






1. 文章信息
文章题为“Multi-Task Learning Using Uncertainty to Weigh Losses for Scene Geometry and Semantics”,该文于2018年发表至Conference on Computer Vision and Pattern Recognition (CVPR)会议上。文章提出一种利用不确定性衡量计算机视觉任务中场景几何和语义的损失的方法。
2. 摘要
许多深度学习应用都受益于具有多回归和分类目标的多任务学习。本文观察到这种系统的性能强烈依赖于每个任务损失之间的相对权重。然而,手动调整权重是一个困难且昂贵的过程,导致多任务学习在实践中难以实现。文章提出了一种调节多任务学习损失的方法,该方法通过考虑每个任务的均方差不确定性来权衡多个损失函数。这种方法允许在分类任务和回归任务中,同时学习不同单位或尺度的各种数量。进一步,文章展示了所提出模型学习单目(monocular)输入图像的逐像素(per-pixel)深度回归、语义和实例分割。实验结果表明,文章所提出的模型可以学习多任务权重,并且优于每个任务单独训练的单独模型。
文章的主要贡献总结如下:
1、利用均方差任务不确定性,同时学习不同数量和单位的各种分类和回归损失的一种新颖的原则性多任务损失;
2、提出了能够实现语义分割、实例分割和深度回归的统一架构;
3、文章展示了损失加权在多任务深度学习中的重要性,以及与等效的单独训练模型相比如何获得更好的性能。
3. 具有均方差不确定性的多任务学习
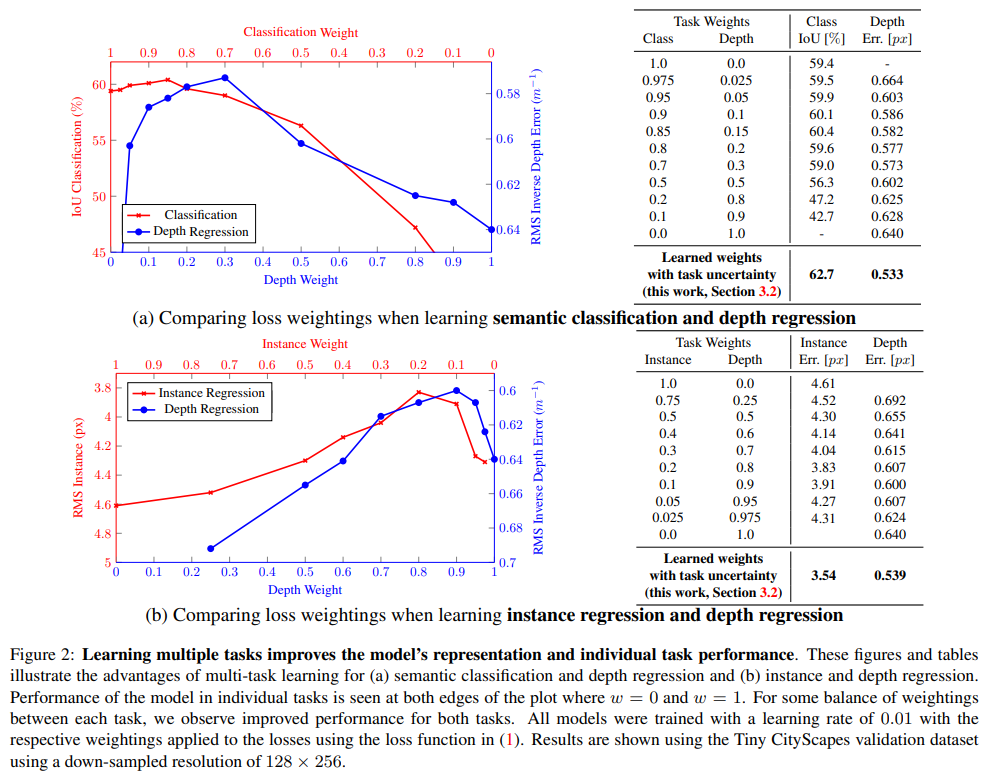
通常而言,多任务学习指针对多个目标进行优化的模型,许多现有的深度学习模型中讲不同任务的损失进行加权求和,从而实现多目标优化。然而,该方法存在许多问题。通常而言,模型性能与权重选择密切相关,且十分敏感,如下图所示。下图展示了一个预测逐像素深度和语义分类的模型和一个预测逐像素深度和语义分割的模型。可以看到,对于不同的权重参数,不同任务的模型性能截然不同。因此,学习不同任务的最优权重是十分重要的。
文章利用概率建模学习不同任务的权重。首先,在贝叶斯建模中主要有两种不确定性:认知不确定性(Epistemic uncertainty)和偶然不确定性(Aleatoric uncertainty)。其中,前者是由于缺乏数据而导致,而后者是由于人们无法解释信息的不确定性。进一步,偶然不确定性又可以划分为:数据相关(或异方差)不确定性和任务相关(或均方差)不确定性。其中,任务相关不确定性是文章的研究重点,该类不确定性不依赖于输入数据,而是对于所有输入数据保持恒定,而对于不同任务不同的偶然误差。
