






 本文详细介绍了如何使用CNN-BiLSTM-Attention模型进行时间序列预测,包括数据预处理、模型构建、训练和评估过程,以及展示预测结果。作者分享了Python代码片段以供读者参考。
本文详细介绍了如何使用CNN-BiLSTM-Attention模型进行时间序列预测,包括数据预处理、模型构建、训练和评估过程,以及展示预测结果。作者分享了Python代码片段以供读者参考。
整理了CNN-BiLSTM-Attention时间序列预测模型python代码分享给大家,记得点赞哦!
#帅帅的笔者
# coding: utf-8
from keras.layers import Input, Dense, LSTM ,Conv1D,Dropout,Bidirectional,Multiply,Concatenate,BatchNormalization
from keras.models import Model
from sklearn.metrics import r2_score, mean_squared_error, mean_absolute_error
from keras.layers.core import *
from keras.models import *
from keras.utils.vis_utils import plot_model
from keras import optimizers
import numpy
import numpy as np
import pandas as pd
import math
import datetime
import matplotlib.pyplot as plt
from pandas import read_csv
from keras.models import Sequential
from keras.layers import Dense
from sklearn.preprocessing import MinMaxScaler
from keras import backend as K
def attention_function(inputs, single_attention_vector=False):
TimeSteps = K.int_shape(inputs)[1]
input_dim = K.int_shape(inputs)[2]
a = Permute((2, 1))(inputs)
a = Dense(TimeSteps, activation='softmax')(a)
if single_attention_vector:
a = Lambda(lambda x: K.mean(x, axis=1))(a)
a = RepeatVector(input_dim)(a)
a_probs = Permute((2, 1))(a)
output_attention_mul = Multiply()([inputs, a_probs])
return output_attention_mul
def creat_dataset(dataset, look_back):
dataX, dataY = [], []
for i in range(len(dataset) - look_back - 1):
a = dataset[i: (i + look_back)]
dataX.append(a)
dataY.append(dataset[i + look_back])
return np.array(dataX), np.array(dataY)
dataframe = pd.read_csv('天气.csv', header=0, parse_dates=[0], index_col=0, usecols=[0, 1])
dataset = dataframe.values
scaler = MinMaxScaler(feature_range=(0, 1))
dataset = scaler.fit_transform(dataset.reshape(-1, 1))
train_size = int(len(dataset) * 0.8)
test_size = len(dataset) - train_size
train, test = dataset[0: train_size], dataset[train_size: len(dataset)]
look_back = 5
trainX, trainY = creat_dataset(train, look_back)
testX, testY = creat_dataset(test, look_back)
def attention_model():
inputs = Input(shape=(look_back, 1))
x = Conv1D(filters = 128, kernel_size = 1, activation = 'relu')(inputs)
BiLSTM_out = Bidirectional(LSTM(64, return_sequences=True,activation="relu"))(x)
