







XLNet:Generalized Autogressive Pretraining for Language Understanding
https://github.com/zihangdai/xlnet
摘要
类似于Bert基于上下文进行建模的DAE(denoising autoencoding)的预训练模型比基于AR(autoRegressive)的语言模型得到了更好的效果。然而,Bert忽视了mask之间的依赖关系,并且预训练和微调之间的不一致(微调的时候没有mask),基于这样的优缺点(可以看到上下文),我们提出XLNet,通过最大化排列组合的因式分解的极大似然估计学习上下文的信息;通过使用AR,克服Bert的缺点。继承了transformer-xl的思想到预训练中。在20个任务上,xlnet比Bert表现好,包括qa、nli、情感分析等。
Introduction
先在未标注的文本进行预训练,后在下游任务中进行微调,两阶段的训练方式在nlp领域取得了巨大的成功。AR语言模型和AE是两个最成功的预训练目标。
AR语言模型计算文本的概率,给定一个文本
x
=
(
x
1
,
x
2
,
.
.
.
,
x
T
)
x=(x_1, x_2, ...,x_T)
x=(x1,x2,...,xT),AR语言模型计算一个前向的似然估计
p
(
x
)
=
∏
t
=
1
T
p
(
x
t
∣
x
<
t
)
p(x)=\prod_{t=1}^Tp(x_t|x_{<t})
p(x)=∏t=1Tp(xt∣x<t)或者一个后向的似然估计
p
(
x
)
=
∏
t
=
T
1
p
(
x
t
∣
x
>
t
)
p(x)=\prod_{t=T}^1p(x_t|x_{>t})
p(x)=∏t=T1p(xt∣x>t)。AR模型只能编码单向(前向或后向)的文本,在下游语言理解任务时,需要获取双向的文本信息。
AE语言模型从损坏的输入中重建数据,比如Bert,给定的输入中,一定量的词被mask替换,恢复原来的词是训练目标,Bert允许从上下文获取信息。然而,mask只出现在预训练过程中,造成了预训练-微调的不对等;Bert不能像AR模型使用链式法则计算联合概率。换句话说:Bert预测的每个mask的词和unmask的词都是独立的。
结合AR和AE的优点,克服缺点:
- XLNet使用分解因子的所有排列组合,替换AR模型中的前向或后向,基于排列组合,每个位置的文本可以看到左边和右边的词。
- AR模型没有对数据进行破坏,所以没有预训练-微调的不对等。基于AR模型,克服了Bert的缺点
proposed method
background
AR语言模型
max
θ
log
p
θ
(
x
)
=
∑
t
=
1
T
log
p
θ
(
x
t
∣
x
<
t
)
=
∑
t
=
1
T
log
exp
(
h
θ
(
x
1
:
t
−
1
)
T
e
(
x
t
)
)
∑
x
′
exp
(
h
θ
(
x
1
:
t
−
1
)
T
e
(
x
′
)
)
\max_{\theta} \log p_{\theta}(x)=\sum_{t=1}^T \log p_{\theta}(x_t|x_{<t})=\sum_{t=1}^T \log \frac {\exp (h_{\theta}(x_{1:t-1})^Te(x_t))}{\sum_{x^{'}}\exp (h_{\theta}(x_{1:t-1})^Te(x^{'}))}
θmaxlogpθ(x)=t=1∑Tlogpθ(xt∣x<t)=t=1∑Tlog∑x′exp(hθ(x1:t−1)Te(x′))exp(hθ(x1:t−1)Te(xt))
其中
h
θ
(
x
1
:
t
−
1
)
h_{\theta}(x_{1:t-1})
hθ(x1:t−1)是语言模型的文本表达(RNN、transformer),
e
(
x
)
e(x)
e(x)是x的向量。
Bert基于DAE,一个文本
x
x
x,随机替换以后成
x
^
\hat x
x^, 替换的单词是
x
∗
x^{*}
x∗,训练的目标函数是
max
θ
log
p
θ
(
x
∗
∣
x
^
)
≈
∑
t
=
1
T
m
t
log
p
θ
(
x
t
∣
x
^
)
=
∑
t
=
1
T
log
exp
(
H
θ
(
x
^
)
t
T
e
(
x
t
)
)
∑
x
′
exp
(
H
θ
(
x
^
)
t
T
e
(
x
′
)
)
\max_{\theta} \log p_{\theta}(x^{*}|\hat x) \thickapprox \sum_{t=1}^T m_t \log p_{\theta}(x_t|\hat x)=\sum_{t=1}^T \log \frac {\exp (H_{\theta}(\hat x)_t^Te(x_t))}{\sum_{x^{'}}\exp (H_{\theta}(\hat x)_t^Te(x^{'}))}
θmaxlogpθ(x∗∣x^)≈t=1∑Tmtlogpθ(xt∣x^)=t=1∑Tlog∑x′exp(Hθ(x^)tTe(x′))exp(Hθ(x^)tTe(xt))
当 x t x_t xt是mask时, m t = 1 m_t=1 mt=1。 H θ H_{\theta} Hθ是 x x x经过transformer以后的隐向量, H θ ( x ) = [ H θ ( x ) 1 , . . . , H θ ( x ) T ] H_{\theta}(x)=[H_{\theta}(x)_1, ...,H_{\theta}(x)_T] Hθ(x)=[Hθ(x)1,...,Hθ(x)T]
优缺点
- 独立假设 Bert假设所有mask的单词都是独立的
- 输入噪音 mask符号在下游任务中不会出现
- 文本独立 AR只接受左边的词,而Bert获取两边的词
objective:permutation language modeling
给定一个长度为T的句子x,有
T
!
