






这里写自定义目录标题
https://arxiv.org/pdf/2503.14182
https://github.com/fudan-zvg/BridgeAD
摘要
端到端自动驾驶在可微分框架中统一了多项任务,使得以规划为导向的优化成为可能,并吸引了越来越多的关注。现有方法通过密集的鸟瞰图(BEV)特征或查询稀疏记忆库来聚合历史信息,这些方法大多遵循从检测任务中演化而来的范式。
这些范式在运动规划中使用历史信息时存在问题:要么忽略了多步规划的特性,要么无法对多步时间预测/规划的需求进行有效对齐。基于“未来是过去的延续”的理念,我们提出了 BridgeAD 框架,它将运动和规划查询重构为多步查询,从而区分每个未来时间步的查询。
这种设计使得历史预测和规划能被有效地应用到系统的不同部分中,根据时间步划分,从而同时提升感知和运动规划性能。具体来说,当前帧的历史查询会整合进感知模块,而未来帧的查询则与运动规划模块相结合。
通过这种方式,我们在每一个时间步上都融合历史信息,弥合过去与未来之间的鸿沟,从而提升端到端自动驾驶系统整体的连贯性与精度。在 nuScenes 数据集上的大量实验(包括 open-loop 和 closed-loop 设置)表明,BridgeAD 达到了当前最先进的性能水平。
引言
近年来,自动驾驶技术发展迅速。传统系统通常采用模块化的方法,将任务划分为感知、预测和规划,从而简化每个模块的任务,但却中断了信息的流动,可能导致系统整体性能下降。
端到端方法将这些任务整合在一起,支持以规划为导向的优化,并提高系统一致性,因此受到了越来越多的关注。
目前大多数端到端方法源自检测任务,主要采用两类方法来利用时间信息:一种是密集方法,通过聚合历史 BEV 特征;另一种是稀疏方法,通过查询记忆库来利用历史查询。然而,这些方法通常会忽略运动规划中对历史信息的使用或处理不当,无法满足多步预测的需求。
为此,我们提出了 BridgeAD 框架,通过结合历史预测和规划来增强端到端自动驾驶系统。它将运动与规划查询解耦为多步时间查询,分别应用于感知和规划模块,确保不同时间步之间的协同一致性。
BridgeAD 的贡献点
(i) 将运动和规划查询表示为多步查询,在查询级别上区分未来每一个时间步;
(ii) 提出了 BridgeAD 框架,利用历史信息对当前帧和未来帧分别进行感知和规划,提升整个端到端系统的连贯性;
(iii) 在 nuScenes 数据集上的大量实验验证了我们方法在 open-loop 和 closed-loop 设置下均达到了 SOTA(最优)性能。
相关工作(Related Work)
感知(Perception):
感知任务从原始传感器数据中提取有意义的信息,包括 3D 检测、多目标跟踪和在线映射。许多方法提取 BEV 表征来增强 2D 图像中的深度感知,还有些采用稀疏记忆机制聚合历史信息。
运动预测(Motion Prediction):
运动预测任务致力于预测交通参与者的多模态未来轨迹。部分方法采用基于查询的结构,另一些方法则引入历史轨迹数据以增强准确性。VP3D 等工作支持基于图像和高精地图的联合预测。
规划(Planning):
规划任务分为基于规则的方法和学习方法。近期一些方法尝试将感知、预测与规划整合到统一框架中,例如 UniAD 和 VAD。SparseDrive 等方法采用稀疏场景表示来支持规划,但对历史信息的融合还不够充分。而我们的 BridgeAD 是首个深入集成该思路的端到端设计。
方法(Methodology)
3.1 框架总览
BridgeAD 框架由以下模块构成:
**图像编码器:**提取多视角图像的空间特征;
**历史增强感知模块:**采用稀疏查询机制,融合历史信息;
**历史增强运动规划模块:**包括多步预测模块和交互模块;
**多步运动和规划查询缓存 Step-Level
Mot2Plan Interaction Module:**用于缓存过去 K 帧的历史查询信息(FIFO机制)。
3.2 多步运动与规划查询设计
我们将运动和规划分别建模为多步查询:
历史运动查询表示为:
Q
motion
∈
R
N
a
×
M
mot
×
T
mot
×
C
Q_{\text{motion}} \in \mathbb{R}^{N_a \times M_{\text{mot}} \times T_{\text{mot}} \times C}
Qmotion∈RNa×Mmot×Tmot×C
历史规划查询表示为:
Q
plan
∈
R
M
plan
×
T
plan
×
C
Q_{\text{plan}} \in \mathbb{R}^{M_{\text{plan}} \times T_{\text{plan}} \times C}
Qplan∈RMplan×Tplan×C
每个query对应一条路径,
T
m
o
t
T_{mot}
Tmot未来预测的次数,
M
p
l
a
n
M_{plan}
Mplan和
T
p
l
a
n
T_{plan}
Tplan表示规划模式的数目和未来规划的步数。轨迹和规划的历史K帧的queries储存在缓存队列,使用FIFO先进先出的机制,新帧信息被加入后,最老帧的信息会被出去,如图2a.
