









LSH Forest: Self-Tuning Indexes for Similarity Search
本文研究了高维数据的(近似)相似性搜索问题。相似性索引在很多场景下都很重要:网络搜索引擎需要快速、并行、基于内存的索引来进行文本数据的相似性搜索;数据库系统需要基于磁盘的高维数据相似性指标,包括文本和图像;Peer-to-peer系统需要低通信开销的分布式相似度指标。提出了一种适用于上述所有场景的LSH Forest索引方案。该索引使用众所周知的局部敏感哈希(LSH)技术,但通过以下方式改进了之前的设计:(a)消除了LSH必须不断手动调整的不同数据依赖参数,(b)在保持相同的存储和查询开销的同时,改进了LSH对倾斜数据分布的性能保证。我们将展示如何在主内存、磁盘、并行系统和对等系统中构建这个索引。在多个文本语料库上进行了实验,评估了该设计,并展示了flashforest的自调优性质和优越性能
方法:LSH索引
现在,我们不再给点分配固定长度的标签,而是让标签具有可变长度;具体来说,每个点的标签要足够长,以确保每个点都有一个不同的标签。
然后,我们可以在所有标签的集合上构建一个(逻辑上的)前缀树,每个叶子节点对应一个点。我们称这棵树为LSHTree。我们的索引结构只是由这样的LSH树组成,每棵LSH树都是由h中独立绘制的随机哈希函数序列构建的,我们称这个l树的集合为LSHForest。
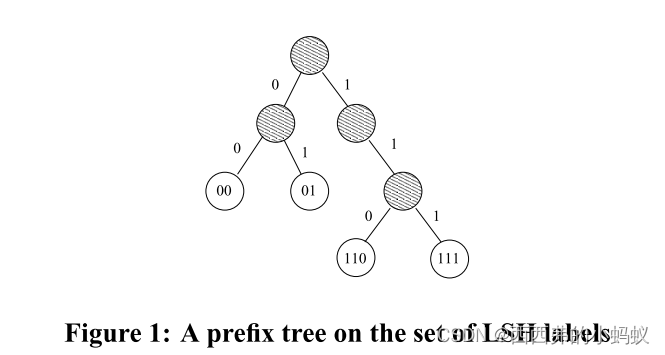
总结:将变长的hash标签,构成一个前缀树。整个hash集合由L个前缀树构成。















 4441
4441











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









