









Neighbor-Sensitive Hashing
使用二进制哈希函数的近似kNN (k-nearest neighbor)技术是最常用的方法之一,用于克服执行精确kNN查询的过高成本。然而,这些技术的成功很大程度上取决于它们的散列函数区分kNN项的能力;也就是说,基于数据项的哈希码检索出的kNN项应该包含尽可能多的真正的kNN项。在这个过程中,一个被广泛采用的原则是,相似的项被分配相同的哈希码,这样与查询的哈希码相似的项很可能是真正的邻居。
本文放弃了这种被大量利用的原则,追求相反的方向,为kNN任务生成更有效的哈希函数。也就是说,我们的目标是增加相似项之间在哈希码空间中的距离,而不是减少它。本文的贡献首先提供了理论分析,说明为什么这种革命性的、看似反直觉的方法可以更准确地识别kNN物品。在分析之后,提出了一种嵌入这种新原理的哈希算法。实证研究表明,基于这种反直觉思想的哈希算法显著提高了当前最先进技术的效率和准确性。
一. NEIGHBOR-SENSITIVE HASHING
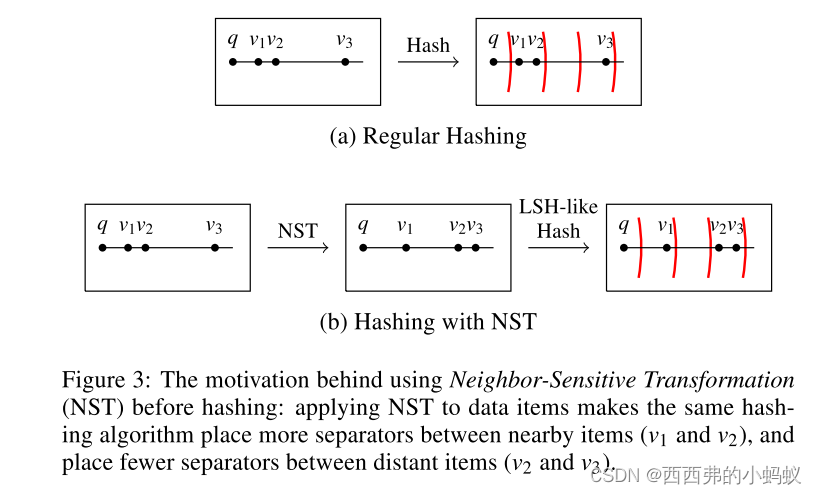
本节介绍我们的主要贡献——邻域敏感哈希(Neighbor-Sensitive Hashing, NSH)。首先,3.1节正式验证了我们在第1节中介绍的直觉: 对附近的数据项使用更多的分隔符可以更准确地区分kNN项。如图3所示,NSH是哈希算法和我们提出的邻域敏感变换(NST)的结合。3.2节列出了NST的一组抽象的数学性质,3.3节给出了一个满足这些性质的NST的具体例子。最后,第3.4节介绍了我们的最终算法(NSH),该算法将提出的NST作为关键组件。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









