







REPT: A Streaming Algorithm of Approximating Global and Local Triangle Counts in Parallel
最近,大量工作致力于近似计算由边序列表示的大型图流的全局和局部(即与每个节点相关)三角形计数。现有的近似三角形计数算法依赖于采样技术来降低计算成本。然而,它们的估计误差很大程度上取决于采样三角形之间的协方差。此外,很少有人关注开发可用于在多核机器或机器集群上快速和近似计数三角形的并行单遍流算法。为了解决这些问题,我们开发了一种新的并行方法报告,以显著降低采样三角形之间的协方差(甚至在某些情况下完全消除协方差)。从理论上证明了REPT算法比直接并行化现有的三角形数目估计算法更准确。在各种真实世界的图上进行了广泛的实验,结果表明,所提出的方法报告的准确性比最先进的方法高出几倍。
一研究方法
我们开发了一种新的并行方法report(随机边划分和三角形计数)。报告将Π流的边随机分配到不同的处理器中,并并行地近似计算三角形的数量。与parallel MASCOT类似,它从流Π中采样一部分边,并计算每个处理器上半三角形的数量。平均而言,每个处理器在任何时候都对Π流的所有边进行采样并存储p × 100%的边。与parallel MASCOT不同,REPT不会独立生成每个处理器的采样边缘集。
Building Fast and Compact Sketches for Approximately Multi-Set Multi-Membership Querying SIGMOD ’21
对于给定的集合S,成员关系查询可以回答查询元素q是否∈S。它是数据库系统和计算机网络等领域的基本任务。本文考虑了一个更一般的问题:多集合多成员查询(MS-MMQ)。给定n个集合S0,…, Sn−1,MS-MMQ回答包含元素q的集合。直接寻址MS-MMQ的方法是为每个集合建立一个MQ结构(例如,布隆过滤器)。然而,查询和空间复杂度随n线性增长,当n很大时变得令人生畏。为了应对这一挑战,本文提出一种新的循环移位和合并(CSC)框架,以有效地实现近似MS-MMQ。CSC索引不是为每个集合构建MQ数据结构,而是将所有n个集合编码为一个紧凑的草图,并仅检索草图中的几个字节用于查询,从而实现了较高的内存效率,并将查询速度提高了几倍。CSC与近似MQ的主流数据结构兼容。在真实的数据集上进行了实验,结果表明,该框架比最先进的方法快91.2倍,准确性高48.9倍。
一研究内容
本文研究了一个更复杂的MQ问题,称为多集多成员关系查询(Multi-set Multimembership query, MS-MMQ)。给定集合S0,…, Sn−1,MSMMQ的目标是回答哪些集合包含查询元素q。注意,一个元素可能存在于多个集合中。它假设每个元素只属于S0中的一个集合,……, Sn−1。

