







 文章详细介绍了自注意力(self-attention)的概念,工作流程,以及在词性标注等任务中遇到的问题。自注意力通过考虑整个序列的输入来解决单个词的多义性问题,并讨论了其与传统注意力机制的区别,以及如何通过矩阵操作解决sequence长度和并行计算问题,但详细的矩阵操作将在后续章节中阐述。
文章详细介绍了自注意力(self-attention)的概念,工作流程,以及在词性标注等任务中遇到的问题。自注意力通过考虑整个序列的输入来解决单个词的多义性问题,并讨论了其与传统注意力机制的区别,以及如何通过矩阵操作解决sequence长度和并行计算问题,但详细的矩阵操作将在后续章节中阐述。
自然语言处理三-自注意力 self attention
自注意力是什么?
在了解自注意力之前,需要先了解注意力,这部分在上篇文章[【自然语言处理-二-attention注意力 是什么】介绍过了。
如果用一句简单的话来概括,就是指在输出的时候,需要关注的输入的哪一部分,以及需要关注的比重大概是多少,比如翻译hello,world这句话,翻译你的时候,对于输入的hello更关注一些。
这种注意力的模型在人工智能界被抽象成了下面这个样子:
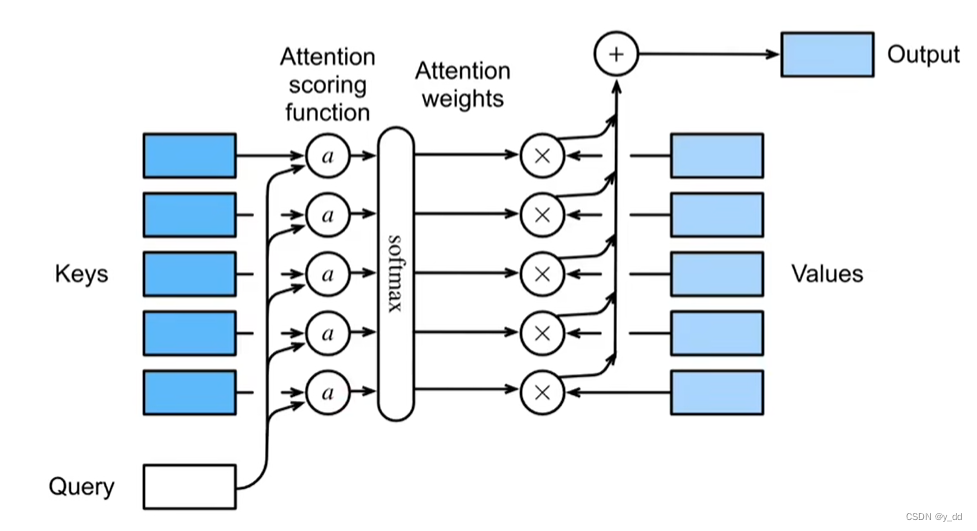
模型中就有三个重要的向量,Query Keys和Values,简称Q K V,Q和K用于产生注意力的分数,而Value 与注意力分数矩阵做处理,产生输出。
按照上面这个抽象模型,我们在[【自然语言处理-二-attention注意力 是什么】,Q和K和V又分别是那些个呢?
1.Q和K分别是编码器中的输入乘上了相应的参数矩阵获取。
2.V是解码器的输入乘上了响应的矩阵参数。
需要注意的一点是,上面所列2点,获取注意力分数的操作可能不一定是矩阵的乘法操作。
可以发现,这里的Q K V的来源(生成Q K V矩阵的来源)是不同的,特殊一点的情况是,当 Q K V 来源于同一个输入的时候,我们就叫自注意力模型。
自注意力模型出现的原因是什么?
它的出现一定是解决了注意力模型或者其他模型无法解决的问题。那么就要来说说,之前的模型在处理具体问题的时候,有哪些难以克服的问题呢?
