







声明:我学习了b站:标注自己的语义分割数据集_哔哩哔哩_bilibili
并且复现了,记录了所思所得。
主要是说了:
做语义分割,数据集怎么用labelme标注成json文件,以及,json文件怎么转成mask
流程:
准备图片-用labelme标注-得到标注的json文件-把json文件转成mask文件
然后,先看看,单张图片,是怎么依次做到上面的事情的。
首先,知道一些基本的:
1、标注前:
工具:labelme
labelme软件配置
2、标注中
标注单张图像(现在做这个)
使用“分割一切”SAM视觉大模型辅助标注
标注多张图像
标注注意事项
3、标注后
划分训练集和测试集
讲labelme的json标注格式,转换为整数掩膜mask格式
下载西瓜语义分割样例数据集
下载labelme
下载labelme
https://github.com/labelmeai/labelme/releases?after=v3.22.1
注意:
文件-取消-同时保存图像(不然很大占用内存)
文件-勾选-自动保存
开始标注
labelme:编辑-创建多边形-开始描狗
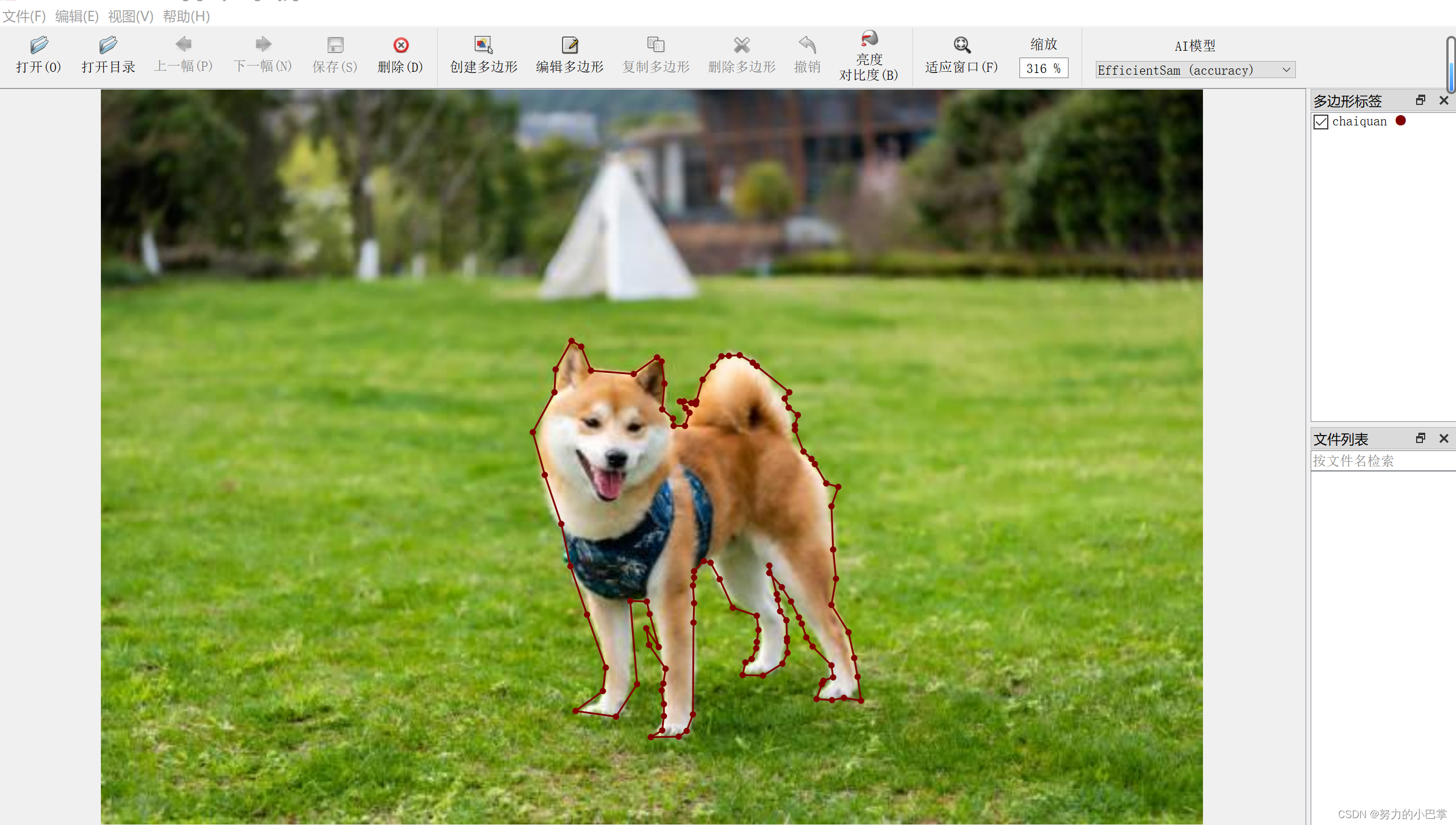
label标注文件:json格式
存储的格式是右边的json格式,这就是刚刚画的labelme格式的标注文件
labelme格式标注文件,json文件,存放了什么?