3.3 历史增强感知(History-enhanced Perception)
检测、跟踪与在线映射(Detection, tracking, and online mapping)。给定多视角图像Nimg3N*W ,其中表示Nimg相机数量,图像编码器、首先从多个视角图像中提取多尺度视觉特征,表示为 𝐹。这些特征随后用于感知模块。
感知模块的关键组件包括 3D 物体检测、跟踪和在线映射。我们遵循稀疏范式 [34, 47, 51],用于感知子任务。在目标检测中,查询表示为一组 anchor 查询
𝑄
o
b
j
𝑄_{obj}
Qobj,anchor 框
𝐵
o
b
j
∈
𝑅
𝐵_{obj}∈𝑅
Bobj∈R,每个框由如下参数表示:
x
,
y
,
z
,
l
n
(
w
)
,
l
n
(
h
)
,
l
n
(
l
)
,
s
i
n
(
θ
)
,
c
o
s
(
θ
)
,
v
x
,
v
y
,
v
z
{x,y,z,ln(w),ln(h),ln(l),sin(\theta),cos(\theta),v_x,v_y,v_z}
x,y,z,ln(w),ln(h),ln(l),sin(θ),cos(θ),vx,vy,vz
我们采用多层注意力解码器 [11, 50, 67] 来细化目标框和查询。每一层将视觉特征 𝐹、目标查询 𝑄obj和 anchor 框
𝐵
o
b
j
𝐵_{obj}
Bobj作为输入,并输出分类分数和坐标偏移,用于目标检测模块。
在跟踪任务中,我们采用 Lin 等人 [35] 的 ID 分配过程,将每个目标分配一个唯一的 ID。在在线地图构建方面,我们采用向量化表示 [26, 31, 47],将实例表示为点集合,并使用结构化语义图表示,以实现地图构建。
在图2(b), Historical Mot2Det Fusion Module集合了历史的预测,从历史缓存的K帧的结果中获取出当前帧的motion query。历史的运动query
𝑄
m
2
d
𝑄_{m2d}
Qm2d和物体的query
𝑄
o
b
j
𝑄_{obj}
Qobj的注意力机制如下:
Q
obj
=
CrossAttn
(
Q
=
Q
obj
,
K
=
V
=
Q
m2d
)
Q_{\text{obj}} = \text{CrossAttn}(Q = Q_{\text{obj}}, K = V = Q_{\text{m2d}})
Qobj=CrossAttn(Q=Qobj,K=V=Qm2d)
3.4 历史增强运动规划(History-enhanced Motion Planning)
在从感知模块获得目标查询和运动查询后,这些查询与地图查询及相互之间通过注意力机制进行交互。然后,这些查询被送入运动规划模块,用于预测周围目标的轨迹,并规划自车的运动路径。是 agent 数量。这种设计方式为历史信息提供了明确的结构化输入路径,使得后续模块更容易利用这些信息。 Q mot ∈ R N a × M mot × T mot × C Q_{\text{mot}} \in \mathbb{R}^{N_a \times M_{\text{mot}} \times T_{\text{mot}} \times C} Qmot∈RNa×Mmot×Tmot×C这是Motion的query。从历史K帧缓存的motion query中获取到未来 T m 2 m T_{m2m} Tm2m步的预测,对 Q m 2 m Q_{m2m} Qm2m, Q m o t Q_{mot} Qmot进行cross atten, Q m o t Q_{mot} Qmot做self atten在motion和step都做
运动预测模块公式(图2c)
Q
mot
=
CrossAttn
(
Q
=
Q
mot
,
K
,
V
=
Q
m2m
)
,
Q_{\text{mot}} = \text{CrossAttn}(Q = Q_{\text{mot}}, \text{K}, V = Q_{\text{m2m}}),
Qmot=CrossAttn(Q=Qmot,K,V=Qm2m),
Q
mot
=
StepSelfAttn
(
Q
mot
)
,
Q_{\text{mot}} = \text{StepSelfAttn}(Q_{\text{mot}}),
Qmot=StepSelfAttn(Qmot),
Q
mot
=
ModeSelfAttn
(
Q
mot
)
.