T!
T!种排列组合,
Z
T
Z_T
ZT是所有排列组合的集合,使用
z
t
z_t
zt和
z
<
t
z_{<t}
z<t代表第t个元素和前t-1个元素,
z
∈
Z
T
z \in Z_T
z∈ZT 我们的目标函数可以写成(期望)
max
θ
E
z
∈
Z
T
[
∑
t
=
1
T
log
p
θ
(
x
z
t
∣
x
z
<
t
)
]
\max_{\theta} E_{z \in Z_T}[\sum _{t=1}^T\log p_{\theta}(x_{z_t}|x_{z_{<t}})]
θmaxEz∈ZT[t=1∑Tlogpθ(xzt∣xz<t)]
对于句子x,一次举例排列组合z,根据排列组合计算似然对数。可以看到上下文。因为基于AR语言模型,避免了Bert的缺点
remark on permutation
提出的目标函数仅置换分解顺序,而不置换句子顺序。换句话说,保持原有的句子顺序,使用与原始句子对应的位置编码,依靠transformer中的proper attention mask来实现分解顺序的替换。这样是有必要的,因为模型在微调期间只会遇到自然顺序的文本序列。
给个例子:
x
3
x_3
x3在相同输入句子x,不同排列组合下的情况

architecture:two-stream self-attention for target-aware representations
a concrete example of how standard LM parameterization fails
在permutation 目标下,传统的transformer不能达到最终目的,为什么呢?
假设
z
<
t
(
1
)
=
z
<
t
(
2
)
=
z
<
t
z_{<t}^{(1)}=z_{<t}^{(2)}=z_{<t}
z<t(1)=z<t(2)=z<t(前面的单词以及顺序都是一样的),但是
z
t
(
1
)
=
i
≠
j
=
z
t
(
2
)
z_{t}^{(1)}=i \neq j=z_{t}^{(2)}
zt(1)=i=j=zt(2)(预测的词位置不一样),在这种情况下,有
p
θ
(
X
i
=
x
∣
x
z
<
t
)
⏟
z
t
(
1
)
=
i
,
z
<
t
(
1
)
=
z
<
t
=
p
θ
(
X
j
=
x
∣
x
z
<
t
)
⏟
z
t
(
1
)
=
j
,
z
<
t
(
2
)
=
z
<
t
=
exp
(
h
(
x
<
t
)
T
e
(
x
)
)
∑
x
′
exp
(
h
(
x
<
t
)
T
e
(
x
′
)
)
\underbrace {p_{\theta}(X_i=x|x_{z_{<t}})}_{z_t^{(1)}=i,z_{<t}^{(1)}=z_{<t}}=\underbrace {p_{\theta}(X_j=x|x_{z_{<t}})}_{z_t^{(1)}=j,z_{<t}^{(2)}=z_{<t}}=\frac {\exp (h(x_{<t})^Te(x))}{\sum_{x^{'}}\exp (h(x_{<t})^Te(x^{'}))}
zt(1)=i,z<t(1)=z<t
pθ(Xi=x∣xz<t)=zt(1)=j,z<t(2)=z<t
pθ(Xj=x∣xz<t)=∑x′exp(h(x<t)Te(x′))exp(h(x<t)Te(x))
从上式可以看出,两个不同位置的目标有同样的模型预测结果,然而,这两者应该是不同的。所以传统的transformer会失败
提出新的目标函数target-aware representations解决上述问题:
p
θ
(
X
z
t
=
x
∣
x
z
<
t
)
=
exp
(
g
θ
(
