










1.认识决策树
决策树的思想来源非常之简单,就是条件分支语句:“如果是,执行哪一步,如果否,执行哪一步”,我们通过一个案例对决策树形成初步认识。下面是一个男的询问他的母亲相亲对象的条件,再决定是否去相亲。
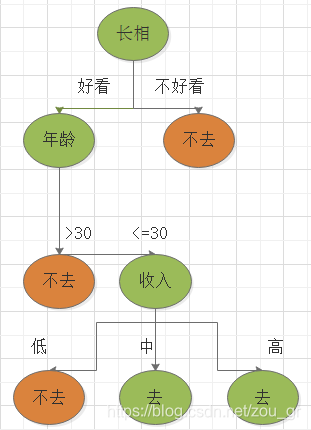
那么从这幅图我们思考这个问题?为什么这个男的要首先考虑相亲对象的长相,再接着考虑年龄,最后考虑收入。其实这就是决策树算法的关键,相亲对象的长相、年龄和收入都是输入特征,输入特征的排序便是决策树的关键之一。
2.决策树做了什么?举个实例
我们举个具体的实例,来讲决策树到底干了些什么活?下面是银行选择是否贷款的数据,那么依照这些数据我们需要判断ID为16的中年、有工作、有房子、信贷情况好,银行是否决定贷款给这位中年。
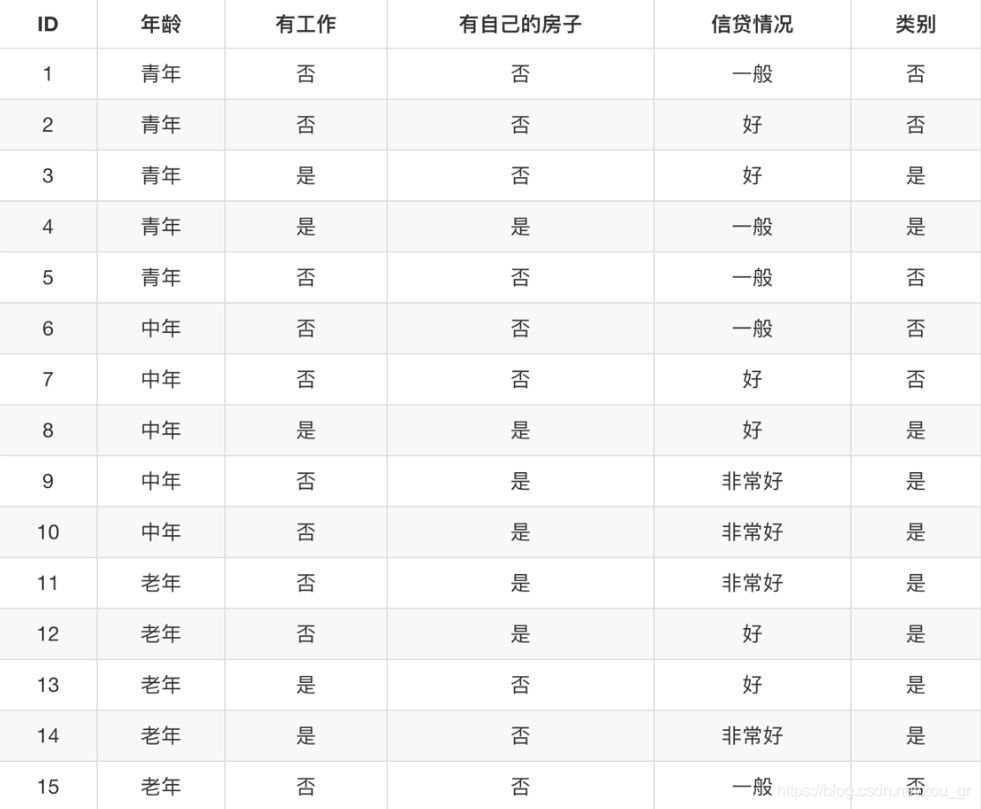
(1)对四个输入特征进行排序
决策树对特征排序我们通常采用信息增益或者基尼指数,两者的效果区别不大,但是从运算效率来说,基尼指数会更棒。本文介绍利用信息增益作为排序的依据。引用信息熵概念,信息熵是什么?可以具体看这篇博客。https://blog.csdn.net/zou_gr/article/details/103519003
计算信息熵:
E
n
t
(
D
)
=
E
[
−
log
p
i
]
=
−
∑
i
=
1
n
p
i
log
p
i
Ent(D)=E[-\log p_i]=-\sum\limits_{i=1}^n p_i \log p_i
Ent(D)=E[−logpi]=−i=1∑npilogpi
其中某个特征的样本集合有a1 a2个取值,对应概率为
p
i
p_i
pi ,式中对数一般取2为底。进一步计算信息增益:
G
a
i
n
(
D
,
a
)
=
E
n
t
(
D
)
−
∑
i
=
1
n
∣
D
i
∣
∣
D
∣
E
n
d
(
D
i
)
Gain(D,a)=Ent(D) - \sum\limits_{i=1}^n \frac{|D_i|}{|D|} End(D^i)
Gain(D,a)=Ent(D)−i=1∑n∣D∣∣Di∣End(Di)
其中的但用文字很难说明白的了,我们直接拿上面一个例子来计算。
针对是否有工作这个特征,取值有是和否,在是有工作的贷款人有5个银行愿意贷款给他的,0个不愿意贷款的,在没有工作的贷款人有4个银行愿意贷款给他的,6个不愿意贷款的,那么针对是有工作的贷款人而言,能贷到款的概率为1,未能贷到款的概率0,同样的,针对没有工作的贷款人对应概率为2/5和3/5,那么依据信息熵的公式,可以计算
E
n
t
(
是
否
有
工
作
)
=
−
1
3
l
o
g
(
1
3
)
−
−
2
3
l
o
g
(
2
3
)
Ent(是否有工作 ) = -\frac{1}{3}log(\frac{1}{3})--\frac{2}{3}log(\frac{2}{3})
Ent(是否有工作)=−31log(31)−−32log(32),
E
n
t
(
没
有
工
作
)
=
−
2
5
l
o
g
(
2
5
)
−
−
3
5
l
o
g
(
3
5
)
Ent(没有工作)=-\frac{2}{5}log(\frac{2}{5})--\frac{3}{5}log(\frac{3}{5})
Ent(没有工作)=−52log(52)−−53log(53),
E
n
t
(
有
工
作
)
=
−
1
l
o
g
(
1
)
−
0
Ent(有工作)=-1log(1)-0
Ent(有工作)=−1log(1)−0,进而计算该特征的信息增益,
G
a
i
n
(
是
否
有
工
作
)
=
E
n
t
(
是
否
有
工
作
)
−
5
15
E
n
t
(
有
工
作
)
−
10
15
E
n
t
(
没
有
工
作
)
Gain(是否有工作)=Ent(是否有工作)-\frac{5}{15}Ent(有工作)-\frac{10}{15}Ent(没有工作)
