,触发main_phase中的uvm_event.trigger,结束仿真。
通过 my_event = uvm_event_pool::get_global(“my_event”) 这种方法将my_event 注册到event_pool中;在set_component中将uvm_event放到event_pool中,并设置好触发条件,在get_component中,从uvm_event_pool中取出来,通过wait_trigger捕获这次事件。(这里用component只是作为例子使用,实际上在object中也可以这么做)。
class my_component extends uvm_comopnent;
...
...
...
uvm_event my_event ;
`uvm_component_utils(my_component)
function void build_phase(uvm_phase phase);
super.build_phase(phase);
my_event = uvm_event_pool::get_global("my_event");
endfunction
task main_phase(uvm_phase phase);
...
...
...
set_trigger();
...
...
...
endtask
task set_trigger();
my_event.trigger();
endtask
endclass
class get_component extends uvm_comopnent;
...
...
...
uvm_event get_my_event ;
`uvm_component_utils(get_component)
function void build_phase(uvm_phase phase);
super.build_phase(phase);
get_my_event = uvm_event_pool::get_global("my_event");
endfunction
task main_phase(uvm_phase phase);
...
...
...
set_trigger();
...
...
...
endtask
task set_trigger();
...
get_my_event.wait_trigger();
...
endtask
endclass
对于uvm_event_pool的使用,也可以用下面的方法进行替换:
events_pool = uvm_event_pool::get_global_pool();
my_event = events_pool.get("my_event");
9 sequence、sequencer、driver关系
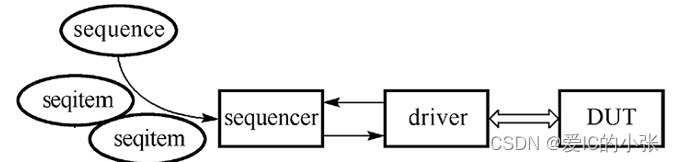
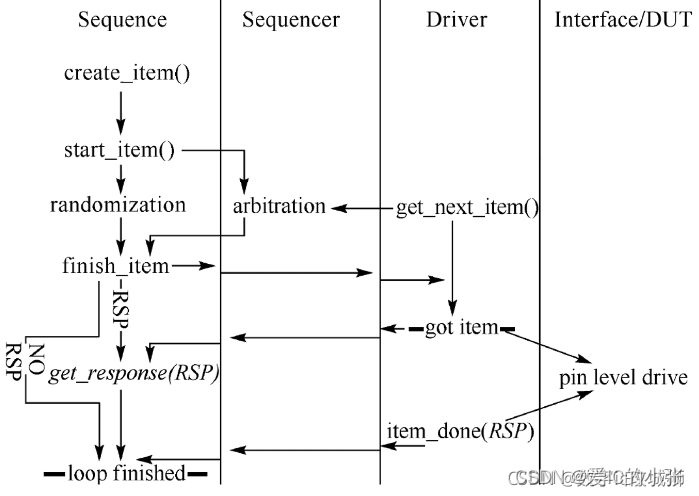
- sequence产生目标数量的sequence item,并通过随机化使每一个sequence item对象的数据内容不同
- sequence item经过sequencer流向driver
- driver将每一个流入的item(req)进行数据解析,按照与DUT的接口协议写入,形成有效激励
- 如有需要,driver解析完一个item后,会将最后的状态信息写回item,再返回给sequencer(rsp),最终抵达sequence。这样sequence就可以得知driver和DUT的互动状态。
- 对于一个标准的写操作,driver不但需要按照时序依次驱动地址总线、命令码总线、数据总线,还应该等待从端的返回信号和状态值,这样才算完成了一次数据写传输。
- 明确划分职责,sequence应该只负责产生item的内容,driver则控制item消化的方式和时序。