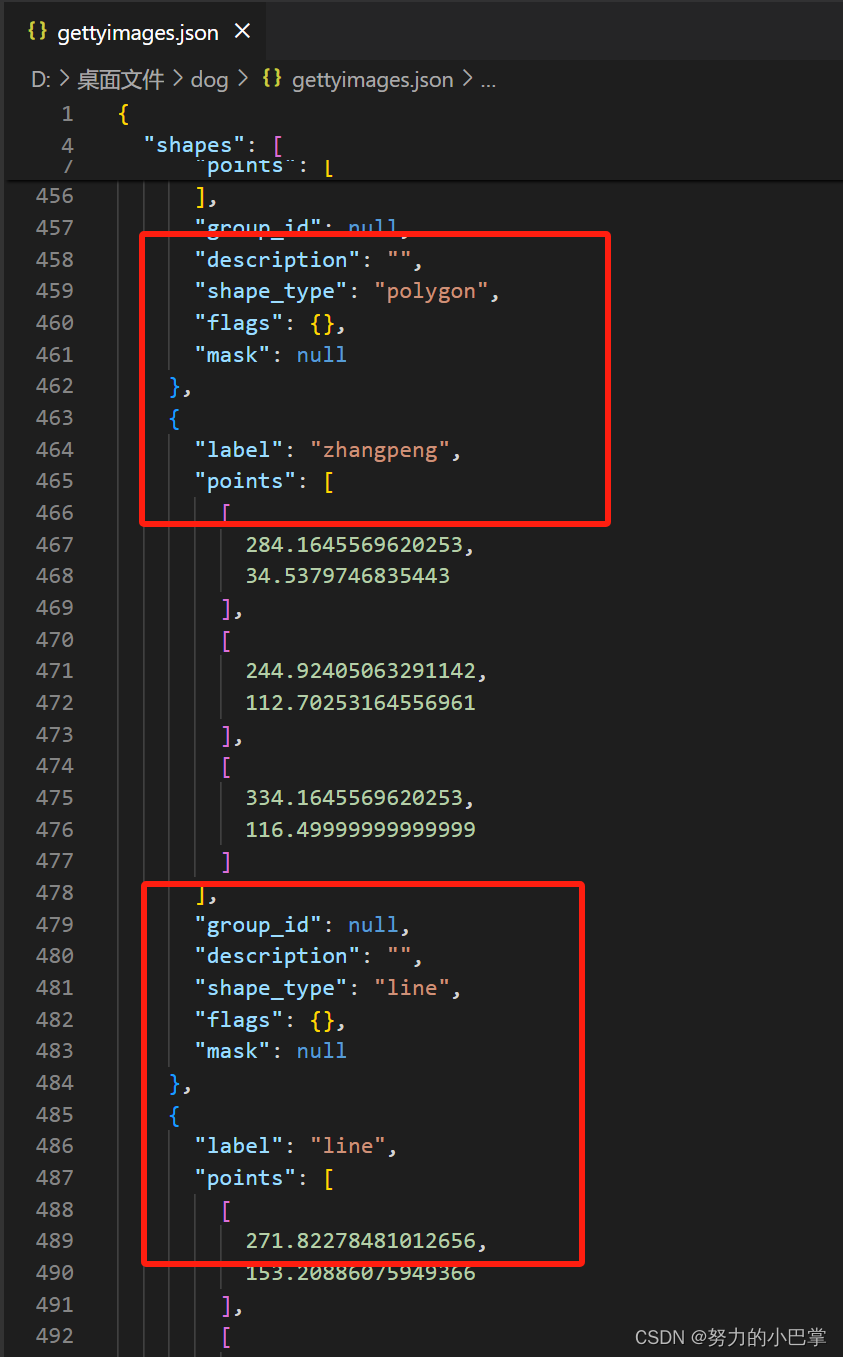
这个shapes很重要,里面有我们自己画的标签的类别,比如“chaiquan1”和我们当时画标签的时候,描的每一个点。
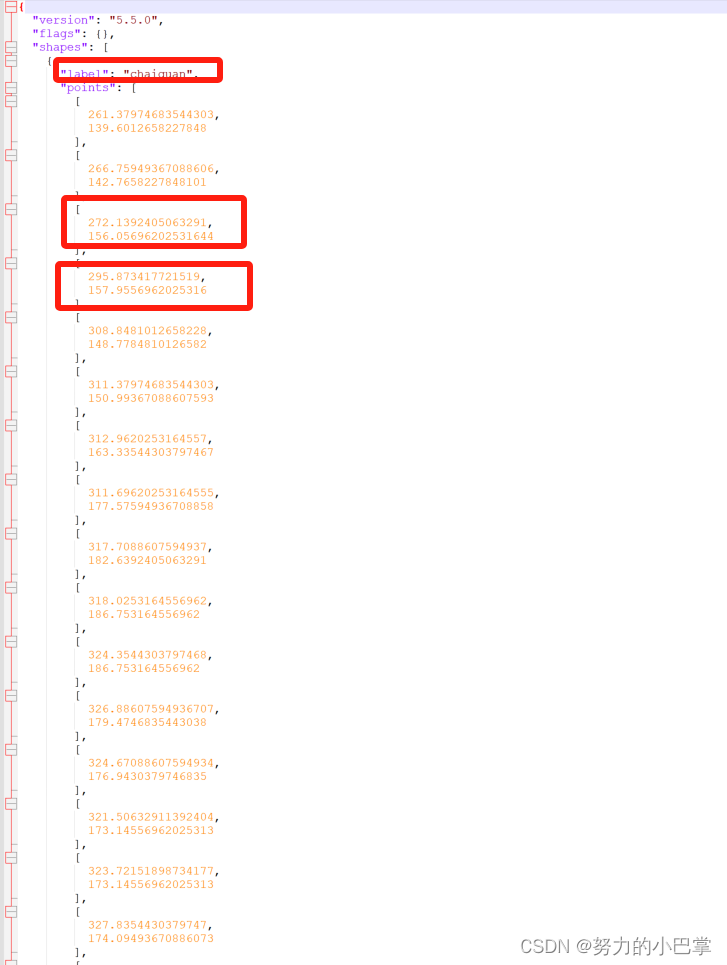

json十分轻量化,9kb就能保存标注了
如果在单张图片上绘制了好几个物体,最后的标注都会汇集在一个json文件上
比如,第一个是“chaiquan”标签的信息;那第二个就是“zhangpeng”的标签信息;以此类推,一张图片上,你打了几个标签,就会在json文件里出现几个标签的信息
除了自己描,还能用AI辅助标注,但是我打开会闪退,这个问题待解决。
另外注意:标注过程中,不要切换目录;
要确认,json文件最后,imagePath的图像路径,只能是图像名字本身,不能有其他的路径和符号。
标注转换(手打json标签文件到mask掩码文件)
现在,labelme格式的标签文件,我们就做好了,但是labelme的json格式的文件,并不能够,直接用于,语义分割的模型训练,所以,我们要把json文件,转换为整数掩膜mask格式,在像素层面上做类别标注,并且划分成训练集和测试集,并且用于后续的训练。
语义分割的本质,就是给每个像素做分类,所以,语义分割的标注,就是给每个像素打上类别标签,这种格式,叫做整数掩膜格式,因为能够严丝合缝的盖在原来的图上,所以,叫做掩码:
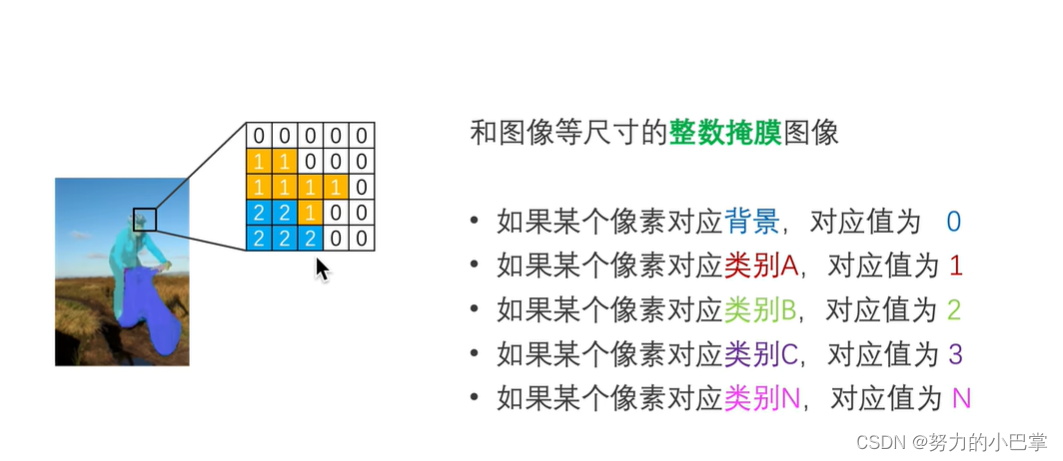

使用代码将labelme的标注文件转换成掩码
链接:常见计算机视觉标注格式相互转换