Gain(是否有工作)=Ent(是否有工作)−155Ent(有工作)−1510Ent(没有工作) ,同样的可以计算另外三个特征。然后进行排序,选择信息增益最大的为根节点,依次地选择下去。关于根节点、叶节点和中间节点的意思看下图就简洁明了。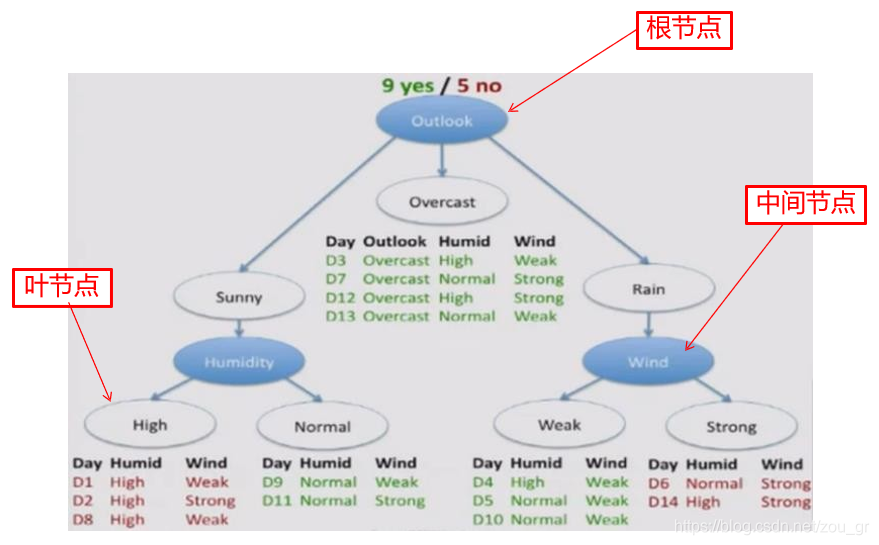
上面举了个很小的例子去说明决策树特征是如何排序,我们大概了解一下就行,这些工作都交给计算机工作就行,我们思考一个问题:对一棵决策树,是否无限制地划分下去?划到什么程度才好?那么决策树另一个关键就是剪枝,剪枝的目的就是就是为了防止过拟合。
(2)剪枝
关于剪枝的简要,我们参考黄昌达的黑书:
决策树的剪枝有两种思路; 前剪枝(Pre-Pruning)和后剪枝(Post-Pruning)。
前剪枝是在构造决策树的同时进行剪枝。在决策树的构建过程中 ,如果无法进一步降 低信息娟的情况下,就会停止创建分支。 为了避免过拟合,可以设定一个阔值, 信息熵减 小的数量小于这个阔值,即使还可以继续降低熵脯, 也停止继续创建分支。 这种方法称为前 剪枝。还有一些简单的前剪枝方法,如限制叶子节点的样本个数, 当样本个数小于一定的阈值时, 即不再继续创建分支。
后剪枝是指决策树构造完成后进行剪枝。剪枝的过程是对拥有同样父节点的一组节点 进行检查,判断如果将其合井,信息熵的增加量是否小于某一阀值。如果小于阔值,则这 一组节点可以合并一个节点。后剪枝是目前较普遍的做法。后剪枝的过程是删除一些子树, 然后用子树的根节点代替,来作为新的叶子节点。这个新叶子节点所标识的类别通过大多 数原则来确定, 把这个叶子节点里样本最多的类别,作为这个叶子节点的类别 。 后剪枝算法有很多种,其中常用的一种称为降低错误率剪枝法( Reduced-Error Pruning) 。其思路是,自底向上,从己经构建好的完全决策树中找出一个子树,然后用子 树的根节点代替这棵子树,作为新的叶子节点。 叶子节点所标识的类别通过大多数原则来确定。这样就构建出一个新的简化版的决策树。然后使用交叉验证数据集来测试简化版本的决策树,看看其错误率是不是降低了 。 如果错误率降低了,则可以使用这个简化版的决 策树代替完全决策树,否则还是采用原来的决策树。通过遍历所有的子树,直到针对交叉验证数据集,无法进一步降低错误率为止。
3.决策树的优缺点
优点:容易理解和解释,使用简单。
缺点:单个决策树最主要的问题就是不稳定,训练数据的小变化非常敏感。
4.利用python和matlab实现决策树
我们利用决策树对著名的乳腺癌数据进行分类。
(1)python
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from sklearn.datasets import load_breast_cancer
cancer = load_breast_cancer()
X = cancer.data
y = cancer.target
from sklearn.tree import DecisionTreeClassifier
clf = DecisionTreeClassifier() #选择决策树
clf.fit(X_train, y_train) #对训练集进行训练
train_score = clf.score(X_train, y_train) #查看训练集的分数
test_score = clf.score(X_test, y_test) #查看测试集的分数
print('train score: {0}; test score: {1}'.format(train_score, test_score)) #输出分数
#利用网格搜索寻找最优参数
from sklearn.model_selection import GridSearchCV
max_depth=np.linspace(1, 101, 101) #最深深度
min_samples_split=np.arange(2,20,1) #结点的最小样本数量
min_samples_leaf = np.arange(1,20,1) #叶子节点最少的样本数
