







1.随机模拟
随机模拟,又名蒙特卡洛方法(Monte Carlo Simulation),发展始于20世纪40年代。
现代的统计模拟方法最早由数学家乌拉姆提出,被Metropolis命名为蒙特卡洛方法。蒙特卡洛是著名的赌场,赌博总是和统计密切相关的。布丰当年用于计算n的著名的投针试验就是蒙特卡罗模拟实验,随机采样的方法其实数学家们很早就知道,但是在计算机出现以前,随机数生成的成本很高,所以该方法也没有实用价值,随着计算机技术的迅猛发展,随机模拟技术很快进入实用阶段,对那些用确定算法不可行或不可能解决的问题,蒙特卡洛方法常常为人们带来希望。
统计模拟中有一个重要的问题就是给定一个概率分布p(x),我们如何在计算机中生成它的样本。一般而言,均匀分布Unifrom(0,1)的样本是相对容易生成的。通过线性同余发生器可以生成伪随机数,我们用确定性算法生成[0,1]之间的伪随机数序列后,这些序列的各种统计指标和均匀分布Uniform(0,1)的理论计算结果非常接近。这样的伪随机序列就有比较好的统计性质,可以被当成真实的随机数使用。

其它常见的概率分布,无论是连续的还是离散的分布,都给予Unifrom(0,1)样本生成,正态分布可以通过著名的Box-Muller变换得到。
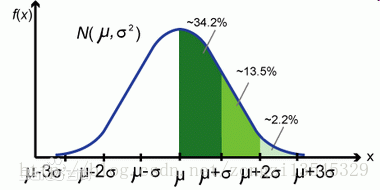
【正态分布】若随机变量X服从一个数学期望为μ、方差为σ^2的正态分布,记为N(μ,σ^2)。其概率密度函数为正态分布的期望值μ决定了其位置,其标准差σ决定了分布的幅度。当μ = 0,σ = 1时的正态分布是标准正态分布。
正态曲线呈钟型,两头低,中间高,左右对称因其曲线呈钟形,因此人们又经常称之为钟形曲线。
【Box-Muller变换】
如果随机变量 U1,U2 独立且U1,U2∼Uniform[0,1],
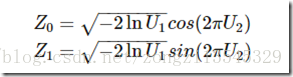
则 Z0,Z1 独立且服从标准正态分布
正态值 Z 有一个等于 0 的平均值和一个等于 1 的标准偏差,可使用以下等式将 Z 映射到一个平均值为 m、标准偏差为 sd 的统计量 X:X = m + (Z * sd)
其它几个著名的连续分布,包括指数分布、Gamma 分布、t 分布、F 分布、Beta 分布、Dirichlet 分布等等,也都可以通过类似的数学变换得到;离散的分布通过均匀分布更加容易生成。更多的统计分布如何通过均匀分布的变换生成出来,大家可以参考统计计算的书,其中 Sheldon M. Ross 的《统计模拟》是写得非常通俗易懂的一本。
不过我们并不是总是这么幸运的,当p(x)的形式很复杂,或者 p(x) 是个高维的分布的时候,样本的生成就可能很困难了。 譬如有如下的情况
- p(x)=p~(x)∫p~(x)dx,而 p~(x) 我们是可以计算的,但是底下的积分式无法显式计算。
- p(x,y) 是一个二维的分布函数,这个函数本身计算很困难,但是条件分布 p(x|y),p(y|x)的计算相对简单;如果 p(x) 是高维的,这种情形就更加明显。
此时就需要使用一些更加复杂的随机模拟的方法来生成样本。而本节中将要重点介绍的 MCMC(Markov Chain Monte Carlo) 和 Gibbs Sampling算法就是最常用的一种,这两个方法在现代贝叶斯分析中被广泛使用。要了解这两个算法,我们首先要对马氏链的平稳分布的性质有基本的认识。
1.2蒙特卡洛数值积分
如果我们要求f(x)的积分,如
而f(x)的形式比较复杂积分不好求,则可以通过数值解法来求近似的结果。常用的方法是蒙特卡洛积分:

这样把q(x)看做是x在区间内的概率分布,而把前面的分数部门看做一个函数,然后在q(x)下抽取n个样本,当n足够大时,可以用采用均值来近似:
因此只要q(x)比较容易采到数据样本就行了。随机模拟方法的核心就是如何对一个概率分布得到样本,即抽样(sampling)。
1.3 Monte Carlo principle
Monte Carlo 抽样计算随即变量的期望值是接下来内容的重点:X 表示随即变量,服从概率分布 p(x), 那么要计算 f(x) 的期望,只需要我们不停从 p(x) 中抽样xi,然后对这些f(xi)取平均即可近似f(x)的期望。


1.4 接受-拒绝抽样(Acceptance-Rejection sampling)
很多实际问题中,p(x)是很难直接采样的的,因此,我们需要求助其他的手段来采样。既然 p(x) 太复杂在程序中没法直接采样,那么我设定一个程序可抽样的分布 q(x) 比如高斯分布,然后按照一定的方法拒绝某些样本,达到接近 p(x) 分布的目的,其中q(x)叫做 proposal distribution 。

具体操作如下,设定一个方便抽样的函数 q(x),以及一个常量 k,使得 p(x) 总在 kq(x) 的下方。(参考上图)
- x 轴方向:从 q(x) 分布抽样得到 a。(如果是高斯,就用之前说过的 tricky and faster 的算法更快)
- y 轴方向:从均匀分布(0, kq(a)) 中抽样得到 u。
- 如果刚好落到灰色区域: u > p(a), 拒绝, 否则接受这次抽样
- 重复以上过程
在高维的情况下,Rejection Sampling 会出现两个问题,第一是合适的 q 分布比较难以找到,第二是很难确定一个合理的 k 值。这两个问题会导致拒绝率很高,无用计算增加。
1.5 重要性抽样(Importance sampling)
Importance Sampling 也是借助了容易抽样的分布 q (proposal distribution)来解决这个问题,直接从公式出发:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 845
845

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