下面用一个实际的下游任务“词性标注”来举例
词性标注
比如有一句话I saw a saw。对这句话进行词性标注。如果我们的模型的网咯结构是全连接层,来处理这个问题
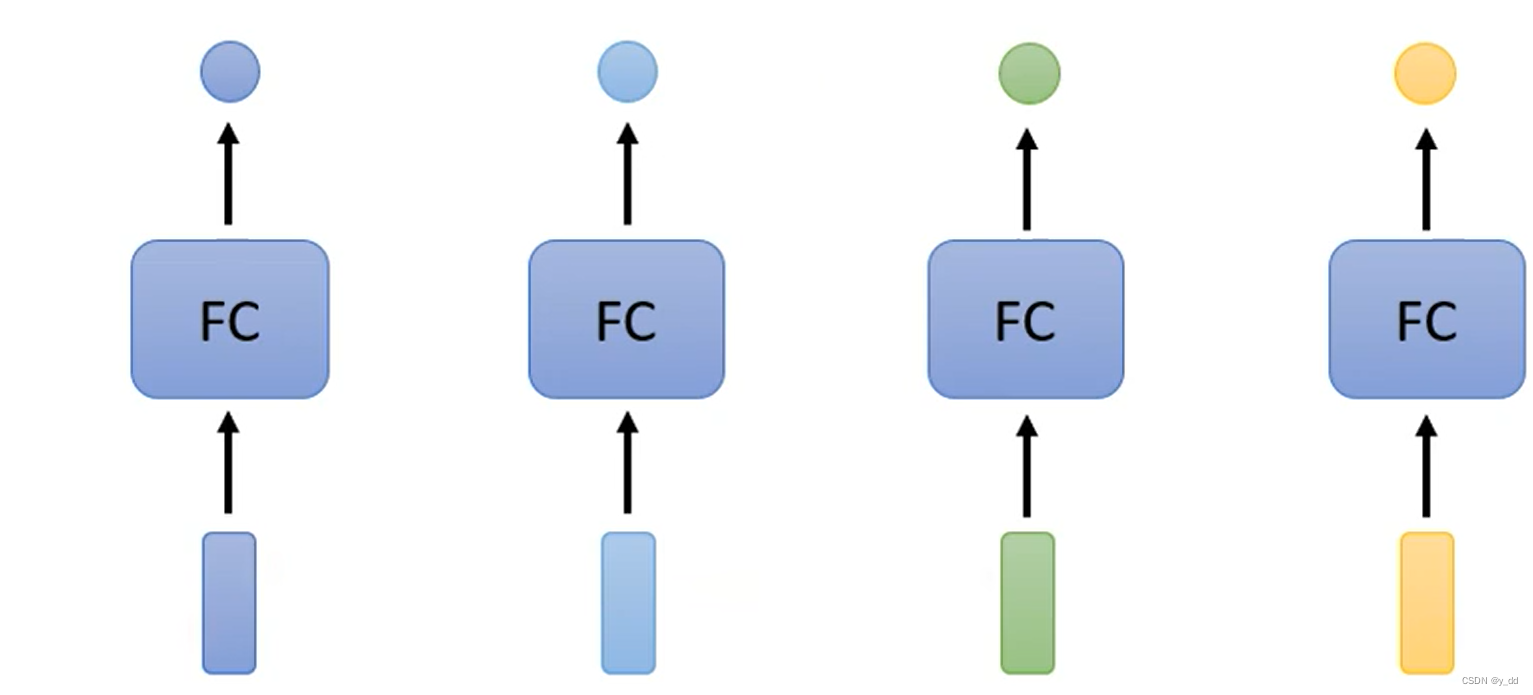
ps:其中的FC是fully connected的简写
问题
这时候会有一个问题,那就是saw这个词在这个句子里是两个词性不同的词,但是对于这个模型来说,同样的输入输出肯定是相同的输出。
解决方法1-扩展window,引用上下文
上面的怎么解决呢?出现这样的原因,是因为没有考虑上下文,于是我们做了改进,输入不再是单独的每个词,是一个包含了上下文的短句。
改进后的模型如下:
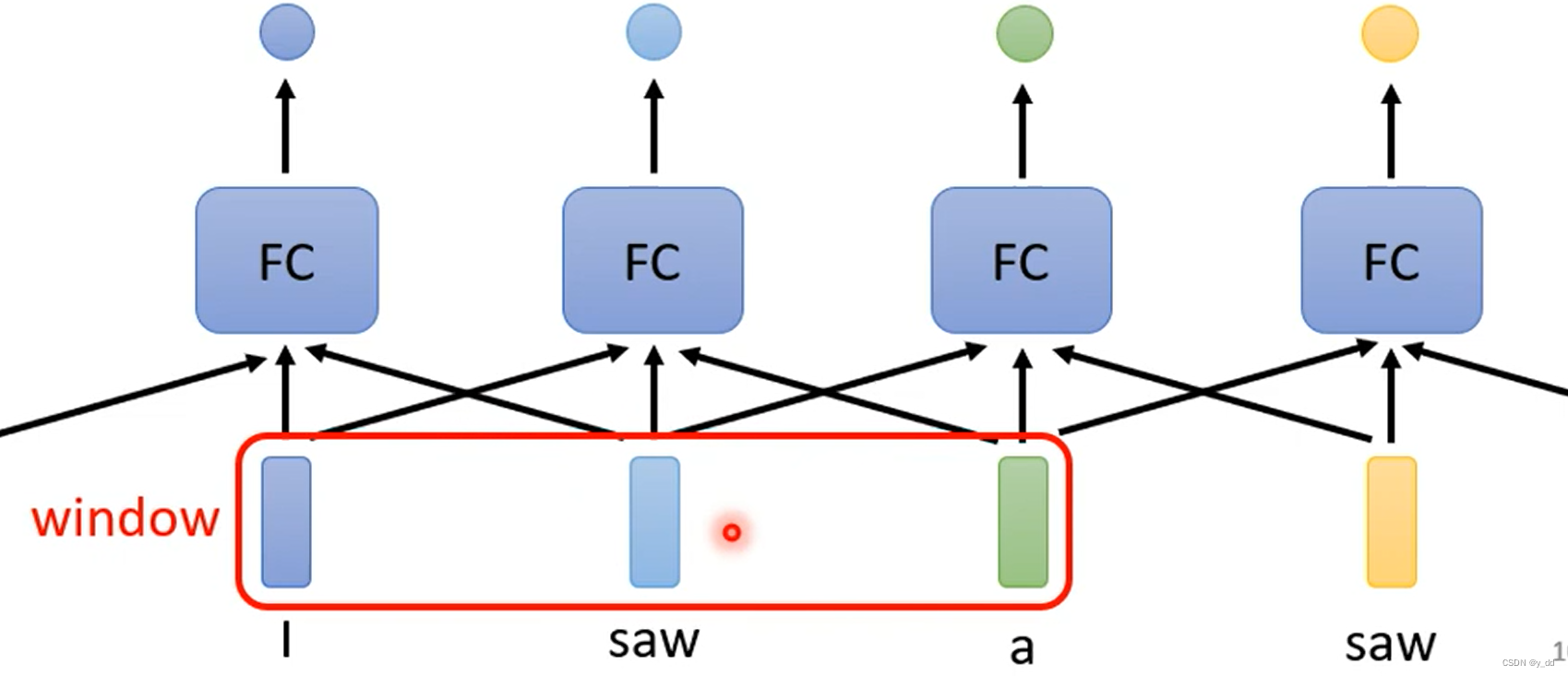
