






 本文开发了KXGBoost模型预测扩建中地铁的乘客出行需求。以深圳地铁为例,利用在线数据,经特征选择、K均值聚类和XGBoost模型训练。实验表明,该模型预测准确度高,优于其他对比模型,但部分站点因特殊情况存在预测偏差。
本文开发了KXGBoost模型预测扩建中地铁的乘客出行需求。以深圳地铁为例,利用在线数据,经特征选择、K均值聚类和XGBoost模型训练。实验表明,该模型预测准确度高,优于其他对比模型,但部分站点因特殊情况存在预测偏差。
导读
论文题目《A Two-Step Model for Predicting Travel Demand in Expanding Subways》。该论文于2023年发表于《IEEE TRANSACTIONS ON INTELLIGENT TRANSPORTATION SYSTEMS》,文章开发了一个两步模型来预测扩建中地铁的乘客出行需求。
摘要
在许多城市,地铁正在扩建,新的或延伸的线路正在建设并投入运营。对地铁未来出行需求的预测,特别是在计划扩建的情况下,具有重要意义,因为这样的信息对新线路规划和新网络运营至关重要。在这项研究中,本文从潜在的影响因素中确定了影响乘客出行需求的决定性特征,并开发了一个两步模型,用于预测扩建中地铁的乘客出行需求。所提出的模型在一条实际的地铁线路上进行了测试,其预测准确度较基准模型更高。
介绍
地铁以高容量、高速度和高准时性为特点。开发高效可靠的地铁被视为缓解大城市普遍交通拥堵的最有效方式之一。大多数发达国家的大城市已建立起良好连接的地铁网络,而对于许多发展中国家的大城市来说,地铁网络仍处于初级或扩建阶段。地铁网络的扩建通过建设新的地铁线路或延伸现有地铁线路来实现。在网络扩建的过程中,乘客的出行需求也会发生相当大的变化。由于网络可达性的增强,更多的乘客将使用地铁,乘客可以通过扩展的地铁网络抵达更多地区。因此,对计划中地铁扩建的乘客出行需求进行预测是一个重要问题,因为出行需求信息对规划新地铁线路或线路延伸以及部署新的网络运营计划至关重要。
在扩建中的地铁网络中预测未来的乘客出行需求尤为具有挑战性。因为地铁网络结构将随着新线路和/或线路延伸而发生变化,而且最重要的是,对于新线路或延伸线,没有可用的历史出行需求信息。因此,在预测扩建地铁的出行需求时,通常使用社会经济数据、交通环境数据和出行调查数据作为模型输入,并经常采用四步建模方法。
在本研究中,本文以扩建中的深圳地铁为案例研究。本文开发了一个两步模型(K均值和XGBoost组合机器学习模型,称为KXGBoost),仅使用在线可用数据来可靠地预测扩建中地铁网络未来的乘客出行需求。使用的在线数据包括人口数据(例如,人口分布)、POI数据(例如,车站周围的购物服务数量)、交通基础设施数据(例如,车站的出口数量)和交通服务数据(例如,列车发车时间间隔)。在提出的预测模型中,首先使用递归特征消除(RFE)算法确定乘客出行需求的决定性特征。基于确定的特征,使用K均值算法将13,806个OD对(118个车站乘以117个车站)分为多簇,并通过平均轮廓系数确定最优簇数。接下来,为每个OD对的簇训练XGBoost预测模型,并获得优化的参数值集。最后,在预测未来的乘客出行需求时,首先将每个OD对聚类到适当的簇中,然后使用为OD对所属簇训练的XGBoost模型预测OD对的乘客出行需求。