- item的生成和传送并不表示最终的接口驱动时序,决定这一点的还包括sequencer和driver
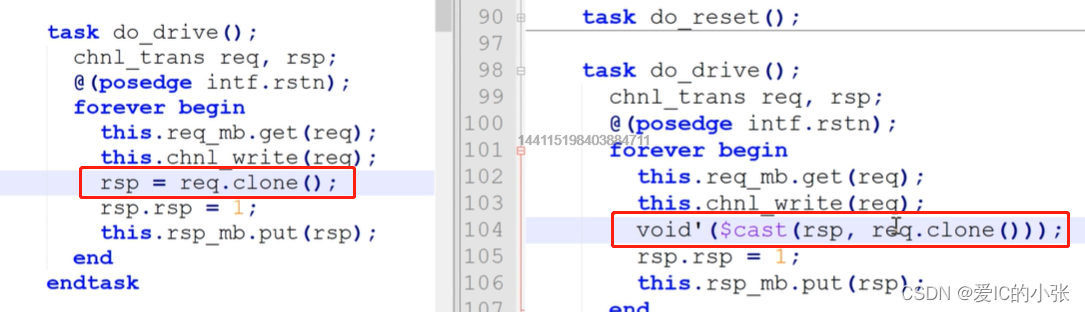
UVM 的clone,返回的是uvm_sequence_item 类型,uvm_object类型, 遵循的是父类函数类型,返回的是父类句柄,创建的是子类对象,因此子类rsp指向父类req.clone()时,需要类型转换。
SV 的clone 返回的是chnl_trans 类型, 可以直接赋值;
//driver
virtual task get_and_drive();
forever begin
seq_item_port.get_next_item(req);
`uvm_info(get_type_name(), "sequencer got next item", UVM_HIGH)
drive_transfer(req);
void'($cast(rsp, req.clone()));
rsp.set_sequence_id(req.get_sequence_id());
rsp.set_transaction_id(req.get_transaction_id());
seq_item_port.item_done(rsp);
`uvm_info(get_type_name(), "sequencer item_done_triggered", UVM_HIGH)
end
endtask
在多个 sequence 同时向 sequencer 发送 item 时,就需要有 ID 信息表明该 item 从哪个sequence 来, 这个 ID 信息在 sequence 创建 item 时就赋值了,而在到达 driver 以后, 这个 ID 也可以用来跟踪它的 sequence 信息,
• 建议在 driver 中通过 clone()方式单独创建 response item, 保证 request item 和 response item 两个对象的独立性。 也许有的用户为了 “ 简便 “,使用 request item 后直接修改它的数据并作为要返回给 sequence 的 response item。这么做看来似乎节能环保,但实际一上可能埋下隐患, 一方面延长了本来应该丢进垃圾桶的 request item 寿命, 另一方面无法对 request item 原始生成数据做出有效记录。
为了便于item传输,UVM专门定义了匹配的TLM端口供sequencer和driver使用:
uvm_seq_item_pull_port #(type REQ=int, type RSP=REQ)
uvm_seq_item_pull_export #(type REQ=int, type RSP=REQ)
uvm_seq_item_pull_imp #(type REQ=int, type RSP=REQ, type imp=int)
由于driver是请求发起端,所以在driver 一侧例化了下面两种端口:
uvm_seq_item_pull_port #(REP, RSP) seq_item_port
uvm_analysis_port #(RSP) rsp_port
而sequencer 一侧则为请求的响应端,在sequencer 一侧例化了对应的两种端口:
uvm_seq_item_pull_imp #(REQ, RSP, this_type) seq_item_export
uvm_analysis_export #(RSP) rsp_export
匹配的第 一对 TLM 端口 完成item 的完整传送,即driver::seq_ item_port和sequencer::seq_ item_ export。