这样可以解决现在的问题,但是又带来了另外一个问题,那就是这个上下文的窗口window的大小到底应该是多少?
最直观的想法就是说把整个sequence的长度作为window的大小不就解决了.
但是我们的句子可长可短,这种情况必须要统计训练资料里面最长的sequnce长度,另外全连接层的参数会极度扩张,不仅是运算量增加,还会导致过拟合,测试集上效果不佳。
解决方法2-运用seq2seq架构
这时候又有人说,这不正是上节课所讲的注意力的应用么,我们用seq2seq + rnn来解决这个问题
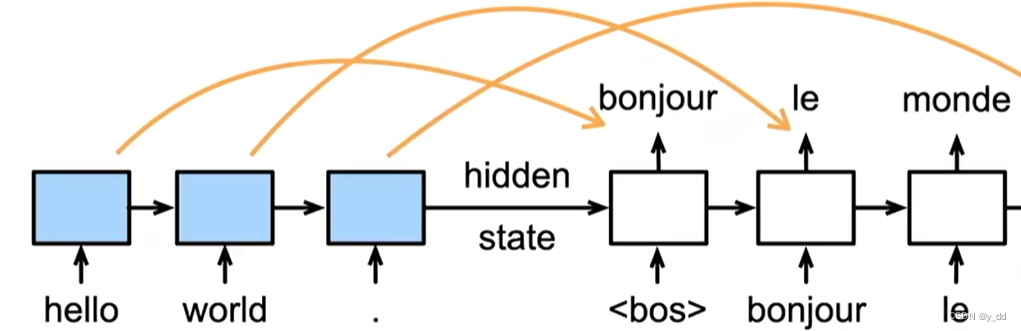
seq2seq的模型中,可以记住上下文,在解码器中就可以使用这些记忆,在此基础上再加上注意力不就很完美的解决了上下文的问题了么?