OUR FRAMEWORK
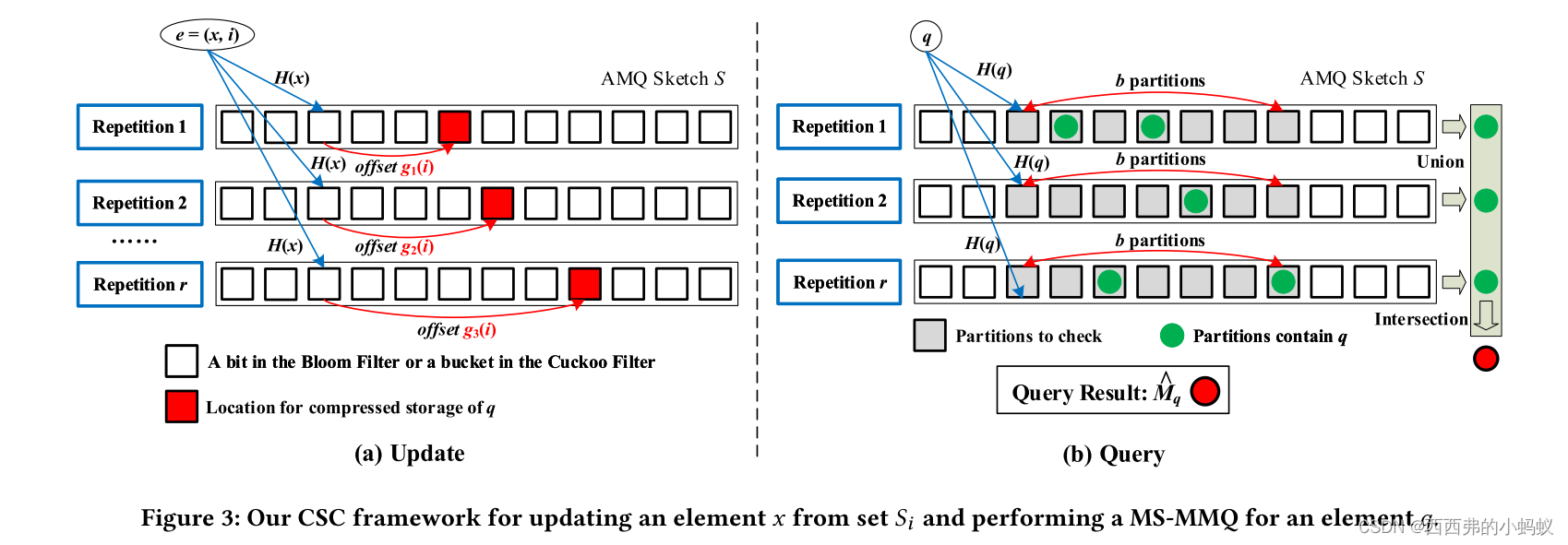
To improve efficiency, we propose a Circular Shift and Coalesce (CSC) framework
1)CSC-BF
CSC-BF的基本构造块是由k个独立的哈希函数h0组成的anm位布隆过滤器。,hk - 1均匀分布于{0,…, m−1}。所有比特位都初始化为0。为每个重复Rj分配这样一个布隆过滤器,0≤j≤r−1。每个重复都有其唯一的划分函数дj将n个集合不相交地映射为b个划分。
2)CSC-CF
我们将CSC框架与布谷鸟过滤器(Cuckoo Filter)作为CSC- cf集成,以支持元素删除。csc - cf的基本构建模块是m桶布谷鸟滤波器,每个桶都有插槽。每个槽存储一个由哈希函数f生成的元素指纹。我们为每个重复Rj分配这样一个布谷鸟滤波器,0≤j≤r−1。
Fast Rotation Kernel Density Estimation over Data Streams KDD ’21
核密度估计方法是一种有效的工具,被广泛应用于异常检测、统计学习等领域。不幸的是,当前的核方法在处理大规模、高维数据集时存在较高的计算或空间成本,特别是当感兴趣的数据集以流的方式给出时。虽然已有一些粗略的核密度估计方法,但它们仍然存在较高的计算成本。针对该问题,本文提出一种新的旋转核。旋转核基于旋转散列方法,计算速度快得多。为了实现内存高效的数据流核密度估计,设计了一种RKD-Sketch方法,将高维数据流压缩为一个小的整数计数器数组。在合成和真实数据集上进行了广泛的实验,实验结果表明,所提出的RKD-Sketch比最先进的方法节省了最多216倍的计算资源和104倍的空间资源。此外,我们将旋转核应用于主动学习中。实验结果表明,该方法在保持与基线方法相同精度的前提下,加速比最高可达256倍,节省空间最高可达13倍。
一研究问题:

因此,设计计算效率和内存效率高的算法来实现对KDE的有效逼近是很有必要的。
二研究内容
本文提出了一种新的相似核和快速草图方法,以在有限的内存中近似核密度
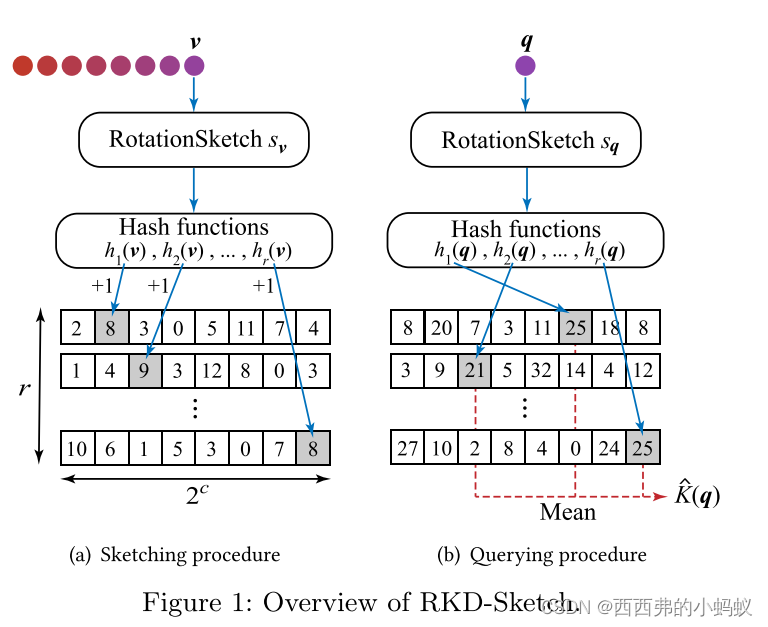
1)Rotation Sketch and Kernel


2)Rotation Kernel Density Sketch
旋转核密度草图(RKD-Sketch)使用少量的空间,并有效地从𝐷中的矢量草图中构建。从RKD-Sketch中,我们可以有效地估计任何查询向量的旋转核密度𝒒
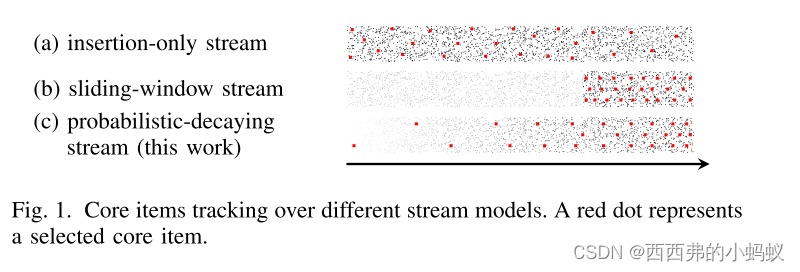
Continuously Tracking Core Items in Data Streams with Probabilistic Decays 2020 ICDE
大数据的规模导致了信息过载问题,迫切需要能够从海量数据中得出有价值见解的工具。研究了核心项目跟踪(core items tracking, CIT)问题,其目标是在数据流中持续跟踪具有代表性的项目(称为核心项目),以便更好地表示/总结数据流。为了同时满足时效性和连续性的要求,本文考虑了概率衰减流上的CIT,即流中的项以概率的方式逐渐被遗忘。首先提出一种算法PNDCIT,用于在一类特殊的概率非衰减数据流中寻找核心项。此外,以PNDCIT为构建模块,设计了两种新的算法,即PDCIT和PDCIT+,以在具有恒定近似比的概率衰减流上维护核心项。最后,在真实数据上的大量实验表明,PDCIT+在提供质量相当的解决方案的同时,比批处理算法的加速比最高可达一个数量级。
一研究问题:
1)开发工具来帮助人们减少数据过载,并从海量数据流中获得有价值的见解是势在必行的。为了解决这个问题,一种方法是有选择地维护几个有代表性的项,称为核心项,以最好地表示/总结流。
2)其挑战在于如何以流式的方式高效地维护核心元素,以保证新元素不断到达,并对维护的核心元素进行相应的更新,以确保它们始终(接近)最佳。我们将此任务称为核心项目跟踪(CIT)任务。
二研究内容
我们建议,一个更好的方法是将时间衰减纳入核心项目选择中。引入了一种概率衰减流(probabilistic-decay stream, PDS)模型,允许从过去到现在的数据项都有机会参与分析(因此满足连续性),但过时的数据比最近的数据更不可能参与分析(因此满足最近性)。随着时间的推移,item会变得越来越不重要,不太可能被选为核心物品,因此它会逐渐被遗忘
 请注意,CIT的目标是最大化PDS上的预期效用,而不是像之前的工作[7,9,18,19]中那样最大化确定性流上的效用。
请注意,CIT的目标是最大化PDS上的预期效用,而不是像之前的工作[7,9,18,19]中那样最大化确定性流上的效用。


