







引言
😆一阵子没耍 Coze(扣子) ,最近不太忙,刚好有新 idea💥,倒腾个Bot耍耍😏,也赶下本期扣子活动的尾班🚗,蹭个参与🏆。扣子好像更新了不少东西啊,先可快速过下😄~
扣子更新速览
多Agents模式
对于 Agent是什么 的一个常见观点:
让AI以类似人的工作和思考方法来完成一系列任务,一个Agent可以是一个Bot,也可以是多个Bot的协作。
😁 扣子的 多Agents模式 就是:支持 组合多个Bot 来实现 功能更全面和复杂的Bot。在Bot的 **编排 **页,可以进行 Agent模式的切换:
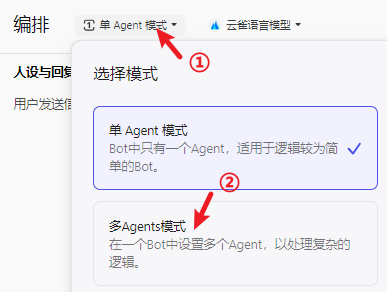
左侧 **配置 **和 **单Agent模式 **时基本类似,只是作用域是 **全局 **的,将适用于所有添加的 Agent。
右侧 画布 区域可以为 Bot添加 节点,默认自带一个 开始节点,可以设置新一轮对话的 起始节点:
- 上一次回复用户的节点:新消息继续发送给上次回复用户的节点。
- 开始节点:所有消息都发送给Start节点,它将用户消息移交给适合的Agent节点。
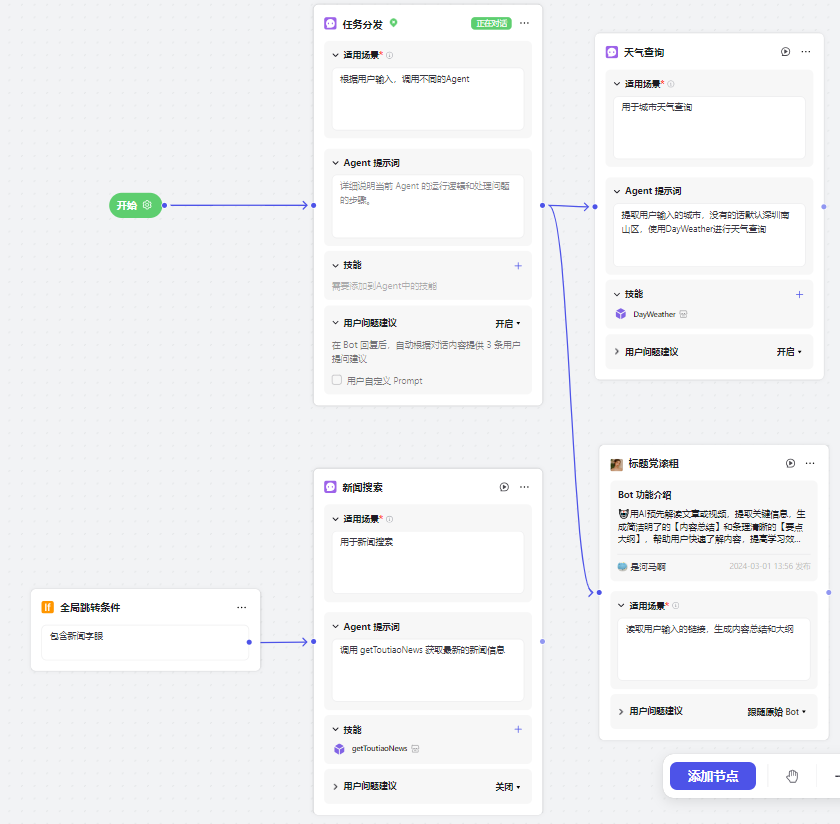
然后,支持添加 **三种类型 **的节点:

① Agent节点 → 可以独立执行任务的智能实体,🤔 感觉是支持 快速灵活搭建的Bot节点 (不用发布)~
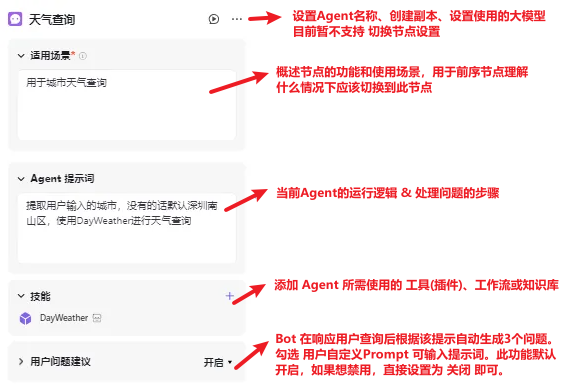
② Bot节点 → 已发布 的可执行特定任务的 单Agent Bot
③ 全局跳转条件 → 用户输入满足此节点的条件,立即跳转到Agent
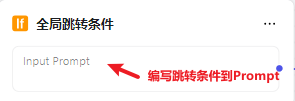
优先级高于 节点选择,命中就直接跳,一个Bot最多添加 **5个条件节点 **❗️ 随手缝合个支持多功能的Bot试试:
发下消息试试:
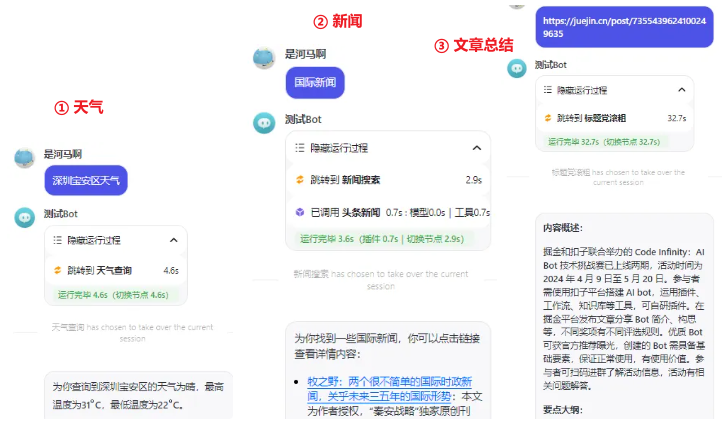
👏 可以,都正确调用了适合的Agent,多Agents的玩法和 工作流很像,感觉是 **执行任务粒度粗细 **的 划分~
记忆-变量
😄 支持创建变量来保存一些 临时数据,在Bot的 编排页,找到 记忆-变量,点击+,可以对Bot中需要用到的变量进行编辑,比如我这里启用了 sys_uuid 用于获取的唯一ID,并添加了一个 city 用于保存用户所在城市:
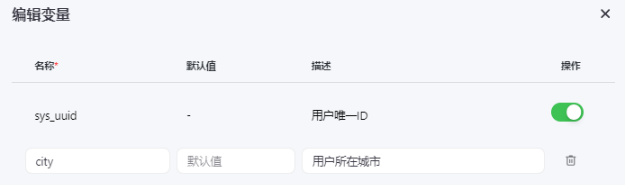
然后在 预览与调试,回复一句:我在深圳,可以看到,变量设置成功:
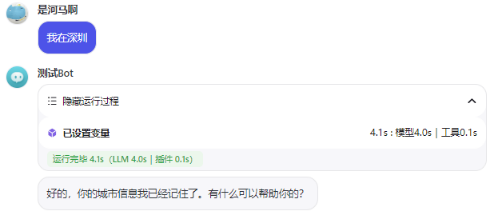
点击右上角的 变量,可以看到保存的数据:
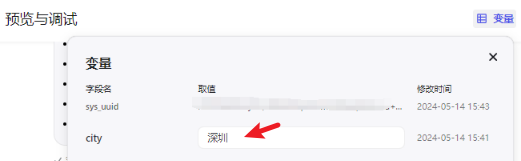
可以在 人设与回复逻辑 限定变量的 具体使用场景,接着,你还可以在 工作流 中添加 变量节点 来 对变量值进行设置或读取。比如,随手建个工作流试试:
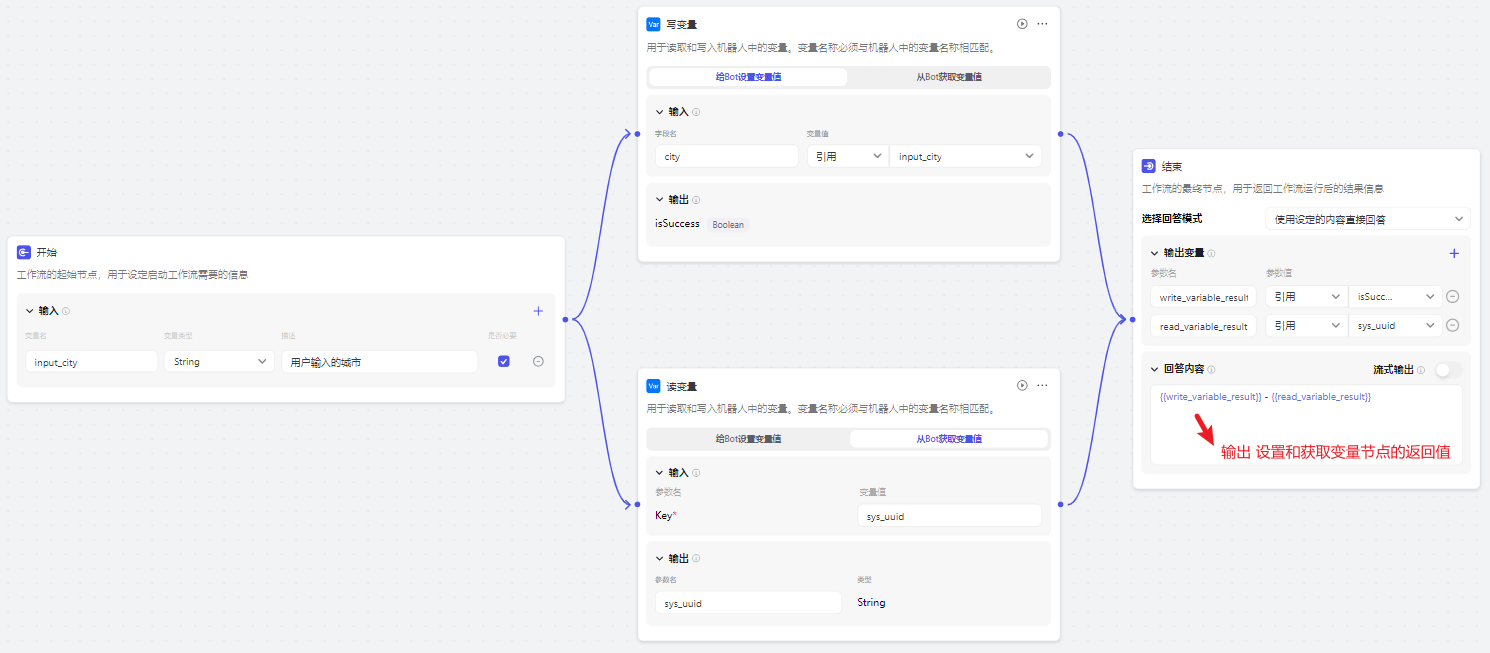
点击 试运行,需要选择关联的Bot,在此可以看到其中定义的变量:
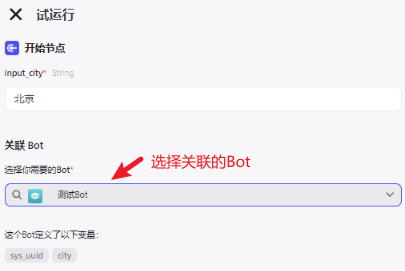
点击运行后的输出结果:
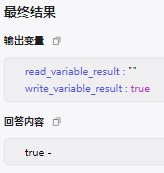
😄 试运行这里肯定是拿不到用户id的,直接 发布工作流,然后添加到Bot里,编写Prompt来调用:
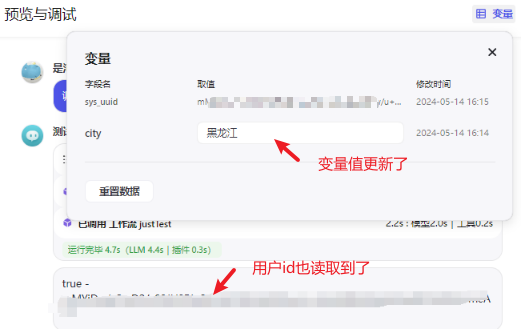
另外,如果用户更新了数据 (如:在会话中提供了新的城市),Bot会自动修改为最新值。
记忆-长期记忆
模仿人脑形成对用户的个人记忆,基于这些记忆提供个性化回复,提升用户体验。主要包含两部分能力:
- 自动记录并总结对话信息;
- 会在回复用户查询时,对总结的内容进行召回,在此基础上生成最终回复。
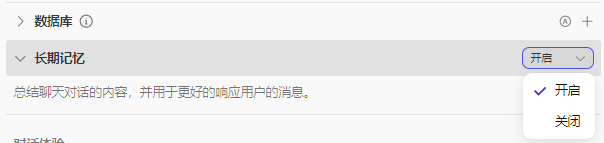
🤔 感觉这个长期记忆就是 一种记录多轮对话上下文的管理机制,用于保持对话的连贯性。点击 编排页 的 记忆-长期记忆,可以开启或关闭。
开启后,点击右上角 预览与调试-长期记忆,可以看到总结的对话内容:
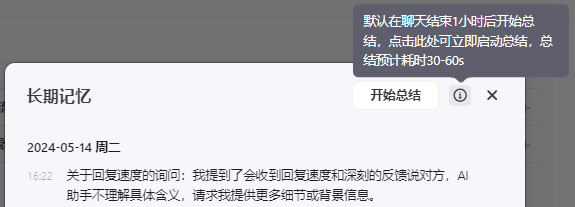
Tips:每个用户包括Bot开发者,只能看到和使用与Bot对话生成的记忆内容。
技能-触发器
使Bot在** 指定时间 **或 接收到特定事件 时自动执行任务,前者无需编写代码,后者会生成 Webhook URL,当你的服务端向这个 Webhook URL 发起HTTPS请求,会触发任务执行。
在 编排页-触发器,点击+添加触发器,比如添加一个 定时触发 的触发器,支持执行三种类型的任务:
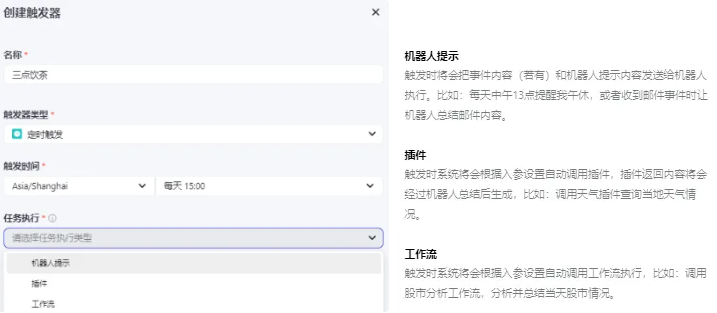
WebHook类型的事件触发器配置稍微麻烦些,普通用户用不到,感兴趣可以看下官方文档对应介绍~
⚠️ 触发器只在Bot发布到 **飞书 **时才有效 ❗️ 每个Bot最多添加10个触发器。
对话体验-快捷指令
在 对话输入框上方配置一些 按钮,以供用户 快速发起预设对话:

支持两种 指令行为,先是 直接发送-指令内容:
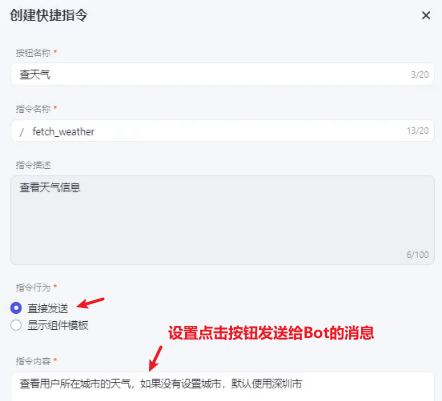
然后是 直接使用插件或工作流,需要进行一些对应的参数配置:
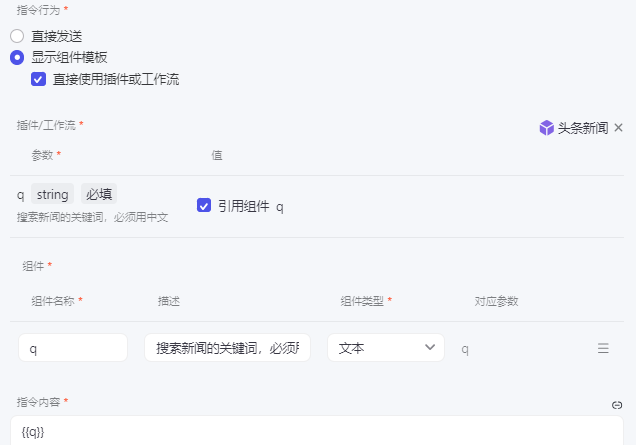