这个模型在上节课最后我们也说过,有它难以解决的问题 如下所述
新问题来了:参数量增加、无法并行的顽疾
运用seq2seq架构虽然可以解决部分记忆力的问题,但是还有很多问题:
-
1.参数量增多。seq2seq的架构会增加注意力参数矩阵,且随着输入的长度而增加。
2.无法并行,seq2seq的架构必须得先产生上一个时间步的输入,在计算下一个时间步的输出,也就说是有依赖关系的,无法实现并行计算,在今天的大模型的计算来说,这也算是一个致命的缺陷。
3.记忆力实际并不全,因为seq2seq架构的记忆力来自于最后一个隐藏层的输出,不能代表所有输入的信息。
基于上面种种问题,就引出了自注意力,那么自注意力的模型究竟是怎么实现的,又是如何解决这些问题的呢?
自注意力self attention模型的工作流程
还是以文章开篇的词性识别为例,self attention的运转是这样的:
- self attention会处理整个输入sequence语句的向量,然后每个input vector输出对应的向量。这些向量是考虑了整个sequece的输入(这也是记忆力的由来)。
- 将这些考虑了整个sequence的输出向量,作为FC的输入,然后再做后续的处理。
这个过程如下:
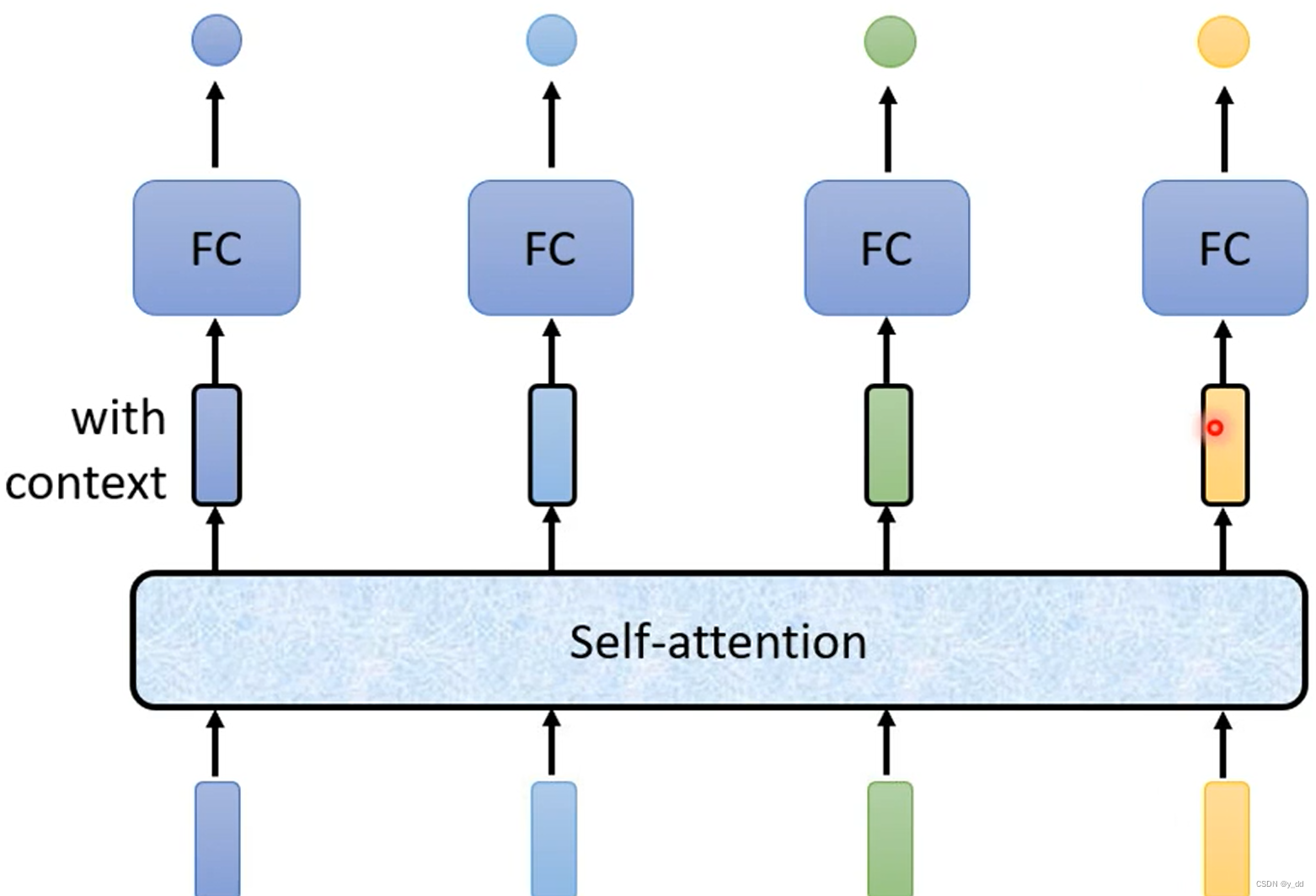
这个过程是不是很简单? 当然self attention和FC是可以嵌套多层的。那么这个self attention具体是怎么实现的呢?
