







目录:
1、RAG的核心价值
- RAG的核心价值在于其能够有效整合外部知识库与生成模型,通过检索增强的方式提升生成内容的准确性和相关性。这种机制不仅能够弥补传统生成模型在知识更新和事实准确性方面的不足,还能根据具体需求动态调整信息检索范围,从而确保生成结果既符合上下文语境,又具备较高的信息可信度。此外,RAG的应用场景广泛,从问答系统到内容创作,都能显著提升用户体验和系统性能。
2、实现流程
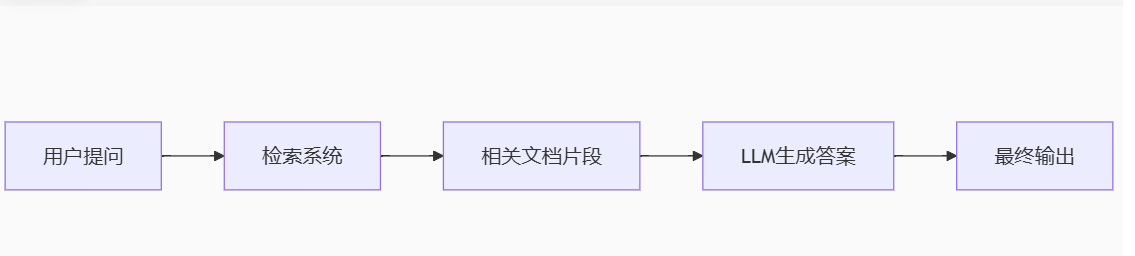
(1) 准备检索系统
向量数据库(推荐):
- Milvus / FAISS / Weaviate:存储文档的向量嵌入(embedding)。
- 使用模型(如 bge-small、text2vec)将文档转换为向量。
全文搜索引擎(备选):
- Elasticsearch:基于关键词检索。
(2) 文档处理与索引
from sentence_transformers import SentenceTransformer
import milvus
# 加载嵌入模型
model = SentenceTransformer('BAAI/bge-small-zh-v1.5')
# 文档示例
documents = ["DeepSeek是深度求索公司开发的AI模型...", "RAG通过检索增强生成..."]
# 生成向量
embeddings = model.encode(documents)
# 存入Milvus
collection.insert([embeddings])
(3) 文档分割和文档向量
# 1. 文档切割
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
chunks = text_splitter.split_text(document)
# 2. 向量化
model = SentenceTransformer('BAAI/bge-small-zh-v1.5')
embeddings = model.encode(chunks)
# 3. 检索(用户提问时)
query = "如何申请年假?"
query_embedding = model.encode(query)
scores, indices = index.search(query_embedding, k=3) # 检索top-3
# 4. 生成
context = [chunks[i] for i in indices[0]]
prompt = f"参考:{context}\n\n问题:{query}"
answer = DeepSeek.generate(prompt)
(4) 检索增强生成
from deepseek_api import DeepSeek # 假设DeepSeek提供API
def rag_answer(question):
# 1. 检索相关文档
query_embedding = model.encode(question)
results = collection.search(query_embedding, top_k=3)
# 2. 拼接上下文
context = "\n".join([doc.text for doc in results])
prompt = f"基于以下信息回答问题:\n{context}\n\n问题:{question}"
# 3. 调用DeepSeek生成
response = DeepSeek.generate(prompt)
return response
3、LLM生成答案
(1)、LLM生成代码
from sentence_transformers import SentenceTransformer
from pymilvus import Collection
from deepseek_api import DeepSeek
# 1. 初始化模型和数据库
model = SentenceTransformer('BAAI/bge-small-zh-v1.5')
collection = Collection("knowledge_base") # 已存在的Milvus集合
llm = DeepSeek()
# 2. 用户提问处理
user_question = "如何用DeepSeek实现RAG?"
