







在许多实际应用中,时间序列预测是一个关键而具有挑战性的问题。近年来,基于transformer的模型在时间序列预测方面取得了很大的进展。此外,一些模型引入了序列分解来进一步揭示可靠而简单的时间依赖关系。不幸的是,很少有模型能够处理复杂的周期性模式,例如真实数据集中的多个周期、可变周期和相位转移。同时,众所周知的点积的二次复杂度阻碍了长序列建模。为了应对这些挑战,我们设计了一个创新的框架四元数转换器(Quaternion Transformer, Quatformer),以及三个主要组件:1)基于四元数的旋转学习(learning-to-rotate attention, LRA),引入可学习的周期和相位信息来描绘复杂的周期模式。2)趋势归一化,考虑到趋势变化缓慢的特点,对模型隐藏层中的序列表示进行归一化。3).利用全局内存解耦LRA,在不失去预测精度的前提下实现线性复杂度。我们在多个真实世界的时间序列数据集上评估了我们的框架,观察到与最好的最先进的基线相比,平均8.1%和高达18.5%的MSE改进。
问题:
1)由于时序依赖关系可能被纠缠的趋势和周期模式所掩盖,如何对时序依赖关系进行建模仍然是一个挑战。
2)传统的预测方法,如seasonal ARIMA[9]和Prophet[24],也利用了具有启发式周期先验的分解,但未能自动智能地建模复杂的周期模式。
方法:
我们的主要目标是对复杂的周期模式进行建模,以实现准确的时间序列预测。首先,设计了一种新的核,即rotatory softmax-kernel,通过四元数形式将给定时间序列的表示序列按频率(或周期)进行旋转,从而在测量成对相似性时融入周期和相位信息。该内核可以直接插入点积注意力。为进一步处理多个周期、可变周期和相位偏移,本文提出以数据驱动的方式学习潜在的频率和相位,得到旋转学习注意力,保留了对注意力机制长程依赖的建模能力,并利用了时间序列的周期特性。此外,我们提出趋势归一化,通过强制趋势分量的缓慢变化特性来更好地归一化隐藏层中的序列表示。
本文提出解耦注意力,通过引入一个额外的固定长度的潜序列来存储全局记忆,将注意力机制解耦为两个具有线性复杂度的注意力
框架:
提出了四元数Transformer框架,成功地处理了复杂的周期模式,打破了长时间序列预测的计算效率瓶颈。其中,四元数旋转注意力学习(LRA)旨在对时间序列的复杂周期依赖关系进行建模,趋势归一化类似于层归一化,但强调隐藏层中序列表示的缓慢变化趋势。提出一种解耦注意力,将LRA的二次复杂度降低为线性。
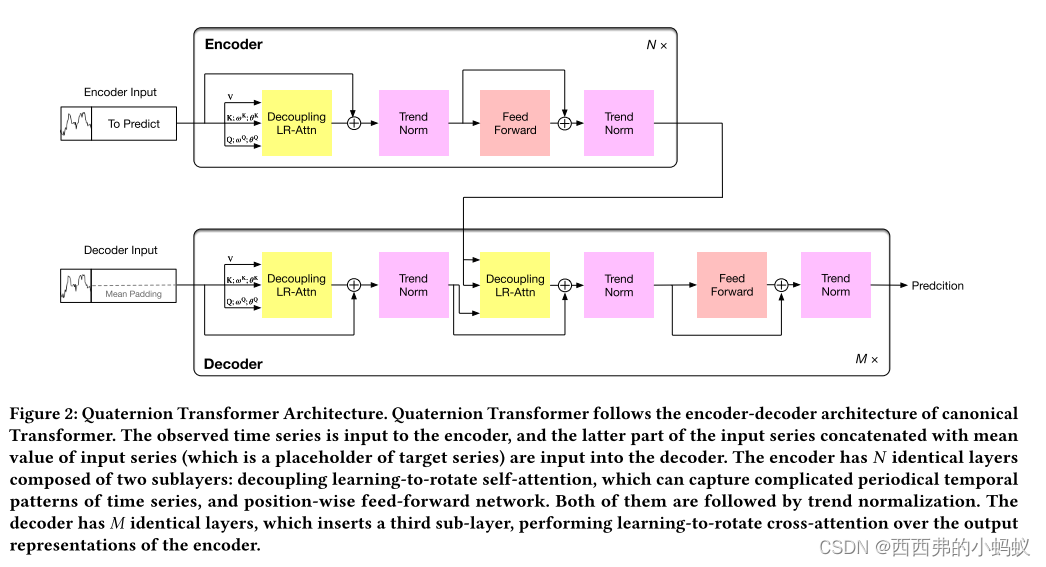
Learning-to-Rotate Attention















 314
314











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