x
<
t
,
z
t
)
T
e
(
x
)
)
∑
x
′
exp
(
g
θ
(
x
<
t
,
z
t
)
T
e
(
x
′
)
)
p_{\theta}(X_{z_t}=x|x_{z_{<t}})=\frac {\exp (g_{\theta}(x_{<t},z_t)^Te(x))}{\sum_{x^{'}}\exp (g_{\theta}(x_{<t},z_t)^Te(x^{'}))}
pθ(Xzt=x∣xz<t)=∑x′exp(gθ(x<t,zt)Te(x′))exp(gθ(x<t,zt)Te(x))
g
θ
(
x
<
t
,
z
t
)
g_{\theta}(x_{<t},z_t)
gθ(x<t,zt)的输入包含了目标的位置
z
t
z_t
zt
two-stream self-attention
怎么定义 g θ ( x < t , z t ) g_{\theta}(x_{<t},z_t) gθ(x<t,zt)是一个问题
- 预测词 x z t x_{z_t} xzt时,只使用 z t {z_t} zt的位置信息,而不使用内容 x z t x_{z_t} xzt—(query representation)
- 预测词 x z j − − j > t x_{z_j}--j>t xzj−−j>t时,应该既编码 x z t x_{z_t} xzt的位置,也要编码内容—(content representation)

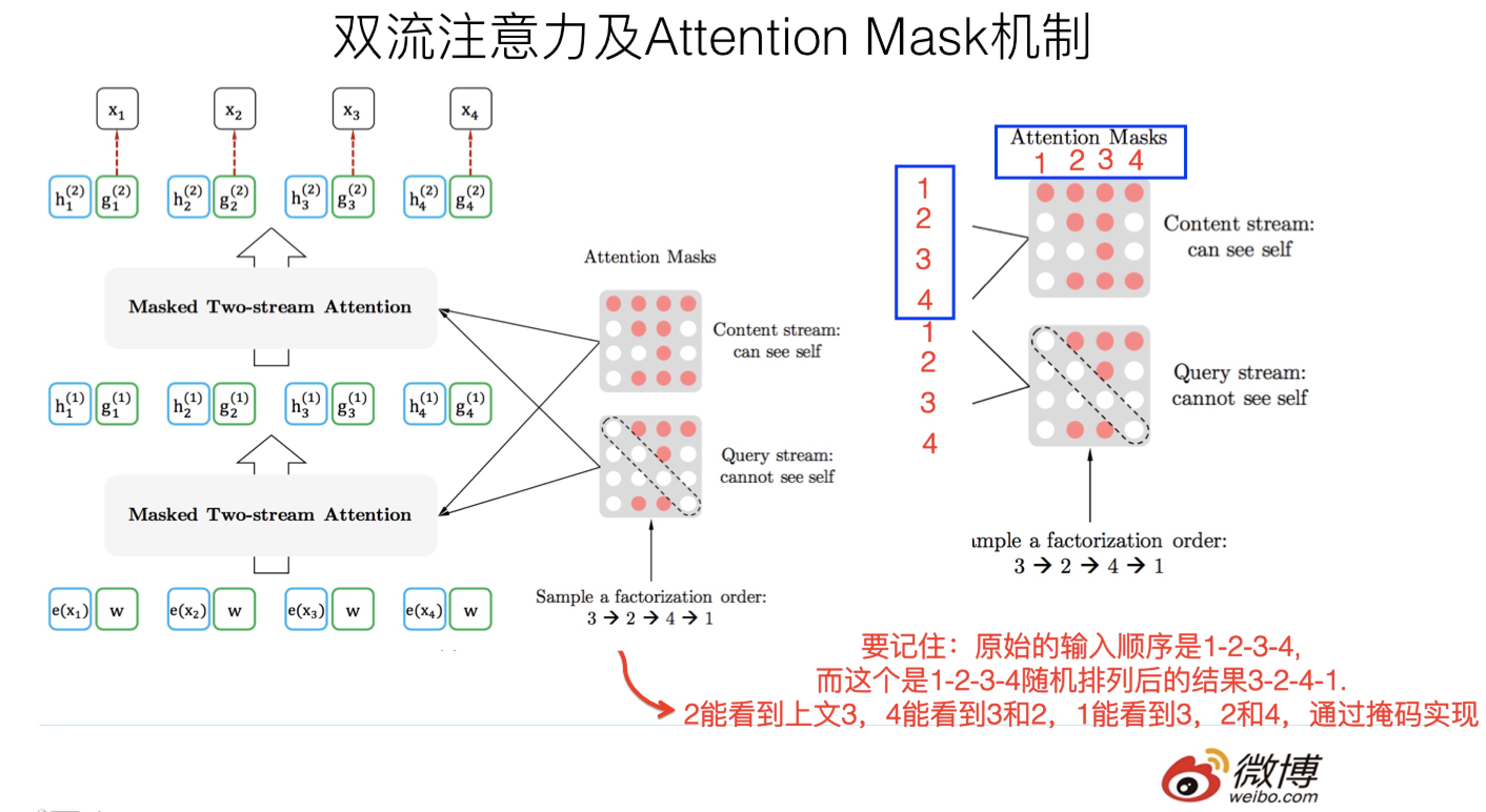
第一层初始化可训练向量
g
i
(
0
)
=
w
g_i(0)=w
gi(0)=w,内容流使用词向量
h
i
(
0
)
=
e
(
x
i
)
h_i(0)=e(x_i)
hi(0)=e(xi)
后面每一层按照
g
z
t
m
=
A
t
t
e
n
t
i
o
n
(
A
=
g
z
t
m
−
1
,
K
V
=
h
z
<
t
m
−
1
;
θ
)
.
.
.
.
(
q
u
e
r
y
−
s
t
r
e
a
m
−
o
n
l
y
−
u
s
e
−
p
o
s
i
t
i
o
n
)
h
z
t
m
=
A
t
t
e
n
t
i
o
n
(
A
=
h
z
t
m
−
1
,
K
V
=
h
z
≤
t
m
−
1
;
θ
)
.
.
.
.
(
c
o
n
t
e
n
t
−
s
t
r
e
a
m
−
c
a
n
−
u
s
e
−
c
o
n
t
e
n
t
)
g_{z_t}^{m}=Attention(A=g_{z_t}^{m-1},KV=h_{z_{<t}}^{m-1};\theta) ....(query-stream-only-use-position)\\ h_{z_t}^{m}=Attention(A=h_{z_t}^{m-1},KV=h_{z_{\leq t}}^{m-1};\theta) ....(content-stream-can-use-content)
gztm=Attention(A=gztm−1,KV=hz<tm−1;θ)....(query−stream−only−use−position)hztm=Attention(A=hztm−1,KV=hz≤tm−1;θ)....(content−stream−can−use−content)
两条网络使用同一组参数,更新规则和传统的transformer一样
在微调时,去掉query流,只保留content流
最后,使用最后一层的表达
g
z
t
M
g_{z_t}^{M}
gztM计算概率
partial prediction
虽然permutation LM挺好的,但是如何优化呢?为了减少优化的难度,在一个因式分解中,我们只选择预测最后的几个单词。