Q_{\text{mot}} = \text{ModeSelfAttn}(Q_{\text{mot}}).
Qmot=ModeSelfAttn(Qmot).
功能:通过跨注意力、步骤自注意力和模态自注意力,整合历史预测信息并增强未来时间步与轨迹模式的一致性。
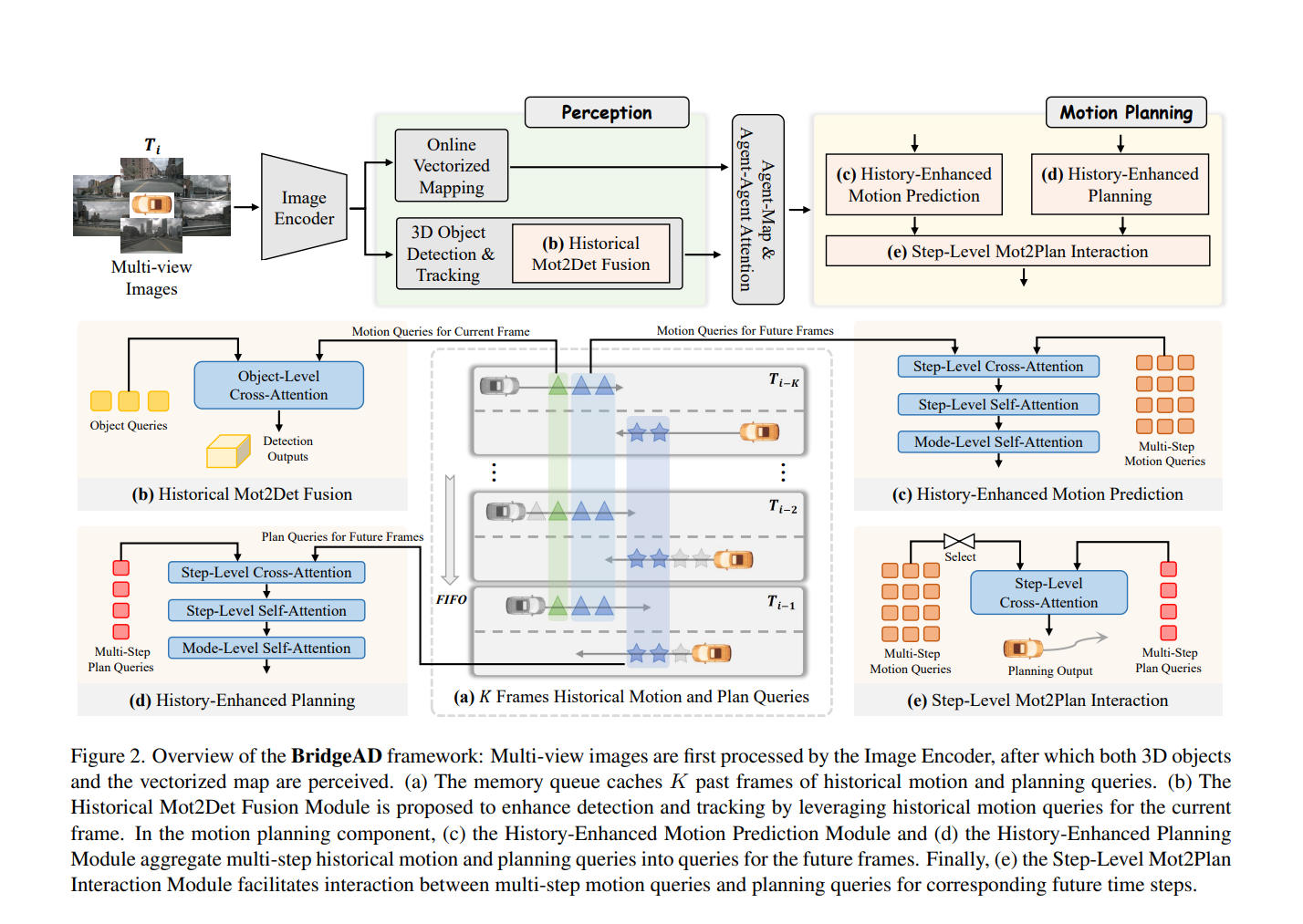
图2. BridgeAD框架概述
多视角图像首先通过图像编码器处理,随后感知3D物体和矢量化地图:(a) 记忆队列:缓存过去K帧的历史运动查询和规划查询。(b) 历史运动到检测融合模块:通过历史运动查询增强当前帧的检测与跟踪。© 历史增强的运动预测模块:聚合多步历史运动查询,生成未来帧的运动预测。(d) 历史增强的规划模块:聚合多步历史规划查询,生成未来帧的规划轨迹。(e) 步骤级运动到规划交互模块:在对应未来时间步上,协调运动查询与规划查询的一致性。
–
规划模块公式(图2d)
规划模块和Motion模块已基本一致, Q plan Q_{\text{plan}} Qplan规划的query是从历史ego query中初始化。 T p 2 p {T_{p2p}} Tp2p未来的步数对应 Q p2p Q_{\text{p2p}} Qp2p.注意力机制的设计
- 规划查询张量定义: Q plan ∈ R M plan × T plan × C Q_{\text{plan}} \in \mathbb{R}^{M_{\text{plan}} \times T_{\text{plan}} \times C} Qplan∈RMplan×Tplan×C
- 历史规划查询提取:
Q
p2p
∈
R
M
plan
×
K
×
T
p2p
×
C
Q_{\text{p2p}} \in \mathbb{R}^{M_{\text{plan}} \times K \times T_{\text{p2p}} \times C}
Qp2p∈RMplan×K×Tp2p×C
Q plan = CrossAttn ( Q = Q plan , K , V = Q p2p ) , Q_{\text{plan}} = \text{CrossAttn}(Q = Q_{\text{plan}}, \text{K}, V = Q_{\text{p2p}}), Qplan=CrossAttn(Q=Qplan,K,V=Qp2p),
Q plan = StepSelfAttn ( Q plan ) , Q_{\text{plan}} = \text{StepSelfAttn}(Q_{\text{plan}}), Qplan=StepSelfAttn(Qplan),