2)MAINTAINING DATA STREAM SAMPLES
我们解决了维护数据流样本的子问题
3)Sampling Methods
三 具体方法
1)A BASIC STREAMING ALGORITHM
设计了一个基本的流算法PDCIT来解决CIT问题。首先考虑一种特殊的概率不衰减情况,并设计PNDCIT来求解这种特殊情况下的CIT。将PNDCIT作为构建模块设计PDCIT以解决CIT问题。
A. The Probabilistic Non-Decaying Case
考虑一个特殊情况,每一项的衰减函数都是常数,

2)The PDCIT Algorithm
![]()

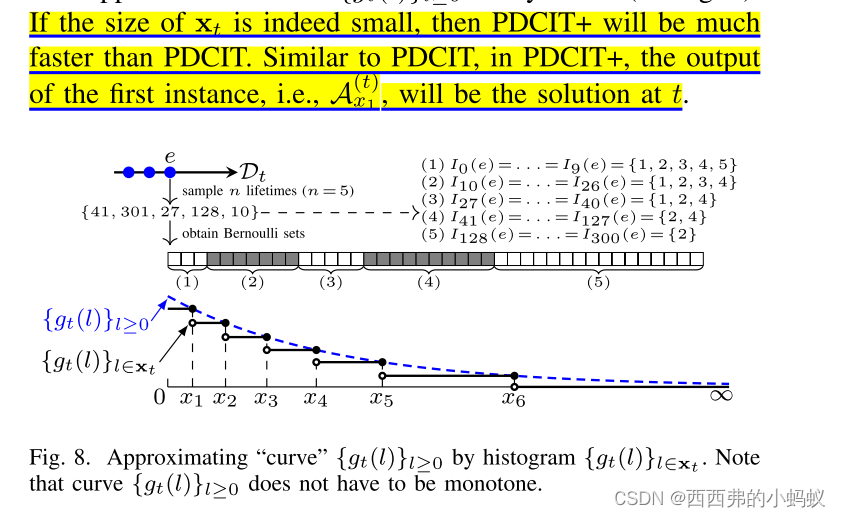
3)A FASTER STREAMING ALGORITHM
我们通过设计一个更快的流算法PDCIT+来解决PDCIT的瓶颈,该算法允许生命周期上限L无穷大。
我们的想法是有选择地维护其中的一些实例,并希望这些被选中的实例能够很好地接近其余的实例。由于只维护少量实例,因此效率应该得到很大提高。这个想法可以被认为是使用直方图来近似曲线。
A Memory-Efficient Sketch Method for Estimating High Similarities in Streaming Sets
估计集合相似度和检测高度相似集合是数据库、机器学习和信息检索等领域的基础问题。MinHash是一种著名的近似集合Jaccard相似性的技术,已被成功地应用于相似性搜索和大规模学习等许多领域。它的两个压缩版本,b-bit MinHash和Odd Sketch,可以显著减少MinHash方法的内存占用,特别是在估计高相似度(相似度约为1)时。MinHash既可以应用于静态集合,也可以应用于流式集合(元素以流式形式给出且基数未知甚至无限),但遗憾的是,b-bit MinHash和Odd Sketch不能处理流式数据。为了解决这一问题,设计了一种内存高效的概要算法MaxLogHash,以准确估计流集中的杰卡德相似度。与MinHash相比,该方法使用更小的寄存器(每个寄存器由少于7位组成)来为每个集合构建紧凑的草图。本文还提供了一个简单而准确的估计器,用于从MaxLogHash草图中推断Jaccard相似性。推导出了估计误差的界限公式,并确定了达到所需精度的最小必要内存使用(即MaxLogHash草图使用的寄存器数量)。在多个数据集上的实验结果表明,MaxLogHash方法在估计高相似度的精度和计算代价相同的情况下,内存效率大约是MinHash方法的5倍。