atttention的实现
从上面也可以看出我们要实现的是这样一个目标:
输入一排向量,输出一排向量,且输出的向量要考虑了这一排的输入向量,这可以用下面这个图来表示
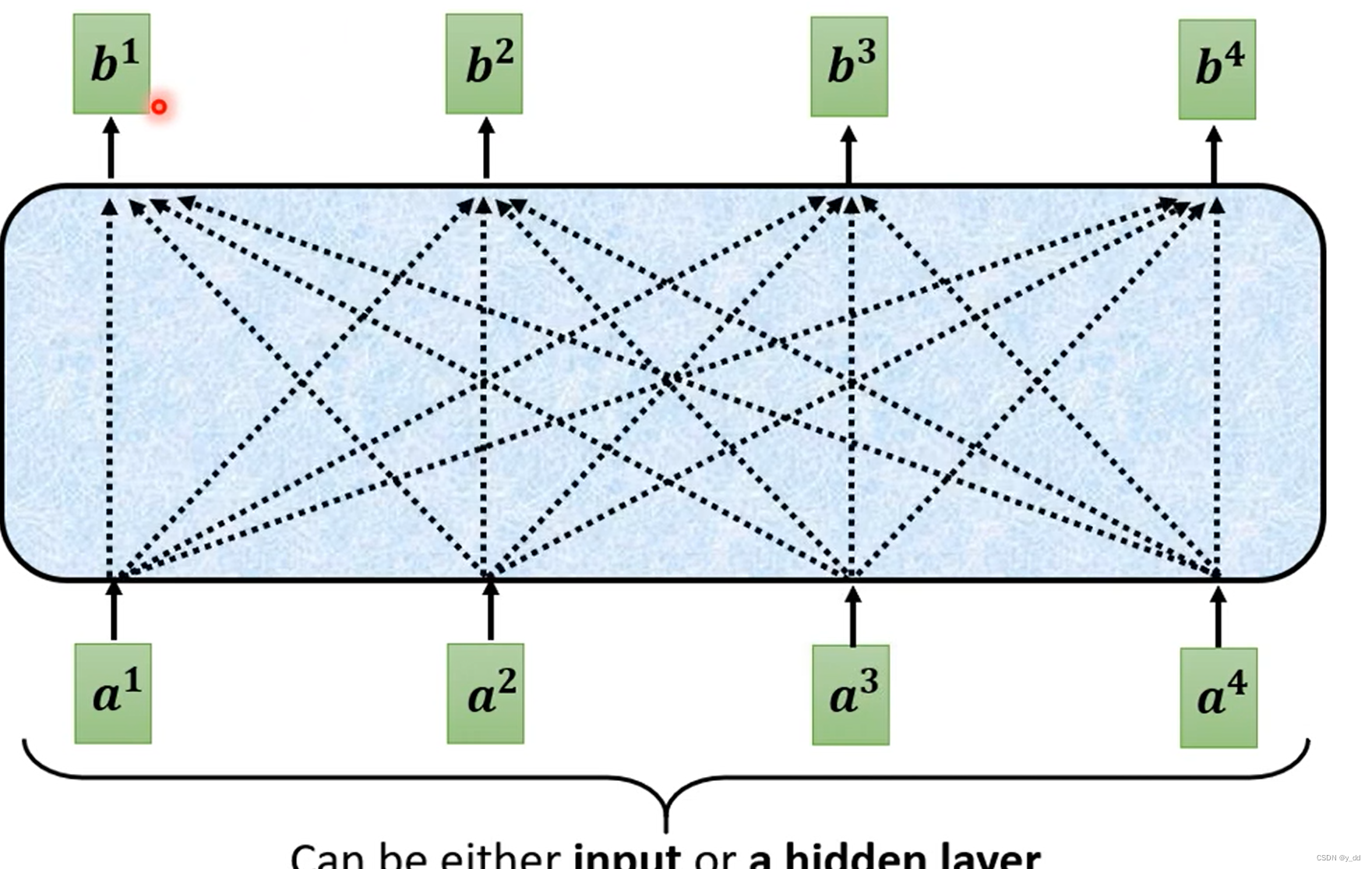
那么我们最重要的探讨就是**怎么从a1…到an,产生b1**呢?
