







对于刚入门深度学习的小白来说,学习代码是一件让人觉得头疼的事情,笔者刚入门时也是非常的苦恼。网上代码基本上都是有偿的,学习成本高昂。因此,笔者整理了经典的LSTM时间序列预测python代码免费提供给大家,希望对大家有帮助。
废话不多说,他来了~~~~ !!!!
记得点赞哦
# 帅气的笔者
# coding: utf-8
import numpy as np
import pandas as pd
import math
from matplotlib import pyplot as plt
from tensorflow.keras.models import Sequential
from sklearn.preprocessing import MinMaxScaler
from keras.layers import Dense, Activation, Dropout, LSTM, Bidirectional
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置中文字体为SimHei
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
# parse_dates参数将csv中的时间字符串转换成日期格式,设置第一列为索引值
df=pd.read_csv("天气.csv", parse_dates=["time"], index_col=[0], encoding='gbk')
df.shape # 执行df.shape会返回一个元组,该元组的第一个元素代表行数,第二个元素代表列数,这就是这个数据的基本形状,也是数据的大小
df.head() # .df.head (n):该方法用于查看dataframe数据表中开头n行的数据,若参数n未设置,即df.head (),则默认查看dataframe中前5行的数据。
dataframe = pd.read_csv('天气.csv',header=0, parse_dates=[0],index_col=0, usecols=[0, 1], squeeze=True)
#读取csv文件,文件名为’焦作.csv’,header=0表示第一行为列名,parse_dates=[0]表示将第一列解析为日期格式,index_col=0表示将第一列设置为索引列,usecols=[0, 1]表示只读取第一列和第二列,squeeze=True表示将读取的数据转换为Series类型
dataset = dataframe.values
test_split=round(len(df)*0.20) # round() 方法返回浮点数x的四舍五入值。
df_for_training=df[:-test_split] # 前80%为训练集合