多任务似然估计:
文章通过最大化高斯似然的均方差不确定性,推导获得多任务损失函数。具体而言,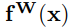 表示神经网络的输出,W为权重,x为输入。文章定义以下概率模型,其中均值由模型的输出给定,对于回归任务而言,文章将似然定义为高斯分布,如下所述。
表示神经网络的输出,W为权重,x为输入。文章定义以下概率模型,其中均值由模型的输出给定,对于回归任务而言,文章将似然定义为高斯分布,如下所述。
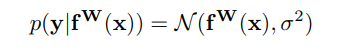
其中,方差为观测值的噪声规模。对于分类任务而言,其似然表达式如下,
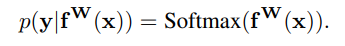
对于多个模型的输出,在给定充足的数据条件下,文章将似然定义为输出的因式分解形式,因此多任务似然如下式所示。其中,为不同任务的输出。
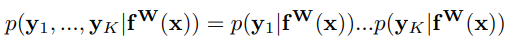
文章利用最大似然估计理论,将上述似然取对数,并最大化。此处以回归任务为例,其对数似然表示式如下。
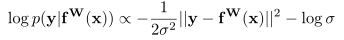
其中,方差表示观测值的模型噪声观测参数,该参数表明模型的输出中噪声的程度。进一步,对模型参数和噪声参数的对数似然取最大化。假设模型输出由两部分组成,即y1和y2,其高斯分布如下式所述。
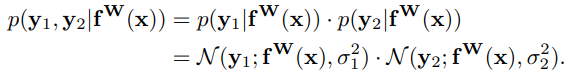
对上式取对数并取负值,从而得到最小化目标,即可得到多输出模型的损失函数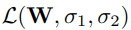 。
。
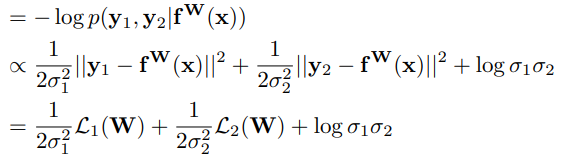
其中,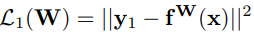 表示第一项输出的损失,L2同理。
表示第一项输出的损失,L2同理。
文章将上述关于σ1和σ2的最小化目标解释为根据数据自适应地学习两个不同任务的相对权重。σ1对应y1的噪声参数,随着σ1的增加,其对应的损失L1也随之下降、另一方面,随着噪声参数的降低,其对应的权重也随之增加。最后一项为正则项,防止噪声增加过多。对于分类任务而言,其原理相似,但推导过程略有差异,此处不再赘述。