Batch_Normalization = BatchNormalization()(BiLSTM_out)
Drop_out = Dropout(0.1)(Batch_Normalization)
attention = attention_function(Drop_out)
Batch_Normalization = BatchNormalization()(attention)
Drop_out = Dropout(0.1)(Batch_Normalization)
Flatten_ = Flatten()(Drop_out)
output=Dropout(0.1)(Flatten_)
output = Dense(1, activation='sigmoid')(output)
model = Model(inputs=[inputs], outputs=output)
return model
model = attention_model()
model.compile(loss='mean_squared_error', optimizer='adam')
model.summary()
history = model.fit(trainX, trainY, epochs=100, batch_size=64, verbose=0,validation_data=(testX, testY))
trainPredict = model.predict(trainX)
testPredict = model.predict(testX)
trainPredict = scaler.inverse_transform(trainPredict)
trainY = scaler.inverse_transform(trainY)
testPredict = scaler.inverse_transform(testPredict)
testY = scaler.inverse_transform(testY)
testScore = math.sqrt(mean_squared_error(testY, testPredict[:, 0]))
print('RMSE %.3f' %(testScore))
testScore = mean_absolute_error(testY, testPredict[:, 0])
print('MAE %.3f' %(testScore))
testScore = r2_score(testY, testPredict[:, 0])
print('R2 %.3f' %(testScore))
trainPredictPlot = np.empty_like(dataset)
trainPredictPlot[:] = np.nan
trainPredictPlot = np.reshape(trainPredictPlot, (dataset.shape[0], 1))
trainPredictPlot[look_back: len(trainPredict) + look_back, :] = trainPredict
testPredictPlot = np.empty_like(dataset)
testPredictPlot[:] = np.nan
testPredictPlot = np.reshape(testPredictPlot, (dataset.shape[0], 1))
testPredictPlot[len(trainPredict) + (look_back * 2) + 1: len(dataset) - 1, :] = testPredict
plt.plot(history.history['loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.show()
M = scaler.inverse_transform(dataset)
N = scaler.inverse_transform(test)
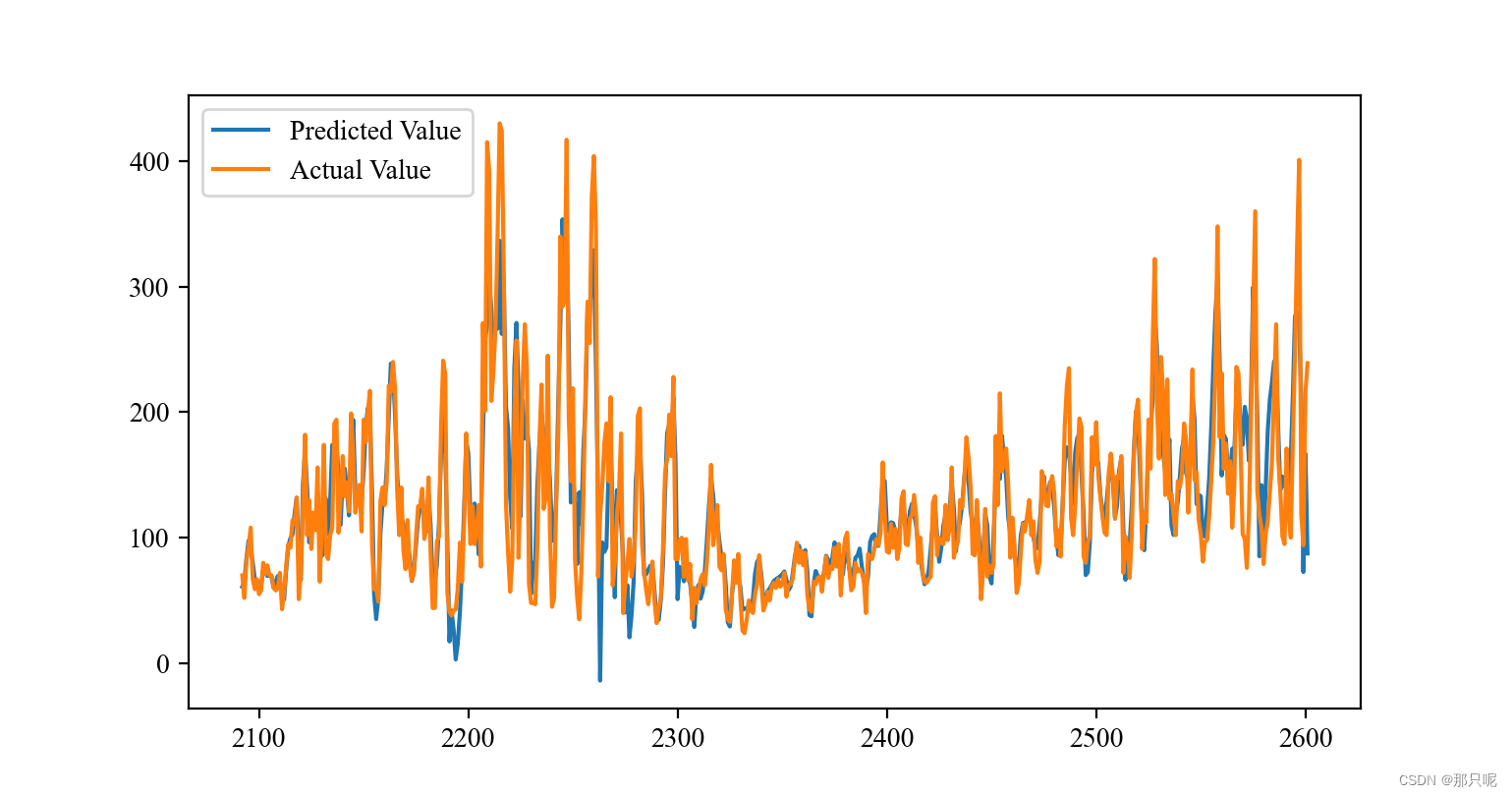
plt.figure(figsize=(10, 3),dpi=200)
plt.plot(range(len(train),len(dataset)),N, label="Actual", linewidth=1)
plt.plot(testPredictPlot, label='Prediction',linewidth=1,linestyle="--")
plt.title('CNN-BiLSTM-attention Prediction', size=10)
plt.ylabel('AQI',size=10)
plt.xlabel('时间',size=10)
plt.legend()
plt.show()
更多55+时间序列预测python代码获取链接:时间序列预测算法全集合--深度学习
















 238
238











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