https://github.com/TommyZihao/Label2Everything

【labelme转mask-单张图像】
为了好展示图像,直接在jupyter notebook上面运行,我的jupyter notebook安装在conda下的yes虚拟环境,cmd激活进入环境,但是py38_pytorch虚拟环境也是和yes环境共同用的jupyter notebook,所以,从cmd进入yes激活jupyternotebook后,进入py38_pytorch虚拟环境就行了;或者在云服务器处理也行。
先查下自己所在的工作路径,当然,在哪里也不影响对图片的读取
1、导入包
import os
import json
import numpy as np
import cv2
import matplotlib.pyplot as plt
%matplotlib inline
2、读取图片
注意:我在这一直报错,搞了半天,原因是,我用了中文路径,换了个英文就好了。。。。,是所以,以后都用英文路径吧
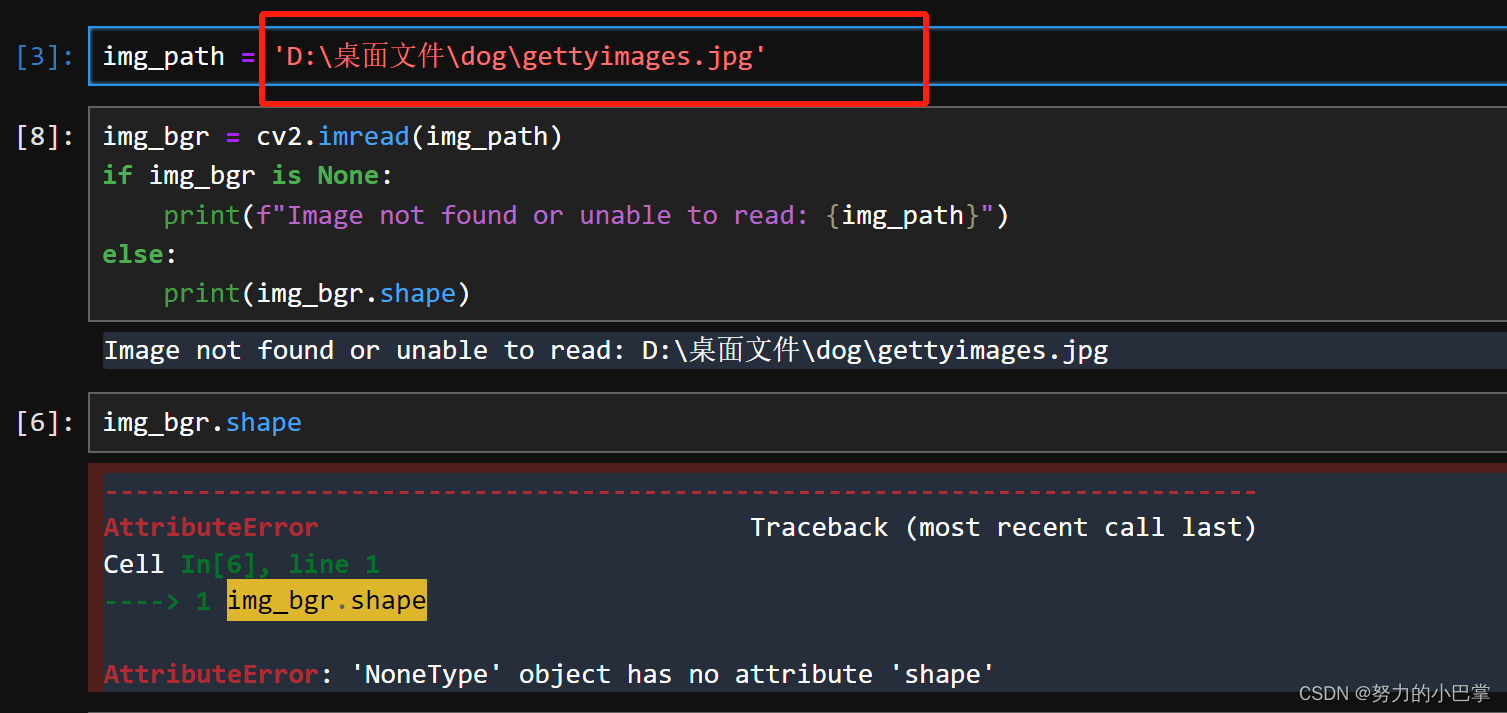
重新来:
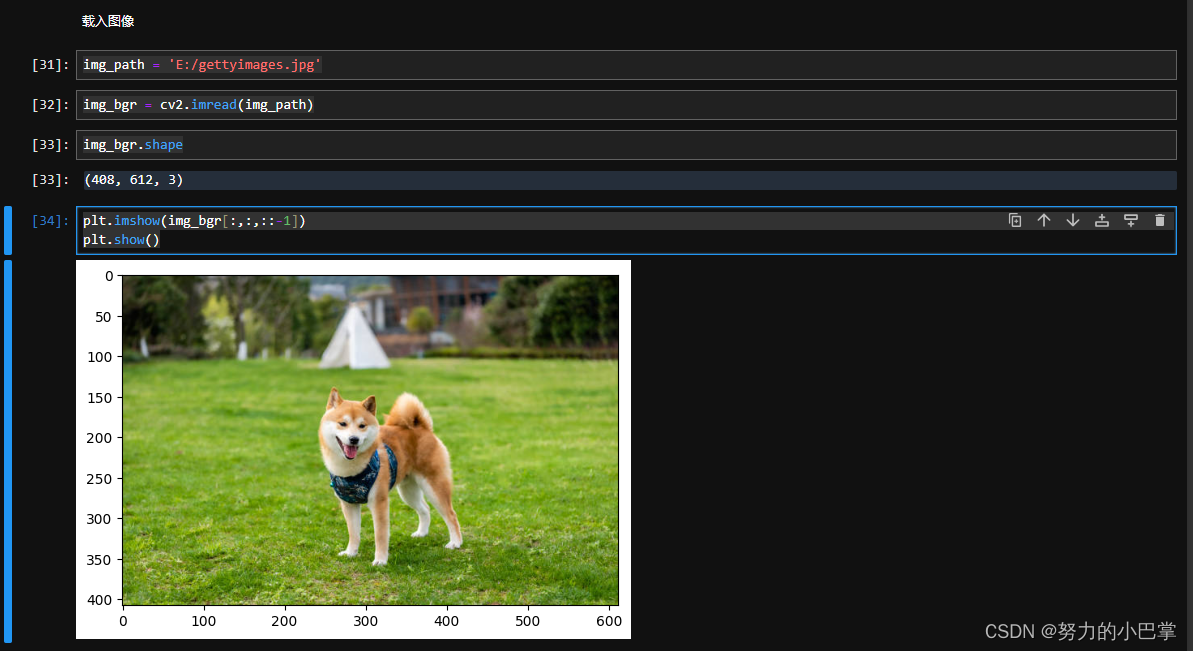
img_path = 'E:/gettyimages.jpg'
img_bgr = cv2.imread(img_path)
img_bgr.shape
plt.imshow(img_bgr[:,:,::-1])
plt.show()
【为什么要plt.imshow(img_bgr[:,:,::-1])】