Q plan = ModeSelfAttn ( Q plan ) . Q_{\text{plan}} = \text{ModeSelfAttn}(Q_{\text{plan}}). Qplan=ModeSelfAttn(Qplan).
功能:与运动预测模块类似,通过分层注意力机制聚合历史规划信息。
motion的head

planning head

Step-Level Mot2Plan交互公式(图2e)
功能:为了改善motion和planning的一致性,这个模块是融合motion和planning, T p l a n T_{plan} Tplan步数的Motion query,在规划时间范围内,将周围智能体的未来状态(由运动查询表示)与规划查询对齐,提升规划与运动预测的一致性。
- 筛选运动查询:
Q mot ∗ = SelectWithScore ( Q mot ) Q_{\text{mot}}^{*} = \text{SelectWithScore}(Q_{\text{mot}}) Qmot∗=SelectWithScore(Qmot) - 跨注意力交互:
Q plan = CrossAttn ( Q = Q plan , K , V = Q mot ∗ ) . Q_{\text{plan}} = \text{CrossAttn}(Q = Q_{\text{plan}}, \text{K}, V = Q_{\text{mot}}^{*}). Qplan=CrossAttn(Q=Qplan,K,V=Qmot∗).
关键说明
跨注意力机制:运动预测与规划模块的跨注意力仅作用于对应时间步(如历史运动查询与所有
T
m
o
t
T_{mot}
Tmot 步运动查询交互)。
历史信息传播:通过两层自注意力(step级和motion级),历史信息被传播到所有查询步骤。
输出:最终输出规划轨迹及其置信度评分。
其他行内公式
- 历史时间步定义:
T m2m = 6 T_{\text{m2m}} = 6 Tm2m=6(运动预测历史步长)
T p2p = 3 T_{\text{p2p}} = 3 Tp2p=3(规划历史步长) - 输入图像尺寸:
256 × 704 256 \times 704 256×704(BridgeAD-S)
512 × 1408 512 \times 1408 512×1408(BridgeAD-B)
功能:通过跨注意力、步骤自注意力和模态自注意力,整合历史预测信息并增强未来时间步与轨迹模式的一致性。
3.5 端到端学习
损失函数包含四个任务:目标检测,map,motion,plannning。每个任务的损失分为回归和分类两部分。对于回归任务,我们使用L1损失;对于分类任务,使用损失(Focal loss)[33]。针对多模态运动预测和规划任务,
Γ
(
z
)
=
∫
0
∞
t
z
−
1
e
−
t
d
t
.