param_grid = {'max_depth':max_depth,'min_samples_split':min_samples_split,'min_samples_leaf':min_samples_leaf}
clf = GridSearchCV(DecisionTreeClassifier(), param_grid, cv=5)
clf.fit(X_train, y_train)
print("best param: {0}\nbest score: {1}".format(clf.best_params_,
clf.best_score_))(2)matlab
% 读取数据,此数据也可从python数据集导出
X_train = csvread('X_train.csv');
y_train = csvread('y_train.csv');
X_test = csvread('X_test.csv');
y_test = csvread('y_test.csv');
% 创建决策树分类器
ctree = ClassificationTree.fit(X_train,y_train);
% 查看决策树视图
view(ctree);
view(ctree,'mode','graph');
tr_acc = 1-resubLoss(ctree) %查看决策树在训练集的错误率: 0.9780
loss_acc = 1-kfoldLoss(crossval(ctree)) %交叉验证准确率0.9231
% 仿真测试
te_pre = predict(ctree,X_test);
% 测试集结果分析
te_sim_0 = length(find(te_pre == 0 & y_test == 0));
te_sim_1 = length(find(te_pre == 1 & y_test == 1));
acc = (te_sim_0 + te_sim_1) / 114
% 用for循环找最优参数,并可视化观察
leafs = logspace(1,2,10);
N = numel(leafs);
err = zeros(N,1);
for n = 1:N
t = ClassificationTree.fit(X_train,y_train,'crossval','on','minleaf',leafs(n));
err(n) = kfoldLoss(t);
end
plot(leafs,err);
xlabel('叶子节点含有的最小样本数');
ylabel('交叉验证误差');
title('叶子节点含有的最小样本数对决策树性能的影响')
%% 设置minleaf为10,产生优化决策树
ctree1 = ClassificationTree.fit(X_train,y_train,'minleaf',10);
view(ctree1,'mode','graph')
tr_acc1 =1-resubLoss(ctree1) %在训练集的准确率0.9538
loss_acc1 = 1-kfoldLoss(crossval(ctree1)) %交叉验证准确率0.9231
%计算ctree1在test中的准确率:0.9211
te_pre = predict(ctree1,X_test);
te_sim_0 = length(find(te_pre == 0 & y_test == 0));
te_sim_1 = length(find(te_pre == 1 & y_test == 1));
acc1 = (te_sim_0 + te_sim_1) / 114 5.总结
总结而言,决策树的关键无非就是特征排序和剪枝,仅仅用决策树是在实际应用是不够,结合着集成学习的Bagging, Boosting, Stacking会更加地棒。















 716
716











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









