







一.实验原理
1.Huffman编码的步骤:
(1)首先将所有字符发生的概率从小到大进行排序;
(2)将最小的两个概率进行两两一合并,之后继续找最小的两个概率进行合并包括前面已经合并的和数;
(3)一步步合并直到最终的根处为1就此形成了一棵二叉树,再进行码字编写,从根部开始树枝处左零右一在,或是左一右零均可以,从根到树叶的部分形成一个码字,依次读出码字形成码表完成最终的编码。
2.二叉树的基本结构及其定义:
完成Huffman编码的主要步骤就是二叉树的建立,二叉树主要有中间节点和树叶的区分,对树叶而言是没有孩子的,而中间节点则是有孩子的;
(1)哈夫曼节点结构
typedef struct huffman_node_tag //节点数据类型
{
unsigned char isleaf; //1表示为叶节点,0表示不是叶节点
unsigned long count; //这个字节在文件中出现的次数
struct huffman_node_tag *parent; //父节点指针
union
{
struct
{ //如果不是叶节点,这里则是左右子节点指针
struct huffman_node_tag *zero,*one;
}
unsigned char symbol; //节点代表符号,如果为叶节点,这里则是一个字节的8位二进制数
};
}huffman_node;
(2)哈夫曼码字结构
typedef struct huffman_code_tag //码字数据类型
{
unsigned long numbits;// 该码所用的比特数
unsigned char *bits; // 指向该码比特串的指针
}huffman_code;
二.实验流程
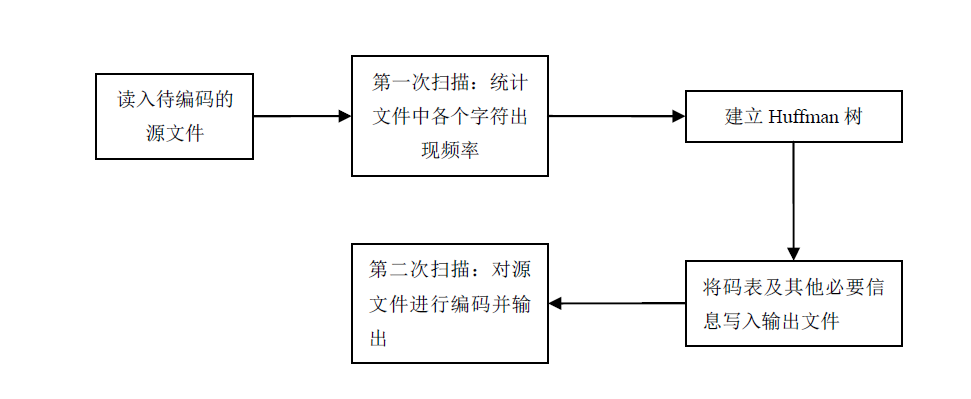
(1)读入文件;
(2)第一次扫描文件统计各个字节出现的概率;
(3)建立Huffman树;
(4)将码表以及其他必要信息写入输出文件;
(5)第二次扫描文件,对源文件进行编码输出;
三.主要代码分析
主函数:
#include "huffman.h"
#include <stdio.h>
#include <string.h>
#include <errno.h>
#include <stdlib.h>
#include <assert.h>
#include "getopt.h"
#pragma comment(lib,"ws2_32.lib")
#ifdef WIN32
#include <malloc.h>
extern int getopt(int, char**, char*);
extern  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