query_embedding = model.encode(user_question)
# 3. 向量数据库检索
results = collection.search(
data=[query_embedding],
anns_field="embedding",
limit=3
)
retrieved_docs = [hit.entity.get("text") for hit in results[0]] # 获取原始文本
#高级技巧
#(1) 重排序(Rerank)
#在检索后、生成前,用交叉编码器(如bge-reranker)对文档片段重新排序,提升上下文质量:
from FlagEmbedding import Reranker
reranker = Reranker('BAAI/bge-reranker-large')
reranked_docs = sorted(zip(retrieved_docs, retrieved_scores), key=lambda x: reranker.compute_score(x[0], user_question), reverse=True)
# 4. 调用LLM生成答案
prompt = f"""参考信息:\n{retrieved_docs}\n\n问题:{user_question}"""
answer = llm.generate(prompt)
print(answer)
#高级技巧
#(2) 流式生成
#对于长答案,可实时流式返回结果(需LLM支持):
for chunk in llm.stream_generate(prompt):
print(chunk, end="", flush=True)
(2)、流式输出
import requests
response = requests.post(
"https://api.deepseek.com/v1/chat/completions",
headers={"Authorization": "Bearer YOUR_API_KEY"},
json={
"model": "deepseek-chat",
"messages": [{"role": "user", "content": "写一篇关于AI的短文"}],
"stream": True
},
stream=True
)
for line in response.iter_lines():
if line:
chunk = line.decode("utf-8").strip()
if chunk.startswith("data:"):
data = json.loads(chunk[5:])
print(data["choices"][0]["delta"].get("content", ""), end="", flush=True)
上述代码中deepseek的响应answer就是此处的response,然后衔接上做流式输出处理。
4、倒排索引 和 KNN/ANN混合使用(大厂)
1、流程图
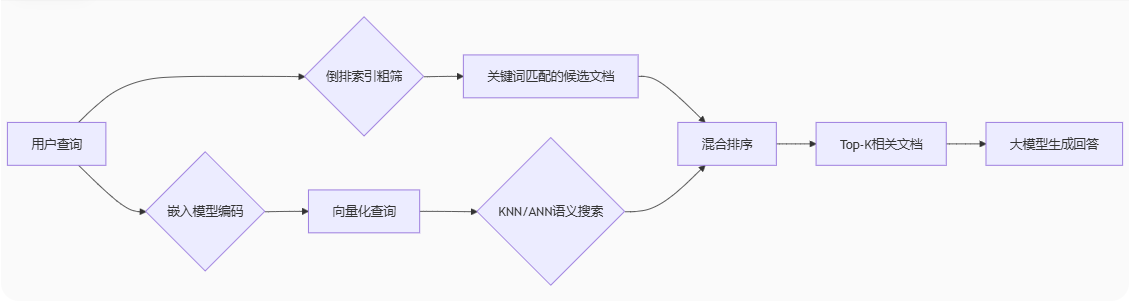
2、使用场景

3、实现步骤
(1)数据预处理
#python
from sentence_transformers import SentenceTransformer
import faiss
import jieba
# 1. 文档处理
documents = ["深度学习框架PyTorch教程", "大模型训练技巧", "神经网络优化方法"]
model = SentenceTransformer("bge-small-zh")
vectors = model.encode(documents) # 文档向量化
# 2. 构建倒排索引
inverted_index = {}
for doc_id, text in enumerate(documents):
words = jieba.lcut(text) # 中文分词
for word in words:
if word not in inverted_index:
inverted_index[word] = []
inverted_index[word].append(doc_id)
# 3. 构建FAISS索引
index = faiss.IndexFlatIP(vectors.shape[1])
index.add(vectors)
(2)混合检索实现
#python
def hybrid_search(query, top_k=3, keyword_weight=0.3, semantic_weight=0.7):
# 1. 倒排索引召回(关键词匹配)
keywords = jieba.lcut(query) # 查询分词
keyword_hits = set()
for kw in keywords:
if kw in inverted_index:
keyword_hits.update(inverted_index[kw])
# 2. KNN语义搜索
query_vec = model.encode([query])
D, I = index.search(query_vec, top_k) # D为相似度分数,I为文档索引
# 3. 混合排序(加权分数)
results = {}
# 倒排索引结果赋分(基于BM25或简单计数)
for doc_id in keyword_hits:
results[doc_id] = keyword_weight * 1.0 # 简化处理
# KNN结果赋分(余弦相似度)
for score, doc_id in zip(D[0], I[0]):
if doc_id in results:
results[doc_id] += semantic_weight * score
else:
results[doc_id] = semantic_weight * score
# 按总分排序
sorted_results = sorted(results.items(), key=lambda x: x[1], reverse=True)
return [documents[doc_id] for doc_id, _ in sorted_results[:top_k]]
# 示例查询
print(hybrid_search("如何优化神经网络?"))