在收集了一段长时间的智能卡数据,其中新的地铁线路(11号线)投入运营。因此,获得的智能卡数据记录了网络结构变化后乘客出行需求的变化,这些智能卡数据用于验证开发的出行需求预测模型。本研究提出的模型可以轻松扩展到其他城市,因为大多数城市都可以轻松获取所有输入数据。所提出的模型还代表了一种基于昂贵和耗时的出行调查的四步方法的时间和成本效益的替代方法。
数据
A. 乘客智能卡数据
本文以深圳地铁扩建为案例研究。截至2016年8月,深圳地铁有6条线路(即1号线、2号线、3号线、4号线、5号线和11号线)和132个车站(图1a)。
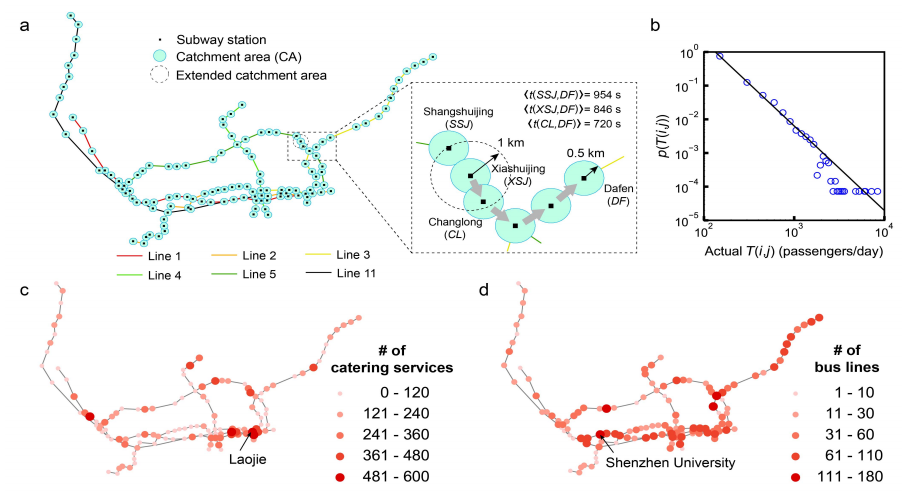
图1 (a)深圳地铁网络、集水区(CA)和扩展集水区(ECA)说明。11号线于2016年6月投入运营,研究地铁在6个工作日运行上午至12点a.m. (b)原地铁网络中OD对的出行需求分布(c) (d)地铁站CA内餐饮服务数量和连接地铁站的公交线路数量的空间分布
表I显示了这6条地铁线路的一般属性,包括车站数量、线路投入运营日期、线路最近扩建日期、线路长度和线路运行速度。智能卡数据由深圳交通运输管理局提供,记录了深圳市300多万地铁乘客的出行。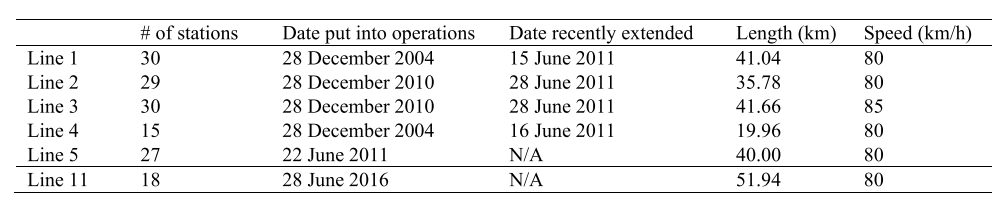
表1 关于深圳地铁线路的一般情况
在智能卡数据中,每次乘客进入或离开车站时都记录了时间、卡ID、站点ID、闸机ID和交易类型(进站或出站)。本文定义乘客从i到j的出行需求,当乘客进入i站并离开j站时,即完成一次出行。可以使用智能卡数据估算任何特定时间窗口内的乘客出行需求。首先,首先过滤掉缺少站点ID和闸机ID的记录(总共40条)。其次,过滤掉从同一站点开始并结束的出行(总共567,983条)。第三,过滤掉进站或出站时间超出运营时间的出行(总共587条)和持续时间超过3小时的出行(总共17,597条)。最后,使用86,361,917条地铁乘客出行记录进行进一步分析。在本研究中,智能卡数据用于训练和验证出行需求预测模型。
本文定义从站点i到站点j的乘客出行需求T(i, j)为平均每日从i到j的乘客出行次数。乘客出行需求可以很好地近似为幂律分布: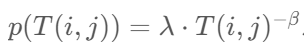 ,其中λ = 2.20×10^5,β = 2.51。具体来说,约80%的OD对的出行需求小于200名乘客/天,而1.6%的OD对的出行需求超过1,000名乘客/天。此外,站点的流入被定义为每天进入该站的乘客人数的平均值
,其中λ = 2.20×10^5,β = 2.51。具体来说,约80%的OD对的出行需求小于200名乘客/天,而1.6%的OD对的出行需求超过1,000名乘客/天。此外,站点的流入被定义为每天进入该站的乘客人数的平均值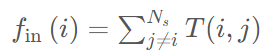 ,流出被定义为每天离开该站的乘客人数的平均值
,流出被定义为每天离开该站的乘客人数的平均值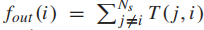 ,其中Ns是车站的总数。