• task get_next_item(output REQ req_arg): 采取blocking的方式等待从sequence获取下一个item。
• task try_next_item(output REQ req_arg): 采取nonblocking 的方式从 sequencer获取item, 如果立即返回的结果req_arg为null, 则表示sequence还没有准备好。
• function void item_done(input RSP rsp_arg=null): 用来通知sequence当前的sequence item已经消化完毕,可以选择性地传递RSP参数,返回状态值。
• task wait_for_sequences(): 等待当前的sequence直到产生下一个有效的item。
• function bit has_do_available(): 如果当前的 sequence 准备好而且可以获取下一个有效的 item, 则返回 I, 否则返回 0。
• function void put_response(input RSP rsp_arg): 采取 nonblocking 方式发送 response, 如果成功返回1, 否则返回0。
• task get(output REQ req_ arg): 采用 get 方式获取 item。
• task peek(output REQ req_arg): 采用 peek 方式获取 item。
• task put(input RSP rsp_arg): 采取 blocking 方式将 response 发送回 sequence。
uvm_sequencer 与 uvm_driver 实际上都是参数化的类:
uvm_sequencer #(type REQ=uvm_sequence_item, RSP=REQ)
uvm_driver #(type REQ=uvm_sequence_item, RSP=REQ)
9.1 uvm_sequence和uvm_sequence_item都继承于uvm_object, 不同于uvm_component只应当在build阶段作为UVM环境的不动产进行创建和配置,它们可以在任何阶段创建。
- 由于无法判定环境在run阶段什么时间点创建sequence并将其挂载(attach)到sequencer上,所以无法通过UVM环境结构或phase机制来识别sequence的运行阶段
- 由于uvm_object独立于build阶段之外,使得用户可以有选择地、动态的在合适时间点挂载所需要的sequence和item
- 由于uvm_sequence和uvm_sequence_item并不处于UVM结构中,所以顶层在做配置时,无法按照层次关系直接配置到sequence中
- 如果sequence一旦活动起来,它必须挂载到一个sequencer上,这样sequence可以依赖于sequencer的结构关系,间接通过sequencer来获取顶层的配置和更多的信息
9.2 组件之间可以通过TLM进行通信,如sequencer和driver;sequence和组件之间(如sequencer)则通过uvm_event进行通信;
sequence和sequence_item是uvm_object类,因此无法通过config_db进行配置,需要先配置sequencer,再传输给sequence进行配置。
9.3 将sequencer作为管道 设立在sequence和driver之间的原因 是以下两个特点:
- sequencer 作为一个组件,可以通过TLM端口与driver发送item对象
- sequencer 在面向多个并行sequence时,有充分的仲裁机制来合理分配和传送item,进而实现并行item数据传送至driver的测试场景
