










最近研究INT8量化的相关计算原理,有一篇文章讲解INT8量化讲解的很通透,我给出了相关链接。
使用Netron进行模型可视化,选取ONNX_MODEL_ZOO中的一个mnist-12-int8的模型,其中的一个算子名字叫做 QLinearConv,其中有一些参数。
Onnx中有共计有几个Proto,ModelProto、GraphProto、NodeProto、ValueInfoProto、TensorProto、AttributeProto这几种。导出一个ONNX模型就是导出一个ModelProto。ModelProtp中包含GraphProto、版本号等信息。GraphProto又包含了NodeProto类型的node,ValueInfoProto类型的input和output,TensorProto类型的initializer。其中,node包含了模型中的所有OP,input和output包含了模型的输入和输出,initializer包含了所有的权重信息。 每个计算节点node中还包含了一个AttributeProto数组,用来描述该节点的属性,比如Conv节点或者卷积层的属性包含group,pad,strides等等。
| 类型 | 用途 |
|---|---|
| ModelProto | 定义了整个网络的模型结构 |
| GraphProto | 定义了模型的计算逻辑,包含了构成图的节点,这些节点组成了一个有向图结构 |
| NodeProto | 定义了每个OP的具体操作 |
| ValueInfoProto | 序列化的张量,用来保存weight和bias |
| TensorProto | 定义了输入输出形状信息和张量的维度信息 |
| AttributeProto | 定义了OP中的具体参数,比如Conv中的stride和kernel_size等 |
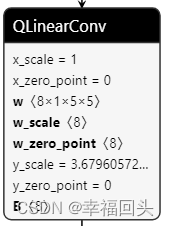
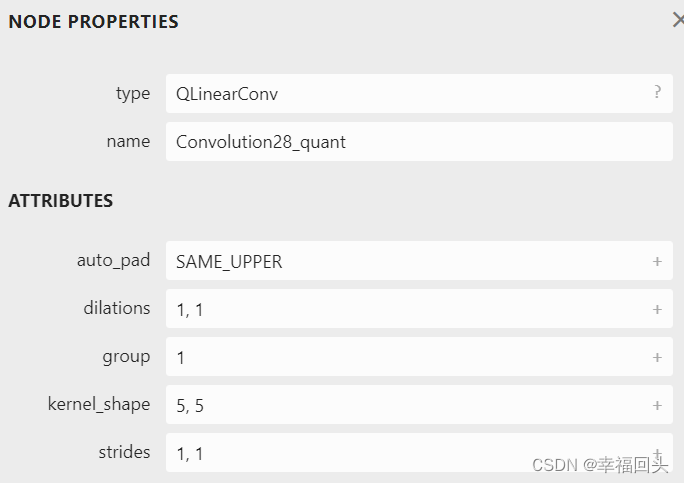
图1 图2
图1为模型结构中的单个算子,图二是该算子的Node和Attribute的两个配置,然后一个算子有许多的Input:x、x_scale、x_zero_point、w、w_scale、w_zero_point、y_scale、y_zero_point、B,各个参数的含义如下:
x: 输入数据的张量,即送入卷积需要计算的数据,[N x C x H x W](INT8)
x_scale: 输入x的比例因子,即x*x_scale(Float32)
x_zero_point: 输入x量化后的零点信息(UINT8)
w: 量化之后的权重(INT8)
w_scale: 权重w的比例因子(Float32)
w_zero_point: 权重w量化后的零点信息(UINT8)
y_scale: 输出y的比例因子(Float32)
y_zero_point: 输出y量化后的零点信息(UINT8)
B: 量化卷积量化后的偏置(INT32)
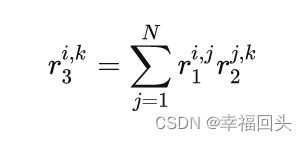
假设 S1、Z1 是r1矩阵对应的 scale 和 zero point, S2 、 Z2 、 S3 、 Z3 同理,那么上式可以推出:

可得出:

可使用Python进行算法上的验证,只知道原理总体来说还是不太好理解(对我本渣的我),因此我写了两份代码进行了算法上的比较。
首先写一份float的正常版本的卷积运算,代码如下:
将输入x设定为尺寸为5x5的矩阵,数值为100,float32类型
# -*- coding: utf-8 -*-
# @Time : 2022-08-03 15:35
# @Author : ZhangTong
# @Email : 1091574181@qq.com
# @File : conv_test_float.py
import numpy as np
kernel = np.array([
[-0.008905669674277306, -0.23690743744373322, -0.5088216662406921, -0.06456177681684494, 0.14181184768676758],
[-0.5919761657714844, -0.4752853810787201, -0.049348145723342896, 0.7682155966758728, 0.26346519589424133],
[-0.4917634427547455, 0.05561765283346176, 1.0189645290374756, 0.5547041893005371, -0.4416643977165222],
[-0.15953698754310608, 0.5575414896011353, 0.5920912623405457, -0.2947413921356201, -0.6131798028945923],
[0.03849884867668152, 0.22601930797100067, -0.21855629980564117, -0.47719430923461914, -0.2917049527168274]],
dtype=np.float32).reshape([5, 5])
x = np.ones([5, 5], dtype=np.float32)*100
y = np.zeros([5, 5], dtype=np.float32)
y[2:, 1:] = x[2:, 1:] # set padding
c = sum(sum(y*kernel))
print(c)输出结果
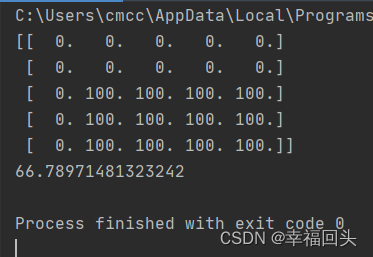
其次写一份INT8量化后的版本,python代码如下:
# -*- coding: utf-8 -*-
# @Time : 2022-08-03 14:42
# @Author : ZhangTong
# @Email : 1091574181@qq.com
# @File : conv_test.py
import numpy as np
kernel = np.array([[-1, -30, -63, -8, 18],
[-74, -59, -6, 96, 33],
[-61, 7, 127, 69, -55],
[-20, 69, 74, -37, -76],
[5, 28, -27, -59, -36]], dtype=np.int32).reshape([5, 5])
x = np.ones([5, 5], dtype=np.int32)*100
y = np.zeros([5, 5], dtype=np.int32)
y[2:, 1:] = x[2:, 1:] # Pad
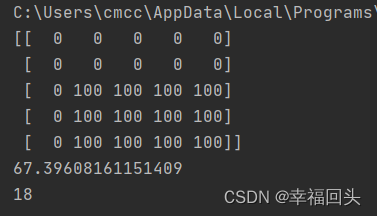
print(y)
x_scale = 1
w_scale = 0.008023343048989773
x_zero_point = 0
w_zero_point = 0
y_scale = 3.679605722427368
B = -20
c = sum(sum(y*kernel))
print(c*w_scale)
c = np.array(y*kernel, dtype=np.int32)
c = sum(sum(np.array(y*kernel, dtype=np.int32))) + B
print(int(c*w_scale/y_scale))
输出结果:
从两份代码中可以看出,float32的代码中的kernel数值就是INT8中的kernel*w_scale计算而来的(因为w_zero_point=0),原本计算公式为
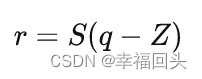
可以看到 INT8量化后的计算结果分别为:66.789、67.396,量化之后的计算结果在float32的差距仅为0.607,差距不到1,因此可以看出INT8量化之后会有一些损失,但差距不算太大,可以接受。
根据输出的比例因子y_scale,获取到量化后的结果为18。
至此,线性量化INT8的卷积计算讲完了,欢迎评论区讨论。















 299
299











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