\Gamma(z) = \int_0^\infty t^{z-1}e^{-t}dt\,.
Γ(z)=∫0∞tz−1e−tdt.我们采(winner-takes-all)。端到端训练的整体损失函数如下:
L
t
o
t
a
l
=
L
d
e
t
+
L
m
a
p
+
L
m
o
t
+
L
p
l
a
n
.
\mathcal{L}_{total} = \mathcal{L}_{det} + \mathcal{L}_{map} + \mathcal{L}_{mot} + \mathcal{L}_{plan}.
Ltotal=Ldet+Lmap+Lmot+Lplan.
(5)
模型和损失函数的更多细节详见补充材料。
4 实验
实验设置
数据集与评估指标:我们在具有挑战性的nuScenes数据集[2]上进行实验,该数据集包含1000个驾驶场景,每个场景持续20秒。数据集提供语义地图和关键帧的3D目标检测标注,采样频率为2Hz,每个关键帧包含6个摄像头图像。我们按照先前工作[19, 26]在nuScenes上进行开放环测试,并在基于nuScenes的NeuroNCAP模拟器[38]中进行封闭环测试。NeuroNCAP是一个逼真的封闭环仿真框架,提供从nuScenes记录的安全关键场景,这些场景在现实世界中难以采集。对于开放环评估,我们使用与VAD[26]一致的L2位移误差指标以及碰撞率[18, 29](定义见[29, 47])。对于封闭环评估,我们采用NeuroNCAP评分和碰撞率[38]。感知和预测任务的额外指标与先前研究[19]一致。更多细节详见补充材料。
实现细节
BridgeAD为自车规划3秒的未来轨迹,并为周围交通参与者预测6秒的未来轨迹。该设置使得运动预测的时间步长为12,规划时间步长为6。运动预测的历史时间步长设为6,规划的历史时间步长设为3。我们在记忆队列中缓存过去K=3帧的运动和规划查询。BridgeAD模型有两个变体:BridgeAD-S和BridgeAD-B。对于BridgeAD-S,使用ResNet50[17]作为骨干网络编码图像特征,输入图像尺寸为256×704(默认模型);对于BridgeAD-B,使用ResNet101,输入图像尺寸为512×1408。训练时,采用AdamW优化器[39]和余弦退火策略[40],权重衰减为1×10−3,初始学习率为1×10 −4 。训练分为两个阶段:一个专注于感知任务,另一个进行端到端训练。实验在8块NVIDIA RTX A6000 GPU上进行。更多配置细节和额外实验见补充材料。