这个问题的实质就是要解决从找到a1…到an的相关性,生成bi
如何找到向量之间的相关性
找到a1与其他的an的这些向量的相关性,这个相关性的分数我们记为 α。这个方法有很多种,下面是最常用的两种 Dot-product和Additive。
Dot-product
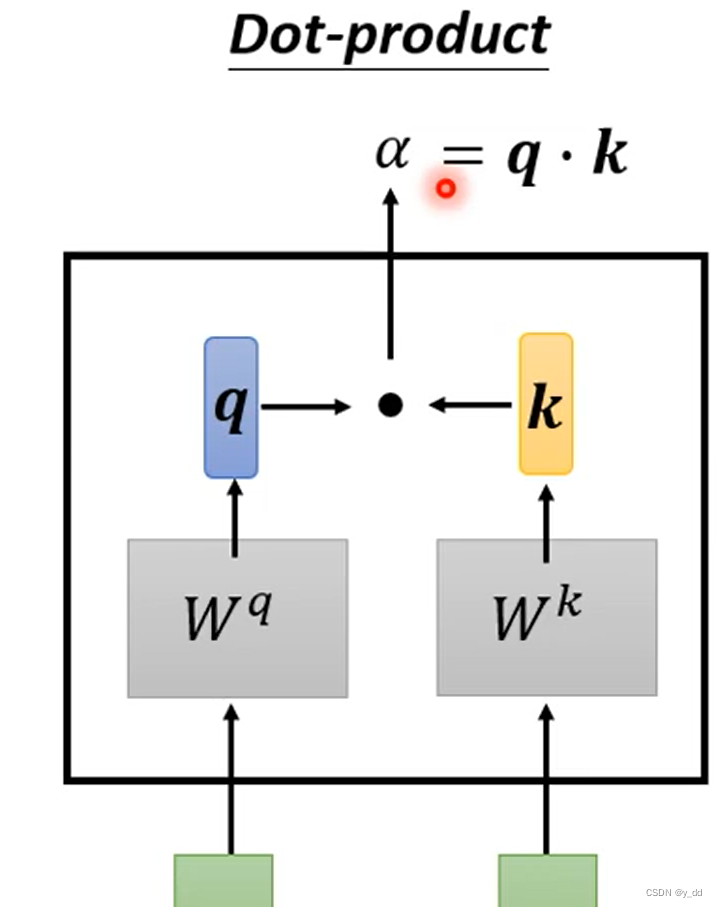
把输入各自乘上一个矩阵Wq和Wk , 然后做dot-product,得到α。
Additive
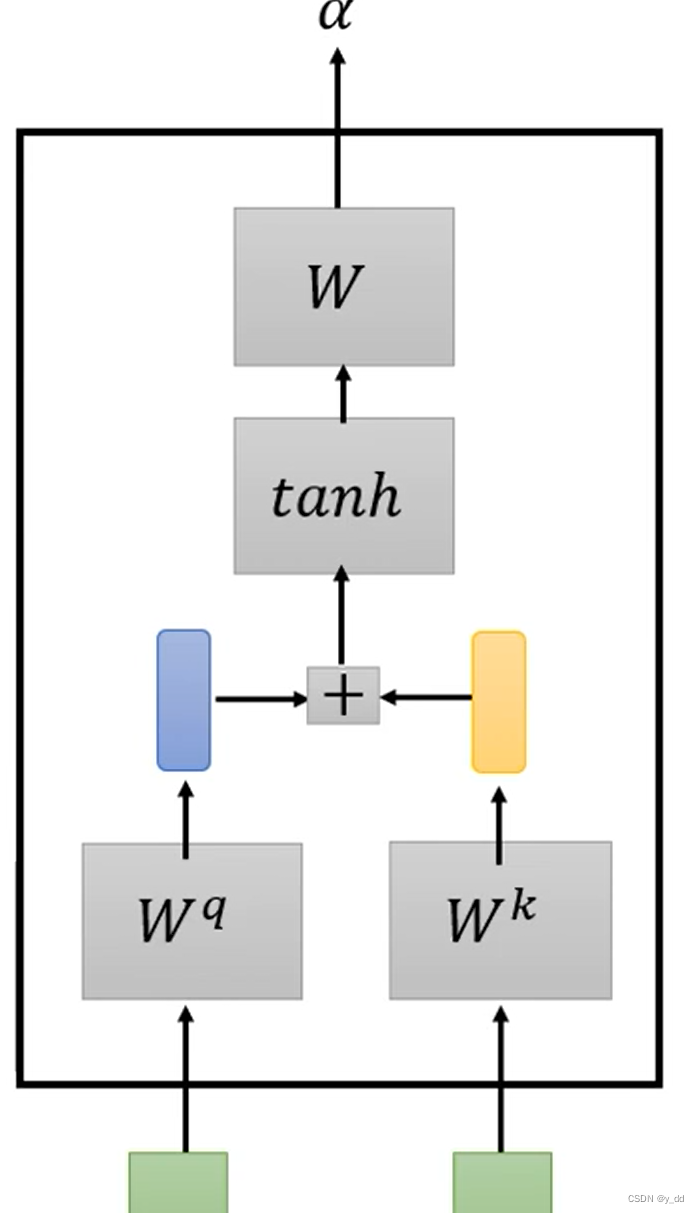
与上面类似,但是复杂一些,q和k不是直接做点乘,而是connect后又做tanh,再经过一个矩阵变换,获取α.