9.4 sqr和driver之间 数据传送机制 用的是get 而不是put。
如果是put模式,那么应该是sequencer将数据put至driver;而get模式则是driver从sequencer获取数据。之所以选择get模式,有以下考虑:
- get模式下,当item从sequence产生,穿过sequencer到达driver时,我们就可以结束该传输(如果不需要返回值的话);而put模式,则必须时sequencer将item传送至driver,同时必须收到返回值才可以进行下一次传输,这在效率上就有所不同。
- 如果让sequencer拥有仲裁特性,可以使多个sequence同时挂载到sequencer上,那么get模式更具有优势。因为driver作为initiator,一旦发起get请求,它会通过sequencer,继而获得仲裁后的item。
四、 uvm 问题汇总
1. 组件各个phase方法中的super.xx_phase(phase)究竟在做什么?
一般都写,子类继承父类方法,
具体来说:
- uvm_agent 的build_phase 写是为了获取上次对它 的is_active成员的配置,也可以显示调用uvm_config_db#(T)::get();
- uvm_sequencer的 connect_phase 写是为了实现内部fifo到sequencer的TLM端口连接,
- 在其run_phase()中调用父类方法,又是为了能够调用上层给指定的default sequence。
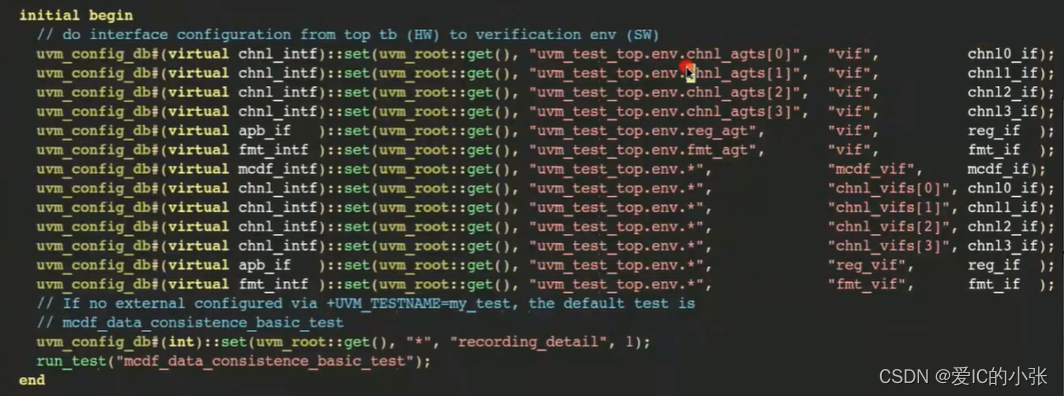
2. virtual interface用那种方式传递适合
tb.sv里set vi如他了interface
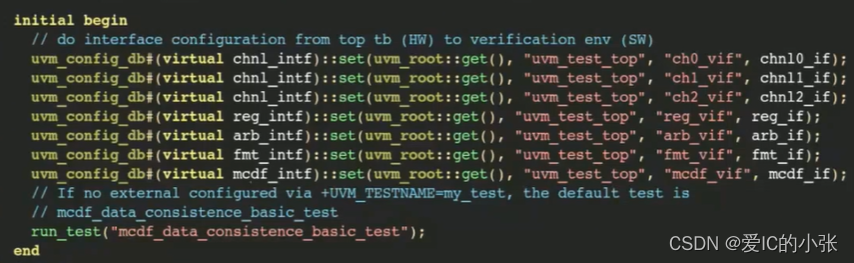
base_test里的
3. 如何对寄存器的某些域做读写操作?
利用寄存器模型对寄存器进行读写访问时,往往对整个寄存器进行读写的机会不多,更多的修改某个单独的域,意味着利用uvm_reg::{write,read}的机会不多,更多的是uvm_reg_field::{set, get}.
- 对于某一个寄存器的若干的域进行写操作:
rgm.reset(); // 如果在上电前 没有访问过寄存器,都要reset 这会把 每一个reg field 的desired value和mirror的value都修改成和DUT一致。 //reset the register block
rgm.REGx,FIELD1.set(data1); // 做完这个动作后,会set该reg_field的desired vlaue,其他reg_field的值会保留 , 可能会导致reg_field 的 desired value和mirror value不一致,
rgm.REGx.update(status); // desired value和mirror value不一致,会主动触发一个前门访问操作,会执行一次写操作; status表示总线会有反馈给我们读的成功或者失败,有没有x值。

- 获取某一个寄存器的某些域的值:
rgm.REGx.mirror(status); .// 先将DUT的值更新到mirror value,
data = rgm.REGx.FIELD1.get() // get rgm里的 desired value
想要利用好uvm_reg_field::{set, get} 的操作,就一定需要注意及时调用uvm_reg::{mirror,update},确保寄存器值进行读写,继而保证寄存器模型内的寄存器值与设计中的寄存器保持一致。
4. force和$hdl_xmr_force,uvm_hdl_force等命令的区别

5. 为什么TLM端口的例化放在new函数里边,而mailbox的例化放在build_phase里边?