是为了让opencv和matplot适应,因为我们在jupyternotebook上,最开始用了%matplotlib,让他直接显示图片。
`plt.imshow(img_bgr[:,:,::-1])` 的部分是为了在matplotlib中正确显示通过OpenCV读取的图像。
- `plt.imshow()`: 这是matplotlib库中的函数,用于显示图像数据。
- `img_bgr[:,:,::-1]`: 这是numpy数组切片的用法,用于改变图像数组的通道顺序。让我们逐部分解析:
- 第一个和第二个冒号(`:`): 这两个冒号意味着选取图像的所有行和列,即不改变图像的高度和宽度。
- 第三个部分(`::-1`): 这里的`-1`是步长参数,它指示从结尾开始向前选取元素,即反转选取的元素。在这个上下文中,它被应用于通道轴,意味着通道的顺序将会被反转。
由于OpenCV读取图像时默认采用BGR(蓝色、绿色、红色)的通道顺序,而matplotlib期望的图像格式是RGB(红色、绿色、蓝色)。因此,通过`[:,:,::-1]`,你实际上是在对图像的通道轴进行反转,将BGR顺序转换为RGB顺序,这样图像在matplotlib中显示时颜色就会正确无误。
总结来说,`img_bgr[:,:,::-1]`这一操作是为了适配OpenCV和matplotlib之间不同的颜色通道顺序,确保图像能够以正确的颜色显示在matplotlib的画布上。
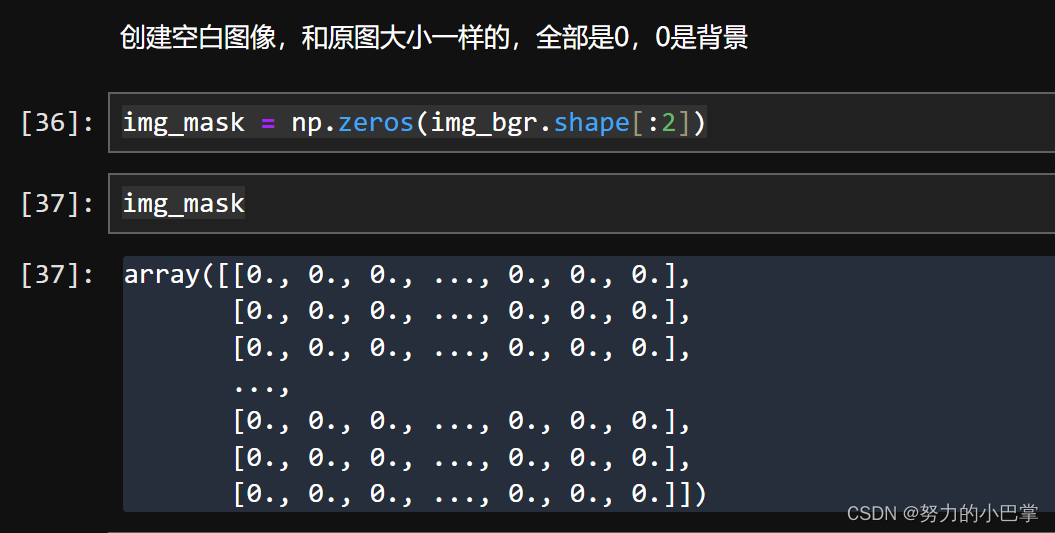
3、创建一个和原图大小一样,的背景图
注意,是和原图一模一样大!