df_for_testing=df[-test_split:]
print(df_for_training.shape)
print(df_for_testing.shape)
scaler = MinMaxScaler(feature_range=(0,1))
training_scaled = scaler.fit_transform(df_for_training)
testing_scaled=scaler.transform(df_for_testing)
def create(dataset,look_back):
dataX = []
dataY = []
for i in range(look_back, len(dataset)):
dataX.append(dataset[i - look_back:i, 0:dataset.shape[1]])
dataY.append(dataset[i,0])
return np.array(dataX),np.array(dataY)
look_back = 30
trainX,trainY=create(training_scaled,look_back)
testX,testY=create(testing_scaled,look_back)
model = Sequential()
model.add((LSTM(units=100, return_sequences=True)))
model.add((LSTM(units=200, return_sequences=True)))
model.add((LSTM(300, return_sequences=False)))
model.add(Dropout(0.1))
model.add(Dense(1))
model.add(Activation('relu'))
model.compile(loss='mean_squared_error', optimizer='Adam')
history = model.fit(trainX, trainY, batch_size=10, epochs=10, validation_split=None, verbose=2)
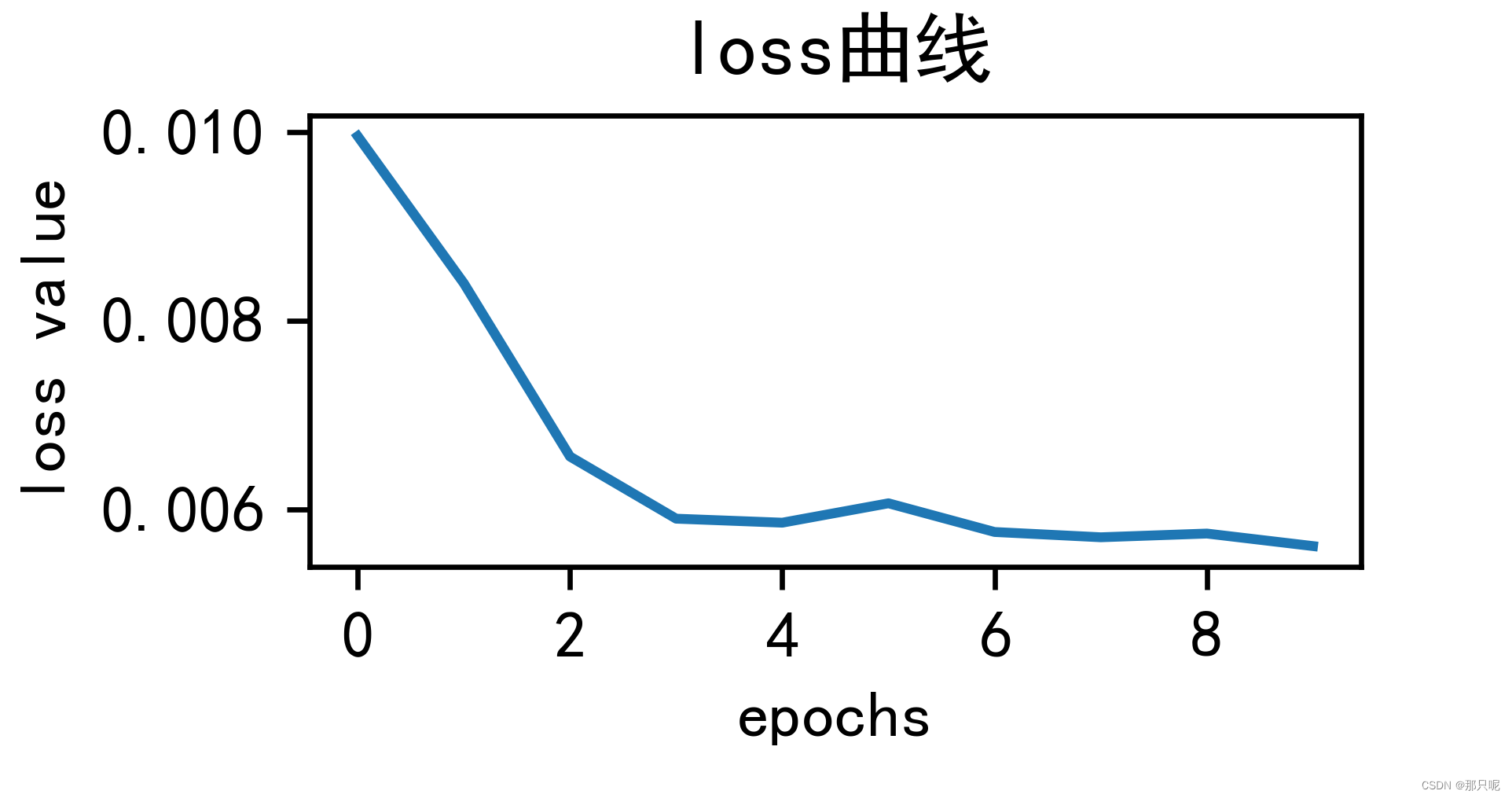
fig1 = plt.figure(dpi=600,figsize=(15, 4))
plt.plot(history.history['loss'])
plt.title('loss曲线')
plt.ylabel('loss value')
plt.xlabel('epochs')
plt.show()
trainPredict = model.predict(trainX)