,其中Ns是车站的总数。
B. 可能影响乘客出行需求的因素
地铁乘客的出行需求受到各种因素的影响,本研究考虑了一组站点级和OD级的特征,用于开发扩建中地铁的出行需求预测模型(表II)。
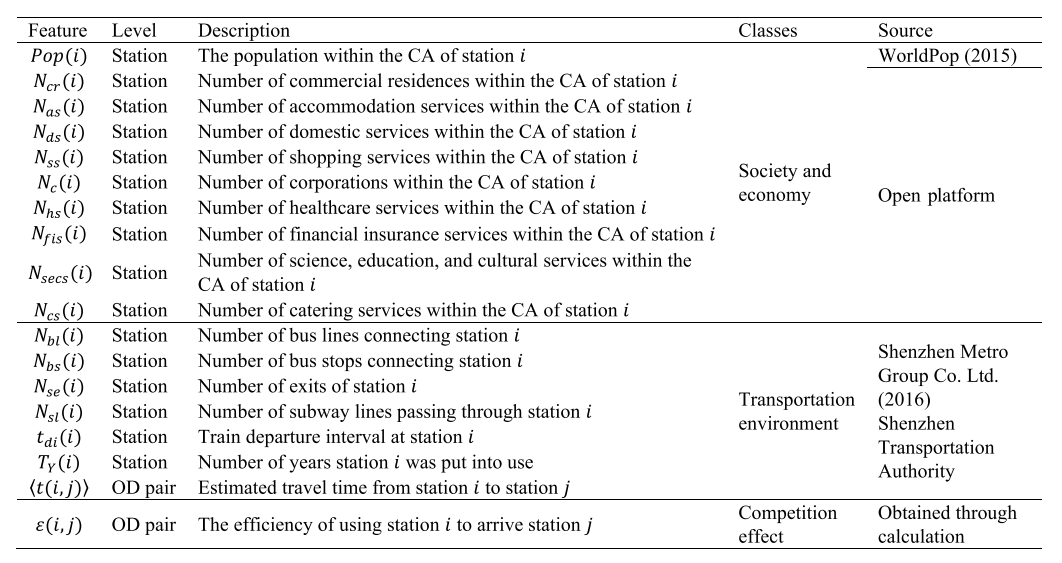
表2 可能影响旅客旅行需求的因素
与大多数依赖耗时和昂贵的出行调查的先前模型不同,所选特征的数据对于大多数城市来说是有效的。
1) 社会经济特征:Pop(i)、Ncr(i)、Nas(i)、Nds(i)、Nss(i)、Nc(i)、Nhs(i)、Nfis(i)、Nsecs(i)、Ncs(i)。人口分布Pop(i)数据来自WorldPop项目。这个人口数据集是在2015年7月发布的,其中对每个面积约为0.1 × 0.1 km^2的高分辨率网格进行了人口估算。在一个站点CA内的每个网格的人口被汇总以估算CA内的人口。本文做出一个合理的假设,即从2015年到2016年,深圳的人口分布相对稳定。POI(兴趣点)指的是地图上的特定点位置。POI可以表示房屋、学校、公交站或购物中心。每个POI都用名称、坐标、类别等信息进行记录。POI信息可以反映城市的土地利用模式,不同的POI具有不同的乘客流吸引特性。车站CA内的POI数量用于量化车站服务区的社会经济特征。
2) 交通环境特征:Nbl(i)、Nbs(i)、Nse(i)、Nsl(i)、tdi(i)、TY(i)、t(i, j)。公交是重要的公共交通方式。相关的公交特征是连接到地铁站的公交线路数量Nbl和连接到地铁站的公交站数量Nbs。这两个特征的值可以反映特定地点的公共交通需求。这两个公交特征的数据通常可以从公共交通机构获取。在本研究中,Nbl和Nbs的数据来自深圳地铁集团有限公司的官方网站。当没有在地铁的官方网站上发布数据时,可以使用在线地图(例如Amap)识别连接到地铁站的公交线路和公交站。深圳地铁站的Nbl范围从1到176,Nbs范围从1到12。
与地铁相关的一些因素也很重要。相关特征包括站点出口数量Nse(i)、通过车站的线路数量Nsl(i)、站点的列车发车间隔tdi(i)、站点投入运营的年数TY(i)以及从站点i到站点j的估算行驶时间t(i, j)。首先,站点出口数量Nse(i)是乘客流量的良好指标。通常,大型车站和中心城区的换乘站比郊区或居住区的站点有更多的出口。其次,换乘站通常预计乘客流量更大。因此,本文使用通过车站的线路数量Nsl(i)作为候选特征。第三,站点的平均列车发车间隔tdi(i)决定了每单位时间内一条线路可以运输的最大乘客数。第四,观察到新地铁站的乘客流量随时间增长[32]。因此,考虑了站点投入运营的年数TY(i)。最后,还包括从站点i到站点j的估算行驶时间t(i, j)。上述所有地铁特征的数据可在深圳地铁集团有限公司的官方网站和维基百科页面上获得。
3) 竞争效应特征:ε(i, j)。地铁站在彼此靠近时可能会竞争乘客。本文将一个站点的相邻站点定义为s(i) ∈ ECA(i),其中ECA(i)是站点i的扩展服务区。研究中的深圳地铁站的相邻站点数量从1到6不等,其中数字为1表示站点i是其自身ECA内的唯一站点(即没有相邻站点与之竞争)。接下来,本文使用从站点i到站点j的旅行效率ε(i, j)来描述竞争效应。旅行效率ε(i, j)定义如下:
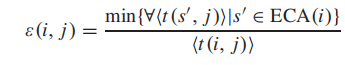
其中t(i, j)表示从i到j的估算行驶时间,s(i)表示ECA(i)内的相邻站点,t(s(i), j)表示从s(i)到j的估算行驶时间。效率ε(i, j)的值范围从0到1,ε(i, j) = 1表示使用i是到达j的最有效方式,与使用i的相邻站点相比。以XSJ到DF为例(图1a),XSJ的ECA内有两个相邻站点,即SSJ和CL。根据(1),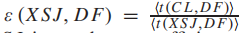 = 0.85,表示使用XSJ不是前往DF的最有效方式。
= 0.85,表示使用XSJ不是前往DF的最有效方式。
方法论
A. 预测模型框架
用于预测扩建地铁乘客出行需求的模型主要包括以下五个模块(请参见图2的流程图):
1) 旅行时间和旅行效率的估算:在新线路投入运营之前,扩建地铁站之间的实际旅行时间是未知的。因此,本文使用Dijkstra最短路径算法(详见B节)估算每对OD之间的旅行时间。利用估算的旅行时间,本文计算每个OD对的旅行效率ε(i, j)。
2) 数据预处理:为确保每个特征的值在相同的尺度上,本文使用z-score方法对每个特征进行标准化,均值为0,方差为1。不同OD对的乘客流量差异很大,这可能影响机器学习模型的性能。因此,在模型训练过程中,本文使用对数乘客流量而不是实际乘客流量。
3) 特征选择:为避免模型过拟合,本文使用递归特征消除(RFE)算法[34]结合交叉验证来识别乘客出行需求的决定性特征。这里,使用sklearn库的RFECV来识别特征。
4) K均值聚类:使用与预测对象相似的数据样本训练机器学习模型可能实现更好的预测性能。在本研究中,本文使用K均值算法对OD对进行聚类,并分别为每个OD对的聚类训练乘客出行需求预测模型。采用平均轮廓系数确定优化的簇数。
5) XGBoost模型:为每个OD对的簇训练一个XGBoost模型。在预测未来乘客出行需求时,首先将每个OD对聚类到适当的簇中,然后使用为该簇训练的XGBoost模型预测OD对的乘客出行需求。最后,使用指数函数将预测的对数乘客流量转换为正常尺度。
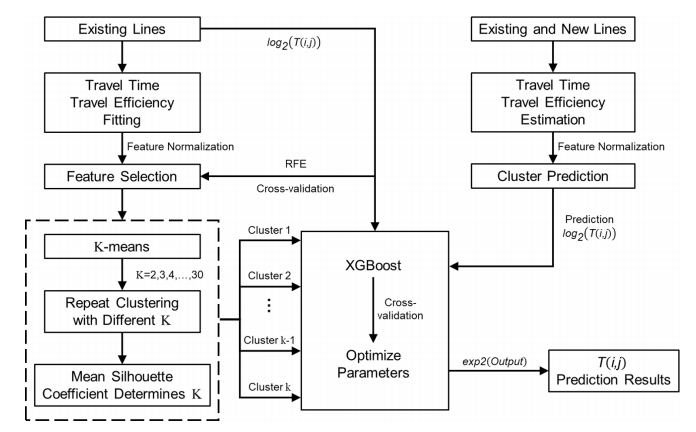
图2 旅客出行需求预测模型的流程图
B. 旅行时间和旅行效率的估算
为了估算每对OD之间的旅行时间,本文将每个地铁站视为一个节点,每个地铁区段视为一条链路。为了考虑换乘时间,本文将每个换乘站拆分为几个虚拟节点,这些节点属于通过换乘站的不同线路。换乘站的每对虚拟节点由一条虚拟链路连接,换乘时间是虚拟链路的权重。换乘站的n个虚拟节点的每对之间的换乘时间设置为相同的值。Si等人[37]提出换乘需要额外的努力。因此,感知换乘时间通过将预期换乘时间乘以放大因子α来估算:
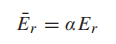
其中 是站点r的感知换乘时间,
是站点r的感知换乘时间,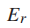 是站点r的官方估算换乘时间,可以从深圳地铁集团有限公司的官方网站获得。因此,使用以下公式计算感知旅行时间:
是站点r的官方估算换乘时间,可以从深圳地铁集团有限公司的官方网站获得。因此,使用以下公式计算感知旅行时间:
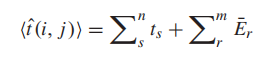
其中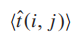 是基于从站点i到站点j的路径的感知旅行时间,ts是从深圳地铁集团有限公司的官方网站获得的地铁区段s的官方估算旅行时间。本文假设乘客选择具有最短感知旅行时间的路径。因此,本文将每个乘客出行分配到地铁网络中,获取每次出行的路线和估算的旅行时间:
是基于从站点i到站点j的路径的感知旅行时间,ts是从深圳地铁集团有限公司的官方网站获得的地铁区段s的官方估算旅行时间。本文假设乘客选择具有最短感知旅行时间的路径。因此,本文将每个乘客出行分配到地铁网络中,获取每次出行的路线和估算的旅行时间:
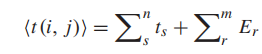
其中![]() 是从站点i到站点j的估算旅行时间,ts是地铁区段s的官方估算旅行时间,Er是换乘站r的官方估算换乘时间。
是从站点i到站点j的估算旅行时间,ts是地铁区段s的官方估算旅行时间,Er是换乘站r的官方估算换乘时间。
本文使用遍历方法确定α的合适值。为了实现这一点,本文将估算的旅行时间与从智能卡数据中获取的平均实际旅行时间进行比较(仅使用2016年4月工作日收集的数据),并选择最小均方根误差(RMSE)的α值。使用选定的α值,本文使用(4)和(1)估算扩建地铁中每对OD的旅行时间和旅行效率。同时,本文为原始地铁中的每对OD估算旅行时间和旅行效率。旅行时间特征和旅行效率特征用于训练乘客出行需求预测模型。
C. K均值聚类算法
K均值算法是一种广泛使用的聚类方法。在这里,使用识别的决定性特征生成特征空间,每个OD对的特征向量是一个数据样本。
根据特征空间中的距离对OD对进行聚类。OD对的聚类主要包括以下步骤:
步骤1:从OD对中随机选择K个样本{μ1, μ2,...,μk}作为初始聚类中心。每个聚类表示为Ci,其中i ∈ {1, 2,..., k}。
步骤2:计算数据样本与每个聚类中心之间的欧几里德距离,并将数据样本分配给具有最小欧几里德距离的聚类。
步骤3:更新聚类中心μi = |C1i| x∈Ci x,其中|Ci|是分配给第i个聚类的OD对数量。接下来,重复步骤2和步骤3,直到达到最大迭代次数或满足收敛条件为止。
步骤4:使用不同的K值重复步骤1-3。使用平均轮廓系数确定K的优化值。在这里,测试K值从2到30(即K = 2, 3, 4,..., 30)。
D. XGBoost模型
XGBoost模型是基于树集成的机器学习模型,具有快速速度和良好的鲁棒性。XGBoost模型的基本思想是将准确度较低的多个树模型合并为一个准确度较高的集成模型,通常用于预测任务。本文将K均值和XGBoost结合起来,开发了一个用于扩建地铁乘客出行需求预测的模型。本文利用K均值聚类为每个OD对训练XGBoost模型。此外,使用五折交叉验证优化模型参数,包括学习率、树的数量和最大树深度。测量预测乘客流量的均方根误差(RMSE),选择平均五折交叉验证的最小RMSE的参数作为优化的参数集。在预测乘客出行需求时,首先将每个OD对聚类到适当的簇中,然后使用为该簇训练的XGBoost模型预测OD对的乘客出行需求。