4. 模型
为了理解图像中的语义信息和几何信息,文章提出一种能够在像素级别学习回归和分类输出的框架。该框架采用了编码器-解码器的结构,并构建深度卷积网络。文章所提出的模型由许多产生共享表示的卷积编码器组成,以及相应数量的特定任务的卷积解码器。
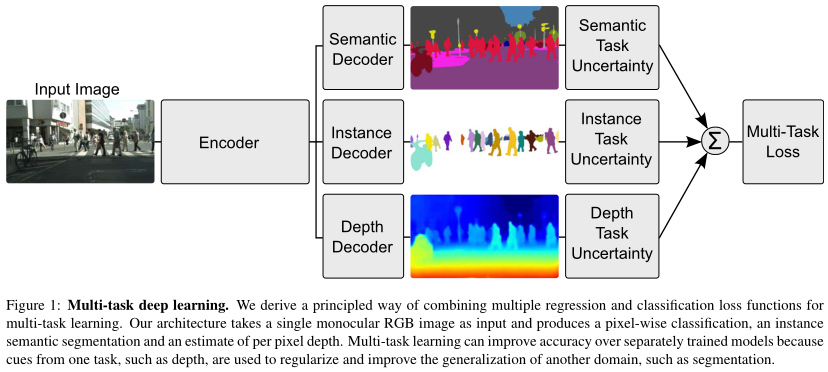
编码器用于学习数据的深度映射,以产生上下文信息。文章基于DeepLabV3构建编码器,采用ResNet101。解码器则是由二维卷积神经网络构成。
5. 实验
文章在CityScapes数据集上进行模型验证。该数据集是一个用于道路场景理解的大型数据集,包括20个类别的实力和语义分割,同时还提供了深度图像。实验结果如下表所示。
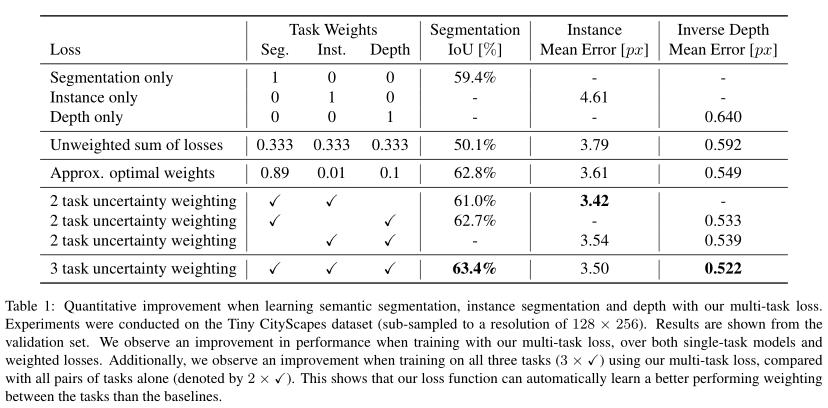
表中前三行展示了只考虑特定任务时,不同任务的模型性能。第四行则展示了不添加权重时,通过多任务学习时的模型性能。可以看到采用多任务学习,但不采用自适应权重时,多任务学习能够一定程度上提升模型性能,降低模型的预测误差,但由于权重分配不合理,导致在某些任务上预测精度下降。表中后四行展示了采用文章所提出的多任务学习损失函数,可以看到模型的性能得到了显著的提高。结果表明,文章所提出损失函数的有效性。同时表明,在进行多任务学习时,对不同任务的权重进行合理分配能够有效提升模型性能。
此外,文章还将所提出框架与其他模型进行比对,以证明其有效性以及多任务学习的优势,结果如下表所示。
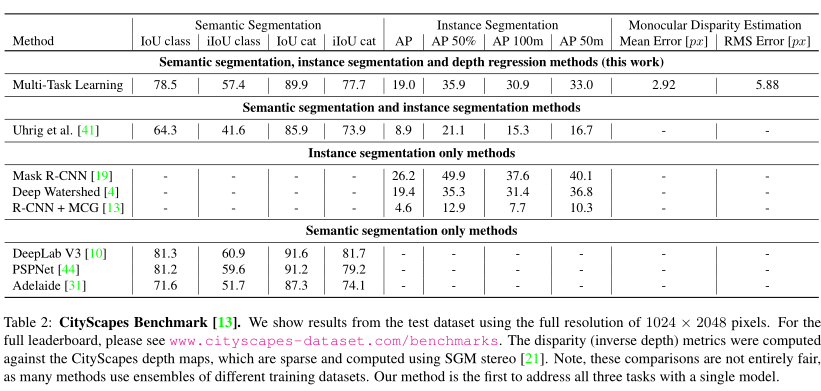
6. 结论
文章结果表明,正确的加权损失项对于多任务学习问题至关重要。文章证明了通过均方差(任务)不确定性对不同任务的损失进行加权是一种有效的方法。此外,文章推导了一个原则性的损失函数,它可以从数据中自动学习相对权重,并且对权重初始化具有鲁棒性。结果表明,通过多任务学习,构建统一的语义分割、实例分割和逐像素深度回归架构可以提高场景理解任务的性能。
Attention
欢迎关注微信公众号《当交通遇上机器学习》!如果你和我一样是轨道交通、道路交通、城市规划相关领域的,也可以加微信:Dr_JinleiZhang,备注“进群”,加入交通大数据交流群!希望我们共同进步!
















 7173
7173











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