配置完点击按钮会 弹窗,用户输入对应的参数,回车触发指令发送
支持 **拖拽按钮 **对指令进行排序,在飞书、微信等渠道支持直接 **输入指令 **(如: /fetch_weather) 唤起快捷指令。
对话体验-背景图片
可以为Bot在 扣子Bot商店添加对话背景图片,点击+上传,能看到横竖屏的效果预览,点击 **确认 **进行设置。

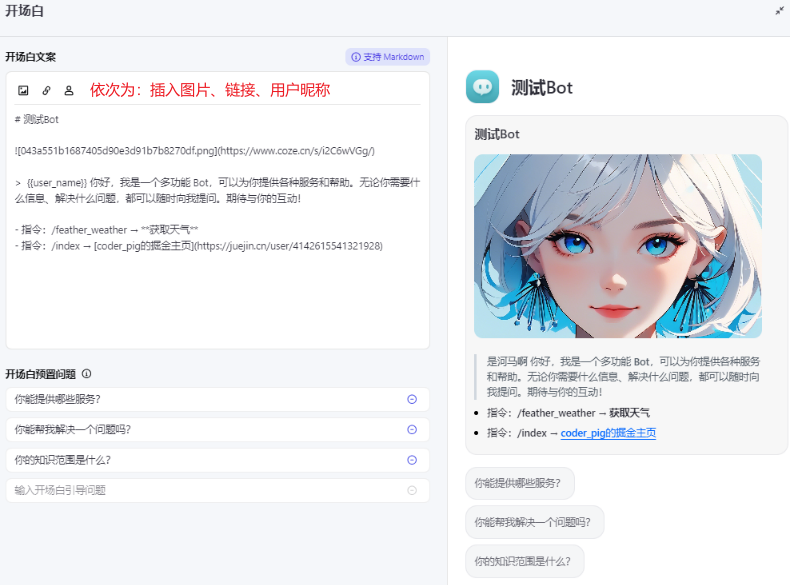
对话体验-开场白支持Markdown语法
在 编排页 找到开场白,点击打开Markdown编辑器:

然后可以使用Markdown语法来编写Bot的开场白,右侧可以看到 效果预览:
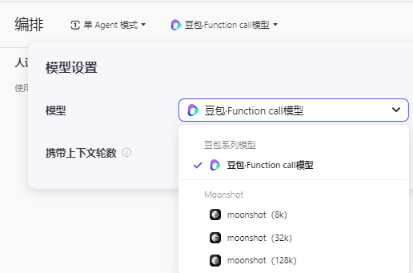
LLM模型更新
**云雀 **改名 豆包,支持 **moonshot (月之暗面-kimi) **模型,后面的数字代表模型支持的 最大上下文长度,即它们能够处理的文本量,如: 8k 表示模型支持的最长上下文长度为8000 tokens,可以更具自己的实际情况进行选择。
工作流-消息节点
支持在工作流中返回响应内容,可用于解决 回复消息较多 或 工作流较长 导致用于 **无法及时收到响应 **的问题:
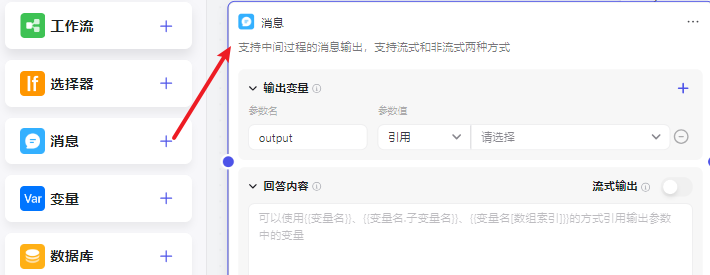
支持两种消息模式:
- 非流式输出:默认,接收到全部消息内容再一次性输出。
- 流式输出:打字机效果,上一个节点一边生成回复内容,一边通过消息节点进行输出,不用等全部内容加载完再返回。消息节点只有在 **大模型节点后 **可才可以开启 流式响应,如果配置了多个开启流式返回的消息节点,会按照工作流的执行顺序,先执行的消息节点优先输出消息。
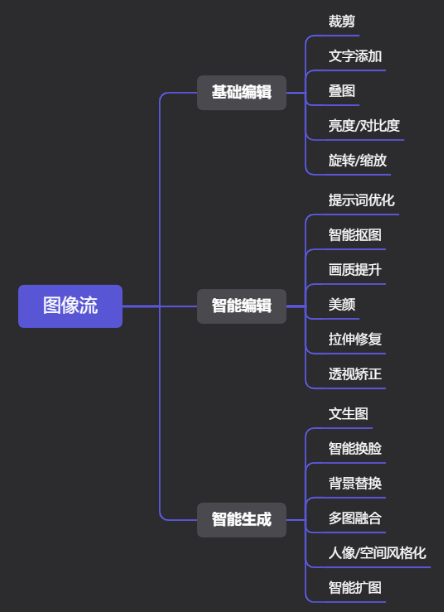
技能-图像流
前些天还在 **编排页 **看到过它,昨天再看没了,有消息说会在5.15的发布会后上线,但今天看还是无影🤷。支持通过 可视化的方式,对图像获取、生成、编辑和发布等功能进行组合,实现自定义的图像处理流程,相关功能:
💁♂️ 现在木得体验,等正式上线了再单独测评下~
灵感乍现的瞬间
😄 了解完扣子都更新了啥,接着捋一捋笔者想做一个什么样的Bot,灵感来源💥:
互联网时代,许多人都养成了一种** 囤积癖**,看到好的文章、工具的第一反应就是 添加收藏/书签,理由是 以后有时间再看,以后可能会用到,然后,基本没以后了,绝大概率就是在收藏夹吃灰🤣。接着,在某天某个情景,突然想起,自己有收藏过相关的链接,但苦寻许久,也可能找不到哪个链接了。🤡 2333,这就是没有养成**定时整理 **的习惯…
😄 由此萌生出做一个 浏览器书签助手 的Bot,支持:书签自动分类整理 + AI检索心仪书签,简易交互流程:

😏 思路有了,接着一步步来实现这个 Bot~
实践过程
文件上传
😀 有些读者可能还没导出过 书签文件,说下方法,依次点击浏览器的 (以笔者的Chrome为例):
设置 → 书签和清单 → 书签管理器 → 右上角整理 (三个竖排点的图标) → 导出书签
然后会生成一个** bookmarks_年_月_日.html** 的书签文件,如:

😄 先不看文件内容,琢磨下 文件上传,除了用户通过Bot上传外,插件和工作流的代码节点,都需要用到,就生成的文件,需要传到服务器,生成一个 访问文件的URL。扣子是 **支持上传文件 **的,但很可惜,并不支持 html 格式 ☹️,尝试上传html后什么反应都没有:
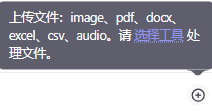
然后在代码节点,试下写提示词让AI写下代码,看能否套出 文件上传相关的代码:
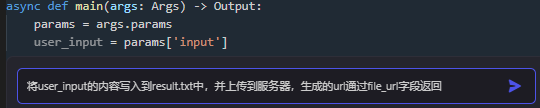
AI生成的代码:
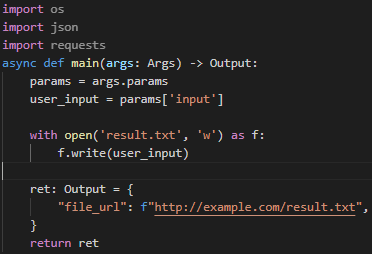
🤡 打扰了,所以 文件上传 这块得自己想办法了,需要一枚 云存储,这里直接上 七牛云,上传文件的核心代码:
from qiniu import Auth, put_file, etag
access_key = 'access_key'
secret_key = 'secret_key'
bucket_name = '仓库名称'
q = Auth(access_key, secret_key)
base_url = "http://xxx.com/{}" # 仓库域名
def upload_file(file_path):
file_name = file_path.split('/')[-1]
token = q.upload_token(bucket_name, file_name)
ret, info = put_file(token, file_name, file_path, version='v2')
# 上传成功滑后返回文件的url
if ret['key'] == file_path and ret['hash'] == etag(file_path):
return base_url.format(file_name)
if __name__ == '__main__':
print(upload_file("rabbit.ico"))
然后,问题来了:用户咋上传生成标签文件的url?总不能让他们每次传文件,都要手动去改 **upload_file() **传递的文件名吧🤣?随手用 **PySimpleGUI **库 (4.60.5, 5后的版本要付费) 写个有简单页面的 exe:
import PySimpleGUI as ps_gui