实验
A. 实验描述
本文以深圳地铁为案例研究。深圳地铁11号线于2016年6月28日投入运营。乘客出行需求预测模型的开发和应用如下:
首先,使用2016年4月工作日的乘客出行时间数据(从智能卡数据推断)来确定换乘放大因子α的值。为了确保旅行时间数据的可靠性,本文仅使用有足够乘客出行数量的OD对。因此,本文使用以下公式估算4月份所需的最小乘客出行次数nmin:
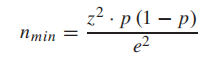
其中z是所需置信水平的选择关键值,p是人口中属性的估计比例或人口的最大变异性,e是所需的精度级别或误差边际。在这里,本文设置z = 1.96(95%置信水平),p = 50%,e = 5%,得到nmin = 384.16。这意味着所选OD对的乘客流量应至少达到384.16名乘客。本文找到了符合条件的OD对,代表了所有OD对的74%,只有符合条件的OD对用于确定放大因子α。随着放大因子α从0.2增加到5,容忍度为0.2,本文发现估算旅行时间的均方根误差(RMSE)在α等于3.6时达到最小值(392.5)(图3a)。
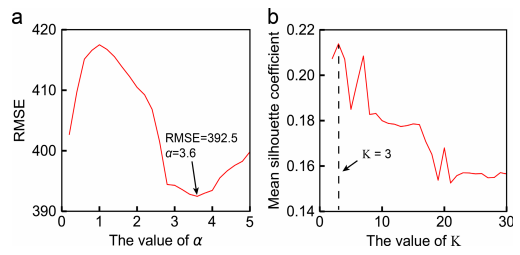
图3 (a)不同放大因子α下的估计旅行时间的RMSE (b)不同数量簇K的平均轮廓系数
因此,将换乘放大因子α设置为3.6,意味着感知换乘时间约为实际换乘时间的3-4倍。然后,本文估算原地铁和扩建地铁中每对OD的旅行时间和旅行效率。
其次,使用z-score方法对每个特征进行标准化,将原地铁网络中每对OD的乘客流量(在11号线投入运营之前)转换为其对数值,使用log2函数。对于没有乘客流量的OD对,无法应用对数变换。为解决这个问题,本文将这些OD对的对数乘客流量设置为-10,表示这些OD对的乘客流量非常小,接近零。
第三,RFE算法中使用多元线性回归模型识别决定性特征。识别了六个决定性特征,并使用五折交叉验证确定了特征的重要性。特征的重要性定义为当该特征未用于预测时均方根误差(RMSE)的增加。按重要性排序,六个决定性特征分别是估算旅行时间t(i, j)、起始站点CA内餐饮服务数量Ncs(i)、目的站点CA内餐饮服务数量Ncs(j)、目的站点连接的公交线数量Nbl(j)、起始站点连接的公交线数量Nbl(i)以及旅行效率ε(i, j)。不足为奇的是,t(i, j)对乘客出行需求有重要影响,因为旅行时间始终是影响乘客路径选择行为的最重要因素之一,而且在许多出行需求预测模型中,旅行时间也作为核心参数。有趣的是,地铁站周围的餐饮服务数量对乘客流量有很大影响。这可能表明餐饮行业可能促进乘客流动性,引发更大的乘客出行需求。例如,老街站周围有各种餐饮服务(图1c),其入站流fin和出站流fout超过37,000名乘客/天。另一个有趣的发现是,地铁线路和公交线路之间的连接,在Nbl(i)和Nbl(j)中体现,也起着重要作用。这意味着在公交乘客较多的地方,地铁乘客的出行需求也较大。例如,深圳大学站连接着许多公交线路(图1d),其入站流fin和出站流fout超过42,000名乘客/天。最后,ε(i, j)对乘客出行需求的影响较其他五个决定性特征较小。
