






前面介绍了Langchain的基本使用方法。仅仅是对GPT方法的封装还不足以让它赢得那么多的Start,以及获得融资。它还有另一个强大的功能-RAG(检索增强生成)。RAG是大模型跟企业内部业务落地的基石。是大模型的北斗导航,可以让大模型的结果更加精准。
一、RAG 的基本概念与实现流程
基于大语言模型(LLM)的应用已经随处可见,工作生活都去大模型问一问,对于很多人已经成为一种习惯,细心的你或许会发现LLM 存在的一个显著问题:它们的回答往往过于依赖训练数据,无法访问实时信息,导致出现“幻想问题”(即生成不符合实际情况的回答)。为了解决这个问题,业界提出了 RAG(Retrieval-Augmented Generation,检索增强生成)这一方案。
RAG 的核心思想是:在生成回答前,通过查询外部数据库或文档库检索相关信息,然后将这些检索到的内容嵌入到 LLM 的上下文中,从而提高生成的准确性和质量。通过这种方式,LLM 不仅可以从内部训练数据中进行生成,还能够结合实时数据做出更加符合实际的回答。
Langchain.js 也支持数据切割、向量化、存储到检索、生成的完整流程,可以很好地实现 RAG。
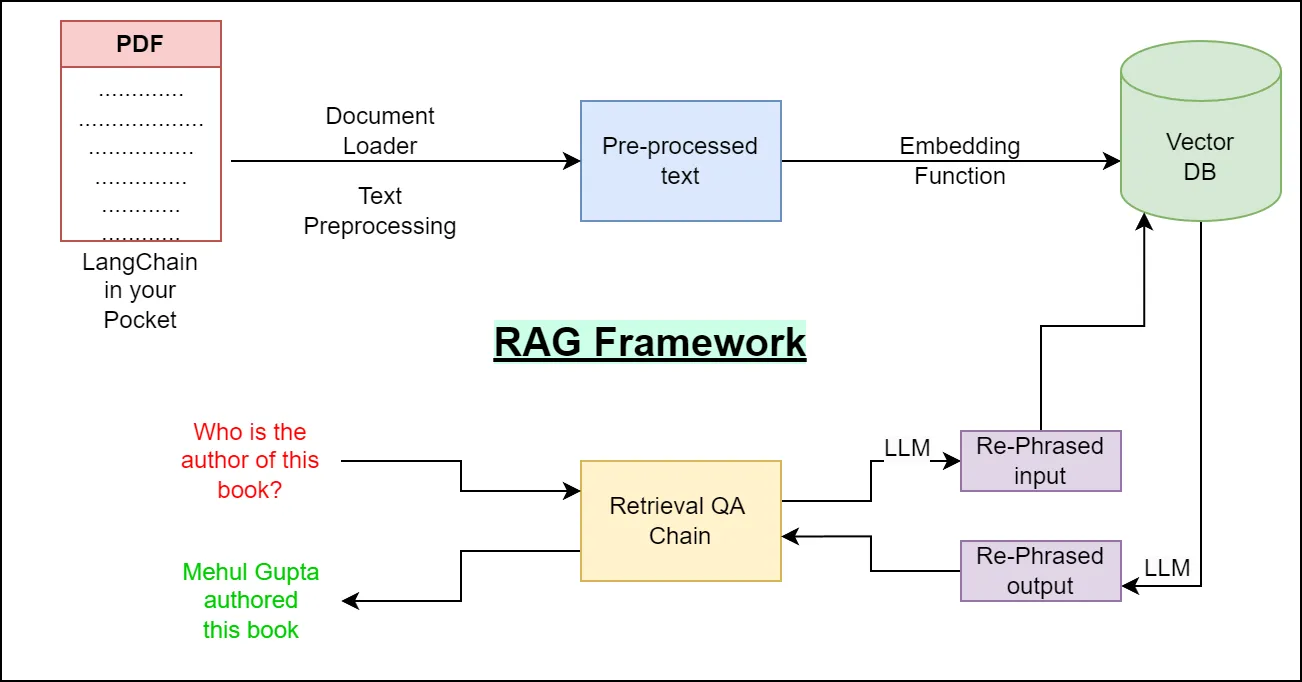
要实现 RAG,我们需要经历以下几个关键步骤:
-
切割(Chunking):由于大模型的上下文长度有限,长文档需要被合理切割成小块,方便向量化和检索。通常在 200 到 500 个字符之间是一个常见的选择。这种大小的片段既能保持较好的上下文完整性,又不会太大以至于超出模型的输入限制。
-
向量化(Embedding):将切割后的文档转化为向量表示,这样我们可以在向量空间中快速查找相关文档。也就是将文本表示为模型可以理解和处理的形式。不同模型对同一数据进行向量化后的结果通常是不同的。
-
存储(Storage):将文档和对应的向量存储到向量数据库中,便于后续的检索。
-
检索(Retrieval):根据用户的查询,将查询向量化后从数据库中检索出相关的文档。
-
增强与生成(Augmentation & Generation):将检索到的文档插入 LLM 的 prompt 中,从而生成高质量的回答。
RAG 的整个流程从输入用户的查询开始,经过嵌入模型向量化、数据库检索和增强,最后通过大模型生成符合实际需求的答案。
三、RAG具体实现
1. 文本切割
大模型的上下文长度是有限的,因此我们需要将长文档分成合理的小块,保证每个小块能够独立表达一定的语义。常见的切割策略包括按照句子、段落或固定字符数进行分割。Langchain.js 提供了多种文本切割策略,主要使用 TextSplitter 类来实现。
import { RecursiveCharacterTextSplitter } from 'langchain/text_splitter';
// 创建一个 RecursiveCharacterTextSplitter 实例
const splitter = new RecursiveCharacterTextSplitter({
chunkSize: 500, // 每个文本块的最大字符数
chunkOverlap: 50, // 各文本块之间的重叠字符数,防止信息丢失
});
// 需要进行切割的文本
const text = `
Langchain.js 是一个用于构建语言模型应用的工具库。它可以处理多种类型的任务,包括语义搜索、问答、对话生成等。
文本切割是 Langchain.js 中的重要功能之一,能够将大块文本分割成易于处理的小段。
`;
// 调用 createDocuments 方法进行文本分割
const documents = await splitter.createDocuments([text]);
console.log(documents);
chunkSize 是每个文本块的最大长度,chunkOverlap 用于控制文本块之间的重叠字符。输出的 documents 会是一个包含文本块的数组,每个文本块都不会超过 chunkSize 的限制,并且会在必要时增加重叠部分以保持上下文完整。