分割句子Z成
z
>
c
z_{>c}
z>c(目标子句子)和
z
≤
c
z_{\leq c}
z≤c(非目标子句子),c是切割点。目标函数是
max
θ
E
z
∈
Z
T
=
=
E
z
∈
Z
T
[
∑
t
=
c
+
1
∣
z
∣
log
p
θ
(
x
z
t
∣
x
z
≤
t
)
]
\max _{\theta}E_{z \in Z_T}==E_{z \in Z_T}[\sum _{t=c+1}^{|z|}\log p_{\theta}(x_{z_t}|x_{z_{\leq t}})]
θmaxEz∈ZT==Ez∈ZT[t=c+1∑∣z∣logpθ(xzt∣xz≤t)]
z
>
c
z_{>c}
z>c是给定排列组合后的z,能处理较长的文本,吸收较多的信息。
给定超参数K,使得
∣
z
∣
/
(
∣
z
∣
−
c
)
=
K
|z|/(|z|-c)=K
∣z∣/(∣z∣−c)=K。比如句子长是100,K=7,则只选后面的14个词
没有选中的词不需要计算query representations,节省速度和内存
incorporation ideas from transformer-xl
整合Transformer-xl的思想到预训练框架中,并以之命名模型名xlnet(同一个作者,同一种命名)
合并两种重要的思想:
- 相对位置编码方案(the relative positional encoding scheme)
- 段循环机制(the segment recurrence mechanism)
假设有两个段落
x
^
=
s
1
:
T
\hat x=s_{1:T}
x^=s1:T和
x
=
s
T
:
2
T
x=s_{T:2T}
x=sT:2T,使用
z
^
\hat z
z^和
z
z
z是两个段落的排列组合。基于
z
^
\hat z
z^,可以计算第一个段落,每一层m得到内容表达(content representation)
h
^
(
m
)
\hat h^{(m)}
h^(m)
对于下一个段落
x
x
x,注意力更新可以被写作:
h
z
t
(
m
)
←
A
t
t
e
n
t
i
o
n
(
Q
=
h
z
t
(
m
−
1
)
,
K
V
=
[
h
^
(
m
−
1
)
,
h
z
≤
t
(
m
−
1
)
]
,
θ
)
h_{z_t}^{(m)} \leftarrow Attention(Q=h_{z_t}^{(m-1)}, KV=[\hat h^{(m-1)}, h_{z_{\leq t}}^{(m-1)}], \theta)
hzt(m)←Attention(Q=hzt(m−1),KV=[h^(m−1),hz≤t(m−1)],θ)
注意:位置编码只依赖于句子中的真实位置,因此,一旦文本表达
h
^
(
m
)
\hat h^{(m)}
h^(m)获得了,上述的注意力更新与
z
^
\hat z
z^是独立的。这就允许在不知道前面段落排列组合的情况下,重复使用内存。query流可以以同样的方式进行计算。
g
z
t
(
m
)
←
A
t
t
e
n
t
i
o
n
(
Q
=
g
z
t
(
m
−
1
)
,
K
V
=
[
h
^
(
m
−
1
)
,
h
z
<
t
(
m
−
1
)
]
,
θ
)
g_{z_t}^{(m)} \leftarrow Attention(Q=g_{z_t}^{(m-1)}, KV=[\hat h^{(m-1)}, h_{z_{<t}}^{(m-1)}], \theta)
gzt(m)←Attention(Q=gzt(m−1),KV=[h^(m−1),hz<t(m−1)],θ)