img_mask = np.zeros(img_bgr.shape[:2])
img_mask
plt.imshow(img_mask)
plt.show()
【img_mask = np.zeros(img_bgr.shape[:2])】
这段代码创建了一个与`img_bgr`图像具有相同宽度和高度的二维numpy数组`img_mask`,并且这个数组的所有元素都被初始化为0。这里是逐步解析:
- `img_bgr.shape[:2]`:这里,`img_bgr.shape`返回一个包含图像尺寸的元组,通常是`(高度, 宽度, 通道数)`。使用切片操作`[:2]`选取前两个元素,即图像的高度和宽度,忽略通道数信息。这是因为掩码通常是对每个像素的位置进行标记,不需要颜色通道信息,所以是一个二维数组。
- `np.zeros(...)`:这个numpy函数用于创建一个指定形状的新数组,并将所有元素初始化为0。传入的参数是`(高度, 宽度)`,因此生成的数组尺寸与原图像的尺寸在宽度和高度上相匹配,但它是单通道的(灰度),每个元素都是0,代表一个全黑的“掩模”图像。
简而言之,`img_mask`是一个与`img_bgr`图像空间尺寸相同的全零数组,常用于后续的图像处理作为掩模,比如在图像分割、对象检测或特定区域的标记等场景中。
 4、载入该图片labelme格式的json标注文件
4、载入该图片labelme格式的json标注文件
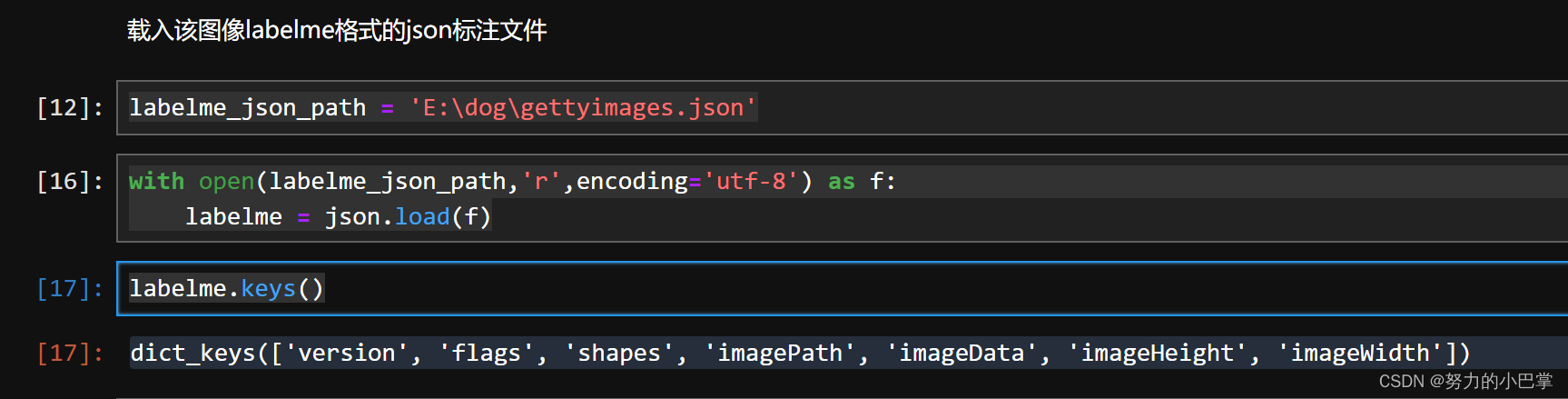
labelme_json_path = 'E:\dog\gettyimages.json'
with open(labelme_json_path,'r',encoding='utf-8') as f:
labelme = json.load(f)
labelme.keys()
【with open(labelme_json_path,'r',encoding='utf-8') as f:
labelme = json.load(f)】
这段代码是用来读取并加载一个使用JSON格式存储的LabelMe标注文件的。以下是代码的逐行解释:
- `with open(labelme_json_path, 'r', encoding='utf-8') as f:`:这一行使用了Python中的`with`语句来打开一个文件。`labelme_json_path`是你要读取的LabelMe JSON文件的路径。文件被以只读模式(`'r'`)打开,并且指定了字符编码为`'utf-8'`来正确处理可能包含的非ASCII字符。`as f`部分创建了一个名为`f`的文件对象,让你能够读取文件内容。使用`with`语句的好处在于它能确保文件在操作完成后会被正确关闭,即使发生了异常也是如此。
- `labelme = json.load(f)`: 这一行使用了Python的内置`json`模块来从已经打开的文件对象`f`中读取数据,并将其解析为Python的数据结构(通常是字典或列表)。这意味着如果LabelMe的JSON文件中包含图像的标签、边界框、多边形等标注信息,这些信息会被转换成Python的数据类型,存储在变量`labelme`中,供后续的程序逻辑使用。
综上所述,这段代码的作用是从指定路径的LabelMe JSON文件中读取图像标注数据,并将其内容以Python数据结构的形式保存在变量`labelme`里,以便进一步处理或分析这些标注信息。
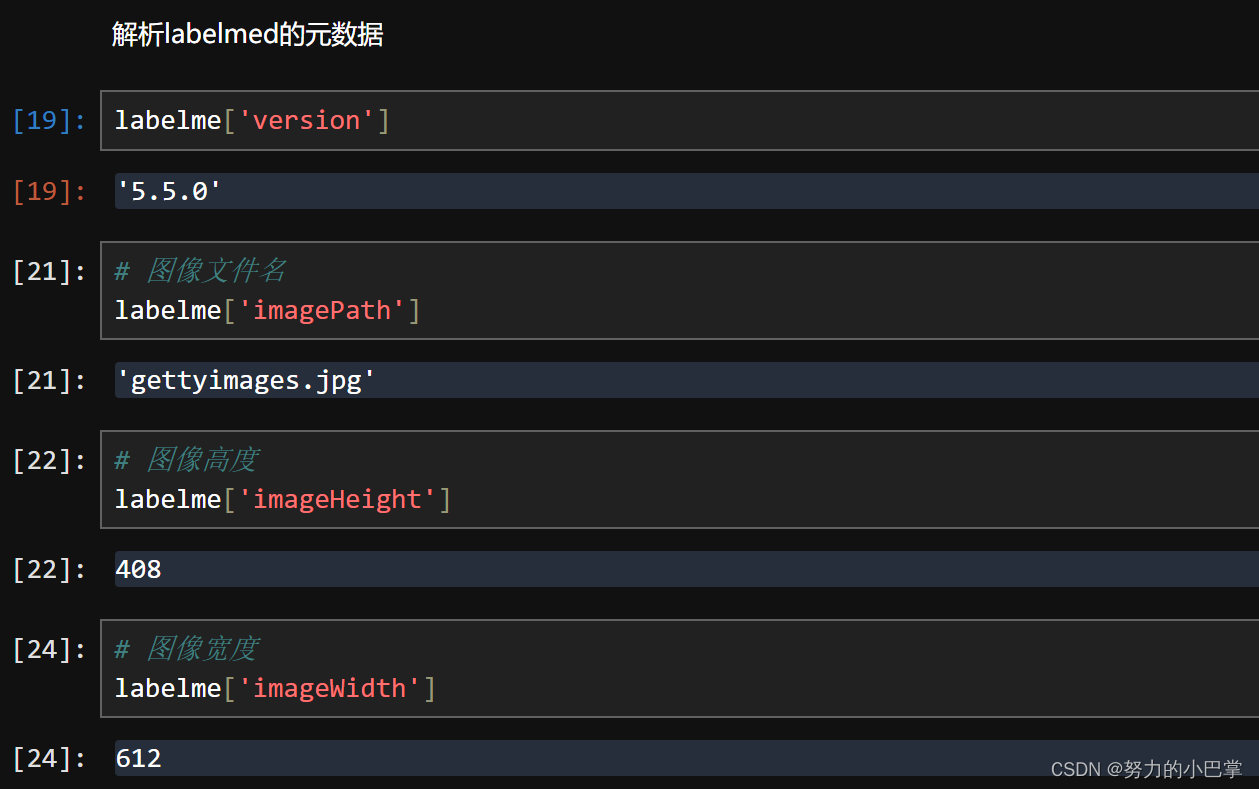
5、解析labelme的元数据
6、打印该图片中的所有标注信息
把labelme的每一个shape拿出来,打印每一个标签名字和画的类别(用什么线画的)
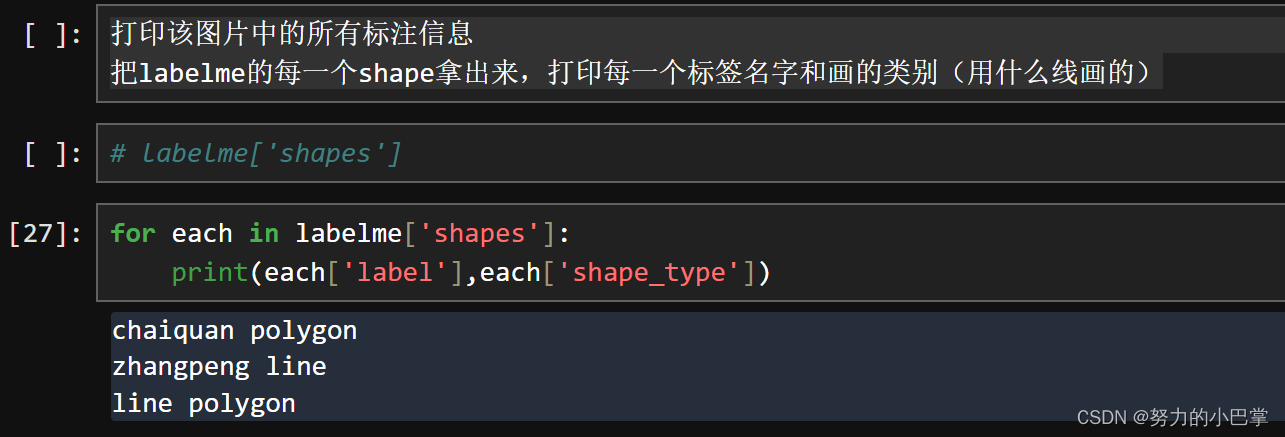
因为在前面,with open(labelme_json_path,'r',encoding='utf-8') as f:
labelme = json.load(f)
我们定义了,labelme是我们标注的json文件,然后这个labelme json文件里,包含了我们标注地所有信息,其中,比较重要的,就是,储存在里面的label标签信息和画这个标签时候我们用的什么线条,是多线段,还是圆圈,还是两点线段什么的
7、开始做绘制每个类别mask的准备
每个类别的信息,然后画mask的顺序是:(画的时候按照由大到小,由粗到精的顺序),比如,从大的天空到中等的建筑,再到小的人;颗粒度也是从粗到精;
# 0-背景,从1开始
class_info = [
{'label':'zhangpeng','type':'line','color':1,'thickness':5} ,# line 两点线段,填充线宽
{'label':'chaiquan','type':'polygon','color':2},
{'label':'line','type':'polygon','color':3}