testPredict = model.predict(testX)
prediction_copies_array = np.repeat(testPredict,7, axis=-1)
pred=scaler.inverse_transform(np.reshape(prediction_copies_array,(len(testPredict),7)))[:,0]
original_copies_array = np.repeat(testY,7, axis=-1)
original=scaler.inverse_transform(np.reshape(original_copies_array,(len(testY),7)))[:,0]
testScore = math.sqrt(mean_squared_error(original, pred))
#使用 mean_squared_error 函数计算原始数据的真实值 original 和预测值 pred 之间的均方根误差(RMSE)
#使用 math.sqrt 函数对均方根误差进行开方,得到测试数据的 RMSE 值,即 testScore
print('RMSE %.4f ' %(testScore))
testScore = mean_absolute_error(original, pred)
#使用 mean_absolute_error 函数计算原始数据的真实值 original 和预测值 pred 之间的平均绝对误差(MAE)
#得到测试数据的 MAE 值,即 testScore
print('MAE %.4f ' %(testScore))
testScore = r2_score(original, pred)
#使用 r2_score 函数计算原始数据的真实值 original 和预测值 pred 之间的 R2 得分
#得到测试数据的 R2 得分,即 testScore
print('R2 %.4f ' %(testScore))
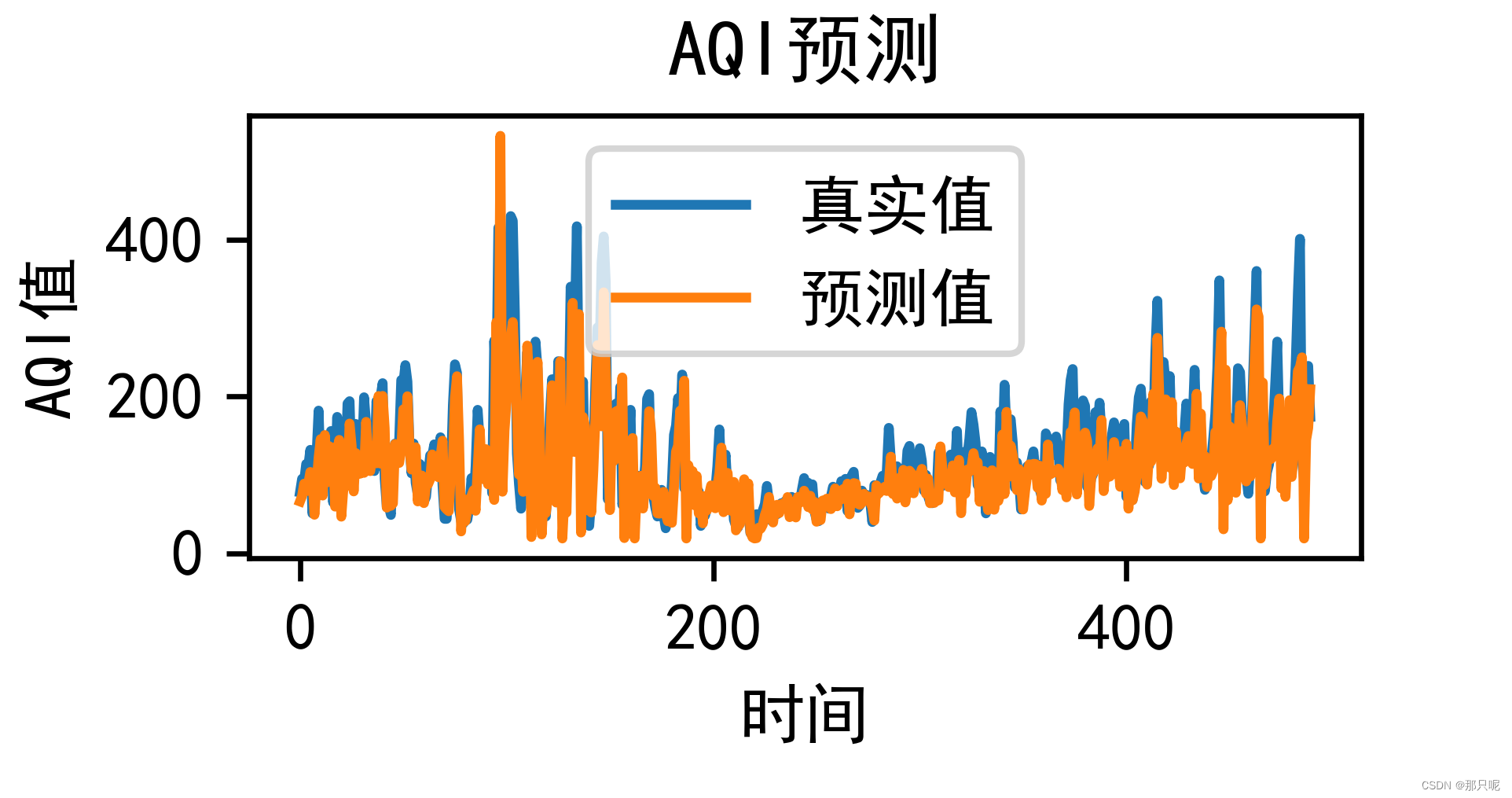
plt.figure(dpi=600, figsize=(10, 3))
plt.plot(original, label = '真实值')
plt.plot(pred, label = '预测值')
plt.title('AQI预测')
plt.xlabel('时间')
plt.ylabel('AQI值')
plt.legend()
plt.show()
更多时间序列python代码获取链接: 时间序列预测算法全集合--深度学习
















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









