







设计LSM树缓冲算法的挑战
- LSM是一个分层的数据结构,那么根据kv对所处的层级不同,cache命中带来的收益也是不同的。根据LSM读取数据的方式,一般来说,kv对所处的层级越深,那么cache命中带来的收益就越大。因为KV对的大小并不是固定的,所以LSM树的缓冲策略需要做到缓冲的数据所占用的DRAM空间与节省的IO之间的平衡。
- 对于点查与范围查询这两种类型的工作负载需要采用不同的缓冲策略。依赖来说缓冲kv对有助于调查,缓冲blockcache有助于范围查询和点查,另外,对于大value可以选择缓冲value的pointer。对于这三种类型的cache,如何动态调整它们的内存占比,以便获取最大的收益是一个挑战。
OS中的自适应替换Cache(ARC)
ARC用于DRAM中的Page替换。总体来说,ARC将cache分为两部分,一部分为新进cache(recency-cache,类似JVM的新生代),另一部分为频率cache(frequency-cache, 类似JVM的老生代)。这两部分分别是一个LRU实例。ARC的策略是,当一个数据第一次被访问的时候,它首先被缓冲到recency-cache中,当该数据再次被访问的时候,它会被迁移到frequency-cache中。
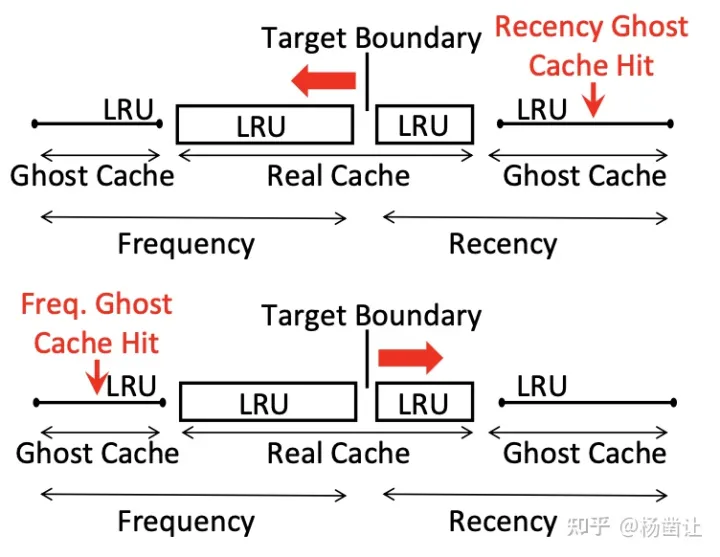
一般来说,缓冲区不可能持续增长,它的总大小是固定的,那么在一个固定的总大小下,ARC如何确定recency-cache-LRU与frequency-cache-LRU的大小比例呢?ARC用两个幽灵cache(ghost-cache)来完成这两个LRU队列的大小动态调整。做法是这样的:
- 这两个ghost-cache分别存储recency-cache和frequency-cache被evicted的数据的元数据。因为ghost-cache只存储了元数据,所以这两个ghost-cache所占的大小是很小的。
- 如果命中了recency-ghost-cache,则表明recency-cache的size太小,所以需要调大recency-cache的size。对于frequency-ghost-cache也是一样的道理。
AC-Key的设计
AC-Key缓冲三种类型的entry:KV,KP,block。也就是说AC-Key共有三个Cache实例,这三个Cache共同组成了整个LSM的Cache,其中:
- KV缓冲key和value数据对
- KP缓冲key和value的pointer
- block缓冲SST的block数据
对于这三个Cache的大小,AC-Key通过分层自适应缓冲算法动态调整。这三个Cache被三个E-LRU队列管理,所谓的E-LRU队列,是AC-Key在LRU的基础上结合缓冲效率因子提出的增强LRU算法。
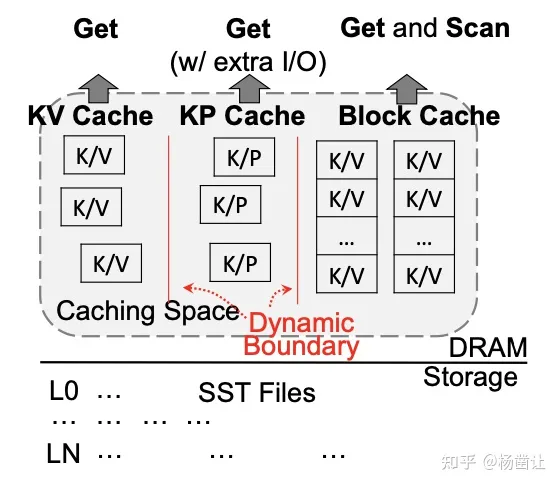
另外,需要注意一点,当数据第一次被访问时候,AC-Key会首先将其缓冲到KPCache中,当KPCache的数据被再次访问,会将其移入KVCache中。
读流程
先读Memtable,然后读KVCache, 接着读KPCache, 再读blockcache,最后读SST文件。
如果命中blockcache,那么除了将数据返回给用户以外,还需要将KP缓冲到KPCache中。所以这里的问题:一个数据被初次访问,它被放入blockcache中和KPCache中,假设kv对的key很小,那么不会造成空间的浪费,问题是如果KPCache再次被命中,那么此时value被缓冲到KVCache中,一个value会被blockcache和KVcache存储,这造成了空间浪费。
对rocksdb的flush处理
已经缓冲在KVCache和KPCache中数据,会被Put操作弄脏。如果memtable被刷到磁盘,此时需要更新KVCache和KPCache中变脏的数据,避免用户读到旧数据。
对compaction的处理