端口 uvm_void -> uvm_port_base -> uvm_analysis_imp;
例化TLM端口不能用factory create,只能用new
6. 前门访问需要通过总线实现,是不是利用前门读取寄存器的时候reg_bus_op在adapter里转换成bus_transaction ,adapter发送到sequencer了。
driver发送给DUT是带有address的data 向量
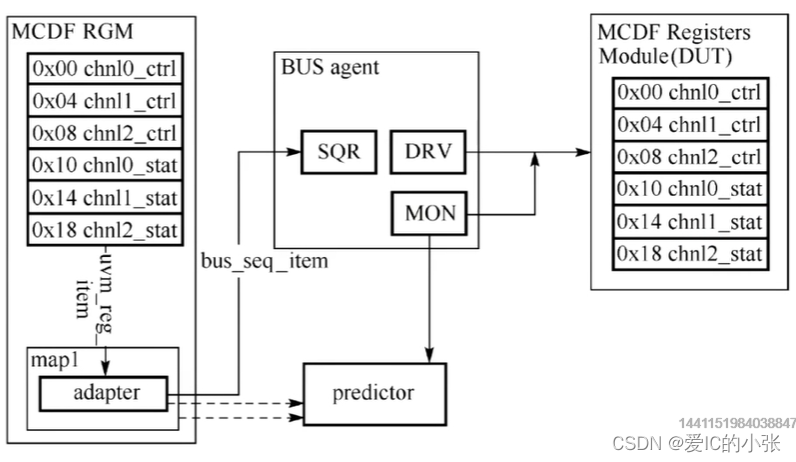
7. 将monitor把 predictor连接上的作用
则 predictor会自动把monitor检测到的DUT给到adapter,更新对应的寄存器的值mirror value和desired value,目的保证DUT actual value和mirror value、desired value三者一致。
8. DUT actual value和mirror value、desired value以及与update和mirror的方法调用关系
mirror value : 是用来在rgm中反映 DUT register 的actual value的,一般会保持一致,在monitor与predictor连接的情况下,给这个reg做set actual value 时,会自动更新 mirror value;
desired value: 一般用的是set方法
update方法: 该方法可以用rgm、reg、reg_field类型update,将desired value更新到DUT中,使其与actual value一致。(update会检查模型中的期望值和镜像值,如果两者不相等,那么将期望值更新到DUT中,并且更新镜像值。)
mirror方法: 在 UVM_NO_CHECK 时,保持mirror_value与DUT中的值相等;在UVM_CHECK时,检查模型中的镜像值与DUT中的寄存器值是否
9. UVM——寄存器模型相关的一些函数
- Set\get\get_mirrored_value\get_reset 分别为:设置模型中寄存器的期望值,不会改变DUT中这个寄存器的值。\返回模型中寄存器的期望值,而不是DUT中的寄存器值。\返回模型中寄存器的镜像值\返回模型中寄存器的镜像值
- Predict 更新模型中的镜像值。新的镜像值通过value参数传入。如果想要更新镜像值又不对DUT进行操作,要用UVM_PREDICT_DIRECT。
- write、read、peek和poke在完成对DUT的读写之后也会调用这个函数,更新镜像值。
- 当寄存器随机化后,期望值会被随机,但是镜像值不变,之后调用update任务,可以更新DUT中的寄存器值。无论是uvm_reg,还是uvm_field、uvm_block,都是支持randomize()。
但是一个field能够被随机化,需要:1. 在filed的configure第八个参数设为1. 2. filed为rand类型。3. filed的读写类型为可写的。 - update将模型中的期望值更新到DUT中。(update会检查模型中的期望值和镜像值,如果两者不相等,那么将期望值更新到DUT中,并且更新镜像值。update与mirror操作相反。)
- mirror读DUT中寄存器的值,与update操作相反。 mirror有两种应用场景:一是在仿真中不断调用,但此时是UVM_NO_CHECK,保证镜像值与DUT中的值相等;二是在仿真结束的时候调用,这时是UVM_CHECK检查模型中的镜像值与DUT中的寄存器值是否一致.
- write模仿DUT的行为,通过前门或者后门方式向DUT中写入寄存器值,会产生总线transaction。并且调用predict更新镜像值。
- read 模仿DUT的行为,通过前门或者后门方式读取DUT中寄存器的值,并更新镜像值,会产生总线transaction。
- peek 通过后门访问方式读取寄存器的值,不关心DUT的行为,即使寄存器的读写类型是不能读,也可以将值读出来。
- poke 通过后门访问方式写入寄存器的值,不关心DUT的行为,即使寄存器的读写类型是不能写,也可以将值写进去。
10. 寄存器中rand描述符作用
分层随机由regblock里的uvm_reg到uvm_reg_field 的 desired value
先随机后可以把desired value单独set成一个值,这样就可以可约束的情况下随机,再update
class mcdf_rgm extends uvm_reg_block;
`uvm_object_utils(mcdf_rgm)
rand ctrl_reg chnl0_ctrl_reg; // 随机化mcdf_rgm 时,会随机句柄ctrl_reg 的chnl0_ctrl_reg对象
rand ctrl_reg chnl1_ctrl_reg;
rand ctrl_reg chnl2_ctrl_reg;
rand stat_reg chnl0_stat_reg;
rand stat_reg chnl1_stat_reg;
rand stat_reg chnl2_stat_reg;
..
