







首先
import matplotlib.pyplot as plt
import numpy as np
(1)Figure
plt.figure() #创建新的Figure。
#不能使用空Figure画图,必须使用add_subplot创建一个或者多个subplot
ax=fig.add_subplot(2,2,1) #图像一共2×2个,当前选中的是第一个。
ax2=fig.add_subplot(2,2,2)
plt.plot(np.random.randn(10).cumsum()) #画图
plt.show() #显示画的图
(2)颜色、标记、线型
plt.plot(np.random.randn(10).cumsum(),color='k',linestyle='dashed',marker='o')
#颜色、线型、标记节点
(3)刻度、标签和图例
plt.xlim([l,r]) #调整x轴的刻度范围,从l到r。
ax.set_xticks([0,250,500,750,1000]) #设置刻度标签的分布位置
ax.set_xticklabels(['a','b','c','d'],rotation=30,fontsize='small') #设置x轴的标签
ax.set_xlabel('') #为x轴设置名称
ax.set_title() #设置标题
#y轴同理
添加图例:
ax.plot(np.random.randn(1000).cumsum(),’k’,label=’one’)
ax.plot(np.random.randn(1000).cumsum(),’k--’,label=’two’)
(4)注解
可以使用text函数
# 第一个参数是x轴坐标
# 第二个参数是y轴坐标
# 第三个参数是要显式的内容
# alpha 设置字体的透明度
# family 设置字体
# size 设置字体的大小
# style 设置字体的风格
# wight 字体的粗细
# bbox 给字体添加框,alpha 设置框体的透明度, facecolor 设置框体的颜色
ax.text(x,y,’hello’,family=’monospace‘,fontsize=10) #x,y是注释所在的坐标位置
或者
annotate函数
# 添加注释
# 第一个参数是注释的内容
# xy设置箭头尖的坐标
# xytext设置注释内容显示的起始位置
# arrowprops 用来设置箭头
# facecolor 设置箭头的颜色
# headlength 箭头的头的长度
# headwidth 箭头的宽度
# width 箭身的宽度
plt.annotate(u"hello", xy = (0, 1), xytext = (-4, 50),arrowprops = dict(facecolor = "r", headlength = 10, headwidth = 30, width = 20))
# 可以通过设置xy和xytext中坐标的值来设置箭身是否倾斜
(5)将图表保存到文件
plt.savefig('temp.png') #将当前的图表保存到文件。
plt.savefig('temp.png',bbox_inches=’tight’) #剪除周围的空白部分。
对于pandas对象 ,有自带的画图函数
(6)pandas对象画线型图
obj.plot() #obj是一个Series对象,可以直接画
frame.plot() #DataFrame同理,并且可以自动生成图例
#plot()中可以加入调整x、y轴刻度,标题等众多参数
(7)pandas对象画柱状图
frame.plot(kind='bar') #画DataFrame对象的柱状图
(8)直方图和密度曲线
直方图是数值数据分布的精确图形表示。 这是一个连续变量(定量变量)的概率分布的估计,并且被卡尔·皮尔逊(Karl Pearson)首先引入。它是一种条形图。 为了构建直方图,第一步是将值的范围分段,即将整个值的范围分成一系列间隔,然后计算每个间隔中有多少值。 这些值通常被指定为连续的,不重叠的变量间隔。 间隔必须相邻,并且通常是(但不是必须的)相等的大小。
直方图也可以被归一化以显示“相对”频率。 然后,它显示了属于几个类别中的每个案例的比例,其高度等于1。
obj.hist(normed=True) #normed=True目的是归一化,默认不归一化,只统计数量
obj.hist(normed=True,bins=2) #这个参数指定bin(箱子)的个数,也就是总共有几条条状图
密度曲线:在频率分布直方图中,当样本容量充分放大时,图中的组距就会充分缩短,这时图中的阶梯折线就会演变成一条光滑的曲线,这条曲线就称为总体的密度分布曲线。这条曲线排除了由于取样不同和测量不准所带来的误差,能够精确地反映总体的分布规律。
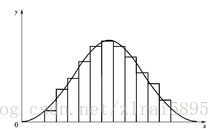
obj.plot(kind='kde') #画密度图(标准混合密度分布)
(9)散点图
plt.scatter(x,y) #x,y是两个同样大小的一维数组















 3633
3633

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