除此之外还支持 CharacterTextSplitter 按字符直接切割,MarkdownTextSplitter 进行基于 Markdown 语法的文本切割。通过 Langchain.js 的 TextSplitter 类,你可以灵活地选择不同的文本切割策略,根据具体的文本格式和处理需求,确保切割后的文本块适合进一步处理。
2. 文档向量化
切割后的文本块需要通过嵌入模型进行向量化。Langchain.js 提供了多种方法来实现文档的向量化,主要是通过将文本嵌入(embedding)到向量空间中,以便用于语义搜索、问答系统等自然语言处理任务。
向量化后的文本可以通过距离度量(如余弦相似度)与其他向量进行对比,从而找到最相关的文档。
文档向量化通常包括以下步骤:
-
文本预处理:对文本进行基本的清洗、切割等操作。 -
文本嵌入:使用预训练的语言模型(如 OpenAI、Hugging Face 等)将文本转换为向量。 -
向量存储与检索:将生成的向量存储起来,以便在语义搜索或问答任务中进行高效检索。
在 Langchain.js 中可以直接集成 OpenAI 的嵌入模型来进行向量化处理。以下是一个使用 OpenAI 模型进行文档向量化的示例:
import { OpenAIEmbeddings } from 'langchain/embeddings/openai';
import { RecursiveCharacterTextSplitter } from 'langchain/text_splitter';
// 1. 创建文本切割器,确保长文本能够被处理
const textSplitter = new RecursiveCharacterTextSplitter({
chunkSize: 500,
chunkOverlap: 50,
});
// 2. 定义要向量化的文本
const text = `
Langchain.js 是一个用于构建语言模型应用的工具库,支持多种文本处理功能。
该库提供了文本切割、嵌入生成、文档存储等能力,方便开发者构建复杂的自然语言处理应用。
`;
// 3. 切割文本,生成文档块
const documents = await textSplitter.createDocuments([text]);
// 4. 使用 OpenAI 的 Embeddings API 对文档进行向量化
const embeddings = new OpenAIEmbeddings({
openAIApiKey: 'your-openai-api-key', // 使用你的 API 密钥
});
const vectors = await embeddings.embedDocuments(documents.map(doc => doc.pageContent));
// 输出生成的向量
console.log(vectors);
Langchain.js 也支持集成 Hugging Face 模型,这允许你使用 Hugging Face 提供的各种预训练模型来处理文档向量化。此外也可以保存到向量数据库(如 Pinecone、Weaviate、Faiss 等)中,可以进行高效的相似度搜索。Langchain.js 也支持与这些向量数据库的集成。
import { PineconeClient } from 'pinecone-client';
import { OpenAIEmbeddings } from 'langchain/embeddings/openai';
// 初始化 Pinecone 客户端
const pinecone = new PineconeClient({
apiKey: 'your-pinecone-api-key',
environment: 'us-west1-gcp',
});
await pinecone.createIndex({
indexName: 'document-embeddings',
dimension: 1536, // 这里的维度要与 OpenAI 或其他模型生成的向量维度匹配
});
// 嵌入文档并存储到 Pinecone
const embeddings = new OpenAIEmbeddings({ openAIApiKey: 'your-openai-api-key' });