compaction会影响KPCache和BlockCache的数据,但是KVCache的数据不会产生影响。AC-Key会在compaction以后更新KPCache和BlockCache的数据。
对于KPCache,在compaction以后,更新对应的pointer即可。
对于BlockCache,在compaction以后,如果缓冲的block数据失效了,那么会用新的block数据替换旧的block数据。新生成的block的key范围和旧block的key范围可能不一致,AC-Key选择缓冲和旧block的key范围最接近的新block。根据rocksdb的compaction原理,新的block在内存也会有一份,因此在缓冲时不用额外的磁盘IO
缓冲效率因子(Caching Efficiency Factor)
缓冲效率因子用于量化s冲的开销与收益。
用E表示一个缓冲条目的缓冲效率因子。那么E由下面的公式计算:
E=bs
上式中:
- E表示一个缓冲条目的缓冲效率因子。
- b表示如果该条目被缓冲,那么可以节省多少IO开销
- s表示该条目被缓冲需要占用多少空间
变量s很容易理解,就是一个缓冲条目会占用多少DRAM空间。但是对于变量b,如何来衡量一个条目的IO开销呢?用什么单位呢?论文中做了解释,b表示节省的IO操作次数,由下面这个公式计算:
b={1if block,f(m)if KV entry,f(m)−1if KP entry,
上式中:
- m表示为了查找key,访问的SST文件的个数。
- f(m)表示为了查找key,需要进行的IO次数。
上式中的f(m)依赖于LSM树的具体实现。一般来说f(m)=m+2, 这个式子可以这么理解,如果我们为了找到一个key,访问了m个SST文件,假设每次磁盘IO可以读取一个SST文件的bloom过滤器,那么此时的IO开销为m,再假设SST文件的indexblock和一个datablock都可以通过一次IO获取到,那么f(m)=m+2。
那如何估测为了查找一个key,访问了多少SST文件呢:
m={n0/2if l=0,l+n0if l>=1,
如果将key所在的Level记为l,上式通过key所在的level估测访问的SST文件个数。因为L0层的SST文件中的key彼此交错,所以如果一个key在L0层,那么它平均需要访问n0/2个SST文件。如果key在非L0层,那L0层的SST文件一般都需要访问,其余每一层都需要访问一个SST文件,所以需要访问的SST文件数为l+n0。
E-LRU
对于普通的LRU队列来说,它仅仅只通过数据访问的时刻这个参量来实现数据的换入换出。但是,这篇论文上文已经提到过,对于LSM树来说,缓冲队列中每个元素的缓冲效率因子是不同的,因此还需要考虑缓冲效率这个参量。在LRU的基础上,这篇论文设计了E-LRU队列。总的来说,在evict元素时,E-LRU会搜索a个最久未被访问的元素,然后将缓冲效率因子最低的元素驱逐出缓冲区。a的计算方式如下:
a=ev
上式中,e为自然基底。v表示当前缓冲区中,各个元素的缓冲效率因子的标准差。如果缓冲区元素很多的话,那么精确地计算标准差是不现实的,所以论文里用的是采样值,具体怎么采样,论文没有具体说明。
HAC-分层自适应缓冲(Hierarchical Adaptive Caching)
HAC将不同的cache组件分为两层管理:
- 上层为Point-Cache与BlockCache
- 下层又将Point-Cache分为KV-Cache和KP-Cache
- 每一层级管理的Cache大小都是自适应动态调整的
- 为了动态调整不同cache的size,与ARC类似,HAC使用了4个Ghost-Cache:Point-Ghost-Cache, Block-Ghost-Cache, KV-Ghost-Cache, KP-Ghost-Cache
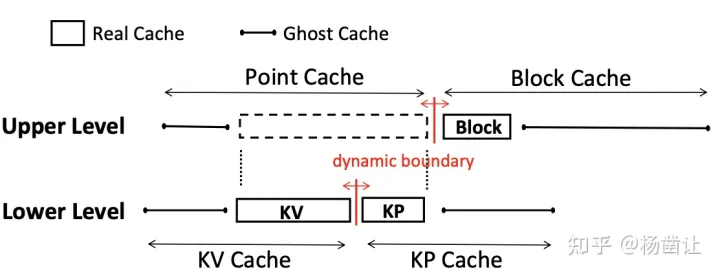
下层HAC
主要关注: HAC怎么利用每个缓冲条目的缓冲效率因子动态调整不同Cache的边界。
整体来说下层HAC用于管理PointCache, 主要涉及了4个Cache组件:
- KV Real Cache, 记为Rkv
- KP Real Cache, 记为Rkp
- KV Ghost Cache, 记为Gkv
- KP Ghost Cache, 记为Gkp
如果用绝对值符号表示一个Cache的size,显而易见:
|Rkv|+|Rkp|=|PointCache|
GhostCache只存储被evicted掉的数据条目的元数据信息,用绝对值符号表示GhostCache表示缓冲的数据代指的总数据大小,那么GhostCache有下面的等式:
|PointCache|=|Rkv|+|Rkp|=|Rkv|+|Gkv|=|Rkp|+|Gkp|
如何处理cache-miss和cache-hit:
- Real Cache Hit: 如果命中了Rkv或者Rkp,那么与普通的LRU算法一样,调整命中的数据在LRU队列中的位置就好。特别地,如果命中的是Rkp,那么需要将数据从磁盘上读出来,然后调整到Rkv中。
- KV Ghost Cache Hit: 如果命中了Gkv,表示Rkv的size要增大,那么将Rkv的目标size增加kE大小的size,这里面的k是一个经验值常量,E是命中的数据的缓冲效率因子。接着将数据从磁盘读入并做替换策略,替换的时候根据Rkv的目标size,需要evict掉Rkv或者Rkp的一部分数据。
- KP Ghost Cache Hit: 如果命中了Gkp,表示Rkp的size要增大,那么将Rkp的目标size增加kE。接着将数据从磁盘读入后插到Rkv中,然后根据Rkp的目标size,evict掉Rkv的一部分数据。ps. 这里论文中说还需要evict掉Rkp的数据,我觉得是说不通的,因为Rkp的size增大了,而且并没有新的数据写入。
- Cache Miss: 从磁盘中读取数据后,将数据适配成KP模式存储到Rkp中,然后做eviciton。
上述eviciton的过程都遵循前文描述的E-LRU的eviciton策略
上层HAC
与下层HAC一样,上层HAC也通过GhostCache调整PointCache与BlockCache的边界。整个过程涉及到下面几个Cache对象:
- BlockCache与PointCache,分别记为Rblock和Rpoint。注意这里的PointCache由KVCache和KPCache构成
- BlockGhostCache与PointGhostCache,分为记为Gblock和Gpoint。从Rblock被evict出的数据将会被Gblock记录,从Rpoint被evict出的数据将被Gpoint记录。注意:上层Gpoinnt记录数据的同时,下层Gkv和Rkv也要做相应记录。
上面这些对象满足下式:
Stotal=|Rblock|+|Rpoint|=|Rblock|+|Gblock|=|Rpoint|+|Gpoint|
目标边界调整
如果命中了Gblock,那么增大Rblock的size,减少Rpoint的size,size变化的大小为kE。因为Rpoint由Rkv和Rkp组成,那么变化的size满足加权平均关系:
|Rkv|←|Rkv|−Δ|Rkv||Rkv|+|Rkp|
|Rkp|←|Rkp|−Δ|Rkp||Rkv|+|Rkp|
如果命中了Gpoint,那么要增大Rpoint的size,调整的方式为:
- 因为命中了Gpoint,那么也一定命中了Gkv或者Rkv, 所以先按照上文的方法做下层HAC的调整。
- 做完下层HAC调整后,然后按照加权平均的方式再次调整KVCache和KPCache的size。
一些实验结果
AC-Key对于点查为主导的workloads有巨大提升, 其他场景相比rocksdb提升不大。
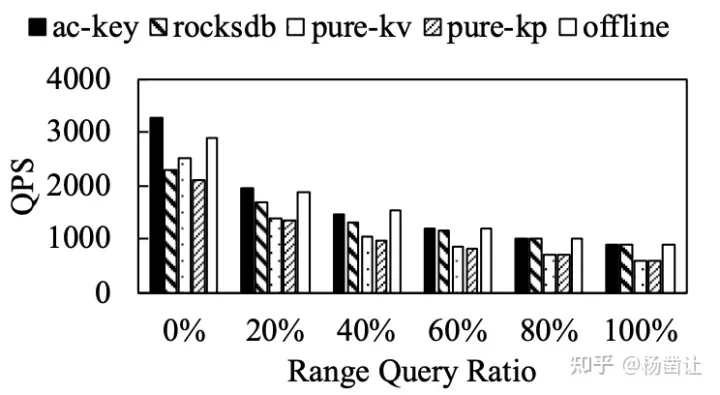
如果用户访问的数据模型是均匀分布的,除了调大CacheSize以外,几乎所有的Cache策略都没有很好的效果。


















 3265
3265

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