modeling multiple segments
[CLS, A, SEP, B, SEP]
两句话输入时,和Bert是一样的输入
虽然在XLNet-large中,取消了NSP(next sentence prediction)这个任务
- relative segment encodings Bert在词向量中,加了一个绝对位置向量(absolute segment embedding),xlnet采用了相对位置编码(relative encoding),这和transformer-xl是一样的
discussion
预测【new york is a city】,Bert和xlnet都选择new York两个单词作为预测词,xlnet的排列组合顺序是【is a city new york】,Bert和xlnet的目标函数分布如下
T
B
E
R
T
=
log
p
(
n
e
w
∣
i
s
,
a
,
c
i
t
y
)
+
log
p
(
y
o
r
k
∣
i
s
,
a
,
c
i
t
y
)
T
x
l
n
e
t
=
log
p
(
n
e
w
∣
i
s
,
a
,
c
i
t
y
)
+
log
p
(
y
o
r
k
∣
n
e
w
,
i
s
,
a
,
c
i
t
y
)
T_{BERT} = \log p(new|is,a, city )+\log p(york|is,a, city )\\ T_{xlnet} = \log p(new|is,a, city )+\log p(york|new, is,a, city )
TBERT=logp(new∣is,a,city)+logp(york∣is,a,city)Txlnet=logp(new∣is,a,city)+logp(york∣new,is,a,city)
代码
run_classifier.py-训练测试代码,需要指定预加载模型、测试数据等
import function_builder # 引进modeling
class InputExample(object)# 文本分类的单一样本
class DataProcessor(object)# 数据处理的基类
class GLUEProcessor(DataProcessor)# GLUE
class Yelp5Processor(DataProcessor)# Yelp5
class ImdbProcessor(DataProcessor)# Imdb
class MnliMatchedProcessor(GLUEProcessor)# Mnli
class MnliMismatchedProcessor(MnliMatchedProcessor)# MuliMismatched
class StsbProcessor(GLUEProcessor)# Stsb--均与Bert类似,比Bert多了几种类型
def file_based_convert_examples_to_features# 转换InputExample到TFRecord file
def file_based_input_fn_builder# 产生input_fn
def get_model_fn#
def main(_):
xlnet.py-模型、运行、xlnet的配置文件
class XLNetConfig(object):
"""XLNetConfig contains hyperparameters that are specific to a model checkpoint;
i.e., these hyperparameters should be the same between
pretraining and finetuning.