# 可能输出:["神经网络优化方法", "深度学习框架PyTorch教程", "大模型训练技巧"]
(3)deepseek配合倒排索引和KNN使用示例
from transformers import AutoModelForCausalLM, AutoTokenizer
from sentence_transformers import SentenceTransformer
import faiss
import jieba
# 1. 初始化模型
tokenizer = AutoTokenizer.from_pretrained("deepseek-ai/deepseek-chat")
generation_model = AutoModelForCausalLM.from_pretrained("deepseek-ai/deepseek-chat")
retrieval_model = SentenceTransformer("bge-small-zh")
# 2. 构建检索系统
documents = ["PyTorch的nn.Module用法...", "深度学习训练技巧...", "神经网络优化..."]
vectors = retrieval_model.encode(documents)
index = faiss.IndexFlatIP(vectors.shape[1])
index.add(vectors)
# 3. 混合检索
def hybrid_search(query, top_k=2):
# 倒排索引(示例:简单分词匹配)
keywords = jieba.lcut(query)
keyword_docs = [i for i, doc in enumerate(documents) if any(kw in doc for kw in keywords)]
# KNN 语义搜索
query_vec = retrieval_model.encode([query])
_, knn_docs = index.search(query_vec, top_k)
# 合并结果
all_docs = list(set(keyword_docs + knn_docs[0].tolist()))
return [documents[i] for i in all_docs[:top_k]]
# 4. 流式生成 + 检索增强
def stream_answer(query):
# 异步检索(实际应用可多线程)
retrieved = hybrid_search(query)
# 将检索结果作为上下文
context = "参考文档:" + " ".join(retrieved)
full_prompt = f"{context}\n\n用户问题:{query}"
# 流式生成
for chunk in generation_model.generate_stream(full_prompt):
yield chunk["text"]
# 示例使用
for text in stream_answer("PyTorch怎么定义模型?"):
print(text, end="", flush=True)
这个使用倒排和KNN将相似的文档输出出来,然后将文档作为提示模版输入到deepseek大模型中,大模型根据提示工程从文档中进行精准的回答。
5、ANN聚类索引的使用
from sentence_transformers import SentenceTransformer
import faiss
import numpy as np
# 1. 加载模型和文档
model = SentenceTransformer("bge-small-zh")
documents = ["文档1内容...", "文档2内容...", ...] # 假设10万条文档
vectors = model.encode(documents) # 形状 [100000, 384]
# 2. 构建带聚类的ANN索引
n_clusters = 256 # 聚类数
quantizer = faiss.IndexFlatIP(384) # 内积相似度
index = faiss.IndexIVFFlat(quantizer, 384, n_clusters, faiss.METRIC_INNER_PRODUCT)
index.train(vectors) # 训练聚类
index.add(vectors) # 添加数据
index.nprobe = 20 # 搜索时检查的簇数
# 3. 检索时使用
query = "如何优化神经网络?"
query_vec = model.encode([query])
D, I = index.search(query_vec, k=5) # 返回Top-5文档
print([documents[i] for i in I[0]])


















 209
209

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