第四,使用K均值算法对OD对进行聚类。当K的值为3时,平均轮廓系数达到最大值,表明最优化的聚类数为3(图3b)。第一簇包含4,691对OD,第二簇包含942对OD,第三簇包含8,173对OD(共计13,806对OD)。图4显示了每个OD对的六个决定性特征的分布。
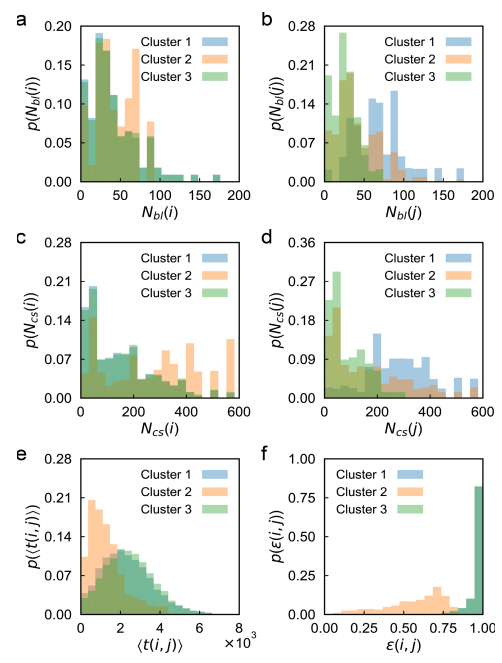
图4 六个决定性特征的统计性质
簇2中大多数OD对的起始站点和目的地之间的距离较短(图4e)。此外,这些OD对的起始站点主要分布在市中心地区,附近有许多公交线路和餐饮服务(图4a和c)。相比之下,簇1和簇3中相当一部分OD对的起始站点和目的地之间距离较远(图4e),并且这些OD对的起始站点通常位于外围地区(图4a和c)。然而,与簇3中的OD对相比,簇1中的OD对的Nbl(j)和Ncs(j)较大(图4b和d)。这表明簇1的OD对的目的地主要位于市中心地区,而簇3的OD对的目的地主要位于外围地区。因此,Nbl(i)、Ncs(i)、t(i, j)和ε(i, j)可以作为簇2 OD对的代表性特征,而Nbl(j)和Ncs(j)可以作为簇1和簇3 OD对的代表性特征。同时,使用五折交叉验证确定XGBoost模型的学习率、树的数量和最大树深度的最优化值。本文将学习率的范围设置为0.01、0.02、0.03、0.06、0.1、0.2和0.3,树的数量的范围设置为100、125、150、175、200、225、250、275和300,最大树深度的范围设置为2、3、4、5、6、7和8。测试这些参数值的所有可能组合,然后使用优化的参数值为每个OD对的聚类训练XGBoost模型。
最后,确定扩建地铁中每个OD对的聚类(11号线投入运营),并将为该聚类训练的XGBoost模型应用于预测该OD对的乘客出行需求。其中,5,411对OD属于第一簇,1,071对OD属于第二簇,10,810对OD属于第三簇(共计17,292对OD)。使用exp2函数将预测的对数乘客流转换为其正常刻度。
本文使用三个误差指标来评估开发模型的预测精度:平均绝对误差(MAE)、均方根误差(RMSE)和平均绝对百分比误差(MAPE)。
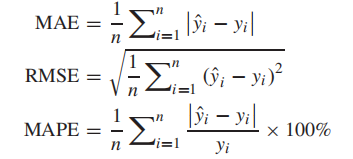
其中y = {y1, y2,..., yi,..., yn}表示扩建地铁(11号线已投入运营)中每对OD的实际每日平均乘客出行次数T(i, j), 表示每对OD的预测平均每日乘客出行次数
表示每对OD的预测平均每日乘客出行次数![]() ,n是扩建地铁中的OD对数。
,n是扩建地铁中的OD对数。
B. 结果分析
本文将扩建地铁中每对OD对的预测乘客流量(11号线已投入运营)与实际乘客流量值进行比较(图5)。
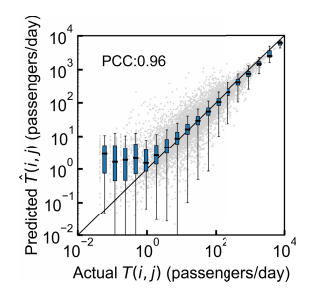
图5 每个OD对的预测平均日客流与相应的实际值进行比较