The following hyperparameters are defined:
n_layer: int, the number of layers.
d_model: int, the hidden size.
n_head: int, the number of attention heads.
d_head: int, the dimension size of each attention head.
d_inner: int, the hidden size in feed-forward layers.
ff_activation: str, "relu" or "gelu".
untie_r: bool, whether to untie the biases in attention.
n_token: int, the vocab size.
"""
class RunConfig(object):
"""RunConfig contains hyperparameters that could be different
between pretraining and finetuning.
These hyperparameters can also be changed from run to run.
We store them separately from XLNetConfig for flexibility.
Args:
is_training: bool, whether in training mode.
use_tpu: bool, whether TPUs are used.
use_bfloat16: bool, use bfloat16 instead of float32.
dropout: float, dropout rate.
dropatt: float, dropout rate on attention probabilities.
init: str, the initialization scheme, either "normal" or "uniform".
init_range: float, initialize the parameters with a uniform distribution
in [-init_range, init_range]. Only effective when init="uniform".
init_std: float, initialize the parameters with a normal distribution
with mean 0 and stddev init_std. Only effective when init="normal".
mem_len: int, the number of tokens to cache.
reuse_len: int, the number of tokens in the currect batch to be cached
and reused in the future.
bi_data: bool, whether to use bidirectional input pipeline.
Usually set to True during pretraining and False during finetuning.
clamp_len: int, clamp all relative distances larger than clamp_len.
-1 means no clamping.
same_length: bool, whether to use the same attention length for each token.
"""
class XLNetModel(object):
"""A wrapper of the XLNet model used during both pretraining and finetuning."""
def __init__(self, xlnet_config, run_config, input_ids, seg_ids, input_mask,
mems=None, perm_mask=None, target_mapping=None, inp_q=None,
**kwargs):
"""
Args:
xlnet_config: XLNetConfig,
run_config: RunConfig,
input_ids: int32 Tensor in shape [len, bsz], the input token IDs.
seg_ids: int32 Tensor in shape [len, bsz], the input segment IDs.
input_mask: float32 Tensor in shape [len, bsz], the input mask.
0 for real tokens and 1 for padding.
mems: a list of float32 Tensors in shape [mem_len, bsz, d_model], memory
from previous batches. The length of the list equals n_layer.
If None, no memory is used.
perm_mask: float32 Tensor in shape [len, len, bsz].
If perm_mask[i, j, k] = 0, i attend to j in batch k;
if perm_mask[i, j, k] = 1, i does not attend to j in batch k.
If None, each position attends to all the others.
target_mapping: float32 Tensor in shape [num_predict, len, bsz].
If target_mapping[i, j, k] = 1, the i-th predict in batch k is
on the j-th token.
Only used during pretraining for partial prediction.
Set to None during finetuning.
inp_q: float32 Tensor in shape [len, bsz].
1 for tokens with losses and 0 for tokens without losses.
Only used during pretraining for two-stream attention.
Set to None during finetuning.
"""
def get_pooled_out(self, summary_type, use_summ_proj=True):
"""
Args:
summary_type: str, "last", "first", "mean", or "attn". The method
to pool the input to get a vector representation.
use_summ_proj: bool, whether to use a linear projection during pooling.
Returns:
float32 Tensor in shape [bsz, d_model], the pooled representation.
"""
def get_sequence_output(self):
"""
Returns:
float32 Tensor in shape [len, bsz, d_model]. The last layer hidden
representation of XLNet.
"""
def get_new_memory(self):
"""
Returns:
list of float32 Tensors in shape [mem_len, bsz, d_model], the new
memory that concatenates the previous memory with the current input
representations.
The length of the list equals n_layer.
"""
def get_embedding_table(self):
"""
Returns:
float32 Tensor in shape [n_token, d_model]. The embedding lookup table.
Used for tying embeddings between input and output layers.
"""
def get_initializer(self):
"""
Returns:
A tf initializer. Used to initialize variables in layers on top of XLNet.
"""
function_builder.py















 450
450











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