# 构造GUI页面
def main_gui():
# 判断 config.txt 文件是否存在
access_key = ''
secret_key = ''
bucket_name = ''
if os.path.exists("config.txt"):
with open("config.txt", "r") as f:
lines = f.readlines()
access_key = lines[0].strip()
secret_key = lines[1].strip()
bucket_name = lines[2].strip()
layout_control = [
[
# access_key的输入框
ps_gui.Frame(layout=[
[ps_gui.Text("Access Key"), ps_gui.InputText(key="access_key", default_text=access_key)],
[ps_gui.Text("Secret Key"), ps_gui.InputText(key="secret_key", default_text=secret_key)],
[ps_gui.Text("Bucket Name"), ps_gui.InputText(key="bucket_name", default_text=bucket_name)],
], title="请输入七牛云相关参数"),
ps_gui.Button("保存", key="save")],
[
ps_gui.Frame(layout=[
[ps_gui.FileBrowse("选择文件", key='file_browser', enable_events=True)]
], title="请选中要上传的文件"),
ps_gui.Frame(layout=[
[ps_gui.Text("", key="file_path")]
], title="当前选中文件"),
ps_gui.Button("上传", key="upload")
],
[
ps_gui.Text("文件URL", key="result_label"),
ps_gui.Text("", key="result"),
ps_gui.Button("复制", key="copy")
],
]
window_panel = ps_gui.Window("七牛云文件上传助手", layout_control)
while True:
event, value = window_panel.read()
if event == ps_gui.WIN_CLOSED:
break
if event == 'save':
with open("config.txt", "w") as f:
f.write("{}\n{}\n{}\n".format(value['access_key'], value['secret_key'], value['bucket_name']))
ps_gui.popup("保存成功")
if event == 'file_browser':
file_path = value[event]
window_panel['file_path'].update(file_path)
if event == "upload":
file_path = window_panel['file_path'].get()
if file_path:
url = upload_file(file_path, value['access_key'], value['secret_key'], value['bucket_name'])
if url:
window_panel['result_label'].update("上传成功:")
window_panel['result'].update(url)
else:
window_panel['result_label'].update("上传失败:")
window_panel['result'].update("")
else:
ps_gui.popup("请选择文件后上传")
if event == "copy":
url = window_panel['result'].get()
if url:
ps_gui.clipboard_set(url)
ps_gui.popup("已复制到剪切板")
else:
ps_gui.popup("请先上传文件")
window_panel.close()
if __name__ == '__main__':
main_gui()
是用 Pyinstaller 打包成exe,执行下述命令:
pyinstaller --onefile --noconsole --name "七牛云文件上传助手" app.py
双击打包后的exe:
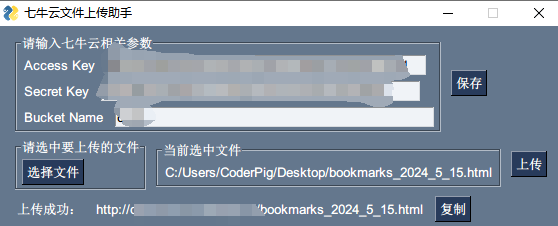
👏 OK,文件上传获取远程文件URL的问题 Fix🥳
书签提取
😄 接着到 读取并解析书签文件,对其中的书签进行提取,打开 **书签html文件 **研究下规律:
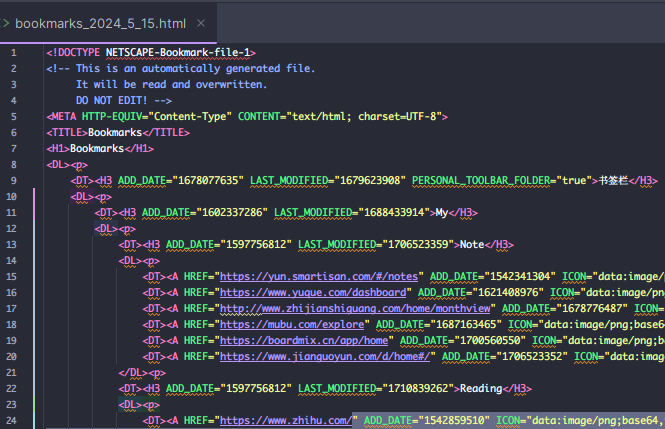
分析结果如下:
- DL→ 书签的一个分组/文件夹
- DT → 书签文件夹标题/具体书签项
- ADD_DATE → 第一次添加的时间戳
- LAST_MODIFIED → 上次修改的时间戳
- HREF → 标签链接
- ICON → 标签对应网页图标Base64
