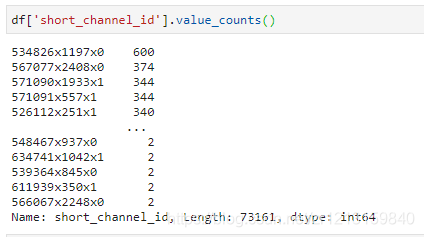
现在有一张表,表中的short_channel_id字段包含很多重复的值,现在统计重复值出现的次数 表大概是这样的 可以看出其中是有重复的值的,现在统计重复的值出现的次数,只需使用下面这一行 df['short_channel_id'].value_counts() 结果如下 注意上面是value_counts(),不是value_count()


























 2061
2061

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


 被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言
被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言