endclass
class ctrl_reg extends uvm_reg;
`uvm_object_utils(ctrl_reg)
rand uvm_reg_field pkt_len; // 进一步随机化 uvm_reg_field 的value
rand uvm_reg_field prio_level;
rand uvm_reg_field chnl_en;
..
endclass
11. 寄存器模型中覆盖组采样选用的变量
mirror value和desired value 都是local型的,sample实际选择的合适时,就能选到合适的值。
12. m_sequencer 和 p_sequencer 的区别以及用法
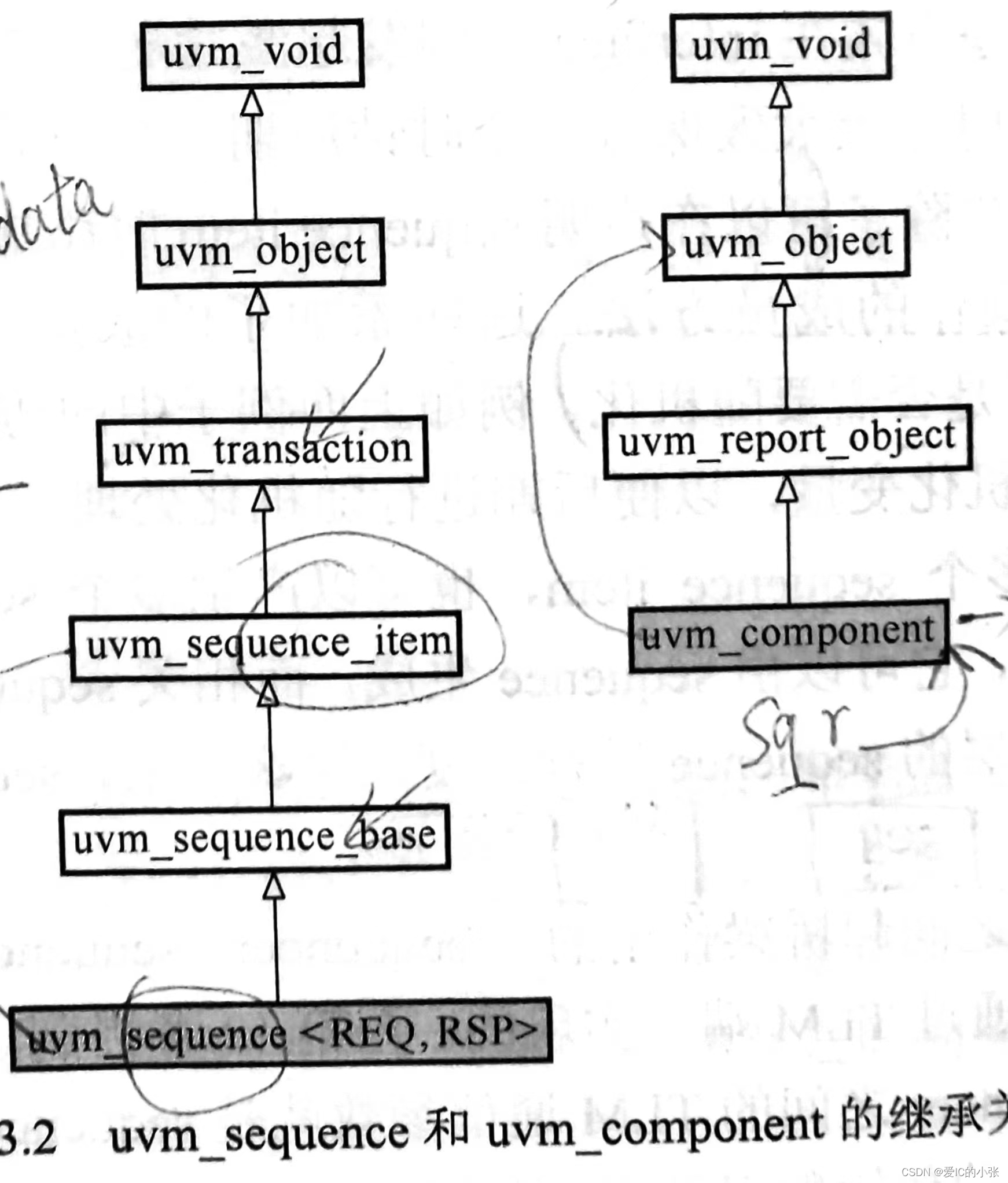
- m_sequencer 是继承于 uvm_transaction 的 uvm_sequence_item 中,定义为 uvm_sequencer_base 类型的变量, 即是个定义在 sequence 里的 sequencer。
- p_sequencer 一般通过宏 `uvm_declare_p_sequencer 声明,并完成转化
- 论大小: uvm_sequence >> uvm_sequence_item >> uvm_transaction, 在sequence里发送的可以是sequence、sequence_item、transaction;
由于用宏uvm_do_on_pri_with(SEQ_OR_ITEM, SEQR, PRIORITY, CONSTRAINTS)需要显式的指定哪个sqr发送transaction, 默认的sqr就是seq启动时为其指定的 sqr,seq将这个sqr的指针放在其成员变量m_sqr中。等价于宏uvm_do(transaction, this.m_sequencer)。
如何在seq的body任务中得到sqr里变量的值?
如果用seq的m_sequencer索引变量,这样会编译错误,因为m_sequencer 是定义为 uvm_sequencer_base 类型的变量,而不是sqr类型。
seq在sqr上启动,在seq中通过cast转换将m_sequencer装成sqr类型,然后再引用sqr的变量:
virtual task body();
my_sequencer x_sequencer;
…
$cast(x_sequencer, m_sequencer);
repeat (10) begin
`uvm_do_with(m_trans, {m_trans.dmac == x_sequencer.dmac;
m_trans.smac == x_sequencer.smac;})
end
…
endtask
上述过程稍显麻烦。在实际的验证平台中,用到sequencer中成员变量的情况非常多。UVM考虑到这种情况,内建了一个宏:
uvm_declare_p_sequencer(SEQUENCER)。
