







出发点
这次开始的模型是qwen1.5-14b-chat,我是基于Llama的代码做的修改,这中间关于模型结构其实没有任何区别,但我为了将input-output对应上,还是用了一天的时间,也是我一开始就疏忽了原因吧。请先阅读上一篇,关于完全一样的内容,这里不再重复
Qwen1.5 介绍
模型结构
from transformers import AutoModelForCausalLM, AutoTokenizer, GenerationConfig
device = "cuda" # the device to load the model onto
model_name = "/usr/downloads/Qwen1.5-14B-Chat"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
prompt = "介绍一下LLM"
messages = [
{"role": "system", "content": "你是一个有用的AI助手"},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
# 为了保证response没有随机性
model.generation_config = GenerationConfig.from_pretrained(model_name)
model.generation_config.do_sample = False
model.generation_config.repetition_penalty
# 1.05
#####################################
# model.generation_config.repetition_penalty = 1# 我终于找到原因了
#####################################
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print (response)
#LLM,全称为Master of Laws(法学硕士),是一种研究生学位,专为那些已经拥有法学学士学位的人设计,旨在提供更深入的法律知识和专业技能。LLM课程通常针对特定的法律领域,如国际法、商业法、知识产权法、税法、环境法等,或者可以是法学理论研究。
#在LLM课程中,学生会进行高级法律分析、案例研究、研讨会和可能的独立研究项目,以深化他们对法律体系的理解,提升批判性思考和解决问题的能力。许多LLM课程也鼓励学生参与教学助理工作或学术研究,以便积累实践经验并为未来的职业生涯做准备。
#LLM学位在全球范围内被广泛认可,对于希望在法律界进一步发展,如成为律师、法律顾问、法律教授或从事国际法律事务的人来说,这是一个重要的学术里程碑。完成LLM后,学生通常需要通过国家或地区的律师资格考试才能执业。
"""
Qwen2ForCausalLM(
(model): Qwen2Model(
(embed_tokens): Embedding(152064, 5120)
(layers): ModuleList(
(0-39): 40 x Qwen2DecoderLayer(
(self_attn): Qwen2Attention(
(q_proj): Linear(in_features=5120, out_features=5120, bias=True)
(k_proj): Linear(in_features=5120, out_features=5120, bias=True)
(v_proj): Linear(in_features=5120, out_features=5120, bias=True)
(o_proj): Linear(in_features=5120, out_features=5120, bias=False)
(rotary_emb): Qwen2RotaryEmbedding()
)
(mlp): Qwen2MLP(
(gate_proj): Linear(in_features=5120, out_features=13696, bias=False)
(up_proj): Linear(in_features=5120, out_features=13696, bias=False)
(down_proj): Linear(in_features=13696, out_features=5120, bias=False)
(act_fn): SiLU()
)
(input_layernorm): Qwen2RMSNorm((5120,), eps=1e-06)
(post_attention_layernorm): Qwen2RMSNorm((5120,), eps=1e-06)
)
)
(norm): Qwen2RMSNorm((5120,), eps=1e-06)
(rotary_emb): Qwen2RotaryEmbedding()
)
(lm_head): Linear(in_features=5120, out_features=152064, bias=False)
)
"""
- 模型从model、tokenizer的加载和之前的模型没有差别
- Model的生成方式默认是sample
- 差别主要是model.generation_config.repetition_penalty
- 这个参数来自于generation_config.json,涉及到采样策略了,是我们之前没见过的领域了。
- 这个模型里有两个rotary_emb,默认使用的是layers的,self_attn中的是不使用的,我的代码里都没有初始化self_attn中的rotary_emb,因为我一开始没注意到,2025.03.21才注意到
参数量
"""
# 注意一下,只有三个线性层有bias
# word embedding+lm_head
152064*5120*2=1557135360
# 最后一层后面的LN
5120
# 0层有的参数
# LN
5120*2=10240
# self_attn weight
5120*5120*4=104857600
# self_attn bias 注意这里o_proj没有bias
5120*3=15360
# MLP
5120*13696*3=210370560
"""
1557135360+5120+(10240+104857600+15360+210370560)*40=14167290880
RepetitionPenaltyLogits
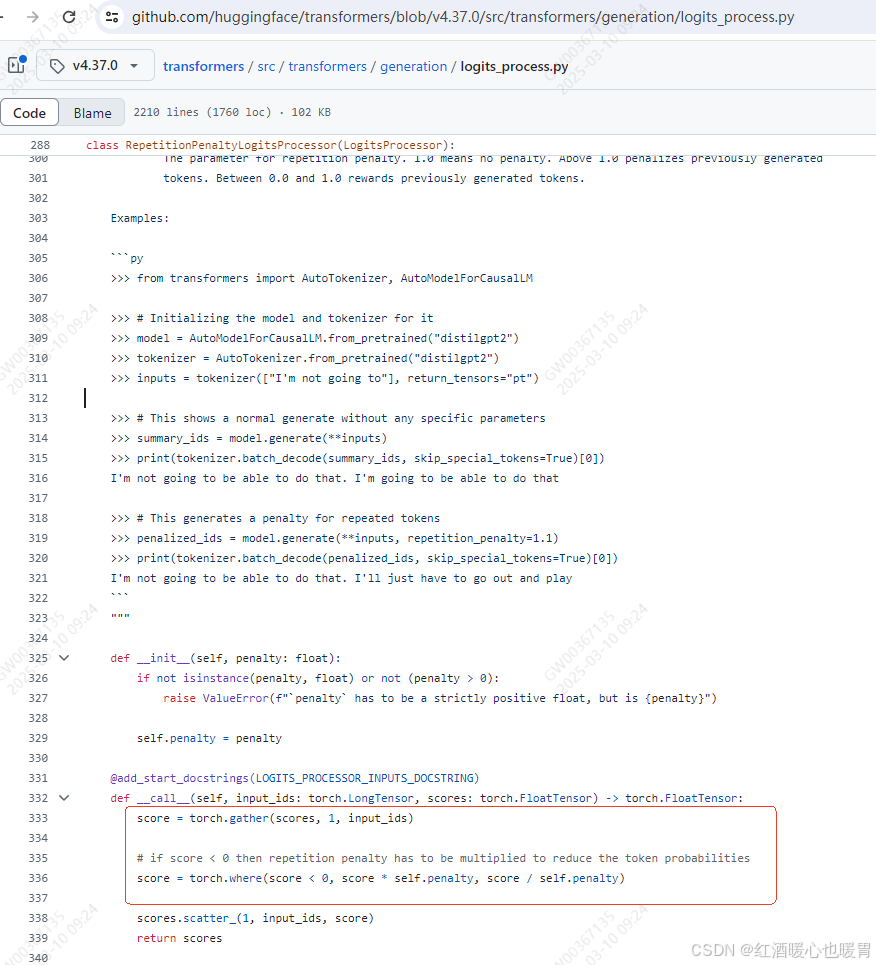
在每步时对之前出现过的词的概率做出惩罚,即降低出现过的字的采样概率,让模型趋向于解码出没出现过的词