结果表明,使用开发的模型可以相当高的准确性预测乘客出行需求(图5,表III)。预测的乘客流量与其实际值高度相关(皮尔逊相关系数PCC = 0.96)。此外,地铁站i的入站流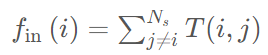 和出站流
和出站流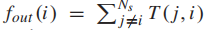 可以从预测的出行需求
可以从预测的出行需求![]() (即从站点i到站点j的平均每日乘客出行次数)中派生出来。本文发现使用开发的模型可以很好地预测站点的入站流和出站流(图6)。
(即从站点i到站点j的平均每日乘客出行次数)中派生出来。本文发现使用开发的模型可以很好地预测站点的入站流和出站流(图6)。
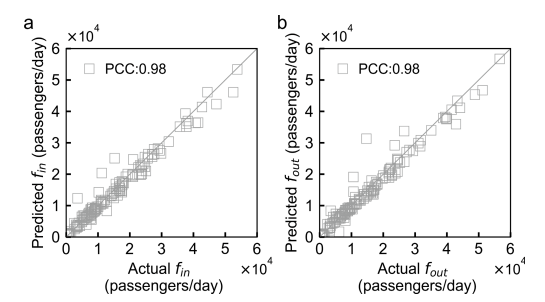
图6 地铁站进出流量预测与相应实际值的比较
为了展示提出的预测模型的优势,本文使用了几个机器学习模型进行比较,包括极端梯度提升(XGBoost)、多层感知神经网络(NN)、K最近邻(KNN)和支持向量机(SVM)(表III)。
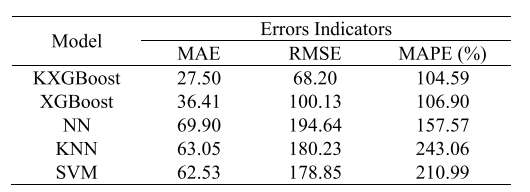
表3 不同模型的性能比较
本文使用在原始网络中收集的乘客流数据(11号线尚未投入运营)来训练比较模型。五折交叉验证用于确定每个模型参数的优化值。对于极端梯度提升(XGBoost),优化的参数值与提出的模型相同。对于多层感知神经网络(NN),隐藏层中节点的最佳数量通常在输入层大小和输出层大小之间,并且一个隐藏层足以解决大多数问题。因此,本文使用一个三层的多层感知神经网络(NN),其中隐藏层神经元的数量从1到6选择。对于K最近邻(KNN),最近邻样本数K可以从1、5、10、20和样本大小的平方根中选择。对于支持向量机(SVM),惩罚系数的范围是2^{-5}、2^{-4}、2^{-3},...,2^{12},gamma的范围是2^{-12}、2^{-11}、2^{-10},...,2^5。如表III所示,提出的预测模型(KXGBoost)在预测所研究扩建地铁的乘客出行需求方面表现最佳。
最后,表IV显示了每个OD对簇的预测精度。
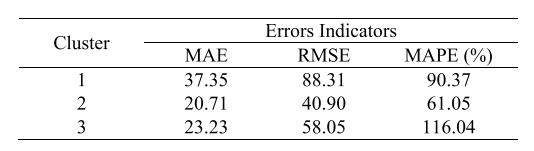
表4 KXGBOOST对每个od对集群的性能
尽管总体上可以准确预测本文研究中站点的乘客流,本文仍然观察到一些站点的入/出站乘客流被低估或高估。例如,11号线车公庙站的乘客流被低估。一个可能的原因是该站位于一个商业街附近,有很多游客光顾。一些站点的乘客流被高估,例如,11号线北机场站的实际乘客流小于预测的乘客流。一个可能的解释是深圳机场T4航站楼在2016年4月尚未投入运营,而提出的模型没有纳入这样的详细信息。在未来的研究中,纳入更多捕捉特定区域特殊移动特性和特殊事件中旅行需求随机变化的具体特征,可以进一步提高预测准确性。
Attention
欢迎关注微信公众号《当交通遇上机器学习》!如果你和我一样是轨道交通、道路交通、城市规划相关领域的,也可以加微信:Dr_JinleiZhang,备注“进群”,加入交通大数据交流群!希望我们共同进步!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











