







Task04:建模与调参
赛题:零基础入门数据挖掘 - 二手车交易价格预测
地址:https://tianchi.aliyun.com/competition/entrance/231784/information
1 内容介绍
2.代码示例
2.1读取数据
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings('ignore')
下面的reduce_mem_usage 函数通过调整数据类型,帮助我们减少数据在内存中占用的空间,可在每个dataframe上节省60%到75%的内存使用量。
# 该代码实现了Python中内存的优化,可直接调用。
def reduce_mem_usage(df):
""" iterate through all the columns of a dataframe and modify the data type
to reduce memory usage.
"""
start_mem = df.memory_usage().sum()
print('Memory usage of dataframe is {:.2f} MB'.format(start_mem))
for col in df.columns:
col_type = df[col].dtype
if col_type != object:
c_min = df[col].min()
c_max = df[col].max()
if str(col_type)[:3] == 'int':
if c_min > np.iinfo(np.int8).min and c_max < np.iinfo(np.int8).max:
df[col] = df[col].astype(np.int8)
elif c_min > np.iinfo(np.int16).min and c_max < np.iinfo(np.int16).max:
df[col] = df[col].astype(np.int16)
elif c_min > np.iinfo(np.int32).min and c_max < np.iinfo(np.int32).max:
df[col] = df[col].astype(np.int32)
elif c_min > np.iinfo(np.int64).min and c_max < np.iinfo(np.int64).max:
df[col] = df[col].astype(np.int64)
else:
if c_min > np.finfo(np.float16).min and c_max < np.finfo(np.float16).max:
df[col] = df[col].astype(np.float16)
elif c_min > np.finfo(np.float32).min and c_max < np.finfo(np.float32).max:
df[col] = df[col].astype(np.float32)
else:
df[col] = df[col].astype(np.float64)
else:
df[col] = df[col].astype('category')
end_mem = df.memory_usage().sum()
print('Memory usage after optimization is: {:.2f} MB'.format(end_mem))
print('Decreased by {:.1f}%'.format(100 * (start_mem - end_mem) / start_mem))
return df
sample_feature = reduce_mem_usage(pd.read_csv('data_for_tree.csv'))
 可以看出数据内存大小压缩了73.4%。
可以看出数据内存大小压缩了73.4%。
continuous_feature_names = [x for x in sample_feature.columns if x not in ['price','brand','model']]
这里不太懂,为什么continuous_feature_names中要去掉brand和model这两个特征???
print(continuous_feature_names)
print(len(continuous_feature_names))# 计算list中的元素个数应该用len(),不能用.shape(这是数组numpy.array的属性)
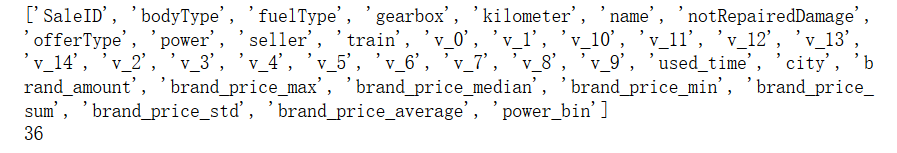
2.2线性回归 & 五折交叉验证 & 模拟真实业务情况
sample_feature = sample_feature.dropna().replace('-', 0).reset_index(drop=True)
sample_feature['notRepairedDamage'] = sample_feature['notRepairedDamage'].astype(np.float32)
train = sample_feature[continuous_feature_names + ['price']]
train_x = train[continuous_feature_names]
train_y = train['price']
1)简单建模(线性回归)
from sklearn.linear_model import LinearRegression
model = LinearRegression(normalize=True) #normalize:是否将数据归一化
model =model.fit(train_x,train_y)
查看训练的线性回归模型的截距(intercept)和权重(coef)
- zip() :可以将两个可迭代的对象,组合返回成一个元组数据
- dict() :使用元组数据构建字典
- items方法 :items() 函数以列表返回可遍历的(键, 值) 元组数组
- sort(iterable, cmp, key, reverse) :排序函数
- iterable - 指定要排序的list或者iterable
- key - 指定取待排序元素的哪一项进行排序 - 这里x[1]表示按照列表中第二个元素排序
- reverse - 是一个bool变量,表示升序还是降序排列,默认为False(升序)
print('intercept:'+ str(model.intercept_))
# 这行代码返回了每个特征的权重,按照权重降序排列
sorted(dict(zip(continuous_feature_names, model.coef_)).items(), key=lambda x:x[1], reverse=True)

from matplotlib import pyplot as plt
subsample_index = np.random.randint(low=0, high=len(train_y), size=50)
#这里随机出现的subsampl 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 273
273











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