]
因为当时,画的时候,我标注了3个标签,一个是柴犬,一个是帐篷,一个是一条线;那按照从大到小的顺序,就是先把,帐篷,柴犬,线,这三个,按照顺序,列出来,在这里,要给出label的名字,画label的线条类别,以及颜色,还有宽度等等。。。
顺序摆好以后,开始画mask
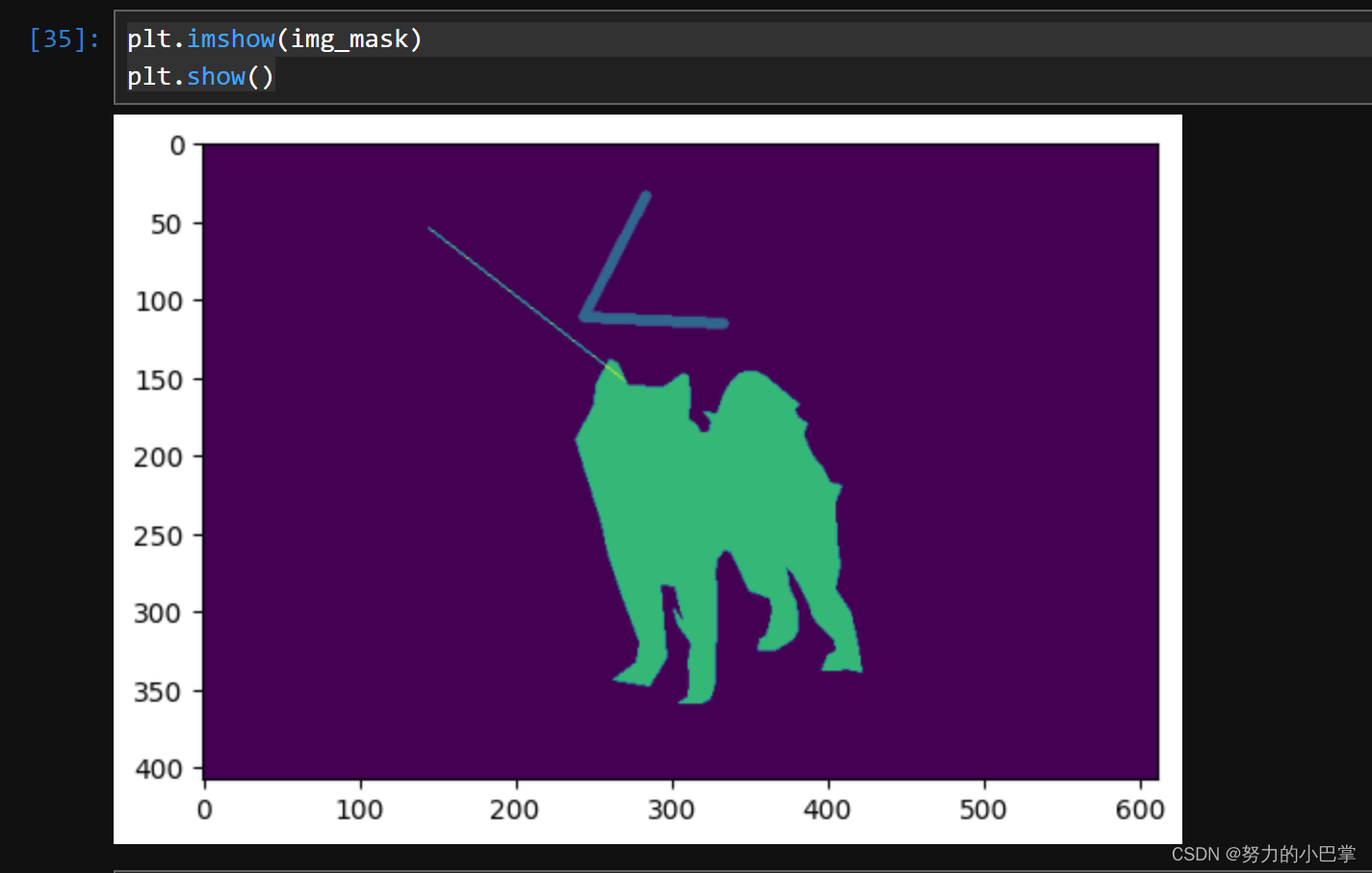
8、按顺序把mask绘制在空白图上
for one_class in class_info: # 按顺序遍历每一个类别
for each in labelme['shapes']: # 遍历所有标注,找到属于当前类别的标注
if each['label'] == one_class['label']:
if one_class['type'] == 'polygon': # polygon 多段线标注
# 获取点的坐标
points = [np.array(each['points'], dtype=np.int32).reshape((-1, 1, 2))]
# 在空白图上画 mask(闭合区域)
img_mask = cv2.fillPoly(img_mask, points, color=one_class['color'])
elif one_class['type'] == 'line' or one_class['type'] == 'linestrip': # line 或者 linestrip 线段标注
# 获取点的坐标
points = [np.array(each['points'], dtype=np.int32).reshape((-1, 1, 2))]
# 在空白图上画 mask(非闭合区域)
img_mask = cv2.polylines(img_mask, points, isClosed=False, color=one_class['color'], thickness=one_class['thickness'])
elif one_class['type'] == 'circle': # circle 圆形标注
points = np.array(each['points'], dtype=np.int32)
center_x, center_y = points[0][0], points[0][1] # 圆心点坐标
edge_x, edge_y = points[1][0], points[1][1] # 圆周点坐标