const vectors = await embeddings.embedDocuments(documents.map(doc => doc.pageContent));
await pinecone.upsert({
indexName: 'document-embeddings',
vectors: vectors.map((vector, idx) => ({
id: `doc-${idx}`,
values: vector,
})),
});
// 在 Pinecone 中检索相似文档
const queryVector = await embeddings.embedQuery("查询文本...");
const results = await pinecone.query({
indexName: 'document-embeddings',
vector: queryVector,
topK: 3,
});
console.log(results);
3、查询与检索
在 Langchain.js 中,查询与检索的核心是将输入的查询文本与已存储的向量化文档进行相似度匹配。这个过程通常称为语义搜索,通过向量化的方式找到与查询最相关的文档。
下面的流程可以帮助你理解如何在 Langchain.js 中进行查询与检索:
-
基本步骤
-
向量化查询:将用户输入的查询文本通过嵌入模型转换为向量。 -
相似度计算:使用向量数据库或本地存储计算查询向量与文档向量之间的相似度(通常使用余弦相似度)。 -
检索最相关的文档:根据相似度返回最相关的文档或信息。
-
使用 OpenAI Embeddings 进行查询与检索
假设我们已经向量化并存储了一些文档,现在我们要对用户的查询进行向量化,并在文档库中查找最相似的文档。
import { OpenAIEmbeddings } from 'langchain/embeddings/openai';
import { PineconeClient } from 'pinecone-client'; // 假设我们使用 Pinecone 作为向量数据库
// 初始化 OpenAI Embeddings 模型
const embeddings = new OpenAIEmbeddings({
openAIApiKey: 'your-openai-api-key',
});
// 初始化 Pinecone 客户端
const pinecone = new PineconeClient({
apiKey: 'your-pinecone-api-key',
environment: 'us-west1-gcp',
});
// 1. 用户输入查询
const queryText = "如何使用 Langchain 进行向量化?";
// 2. 对查询文本进行向量化
const queryVector = await embeddings.embedQuery(queryText);
// 3. 在 Pinecone 中进行向量检索
const results = await pinecone.query({
indexName: 'document-embeddings',
vector: queryVector,
topK: 3, // 返回最相关的3个文档
});
console.log(results);
如果不使用外部向量数据库(如 Pinecone),你可以将向量存储在本地并使用本地算法进行检索。以下是一个使用余弦相似度在本地计算查询与文档相似度的示例。
import { cosineSimilarity } from 'vector-similarity';
// 模拟已存储的文档向量(通常从数据库加载)
const storedVectors = [
{ id: 'doc1', vector: [0.1, 0.2, 0.3] },
{ id: 'doc2', vector: [0.4, 0.5, 0.6] },
{ id: 'doc3', vector: [0.7, 0.8, 0.9] },
];
// 假设这是查询向量
const queryVector = [0.2, 0.3, 0.4];
// 计算每个文档与查询的相似度
const similarities = storedVectors.map(doc => ({