这个宏的本质是声明了一个SEQUENCER类型的成员变量,如在定义sequence时,使用此宏声明sequencer的类型:
//my_case0.sv
3 class case0_sequence extends uvm_sequence #(my_transaction);
4 my_transaction m_trans;
5 `uvm_object_utils(case0_sequence)
6 `uvm_declare_p_sequencer(my_sequencer) //note
…
24 endclass
则相当于声明了如下的成员变量:
class case0_sequence extends uvm_sequence #(my_transaction);
my_sequencer p_sequencer;
…
endclass
UVM之后会自动将m_sequencer通过cast转换成p_sequencer。
因此在sequence中可以直接使用成员变量p_sequencer来引用dmac和smac:
//my_case0.sv
3 class case0_sequence extends uvm_sequence #(my_transaction);
…
12 virtual task body();
…
15 repeat (10) begin
16 `uvm_do_with(m_trans, {m_trans.dmac == p_sequencer.dmac;
17 m_trans.smac == p_sequencer.smac;})
18 end
…
22 endtask
23
24 endclass
因为uvm_declare_p_sequence的实质是在base sequence中声明了一个成员变量p_sequencer。当其他的sequence从base sequence派生时,p_sequencer依然是新的sequence的成员变量,所以无须再声明一次了。
12.0 为什么transaction不继承于uvm_transaction,而要从uvm_sequence_item派生?
uvm_sequence_item是用户定义的事务的基类,同时也是uvm_sequence的基类。提供了使用强大sequence机制的基本功能。
12.1 sequence的启动方式
starting_phase何时不为null?
1.手工启动sequence时为starting_phase赋值

2.将此sequence作为sequencer的某动态运行phase的default_phase时,starting_phase不为null。

通俗一点,设置默认default_sequence时,会自动赋值phase给starting_phase,如果使用`uvm_do宏将sequence作为参数,则starting_phase为null。

















 924
924

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