radius = np.linalg.norm(np.array([center_x, center_y] - np.array([edge_x, edge_y]))).astype('uint32') # 半径
img_mask = cv2.circle(img_mask, (center_x, center_y), radius, one_class['color'], one_class['thickness'])
else:
print('未知标注类型', one_class['type'])
plt.imshow(img_mask)
plt.show()
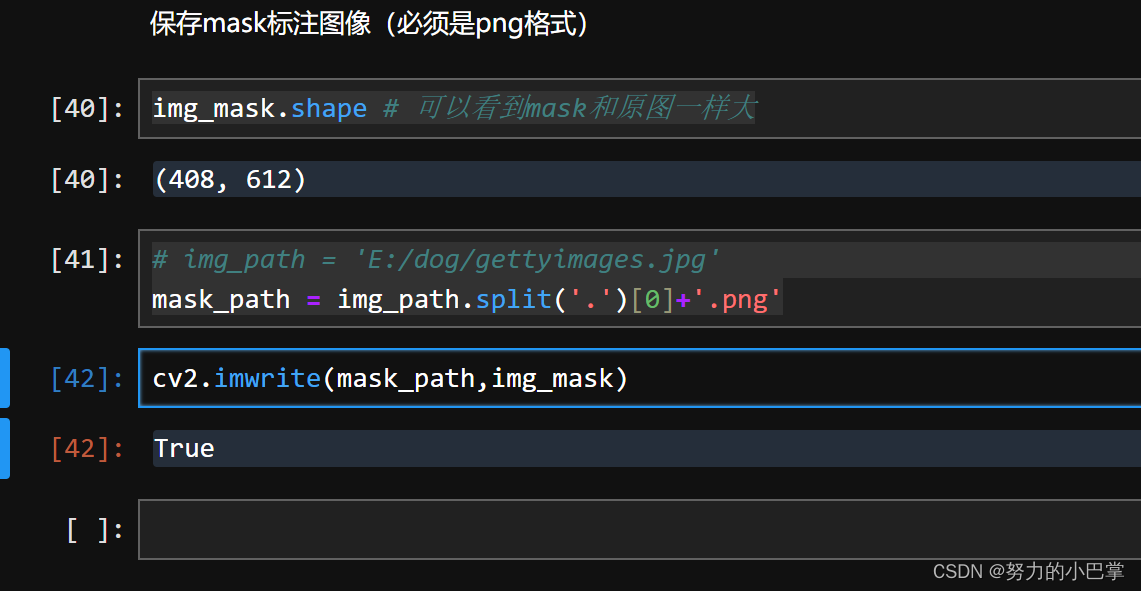
9、把刚刚画的mask保存下来
保存的mask必须是png格式
img_mask.shape # 可以看到mask和原图一样大
# img_path = 'E:/dog/gettyimages.jpg'
mask_path = img_path.split('.')[0]+'.png'
cv2.imwrite(mask_path,img_mask)
然后这时候,看到,原来放原图和标注label的json文件,还有刚刚生成的mask文件,都在一个文件夹下面,但是,如果直接打开是黑色的,因为,1,2,3,4这种像素在0-255里面是很小的像素,直接打开图片只会是黑色的。
所以,用cv2.imread载入图像
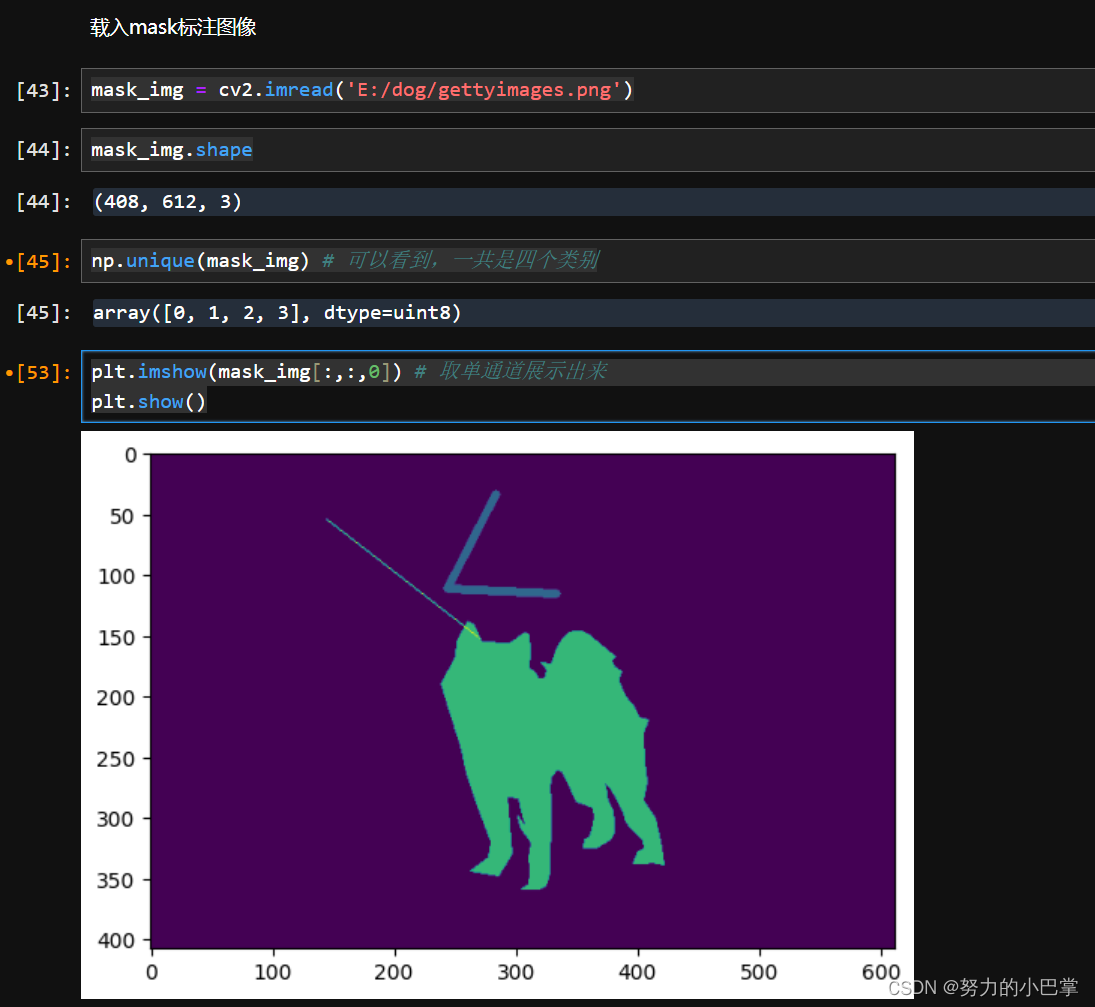
10、正确的载入和显示mask图像
mask_img = cv2.imread('E:/dog/gettyimages.png')
mask_img.shape
np.unique(mask_img) # 可以看到,一共是四个类别
plt.imshow(mask_img[:,:,0]) # 取单通道展示出来 ,所以最后是取0(取1,2也是一样的)
plt.show()
完整代码
http://localhost:8888/doc/tree/%E5%8D%95%E5%BC%A0%E5%9B%BE%E7%89%87label%E8%BD%ACmask.ipynb
















 3656
3656

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









