







整理了30种回归预测组合模型的matlab代码,效果优异,配备数据集,选取了MSE、RMSE、MAE、MAPE四种评价指标。模型主要有CNN-BiLSTM-GRU,CNN-BiLSTM-Attention、CNN-BILSTM-Adaboost、ELM-Adaboost、RF-Adaboost、TCN-GRU-Attention、TCN-BiGRU-Attention等等。
代码获取链接:30种回归预测组合模型的matlab代码
1、CNN-GRU
…………训练集误差指标…………
1.均方差(MSE):5.4571
2.根均方差(RMSE):2.336
3.平均绝对误差(MAE):1.8588
4.平均相对百分误差(MAPE):6.1163%
5.R2:75.8178%
…………CNN-BiGRU-测试集误差指标…………
1.均方差(MSE):14.1105
2.根均方差(RMSE):3.7564
3.平均绝对误差(MAE):2.4333
4.平均相对百分误差(MAPE):7.8314%
5.R2:18.7983%

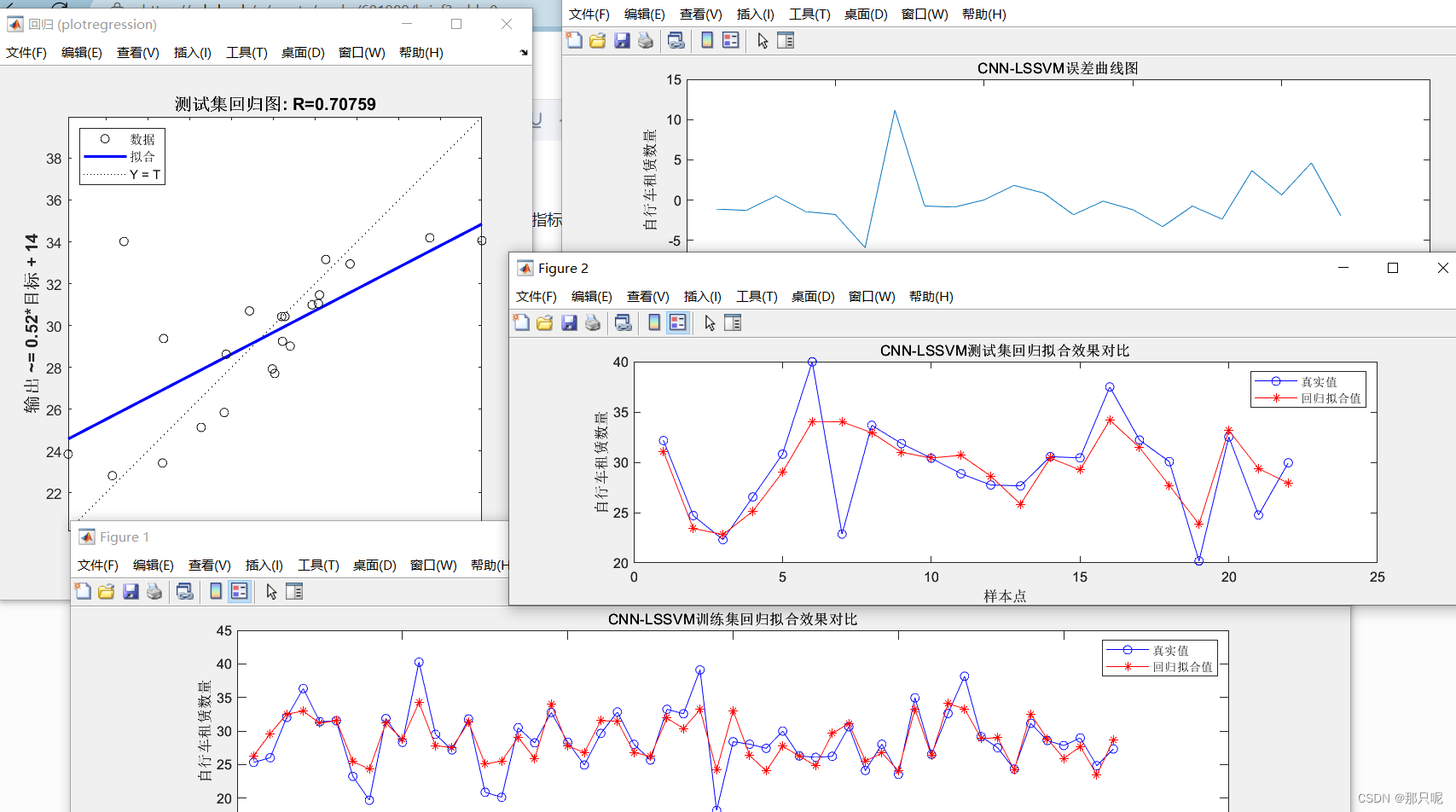
2、CNN-LSSVM
…………训练集误差指标…………
1.均方差(MSE):6.3618
2.根均方差(RMSE):2.5223
3.平均绝对误差(MAE):1.9019
4.平均相对百分误差(MAPE):6.4803%
5.R2:69.0622%
…………CNN-LSSVM测试集误差指标…………
1.均方差(MSE):10.6481
2.根均方差(RMSE):3.2631
3.平均绝对误差(MAE):2.1829
4.平均相对百分误差(MAPE):7.0261%
5.R2:49.9877%
3、ELM-Adaboost
1.均方差(MSE):1510.6054
2.根均方差(RMSE):38.8665
3.平均绝对误差(MAE):29.3337
4.平均相对百分误差(MAPE):0.99604%
5.R2:99.9615%
6.剩余预测残差RPD:50.9503
…………ELM-Adaboost测试集误差指标…………
1.均方差(MSE):703.2068
2.根均方差(RMSE):26.518
3.平均绝对误差(MAE):17.4717
4.平均相对百分误差(MAPE):0.53958%
5.R2:99.9789%
6.剩余预测残差RPD:69.1373

4、RF-Adaboost
…RF-Adaboost训练集误差指标…………
1.均方差(MSE):16131.4795
2.根均方差(RMSE):127.0098
3.平均绝对误差(MAE):86.2572
4.平均相对百分误差(MAPE):2.5626%
5.R2:99.5389%
6.剩余预测残差RPD:14.727
…………RF-Adaboost测试集误差指标…………
1.均方差(MSE):84314.6317
2.根均方差(RMSE):290.3698
3.平均绝对误差(MAE):207.9698
4.平均相对百分误差(MAPE):6.3907%
5.R2:97.3893%
6.剩余预测残差RPD:6.1921

5、tcn-bigru
…………训练集误差指标…………
1.均方差(MSE):10130.8496
2.根均方差(RMSE):100.6521
3.平均绝对误差(MAE):69.7368
4.平均相对百分误差(MAPE):1.2992%
5.R2:99.7207%
…………训练集误差指标…………
1.均方差(MSE):10130.8496
2.根均方差(RMSE):100.6521
3.平均绝对误差(MAE):69.7368
4.平均相对百分误差(MAPE):1.2992%
5.R2:99.7207%
…………tcn-bigru测试集误差指标…………
1.均方差(MSE):21390.8906
2.根均方差(RMSE):146.2563
3.平均绝对误差(MAE):95.9158
4.平均相对百分误差(MAPE):1.7985%
5.R2:99.4693%
















 7219
7219











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