😏 **Coding **时间到,新建 插件,创建方式选 在 Coze IDE 中创建,IDE运行时选 Python3,点击 确认:
创建完会跳页面,点击 在IDE中创建工具,写下工具名称和介绍,点确定,然后就可以写代码了🎉,逻辑:
- 定义一个BookmarkItem的类存 书签标题、书签链接、书签创建时间、图标。
- 请求用户传入的 书签文件URL,读取文件内容。
- 编写 正则表达式 提取所有书签信息,保存为json文件并上传。
- 输出:文件url、错误信息。
添加下 requests 和 qiniu 依赖库,然后写出具体实现代码:
from runtime import Args
from typings.extract_bookmark_list.extract_bookmark_list import Input, Output
import re
import requests
from qiniu import Auth, put_file, etag
import time
import os
import json
# 提取书签的正则
bookmark_item_pattern = re.compile(r'A HREF="(.+?)" ADD_DATE="(\d+)" ICON="(.*?)">(.*?)</A>')
# 七牛云相关配置
access_key = 'xxx'
secret_key = 'yyy'
bucket_name = 'zzz'
base_url = "http://xxx.yyy.zzz/{}"
q = Auth(access_key, secret_key)
class BookmarkItem:
def __init__(self, title, url, add_date, icon):
self.title = title
self.url = url
self.add_date = add_date
self.icon = icon
def __str__(self):
return str(self.__dict__)
# 读取在线文件内容
def read_file_from_url(file_url):
response = requests.get(file_url)
# 避免中文乱码
response.encoding = response.apparent_encoding
if response:
return response.text
else:
return None
# 保存文件
def save_file(uuid, content):
file_path = "{}{}{}_{}.json".format(os.getcwd(), os.sep, uuid, int(time.time() * 1000))
with open(file_path, 'w', encoding='utf-8') as f:
f.write(content)
return file_path
# 上传文件到七牛云
def upload_file(file_path):
q = Auth(access_key, secret_key)
file_name = file_path.split('/')[-1]
token = q.upload_token(bucket_name, file_name)
ret, info = put_file(token, file_name, file_path, version='v2')
if ret['key'] == file_name and ret['hash'] == etag(file_path):
return base_url.format(file_name)
return ''
def handler(args: Args[Input])->Output:
# 获取用户输入的uuid
sys_uuid = args.input.sys_uuid
file_url = args.input.input_file_url
file_content = read_file_from_url(file_url)
if file_content:
match_results = bookmark_item_pattern.findall(file_content)
bookmark_item_list = []
if match_results and len(match_results) > 0:
for result in match_results:
bookmark_item_list.append(BookmarkItem(result[3], result[0], result[1], result[2]))
bookmark_json = json.dumps(bookmark_item_list, default=lambda obj: obj.__dict__, ensure_ascii=False)
output_file_url = upload_file(save_file(sys_uuid, bookmark_json))
return {"output_file_url": output_file_url, "error_msg": ""}
else:
return {"output_file_url": "", "error_msg": "未检索到书签项"}
**元数据 **配置下输入输出参数:
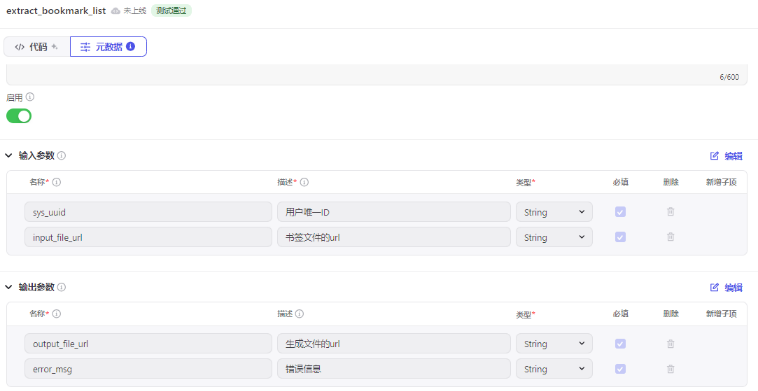
接着 **输入 **处点击 自动生成,把 input_file_url 的值替换为上传的书签文件url,点击 运行 试试:
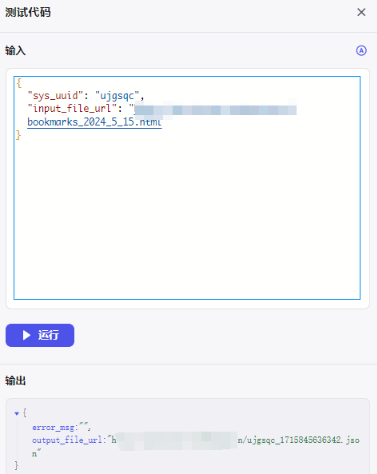
打开输出文件的URL:
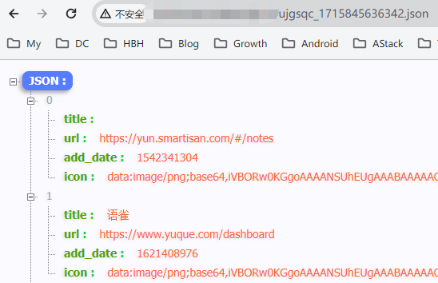
😄 书签列表提取成功🎉~
数据清洗
看了下书签列表,发现有些书签是有问题的 → 没有titile,而后面的 **分类整理 **和 **AI搜索 **都是很依赖标题的,需要为没有title的书签设置title。🤔 在请求站点时,**title字段 **一般都会返回 (即便弄了反爬),毕竟是 **SEO **(搜索引擎优化) 中一个重要的考虑因素,当然,还有一些其它有用的信息:

然后,requests 库的请求是 **同步 **的,发送一个请求,程序要等服务器响应后才继续执行,如果没title的书签比较多,耗时会比较久,节点太久没返回输出 ,会直接报错,整个工作流就崩了。
😄 所以,这里需要尽可能地快完成,直接上 异步请求+代理,前者用的 aiohttp,后者用的 亮数据,因为时不时有些数据爬取的单子,经常用到代理IP,用得最多的还是它,主要有以下几点:
- 代理 IP 质量和稳定性比较高,支持获取指定区域的代理IP (国内、国外)。
- 支持API调 **无头浏览器 **爬数据,自动过验证码、重试和指纹管理。
- 提供数据服务,有些都不用自己爬。
- 🌚 最重要一点,不用各种恶心的个人/企业认证
这里需要 动态IP → 真人住宅代理,直接写出爬取代码:
import aiohttp
import asyncio
import re
proxy = 'http://代理地址:端口'
title_pattern = re.compile(r'>([^<]*)</title>')
async def fetch(bookmark):
async with aiohttp.ClientSession() as session:
try:
async with session.get(bookmark['url'], proxy=proxy, ssl=False) as response:
if response:
bookmark['title'] = title_pattern.search(await response.text()).group(1)
return bookmark
except Exception as e:
print(str(e))
async def task(json_content):
# 构造异步请求任务列表
tasks = [fetch(bookmark) for bookmark in json_content]
# 等待所有任务完成
results = await asyncio.gather(*tasks)
return results
def handler(args: Args[Input])->Output:
result = asyncio.get_event_loop().run_until_complete(task(bookmark_json))
return {"result": result}
简单分类
💁♂️ 数据清洗完,就该分类了,一个简单粗暴的思路:
遍历提取书签 域名 作为Key,值为同一域名下的书签列表,写 Prompt 让 **AI模型 **判断它属于什么类型的站点,然后分类。
新建一个 工作流:
- 开始节点:传入书签json文件的url
- 代码节点:读取文件,遍历书签,组装prompt往后传递
- 大模型节点:使用 moonshot (128k) 模型来执行前面组装的prompt
- 代码节点:提取 分类标签,并未每个书签添加上次字段,最后返回更新后的json数据
拖拽下节点:
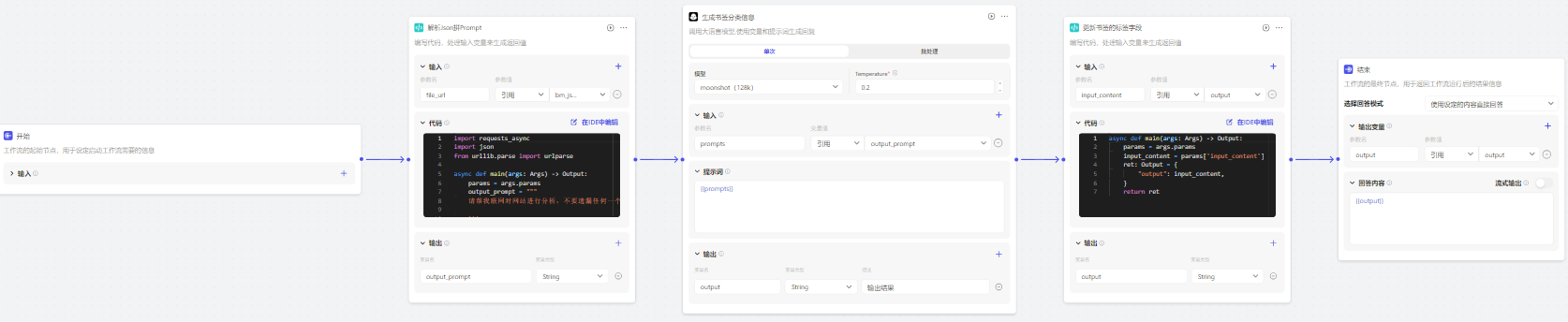
**解析Json拼Prompt节点 **的代码如下:
import requests_async
from urllib.parse import urlparse
async def main(args: Args) -> Output:
params = args.params
output_prompt = """
请帮我联网对网站进行分析,不要遗漏任何一个,严格按照这样的json格式返回:
```
[
{
"website_url": <网站链接>,
"website_name": <网站中文简称>,
"website_category": <网站分类,只显示一个最准确的>
}
]
```
具体网站列表如下:
"""
website_str = ""
input_file_url = params["file_url"]
response = await requests_async.get(input_file_url)
netloc_set = set()
if response:
response_json = response.json()
for bookmark_info in response_json:
netloc = urlparse(bookmark_info['url']).netloc
netloc_set.add(netloc)
for netloc in netloc_set:
website_str += " - {}\n".format(netloc)
ret: Output = {
"output_prompt": (output_prompt + website_str).strip(),
}
return ret
输入前面生成的** json文件url** 进行测试:
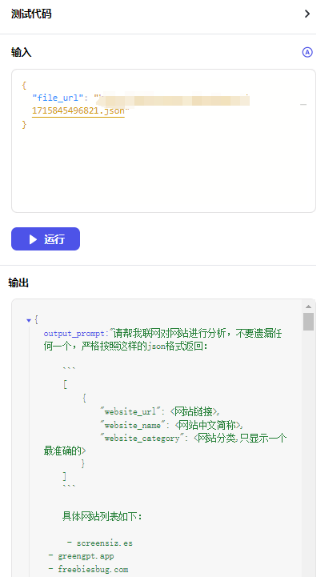
大模型节点直接使用输出结果作为 提示词,试运行后的输出结果:
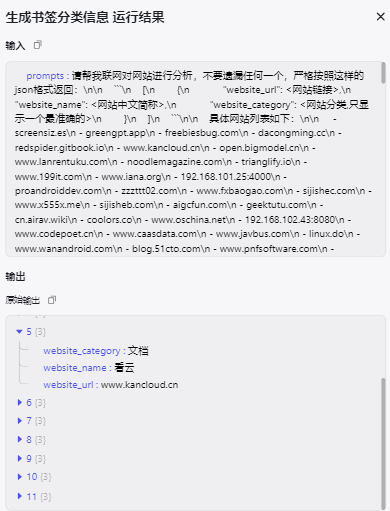
🤔 **输出格式 **是没错的,就是数量太少了,才11条,估计是 **提示词太长 **导致的,拆成10个网站列表,然后模型使用 批处理,修改下代码节点:
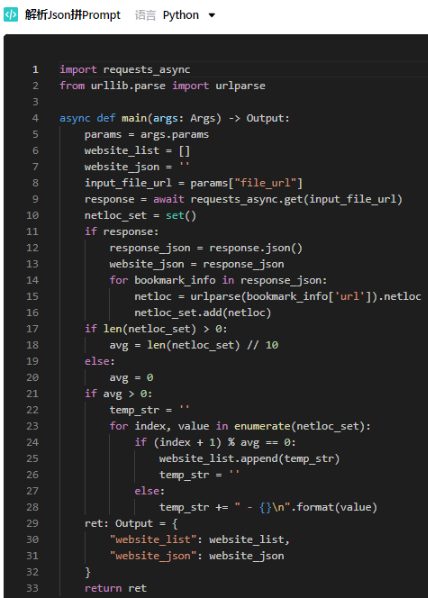
大模型节点也改改:
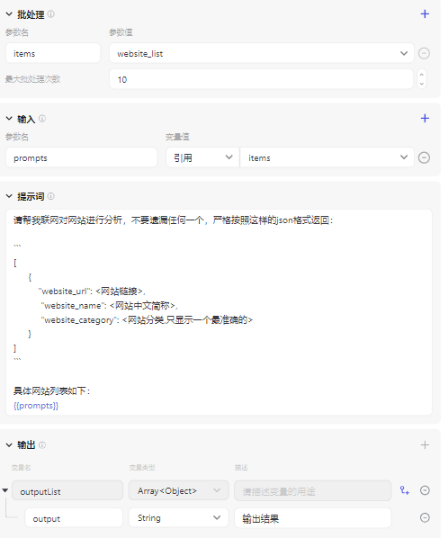
试运行看看效果:
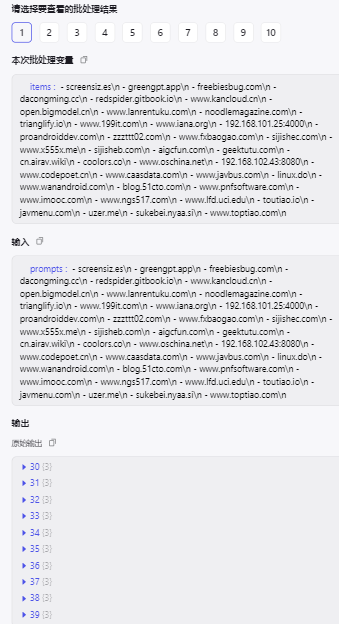
Nice,基本都拿到了,接着就是为每个书签添加对应的分类了,
import json
async def main(args: Args) -> Output:
params = args.params
website_json = json.loads(params['website_json'])
new_website_list = []
ret: Output = {}
# 存域名-分类的字典
website_category_dict = {}
llm_results = params['llm_result']
for llm_result in llm_results:
for website in json.loads(str(llm_result['output'])):
website_category_dict[website['website_url']] = website['website_category']
for website in website_json:
for website_category_key in website_category_dict.keys():
if website_category_key in website['url']:
website['category'] = website_category_dict[website_category_key]
new_website_list.append(website)
ret['output_json'] = json.dumps(new_website_list)
return ret
最后输出的json字符串:

👏 Nice,分类都安排上了~
生成书签文件
接着就是写插件,来解析上面的字符串,生成可以导入到浏览器的书签文件。☹️这一步是真的 坑,反复调整生成后的书签文件,然后浏览器导入书签测试。要么就是不显示分组,要么就是不显示书签,折腾了大半天终于成功导入😭,给出具体实现代码:
from runtime import Args
from typings.json_to_bookmark_file.json_to_bookmark_file import Input, Output
import requests
from qiniu import Auth, put_file, etag
import time
import os
import json
# 七牛云相关配置
access_key = 'xxx'
secret_key = 'yyy'
bucket_name = 'zzz'
base_url = "http://xxx.yyy.zzz/{}"
q = Auth(access_key, secret_key)
# 读取在线文件内容
def read_file_from_url(file_url):
response = requests.get(file_url)
# 避免中文乱码
response.encoding = response.apparent_encoding
if response:
return response.text
else:
return None
# 保存文件
def save_file(uuid, content):
file_path = "{}{}{}_{}.html".format(os.getcwd(), os.sep, uuid, int(time.time() * 1000))
with open(file_path, 'w', encoding='utf-8') as f:
f.write(content)
return file_path
# 上传文件到七牛云
def upload_file(file_path):
q = Auth(access_key, secret_key)
file_name = file_path.split('/')[-1]
token = q.upload_token(bucket_name, file_name)
ret, info = put_file(token, file_name, file_path, version='v2')
if ret['key'] == file_name and ret['hash'] == etag(file_path):
return base_url.format(file_name)
return ''
# 生成书签文件内容
def gen_bookmark_file_content(json_content):
result_content = """
<!DOCTYPE NETSCAPE-Bookmark-file-1>
<!-- This is an automatically generated file.