OUR METHOD

阅读者总结:这篇论文提出了一种近似集合相似性算法
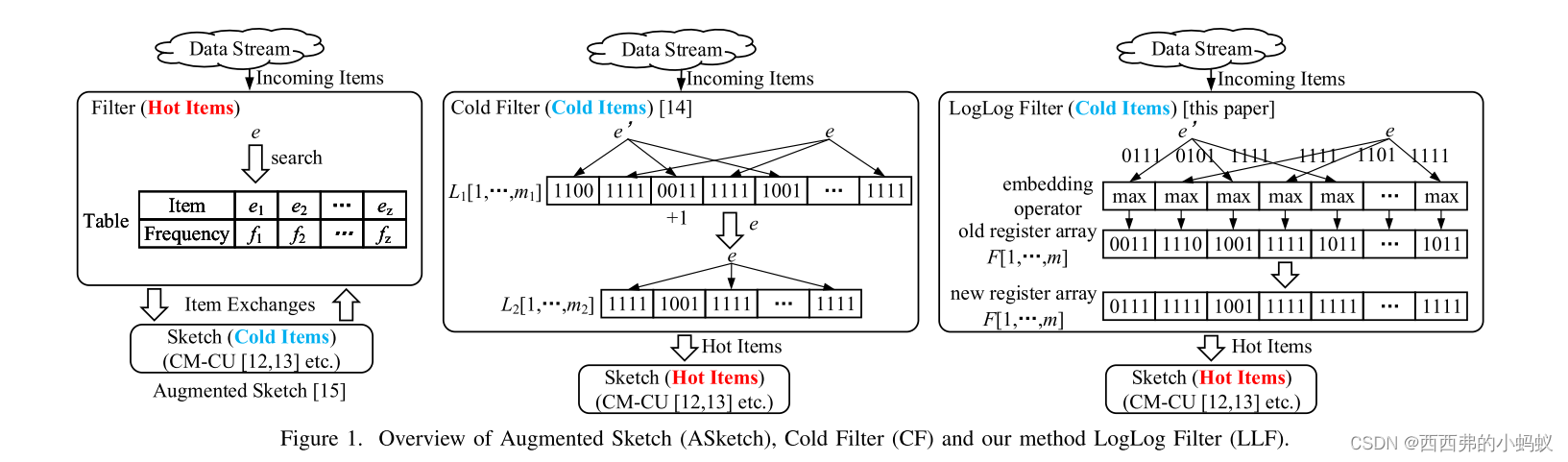
LogLog Filter: Filtering Cold Items within a Large Range over High Speed Data Streams
现实世界中的许多数据集都是以数据流的形式给出的,对这些数据流的处理是异常检测等许多应用的基础。该文研究了项目出现频率的计算、topk热点项目的发现以及剧烈变化的检测问题。然而,广泛使用的草图内存消耗大,性能容易受到数据流分布不均衡的影响。针对这一问题,提出一种新颖的冷过滤(CF)方法来分割冷项和热项,并使用单独的结构来记录热项的频率。通常,CF的过滤范围较小,只对频率较小的冷门物品有效。然而,在一些实际应用中,冷元素的频率也可能超过数百甚至数万。为了解决上述挑战,利用" LogLog "结构,开发了一种内存高效的LogLog Filter (LLF)方法来准确估计上述3个指标。LLF建立一个寄存器数组,其中每个寄存器大约计算散列到其中的元素频率的总和。该方法以较少的比特数显著地扩大了CF的过滤范围,并且仅需4比特就能过滤频率达224的冷项。在真实数据集和合成数据集上进行了广泛的实验,实验结果证明了所提方法的效率和有效性。
一研究内容
提出了一种内存高效的方法LogLog Filter (LLF)来近似测量数据流中的上述3个指标。LLF的基本思想是利用" LogLog "结构[21]-[23]来有效地过滤冷项。这使我们能够使用更少的比特来实现更大的滤波器范围。















 1651
1651











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









