







近年来,数据挖掘界普遍认为,时间序列分析中的许多问题本质上都可以归结为发现并推理时间序列中的重复结构。现有的工具可以发现单个时间序列(motif)和时间序列对(join)之间的保守结构。然而,到目前为止,还没有工具来发现时间序列集中的重复结构,我们将这种想法称为时间序列共识motif,以识别它们与DNA字符串中离散类似物的相似性。本文提出一种时间序列共识motif的定义,以及一种可扩展的算法,用于在大规模数据集中发现它们。本文进一步表明,给定这个新原语,可以解决时间序列数据挖掘中的多个更高层次的问题。在动物运动研究、人类行为、医学和能量分解等不同领域的案例研究中,证明了所提出想法的实用性。
我们把时间序列数据集中的重复结构,时间序列共识motif,

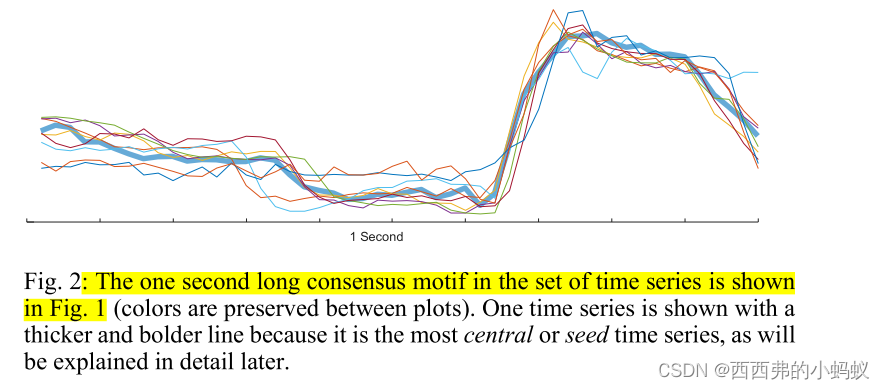
我们现在要问相应的问题,是否存在一个保守的模式,覆盖一秒的间隔,出现在每个时间序列中?在本文提出的定义下,最佳答案如图2所示。

Ostinato: Fast Consensus Motif Search
我们将共识motif搜索算法称为Ostinato。Ostinato首先通过蛮力方法计算每个候选子序列的下界。这个下界序列既用于排序我们的搜索,也用于允许地修剪不有希望的候选项。
总结:在集合中找到多个时间序列之间共存的motif ,即为共识motif问题,这类似于k-维度motif发现问题
















 385
385











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