由于二者最终效果相差不多,本文以计算更为简单的Dot-product为例,怎么计算注意力分数α
相关性(attention分数)的具体计算方法
根据上述的Dot-product的方式,计算attention score
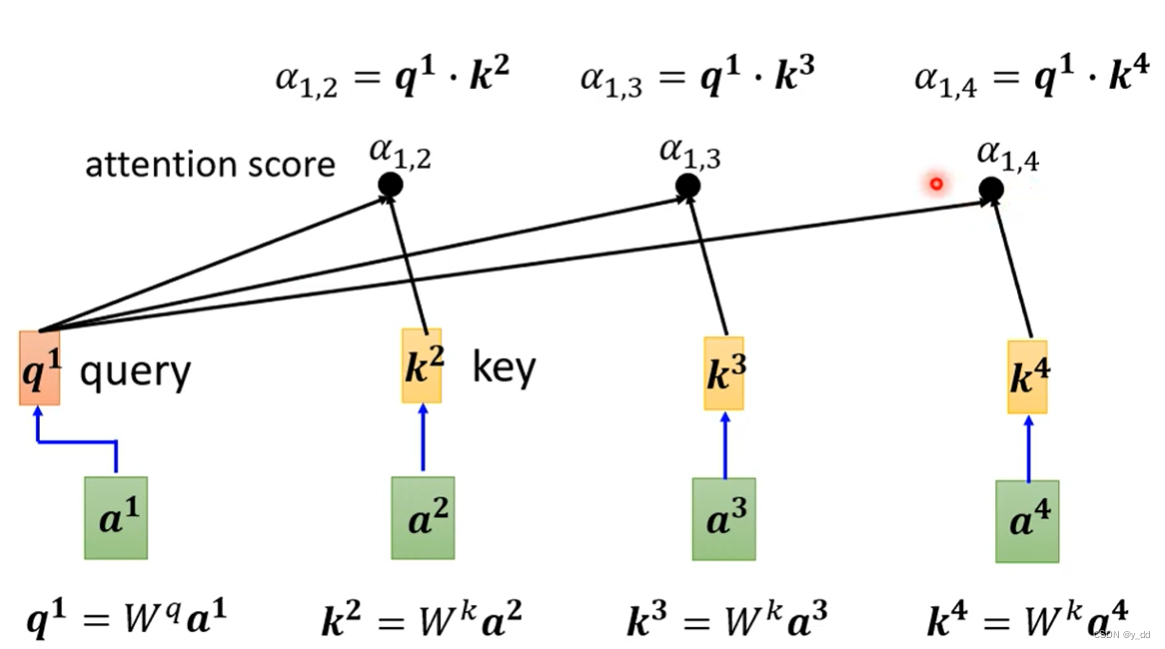
注: a1到a4 可能是模型的输入,也可能是隐藏层的输出,下文简化为输入。
首先是获取q k v矩阵:
查询q1:a1乘上矩阵Wq
ki:ai乘上矩阵Wk
vi:ai乘上矩阵Wv
然后执行下述:
-
q和每一个k 做dot-product,得到注意力分数,实际的应用,在获取注意力的时候,也会获取对其本身ai的注意力(也就是q要和每一个ai生成的k,包括生成q的这个输入am,生成的km)
-
做softmax(这个其实也可以换成RELU等等操作,不是固定的)上面这个四个步骤就最终如下:
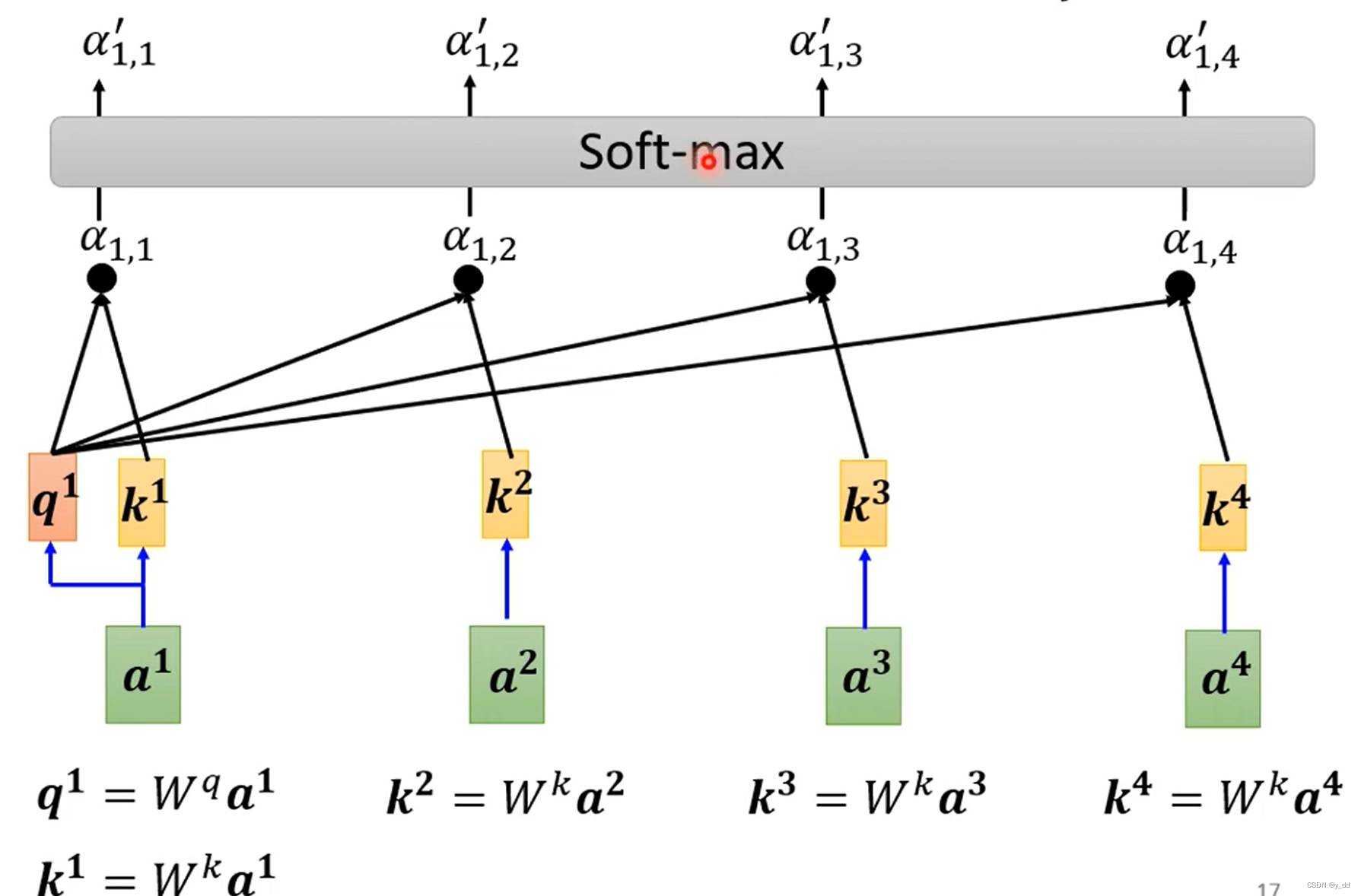
-
b1的计算 。 softmax后的注意力分数 乘上 vi的和
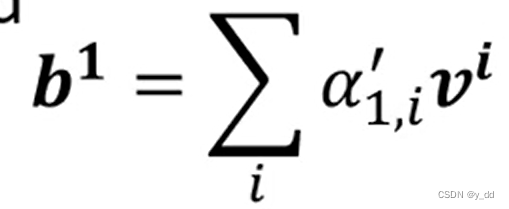
然后依次计算其他bi,attention层的输出就计算完毕
计算完attention层后的结果,作为FC的输入
上述计算完attention层后,可以嵌套多层attention fc,一直到模型结束
atttention 到底是如何解决sequence长度以及并行等问题的呢?
本篇幅太长了,这部分我们会在下一篇文档《 自然语言处理四-从矩阵操作角度看 自注意self attention》中讲解,下一篇文章,将从矩阵操作的角度看self attention是如何实现的,看完矩阵操作就会明白自注意力如何解决本文档上面的问题。















 4185
4185











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