与现有技术的对比
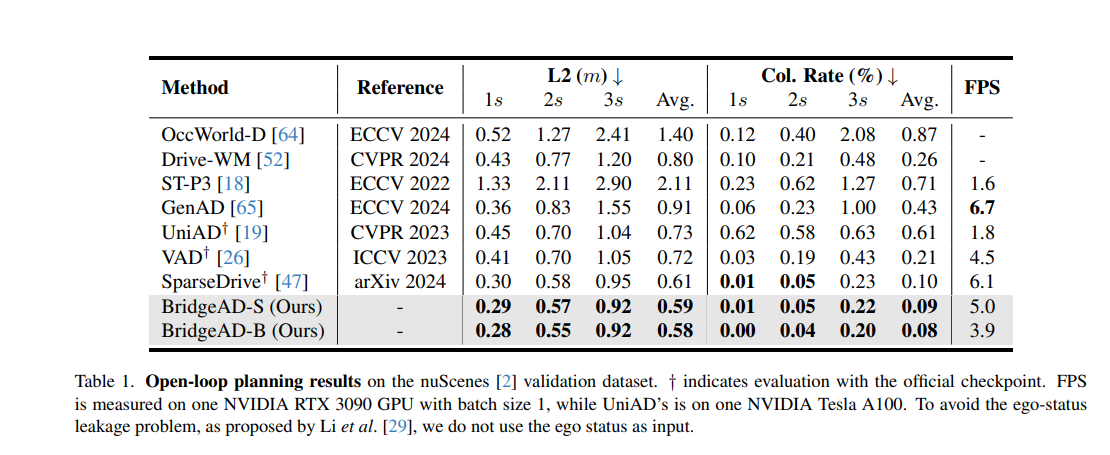
开放环规划结果:如表1所示,我们将BridgeAD的开放环规划性能与近期表现最佳的方法进行比较,包括端到端自动驾驶方法[19, 26, 47, 65]和世界模型方法[52, 64]。BridgeAD实现了最先进的性能。针对Li等人[29]指出的未来路径规划过度依赖自车状态的问题,BridgeAD的输入不包含自车状态。尽管如此,我们的方法仍优于依赖自车状态的其他方法。
封闭环规划结果
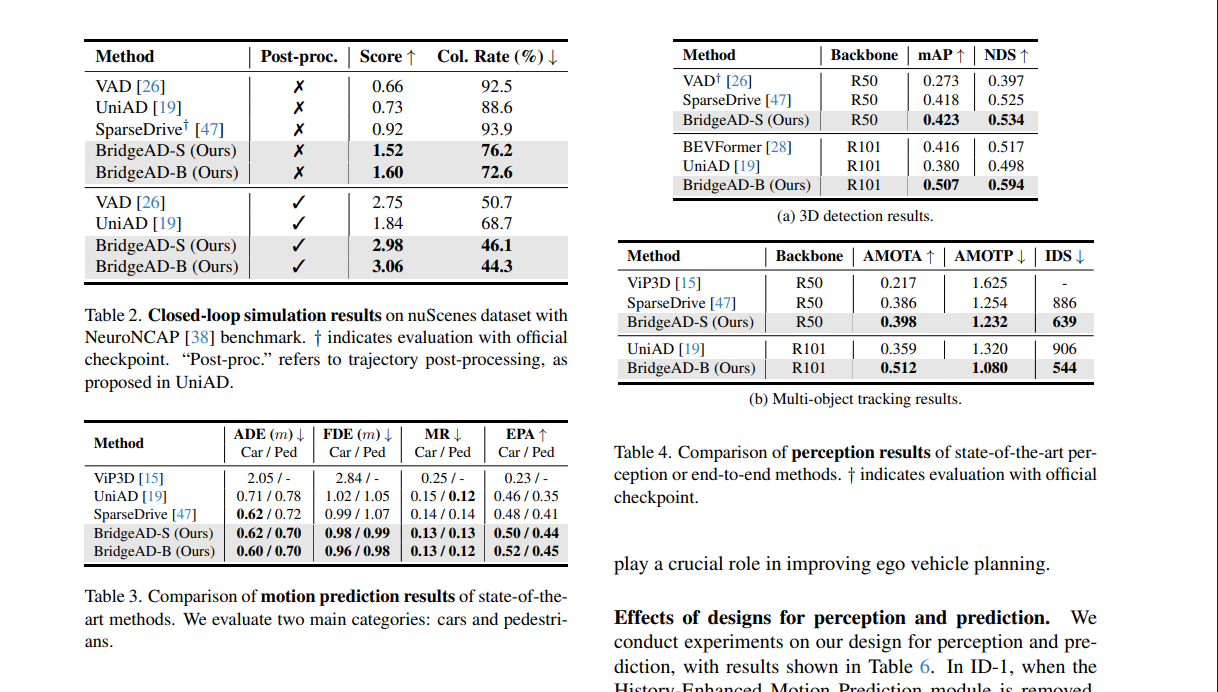
我们在基于nuScenes[2]的NeuroNCAP模拟器[38]中对BridgeAD进行封闭环评估。NeuroNCAP提供逼真的安全关键场景测试。如表2所示,无论是否采用UniAD[19]提出的轨迹后处理,BridgeAD的性能均显著优于先前方法[19, 26, 47]。具体而言,未使用后处理时,BridgeAD-S的NeuroNCAP评分比SparseDrive高65%,碰撞率较UniAD降低12.4%。结果表明,通过有效聚合历史信息,我们的模型提升了连续驾驶场景中规划的连续性和一致性,凸显了BridgeAD在封闭环仿真中的潜力。相比之下,其他方法要么忽略运动规划中的历史信息[19, 26],要么未在当前帧有效整合历史信息[47],这使其能感知周围交通参与者但难以避免碰撞。我们通过定性分析进一步强调这一优势。
感知与运动预测结果:感知结果如表4所示,运动预测结果如表3所示。通过利用历史信息和多步运动查询表示,BridgeAD在所有指标上均优于其他方法。感知任务(检测与跟踪)的结果也呈现类似的提升。

















 2137
2137

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