id: doc.id,
similarity: cosineSimilarity(queryVector, doc.vector),
}));
// 排序并输出最相似的文档
similarities.sort((a, b) => b.similarity - a.similarity);
console.log(similarities);
余弦相似度,即使用 cosineSimilarity 函数计算查询向量与每个文档向量的相似度。
查询与检索的核心流程是向量化查询和相似度检索。你可以通过集成 OpenAI、Hugging Face 等嵌入模型将查询文本转换为向量,再利用 Pinecone、Weaviate 等向量数据库,或者本地计算相似度来找到最相关的文档。选择合适的向量数据库和嵌入模型,可以提高语义搜索和问答系统的性能。
四、应用场景与扩展
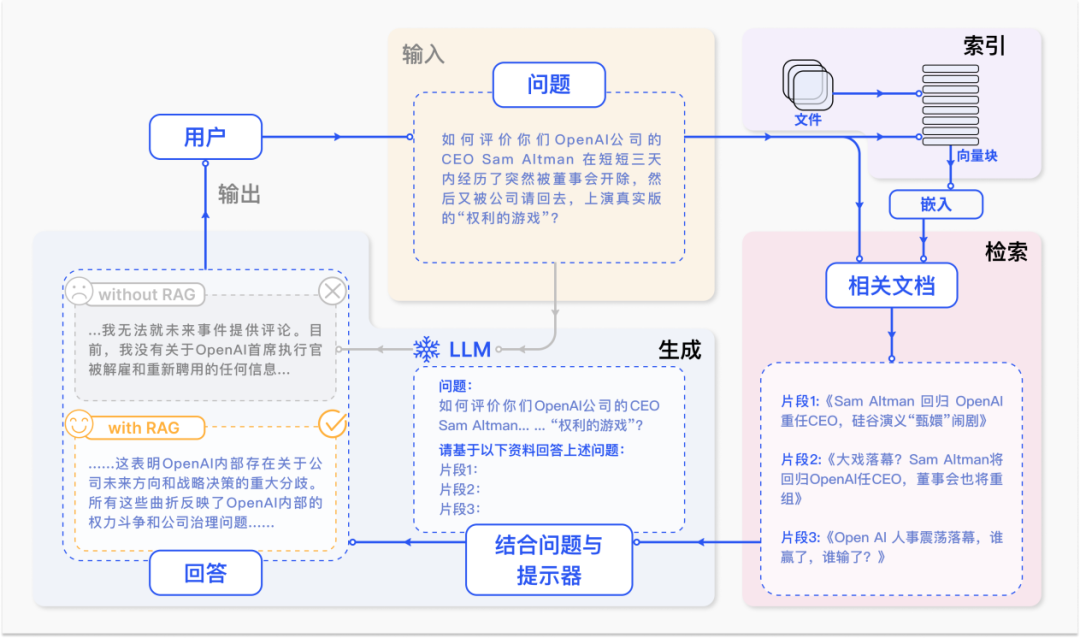
一个典型的 RAG 案例如图所示。如果我们向 ChatGPT 询问 OpenAI CEO Sam Atlman 在短短几天内突然解雇随后又被复职的事情。由于受到预训练数据的限制,缺乏对最近事件的知识,ChatGPT 则表示无法回答。RAG 则通过从外部知识库检索最新的文档摘录来解决这一差距。在这个例子中,它获取了一系列与询问相关的新闻文章。这些文章,连同最初的问题,随后被合并成一个丰富的提示,使 ChatGPT 能够综合出一个有根据的回应。
RAG 就像给模型一本教科书,用于定制的信息检索,非常适合特定领域的查询。结合实际的应用场景,可以做如下的实践方向:
1. 企业内部知识库
对于大型企业来说,员工往往需要从大量文档中快速获取所需的信息。通过 RAG,员工可以输入查询,系统将从企业内部知识库中检索相关文档,并生成基于这些文档的回答。这样不仅提高了信息获取效率,还减少了员工手动查找文档的时间。
2. 实时搜索引擎
RAG 还可以用于构建结合大语言模型的实时搜索引擎。当用户提出查询时,系统可以从互联网或内部数据库中检索最新的相关信息,并生成准确的回答。这在新闻推送、市场行情分析等需要实时信息的场景下尤为重要。
3. 技术支持和客服
在技术支持或客服领域,RAG 可以帮助自动生成基于用户问题的回答,同时结合企业知识库中的相关文档,提供更加准确、专业的支持。这种方式不仅提高了客服效率,还减少了客户等待时间,提升了用户体验。
五、技术挑战与最佳实践
在实际应用 RAG 技术时,我们也需要注意一些可能的技术挑战:
1. 嵌入模型的选择
选嵌入模型就像挑工具,不同的模型有不同的表现。有的模型擅长处理文本,有的模型适合图像,如果你的项目需要同时处理多个类型的数据(比如文字和图片),你得确保模型能够稳定、准确地处理这些不同类型的数据。所以,开始项目之前,必须好好对比一下不同模型,看哪个最适合你的需求。而且不同模型由于架构、训练方法和目标不同,其向量也不一致,后期迁移的成本会非常大。
2. 向量数据库的扩展性
随着你存储的数据越来越多,你需要一个能够轻松扩展的数据库。如果选的数据库处理不了大规模的数据,就会卡壳。比如 LanceDB 就是个不错的选择,它可以处理多种类型的数据(比如图片、文本),查询速度也很快,适合长时间使用和数据量不断增长的项目。
3. 检索与生成之间的权衡
在用大模型生成内容时,虽然你可以通过检索获得更准确的信息,但如果检索出来的信息太多,反而会让生成的内容变得杂乱,影响效果。所以你得平衡好,检索的信息要足够,但不能过多,确保生成的内容既准确又简洁。
六、总结与未来展望
RAG 的核心在于将外部信息与大语言模型的生成能力结合起来,利用嵌入模型和向量数据库,实现更高质量、更可信的生成结果。通过这种方式,LLM 不仅能够从自身的训练数据中生成答案,还能结合实时信息做出更加合理的推断。
未来,随着向量数据库和嵌入技术的不断发展,RAG 有望在更多领域得到应用。例如,在医学、法律等需要高度精准和实时信息的场景中,RAG 可以帮助自动生成权威且符合现实需求的回答,为各行业带来更加智能化的解决方案。
本文由 mdnice 多平台发布















 1368
1368

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









