







1训练mnist数据集,首先运行以下脚本:
./examples/mni st/train_lenet.sh
打开该脚本,发现里面就一句话
./build/tools/caffe train –solver=examples/mnist/lenet_solver.prototxt
这是调用编译好的build/tools/caffe.bin二进制文件,参数solver指定了训练超参数文件。
接着打开该prototxt文件,内容如下:
net: “examples/mnist/lenet_train_test.prototxt’’ #指定使用哪个网络模型进行训练
test_iter: 100 #在测试的时候,需要迭代的次数,一般等于测试样本数/batch_size
test_interval: 500 # 训练时的测试间隔。也就是每训练500次,进行一次测试。
base_lr: 0.01 #基础学习率
momentum: 0.9 #上一次梯度更新的权重
type: SGD #优化算法选择
weight_decay: 0.0005 # 权重衰减参数,正则化项前面的系数。
lr_policy: “inv“ #学习率策略设置
gamma: 0.0001 #与学习率策略设置相关的变量,稍后介绍
power: 0.75 #与学习率策略设置相关的变量,稍后介绍
display: 100 #每训练100次,在屏幕上显示一次。可以随便设置
max_iter: 20000 #最大迭代次数
snapshot: 5000 #设置训练多少次以后保存(训练好的caffemodel)
snapshot_prefix: “examples/mnist/lenet“ #设置上面的保存路径
solver_mode: GPU #设置训练模式为GPU其中,weight decay是放在正则项(regularization)前面的一个系数,正则项一般指示模型的复杂度,所以weight decay的作用是调节模型复杂度对损失函数的影响。
SGD是通过梯度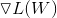
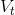
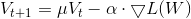
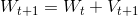
其中,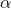
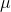
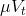
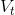
在本例中,base_lr,lr_policy,gamma,power一起决定了学习率随迭代次数的变化。
caffe总共提供了6种学习率设置策略(具体定义位于caffe-master/src/caffe/solvers/sgd_solver.cpp中的GetLearningRate())
lr_policy:
1 fixed: always return base_lr
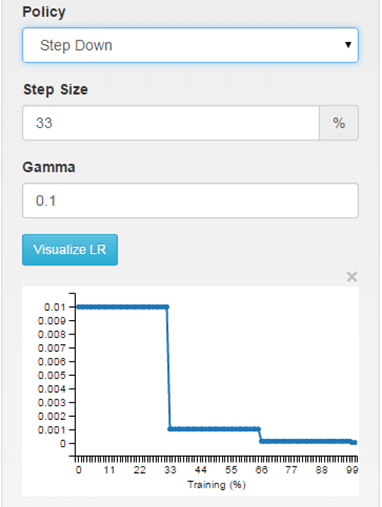
2 step: return base_lr * gamma ^ (floor(iter / step))
3 exp: return base_lr * gamma ^ iter
4 inv: return base_lr * (1 + gamma * iter) ^ (- power)
5 multistep: similar to step but it allows non uniform steps defined by stepvalue
6 poly: return base_lr (1 - iter/max_iter) ^ (power)
7 sigmoid: return base_lr ( 1/(1 + exp(-gamma * (iter - stepsize))))
其中,inv和step用的比较多。inv表示学习率随迭代次数是指数下降的关系,而step表示迭代次数每增加一个步长(step),学习率则变为原来的gamma倍。如下所示:
具体的网络模型(examples/mnist/lenet_train_test.prototxt)就不一层层地贴出来了。这里介绍一下权重初始化的一些参数。
weight_filler
{
type: “xavier”
std: 0.01
}
Weight_filter的种类大致有3种,constant, gaussian,Xavier
consant: 0
gaussian: 初始化权重满足高斯分布
xaiver: 初始化权重满足均匀分布(目的是保证输入和输出方差一致),如下图所示:
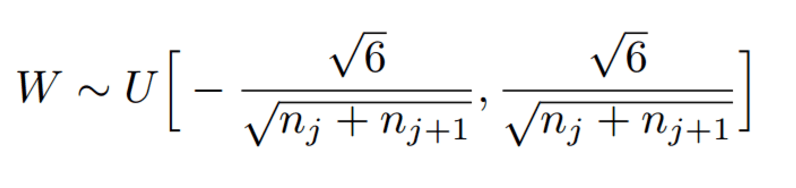
Xavier博客
Xavier论文
下图是Lenet的结构图,我们可以据此退出其权重以及偏置的个数。

















 363
363

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