class RepetitionPenaltyLogitsProcessor():
r"""
[`LogitsProcessor`] that prevents the repetition of previous tokens through a penalty. This penalty is applied at
most once per token. Note that, for decoder-only models like most LLMs, the considered tokens include the prompt.
In the original [paper](https://arxiv.org/pdf/1909.05858.pdf), the authors suggest the use of a penalty of around
1.2 to achieve a good balance between truthful generation and lack of repetition. To penalize and reduce
repetition, use `penalty` values above 1.0, where a higher value penalizes more strongly. To reward and encourage
repetition, use `penalty` values between 0.0 and 1.0, where a lower value rewards more strongly.
Args:
penalty (`float`):
The parameter for repetition penalty. 1.0 means no penalty. Above 1.0 penalizes previously generated
tokens. Between 0.0 and 1.0 rewards previously generated tokens.
"""
def __init__(self, penalty: float):
self.penalty = penalty
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor) -> torch.FloatTensor:
score = torch.gather(scores, 1, input_ids)
# if score < 0 then repetition penalty has to be multiplied to reduce the token probabilities
score = torch.where(score < 0, score * self.penalty, score / self.penalty)
scores.scatter_(1, input_ids, score)
return scores
代码修改的部分
代码中需要将Llama修改为Qwen2,注意bias中q_proj、k_proj、v_proj是True,其他几个都是False
添加RepetitionPenaltyLogitsProcessor
class Qwen2ForCausalLM(Qwen2PreTrainedModel):
def chat(self, tokenizer, query):
...
next_token_logits = hidden_states[:, -1, :].float()
# 注意一下,这里的数据类型需要转换为float
if self.generation_config.repetition_penalty>1:
logits_processor = RepetitionPenaltyLogitsProcessor(self.generation_config.repetition_penalty)
next_token_scores = logits_processor(input_ids, next_token_logits)
next_token_logits = next_token_scores
# 修改logits
next_tokens = torch.argmax(next_token_logits, dim=-1)
...
最后一点代码量
""" PyTorch Qwen2 model. """
import copy
import re
import torch
import torch.nn.functional as F
from torch import nn
from typing import Optional, Tuple, List, Callable
from transformers.modeling_utils import PreTrainedModel
from transformers.modeling_rope_utils import ROPE_INIT_FUNCTIONS
from configuration_qwen2 import Qwen2Config
from transformers.activations import ACT2FN
把这些代码保存成llama.py,放在Qwen1.5-14B-Chat的代码中,就可以正常使用了
from llama import *
from transformers import AutoTokenizer
model_path = "/usr/downloads/Qwen1.5-14B-Chat"
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
model = Qwen2ForCausalLM.from_pretrained(model_path, trust_remote_code=True, torch_dtype=torch.bfloat16).cuda()
print (model.generation_config)
prompt = "介绍一下LLM"
messages = [
{"role": "system", "content": "你是一个有用的AI助手"},
{"role": "user", "content": prompt}
]
response = model.chat(tokenizer, messages)
print (response)
结束语
这里介绍了Qwen1.5-14b-chat模型从输入到输出,模型使用Llama结构,但是额外引入了logits_processor,后面也会慢慢的介绍其他的采样方法。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