It will be read and overwritten.
DO NOT EDIT! -->
<META HTTP-EQUIV="Content-Type" CONTENT="text/html; charset=UTF-8">
<TITLE>Bookmarks</TITLE>
<H1>Bookmarks</H1>
<DL><p>
<DT><H3 ADD_DATE="1678077635" LAST_MODIFIED="1679623908" PERSONAL_TOOLBAR_FOLDER="true">书签栏</H3>
<DL><p>
"""
# 生成分类字典
category_dict = {}
bookmark_list = json.loads(json.loads(json_content))
for bookmark in bookmark_list:
if category_dict.get(bookmark['category']) is None:
category_dict[bookmark['category']] = []
category_dict[bookmark['category']].append(bookmark)
# 获取当前时间戳
timestamp = str(int(time.time()))
for key, value in category_dict.items():
# 分组标签
group_str = '<DT><H3 ADD_DATE="{}" LAST_MODIFIED="{}">{}</H3>\n<DL><p>\n'.format(timestamp, timestamp, key)
# 书签标签
for bm in value:
bookmark_str = '<DT><A HREF="{}" ADD_DATE="{}" ICON="{}">{}</A>\n'.format(bm['url'], bm['add_date'],
bm['icon'], bm['title'])
group_str += bookmark_str
group_str += "</DL><p>\n"
result_content += group_str
result_content += "<p></DL><p></DL><p>"
return result_content
def handler(args: Args[Input])->Output:
sys_uuid = args.input.sys_uuid
bookmark_json_file_url = args.input.bookmark_json_file_url
# 读取json文件内容
content = read_file_from_url(bookmark_json_file_url)
# 生成书签html文件后返回url
output_file_url = upload_file(save_file(sys_uuid, gen_bookmark_file_content(content)))
return {"output_file_url": output_file_url}
测试下代码试试:
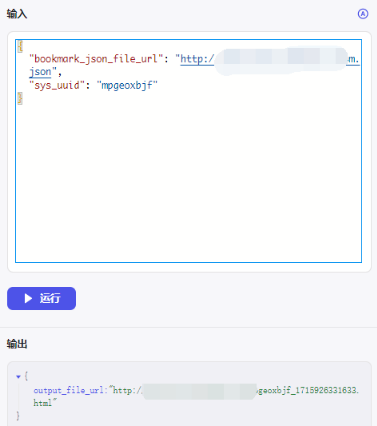
把生成后的书签html文件下载到本地,浏览器导入:
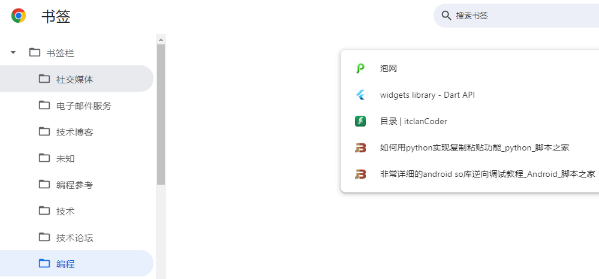
AI书签检索
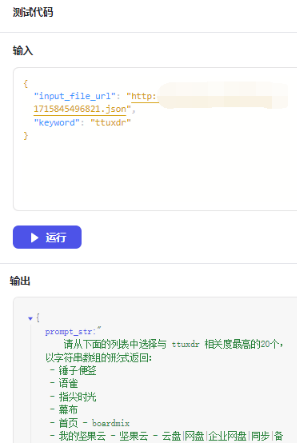
这部分就是把所有标题丢给大模型,让它去找其中可能与用户输入关键字最接近的20个书签,起一个代码节点拼prompt:
import requests_async
async def main(args: Args) -> Output:
ret: Output = {}
bookmark_dict_list = []
params = args.params
input_file_url = params['input_file_url']
keyword = params['keyword']
prompt_str = """
请从下面的列表中选择与 {} 相关度最高的20个,以字符串数组的形式返回:
""".format(keyword)
response = await requests_async.get(input_file_url)
if response:
response_json = response.json()
for bookmark_info in response_json:
prompt_str += " - {}\n".format(bookmark_info['title'])
bookmark_dict_list.append({bookmark_info['title']: bookmark_info['url']})
ret['prompt_str'] = prompt_str
ret['bookmark_dict_list'] = bookmark_dict_list
return ret
运行测试下:
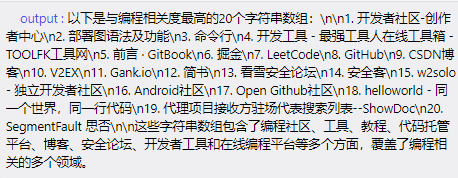
接个大模型节点,执行下生成的prompt,输出结果:
😄 不错,后面再加个代码节点,关联下书签链接,格式化下输出结果:
import re
async def main(args: Args) -> Output:
params = args.params
match_str = params['match_str']
bookmark_dict_list = params['bookmark_dict_list']
keyword = params['keyword']
output_str = 'AI检索到可能与【{}】匹配的书签如下:\n'.format(keyword)
fetch_title_pattern = re.compile(r'\d+\. ?(.*?)\n')
title_results = fetch_title_pattern.findall(match_str)
for bookmark_dict in bookmark_dict_list:
for title in title_results:
if bookmark_dict['title'] == title:
output_str += "- [{}]({})\n".format(title, bookmark_dict['url'])
ret: Output = {
"output_str": output_str,
}
return ret
接着试运行看看 **工作流 **的输出结果:
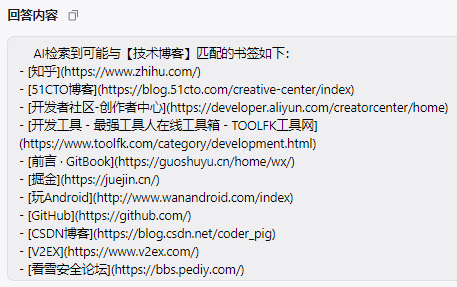
OK,运行无误,接着建个Bot把这些都串起来~
写个Bot串起来
🤡 随便写点东西:
然后我希望通过 **指令 **的形式来使用Bot:
- /tidy 书签html文件URL → 自动整理书签分类
- /search 书签html文件URL 关键词 → 书签检索
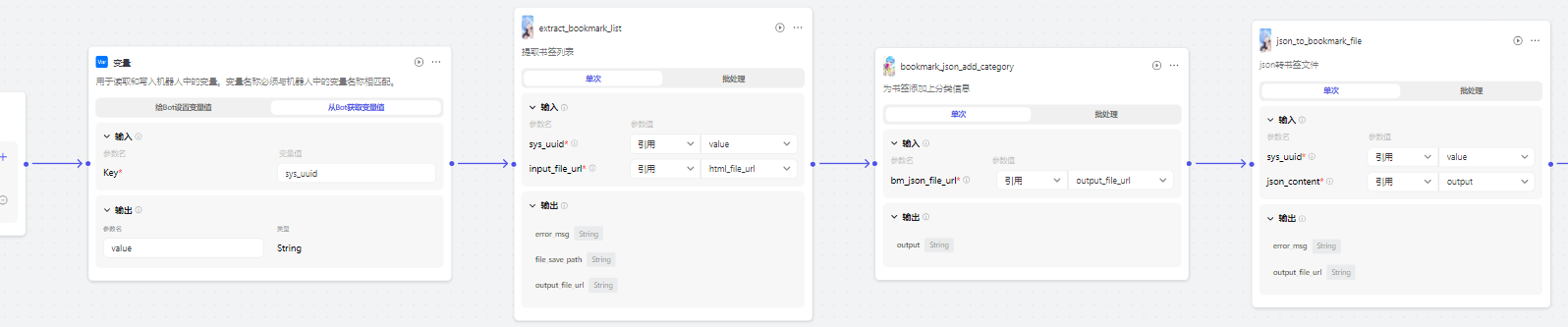
然后要建一个 自动整理书签分类 的工作流:
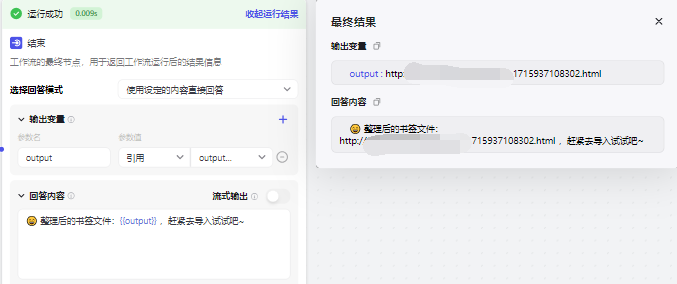
**试运行 **输出结果如下:
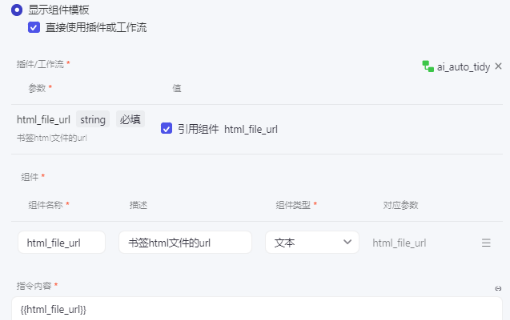
配置下 快捷指令 调用工作流:
书签检索也配上,点击按钮后,输入对应的参数值:
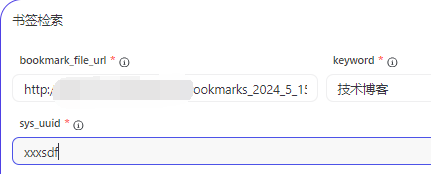
**回车 **看看输出结果:

🤷估计是 **收藏夹整理 **的工作流耗时比较久,所以一直报 运行中止,但是 **试运行 **又是可以的,后续看下这块怎么优化吧,毕竟大模型批处理10次 🤣
小结
🤡 还是低估了这个 Bot的复杂度 和 大模型输出结果的不稳定性,踩坑两天,大部分时间都花在改改上了,勉强实现了一个简单的雏形,虽然可用性 ≈ 0,不过也有收获,比如,使用 Coze IDE 开发 两个小技巧😏:
① 插件测试没问题,工作流调用,一跑就报错,而且全是这个错
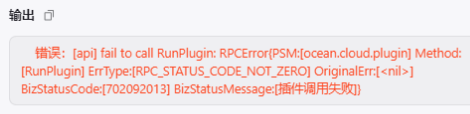
😳 能从这个错误信息里看出为啥报错吗?不能 ❗️,你只能知道插件挂了,没任何意义… 😏 那就自己 兜底,给插件代码包一层 try-except,**元字典 **里配一个存错误信息的字段:
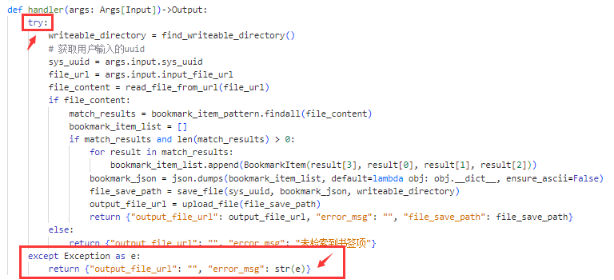
然后插件蹦的时候,你就能看到错误了,比如我上面的错误就是在这个目录写文件没权限:

💁♂️ 而且这样玩还有一个好处 → 插件测试直接通过,无脑发布~
②** 插件开发时能写文件,工作流不行**
🤷♀️ 我上面的报错就是这个,估摸着是不想让人在服务器上 乱拉💩(建文件) ,所以工作流的这个路径没给写权限。🤔 插件还是只用来处理和返回数据,当然,硬要拉,也是可以的,一种粗暴的方式就是向上和向下递归遍历可以写文件的目录,不过不建议这样玩哈 😄:
def has_write_permission(directory):
"""检查目录是否有写权限"""
return os.access(directory, os.W_OK)
def find_writeable_directory_upwards(directory):
"""向上递归查找有写权限的目录"""
if has_write_permission(directory):
return directory
parent_directory = os.path.dirname(directory)
if parent_directory == directory or parent_directory == '':
# 已经到达根目录或无更上一级目录,仍未找到有写权限的目录
return None
return find_writeable_directory_upwards(parent_directory)
def find_writeable_directory_downwards(directory):
"""向下递归查找有写权限的目录"""
for root, dirs, files in os.walk(directory):
if has_write_permission(root):
return root
for name in dirs:
dir_path = os.path.join(root, name)
if has_write_permission(dir_path):
return dir_path
# 如果当前目录及所有子目录都没有写权限
return None
def find_writeable_directory():
"""找到一个可写入的目录"""
current_directory = os.getcwd()
if has_write_permission(current_directory):
return current_directory
# 向上查找
writeable_directory_upwards = find_writeable_directory_upwards(current_directory)
if writeable_directory_upwards is not None:
return writeable_directory_upwards
# 向上未找到,尝试向下查找
return find_writeable_directory_downwards(current_directory)
# 调用处
writeable_directory = find_writeable_directory()
😊 然后也有一些新的灵感,比如:
- 使用 多Agent模式 来解耦,一个Bot专门处理收藏夹整理,一个Bot专门处理书签搜索。
- 用 数据库 来存解析后的书签数据,不用每次都贴一个url。
- 标签分组规则 的细化,比如:支持多级目录,基于用户的分组规则对未分组书签进行分组。
- 书签搜索:支持搜索词 精准搜索 和 AI模糊搜索,搜索结果附上精简的总结
- 等等…
🥰 后续会继续打磨,敬请期待~















 392
392











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









